本着记录自己学习的脚步,以及明记自己学习的知识点不忘记,今天我会开始更新自己博客。加油
首先,说明一下我的环境:win7(x86)系统,python3.6, TensorFlow版本为“termcolor-1.1.0-py3.6”。
在开始调试之前需要保证系统安装了readline这个python库,但是windows下无法安装这个python库,所以我又下载了pyreadline这个库,我也没有实验单装readline(虽然windows会失败)是否能直接使用,还是建议将两个库都安装一下吧,希望有兴趣的小伙伴帮忙验证一下只装readline或者pyreadline能否调试。
使用pip install --upgrade readline 以及 pip install --upgrade pyreadline就可以安装了。
接下来调试的时候,需要在python代码中引入python的debug包,使用:
from tensorflow.python import debug as tfdbg这里使用LocalCLIDebugWrapperSession函数,以调试TensorFlow的cifar10的代码为例。
在cifar10_train.py的train函数中的以下代码里加入LocalCLIDebugWrapperSession函数,如下:
with tf.train.MonitoredTrainingSession(
checkpoint_dir=FLAGS.train_dir,
hooks=tf.train.StopAtStepHook(last_step=FLAGS.max_steps),
tf.train.NanTensorHook(loss),
_LoggerHook()],
config=tf.ConfigProto(
log_device_placement=FLAGS.log_device_placement)) as mon_sess:
mon_sess = tfdbg.LocalCLIDebugWrapperSession(mon_sess)
while not mon_sess.should_stop():
mon_sess.run(train_op)
# Update the masks
mon_sess.run(mask_update_opmon_sess = tfdbg.LocalCLIDebugWrapperSession(mon_sess)在每次执行代码就会进入TensorFlow的debug(tfdbg)模式,如图:
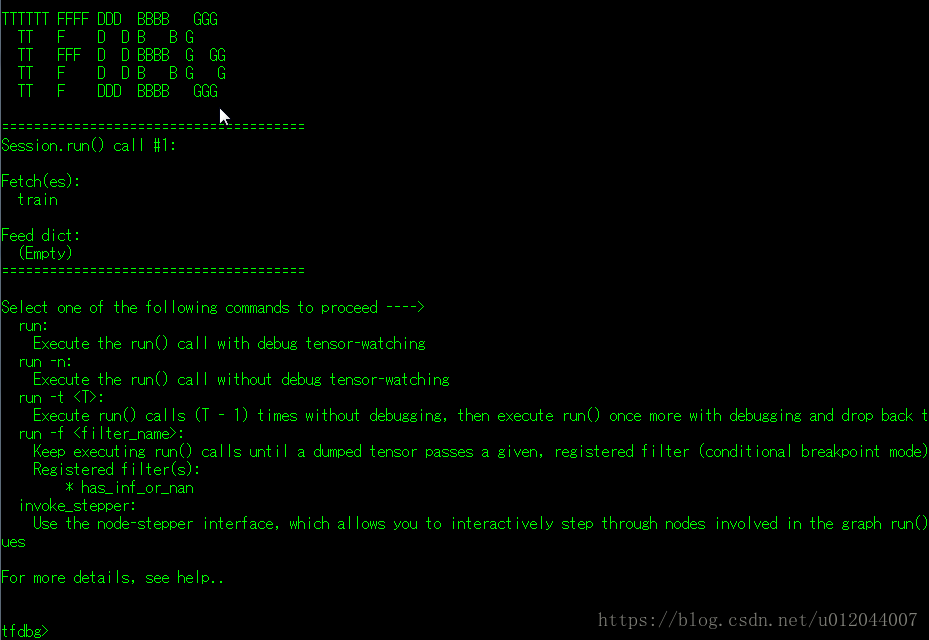
执行run后会打印出处所有的张量表,如下:
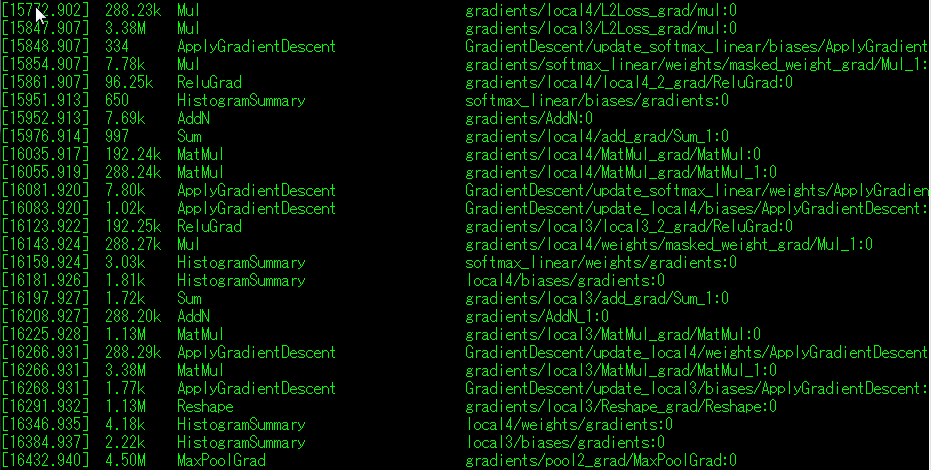
由于张量太多,这里只截取部分。
(1) 打印出的张量表的列依次是:执行时间,张量大小,操作类型,张量名。
(2) run命令:
程序一直执行到下次Session.run()被调用的地方,并将张量表打印到命令控制行(CLI)。
其中run命令的参数有:
a. -n 在不打印debug调试信息的情况下,令程序运行到下次Session.run()被调用的地方。因此命令控制行不会打印任何信息。
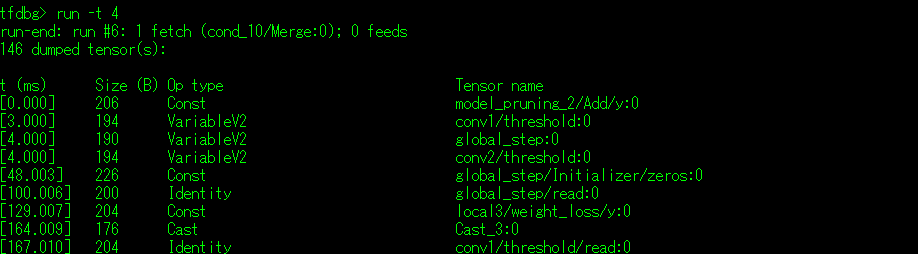
b. -t<Times> 运行指定Times次程序,打印出第Times次的调试信息,如下:
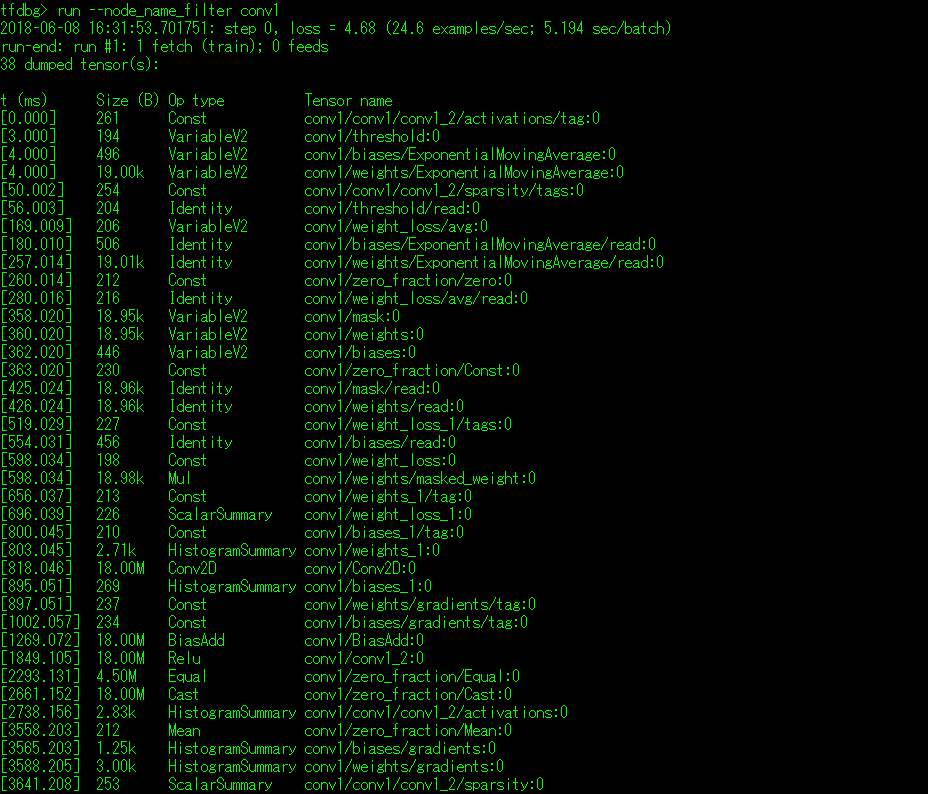
