1.关联规则
关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,如果两个或多个事物之间存在一定的关联关系,那么,其中一个事物就能通过其他事物预测到。关联规则是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系。
关联规则挖掘的最经典的例子就是沃尔玛的啤酒与尿布的故事,通过对超市购物篮数据进行分析,即顾客放入购物篮中不同商品之间的关系来分析顾客的购物习惯,发现美国妇女们经常会叮嘱丈夫下班后为孩子买尿布,30%-40%的丈夫同时会顺便购买喜爱的啤酒,超市就把尿布和啤酒放在一起销售增加销售额。有了这个发现后,超市调整了货架的设置,把尿布和啤酒摆放在一起销售,从而大大增加了销售额。
2.基本概念
(1) 什么是规则?
规则形如"如果…那么…(If…Then…)",前者为条件,后者为结果。例如一个顾客,如果买了可乐,那么他也会购买果汁。
如何来度量一个规则是否够好?有两个量,置信度(Confidence)和支持度(Support),假如存在如下表的购物记录。
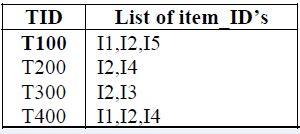
其中,I={ I1, I2, … Im } 是m个不同项目的集合,集合中的元素称为项目(Item)。
项目的集合I称为项目集合(Itemset),长度为k的项集成为k-项集(k-Itemset)。
设任务相关的数据D是数据库事务的集合,其中每个事务T是项的集合,使得T⊆I。每个事务有一个标识符TID;设A是一个项集,事务T包含A当且仅当A⊆I,则关联规则形式为A=>B(其中A⊂I,B⊂I,并且A∩B= ∅),交易集D中包含交易的个数记为|D|。
在关联规则度量中有两个重要的度量值:支持度和置信度。
对于关联规则R:A=>B,则:
支持度(suppport):是交易集中同时包含A和B的交易数与所有交易数之比。
Support(A=>B)=P(A∪B)=count(A∪B)/|D|
置信度(confidence):是包含A和B交易数与包含A的交易数之比。
Confidence(A=>B)=P(B|A)=support(A∪B)/support(A)
(2) 支持度
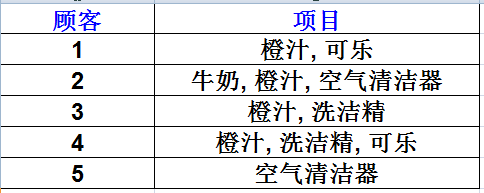
支持度(Support)计算在所有的交易集中,既有A又有B的概率。例如在5条记录中,既有橙汁又有可乐的记录有2条。则此条规则的支持度为 2/5=0.4,即:
Support(A=>B)=P(AB)
现在这条规则可表述为,如果一个顾客购买了橙汁,则有50%(置信度)的可能购买可乐。而这样的情况(即买了橙汁会再买可乐)会有40%(支持度)的可能发生。
(3) 置信度
置信度(confidence)表示了这条规则有多大程度上值得可信。设条件的项的集合为A,结果的集合为B。置信度计算在A中,同时也含有B的概率(即:if A ,then B的概率)。即 :
Confidence(A=>B)=P(B|A)
例如计算“如果Orange则Coke”的置信度。由于在含有“橙汁”的4条交易中,仅有2条交易含有“可乐”,其置信度为0.5。
(4) 最小支持度与频繁集
发现关联规则要求项集必须满足的最小支持阈值,称为项集的最小支持度(Minimum Support),记为supmin。支持度大于或等于supmin的项集称为频繁项集,简称频繁集,反之则称为非频繁集。通常k-项集如果满足supmin,称为k-频繁集,记作Lk。关联规则的最小置信度(Minimum Confidence)记为confmin,它表示关联规则需要满足的最低可靠性。
(5)强关联规则
如果规则R:X=>Y 满足 support(X=>Y) >= supmin 且 confidence(X=>Y)>=confmin,称关联规则X=>Y为强关联规则,否则称关联规则X=>Y为弱关联规则。
在挖掘关联规则时,产生的关联规则要经过supmin和confmin的衡量,筛选出来的强关联规则才能用于指导商家的决策。
Apriori算法将发现关联规则的过程分为两个步骤:
1.通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;
2.利用频繁项集构造出满足用户最小置信度的规则。
挖掘或识别出所有频繁项集是该算法的核心,占整个计算量的大部分。
最后
以上就是动人小猫咪最近收集整理的关于数据挖掘之关联规则练习的全部内容,更多相关数据挖掘之关联规则练习内容请搜索靠谱客的其他文章。








发表评论 取消回复