
前言
之前本号就有一篇文章是关于用Python编写一个"拿石子"游戏,一个能让你与电脑对弈的小游戏,但其中电脑玩家的选择是随机的,意味着你是与一个智障电脑在玩游戏。
今天我们更进一步,编写程序让这个智障电脑可以自己与自己不断玩这个"拿石子"游戏,最终学会如何赢得这个游戏。不仅如此,我们还可以通过这个训练后的电脑玩家得知这个游戏的必胜秘诀(文末处)。下面看看示意动图。

高能预警,本文与之前的文章不一样,需要自己实现一个强化学习中的一个小算法,但这个算法不难,而且可以广泛应用到其他同类型的博弈问题中,可以让你做出有趣的东西出来。我们开始吧。
"拿石子"游戏规则
拿石子游戏规则很简单,开始有一定数量的石子(假如是10),然后两人轮流从石子堆中取走一定范围的数量(例如是1到3),以此类推,最后拿走剩余的所有石子的人就输了。
本文需要的库
- numpy
- pandas
- retrying
如果你已经看过我关于如何安装Anaconda的文章,那么这些库基本都不用安装了。
程序结构
由于本次程序较为复杂,并且日后我会继续使用不同的方式去改善他。因此本次不会使用上次文章中的代码结构,而是采用类的方式组织代码。 最后,如果你的时间不是很紧张,并且又想快速的python提高,最重要的是不怕吃苦,建议你可以架尉♥信(同音):276 3177 065 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
整个游戏有3个角色:
- 人类玩家:UserPlayer
- 本次拿取数量:get_taken_num(current_num)
- 电脑玩家:CpuPlayer
- 本次拿取数量:get_taken_num(current_num)
- 学习:learning(current_num,taken_num,state)
- 裁判:Referee
- 准备开局:ready
- 获取当前剩余石子数量:current_num
- 判定当前局面状态:get_state(taken_num)
- 更新剩余石子:take_away(taken_num)
- 本局是否结束:is_end_game
上述所有实现都在models.py中,有兴趣的朋友请去github查看即可。
关键点说明
到底机器学习的程序与普通的应用开发程序有什么不一样?正如本文的实现,程序的逻辑走向不是通过我们写代码的方式编写的,而是通过数据来决定。
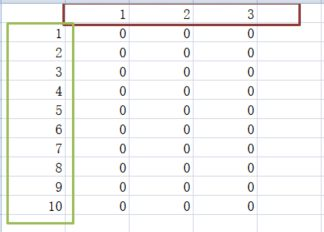
下面就来简单说明整个过程的关键点
- 整体上来说,电脑玩家每次选择拿取多少个石子,是通过一个表的数据判断出来。
- 图中的行索引(左边绿色框中的),表示当前盘面的石子数量。
- 列索引(上方红色框中),表示可以选择的数量
- 那么行列索引交叉点的数据,就表示这次选择的价值,这个值越大,电脑玩家就会越可能选择。
- 所以你可以看到,当你与电脑玩家对战时,其实他早就想好每一步要怎么走了。
问题是,这个表格中的价值数据是怎么得来的?没错,就是让他与自己不断的对战从而获得经验而来。 我们来分析一下这个对战过程
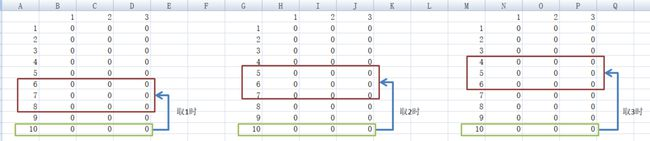
- 一开始的时候,整个表格的值全是0
- 假设当前剩余数量是10,那么他就会看行索引10对应的那一行的数据。
- 他发现那一行全是0,那么他就会随机来挑。对的,此时他就是在碰运气。
- 当他选好本次拿取数后,就会根据下一轮可能出现的状态来计算价值,然后更新到本次选择中。
- 上图包含了3种可能的选择中的每个情况
当然,第一次训练时,比较靠后的记录都不会有任何更新。直到遇到奖励或惩罚。下图表明了这样的情况

- 假如当前剩余数量是4,电脑玩家选择,他选了取走3个。
- 这是裁判反馈给他说,你赢了,因此在(行4,列3)那里的价值加了10分。这就是电脑玩家可以自己学会玩游戏的关键。
- 如果裁判反馈给他说,你输了,那么以一样的机制扣减价值分。
再来看看之后他是怎么得到下面行的分数。假设现在已经训练了几个回合,表格上方的行陆陆续续有些得分
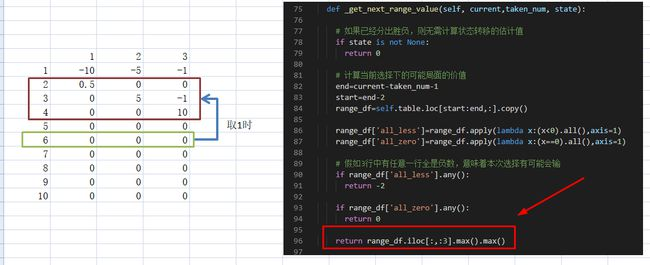
- 假设当前剩余数量为6,电脑玩家随机选了1,那么就可以确定下一个可能的状态区域
- 发现3行数据没有一行全是0或全是负数,因此(行6,列1)那里的价值分加3行区域中的最大值*学习率(就是一个百分比)
- 以此类推,电脑玩家不断与自己玩游戏,不断更新表格中的分数。
- 注意一点,整个项目我们都没有编写任何的游戏逻辑代码。只有关于奖励与惩罚相关的逻辑。
游戏必胜秘诀
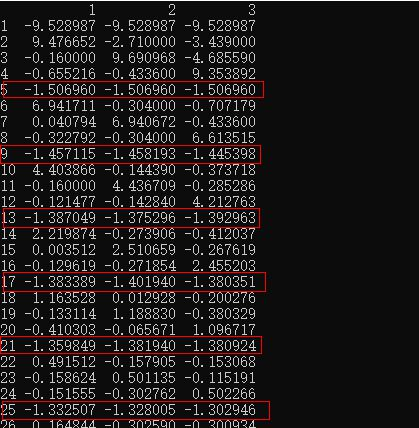
- 上图把电脑玩家学习到的表格数据显示出来
- 看到那些整行都是负数的吗,那些就是必定会输的状态。
- 这也是为什么我设定于电脑对战时默认是21开始并且是电脑先拿,这样我才有机会赢。
- 我们还看到从2开始,每个3段就会出现一个必输的盘面。
小结
本文利用了最简单的强化学习中的Q-Table机制,让电脑自学玩游戏,这是一个非常适合入门的例子(他需要你在Q-Table方法上做出变通)。以后我会继续改善这个游戏,用不同的机器学习的方式去实现这些功能,敬请期待。
如果觉得本文对你有所帮助,记得关注、评论、转发、收藏噢~
最后
以上就是寒冷枫叶最近收集整理的关于Python做人工智能?让电脑自己学会玩游戏,实战带你入门机器学习的全部内容,更多相关Python做人工智能?让电脑自己学会玩游戏内容请搜索靠谱客的其他文章。








发表评论 取消回复