c. --node_name_filter <re> 在调试中,根据正则表达打印出指定的节点到命令控制行中。例如,Cifar10所涉及的张量表过大可以使用该命令对显示的张量表进行过滤,如下:
d. --op_dtype_filter <re> 上面说了能够根据张量名来过滤张量表,同样的该参数就是通过操作类型来过滤张量表。
e. --tensor_dtype_filter <re> 该参数则是通过张量的类型来过滤张量表
·接下来再接收一些其他命令:
(1)lt 命令: 该命令在不使用参数的情况下会输出本次Session.run()执行后所有的张量一览表。
-n <re>参数: 根据re参数指定的张量名过滤张量表,功能与run命令中的--node_name_filter类似
-t <re>参数:根据re参数指定的操锁类型过滤张量表,功能与run命令中的--op_dtype_filter类似
-r 参数:逆序输出所有的张量表
(2)pt 命令:该命令输出需要配合指定的张量名一起使用输出指定的张量信息。
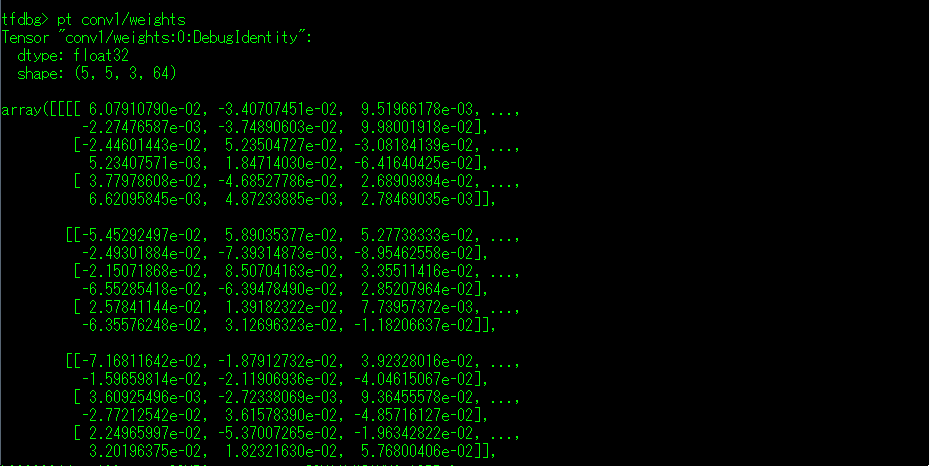
-a 详细的输出指定的张量信息,在张量过大的情况下谨慎使用。
(3)ni 命令:显示指定张量的信息,信息主要是显示输入和接收节点的信息(详细内容可使用下面的li命令和lo命令)。
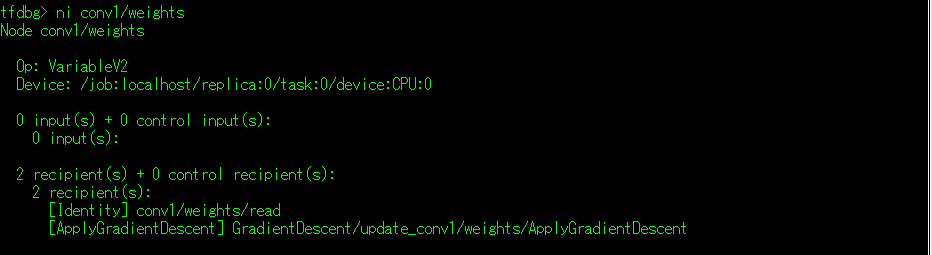
-a 参数:详细输出指定张量的属性信息,请将下图对照上图进行参照。
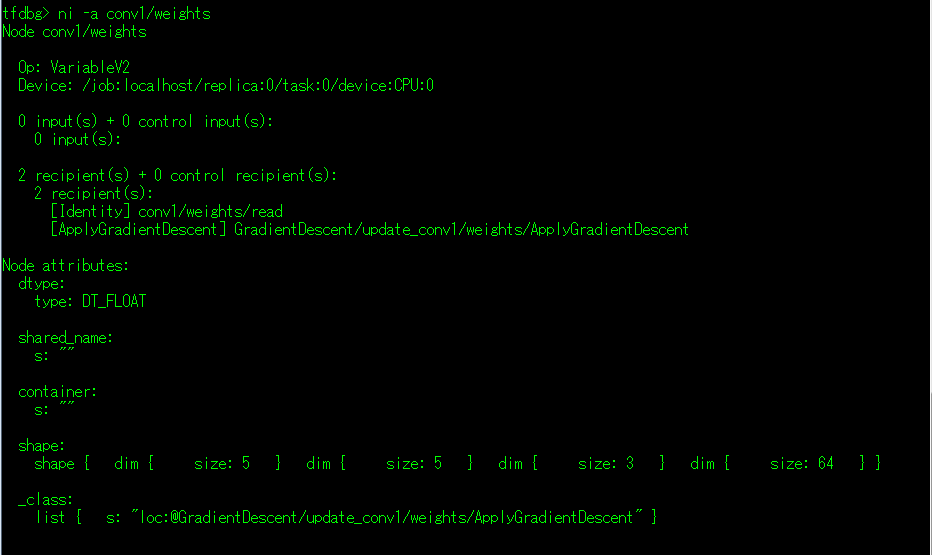
(4)li 命令:列出张量的输入神经元节点的信息。

可以看到,因为卷积核(conv1/weights)是定义好的不存在输入的神经元节点所以他的输入是None;
而下面的代码可以看到conv1/Conv2D的第一个输入由调用Interface(images)方法传入的images参数获得的而images就是通过shuffle_batch来从队列中批量读取出来的数据。
再下来conv1/Conv2D是进行卷积运算,的所以他的一个输入是conv1/weights/massked_weight(这里的结论我没有信心,希望说错了能够被指摘出来,谢谢~)
conv = tf.nn.conv2d(images, pruning.apply_mask(kernel, scope), [1, 1, 1, 1], padding='SAME')(5) lo 命令:同li相反一个试input,那么lo就是output这里就不介绍了。
(6)eval 命令: 该命令是可以在调试的过程中使用python语法加numpy的库来执行python语句。
-a 参数:能够详细的不加省略号的输出计算后的值,同样的在使用该参数查看大的数据的时候要谨慎,会长到让你怀疑人生。
在这里要说明几个重要的事情。
a. 执行的python语句是一个字符串
b. 变量一定要使用"`"(键盘的Tab键上方的符号)来括住张量名。
c. 我只验证能够使用库是numpy库,而TensorFlow库不能使用,至于其他的库还请各位尝试一下。

以上就是关于tfdbg的相关内容,希望学识渊博的各位指出我的不正,并且完善一下,在下不胜感激。
最后
以上就是瘦瘦店员最近收集整理的关于TensorFlow学习总结:TensorFlow的debug调试的全部内容,更多相关TensorFlow学习总结:TensorFlow内容请搜索靠谱客的其他文章。








发表评论 取消回复