文章目录
- 一、基础操作
- 1.1 如何读取数据
- 1.2 如何输出到文件
- 1.3 如何获取行数、列数、某行值、某列值、某行某列值
- 1.4 删除某些行
- 1.5 如何删除指定列中为nan的行
- 1.6 选择包含特定字符串的行
- 1.7 删除某些列
- 1.8 对某列去重
- 1.9 如何获得所有列名
- 1.10 如何查看每列数据的数据类型属性
- 1.11 将df中所有为nan的数据替换为字符串空
- 1.12 对某列排序
- 1.13 如何插入一列
- 1.14 替换某列的值为某个值
- 1.15 读取或者选择某几列
- 1.16 如何修改数据类型
- 1.17 如何获取某个字段的文本长度
- 二、进阶用法
- 2.1 如何重建index
- 2.2 如何按行遍历DataFrame
- 2.3 如何打乱顺序
- 2.4 如何检查数据中是否存在nan或者null
- 2.5 如果某两列相当于dict的key和value,如何快速将这两列抽取并变成dict
- 2.6 如何重命名修改列名
- 2.7 如何每隔n行取一行
- 2.8 如何显示进度条
- 2.9 如何多线程并行apply并显示进度条
- 2.10 如何拼接合并两个DataFrame
- 2.11 如何对两个DataFrame根据某字段做join
- 2.12 如何由其他几列计算得到新的一列
- 三、高级用法
- 3.1 如何统计分数的区间分布
- 3.2 如何将某个表中某列不在另一个表的某列的那些行抽取出来
- 3.3 统计某一列中各个值的出现次数
- 3.4 如何快速筛选出满足某种条件的行
- 3.5 对某列进行分组编号
- 3.6 如何构建DataFrame
- 3.7 数值序列描述性统计
- 3.8 将数据归一化到0~1
- 3.9 如何将归一化后的数据复原
- 3.10 如何数据增广
- 3.11 矩阵中的‘逗号跟冒号’
- 3.12 计算振幅、涨跌幅
- 3.13 如何查看series的值分布情况
- 3.14 如何求最近后面几行的最大值
- 3.15 如何批量读取某文件夹下的所有csv文件
- 3.16 如何合并重复的行,并对其他列执行求和等操作
欢迎大家访问类chatGPT网站: 智聊对话机器人
pandas时不要盲目的使用for-loop,费时费力;要熟练掌握pandas提供的内置函数。
一、基础操作
1.1 如何读取数据
df_text = pd.read_csv("data.csv", names=['url','user_id','id','day','title','text'], sep='x01', index_col=0, ,dtype=str, on_bad_lines="warn")
# 如果data.csv本身已经含有表头,那么就无需指定names字段。
# setp='x01',表示使用分隔符x01,一般原始数据中不容易含有这样的字段。这个分隔符最好在用sql下载数据时就保持这个分隔符,这样解析时分隔符一致。
# index_col=0,表示跳过第一列
# dtype=str,表示读取整个表格时,每个字段都被当做字符串格式
# on_bad_lines="warn",表示跳过列读取错误的行
1.2 如何输出到文件
df.to_csv("train.csv", index=False)
df.to_excel("train.xlsx", index=False)
1.3 如何获取行数、列数、某行值、某列值、某行某列值
#获取行数
df.shape[0]
#获取列数
df.shape[1]
# 读取第二行的值
data1 = data.loc[1, :]
# 读取第二列的值
data2 = data.loc[ : ,"B"]
# 读取第1行,第B列对应的值
data3 = data.loc[ 1, "B"]
# 读取倒数第1行
data4 = data.iloc[-1]
假设data.csv文件内容为
| id | text |
|---|---|
| 178937849 | 你好啊 |
那么获取id为178937849的对应的text方式如下:
import pandas as pd
df_text = pd.read_csv("data.csv")
text=df_text[df_text["id"]==178937849]["text"].values
print(text)
1.4 删除某些行
df_clear = df.drop(df[df['x']<0.01].index)
# 也可以使用多个条件
df_clear = df.drop(df[(df['x']<0.01) | (df['x']>10)].index) #删除x小于0.01或大于10的行
1.5 如何删除指定列中为nan的行
df=df.dropna(subset=['filed_name'])
1.6 选择包含特定字符串的行
df = df[(df['text'].str.contains('#你想找的字符串#'))]
1.7 删除某些列
df.drop(columns=['B', 'C'])
1.8 对某列去重
df.drop_duplicates(subset = 'text',inplace = True)
df = df.drop_duplicates(subset=['brand', 'style'], keep='last')
1.9 如何获得所有列名
df_train.columns
1.10 如何查看每列数据的数据类型属性
df_train.info()
1.11 将df中所有为nan的数据替换为字符串空
train_df = train_df.replace(np.nan, '', regex=True)
1.12 对某列排序
df.sort_values(by=["user_id","score"], ascending=(True,False))
1.13 如何插入一列
使用 pandas 的 insert 方法,第一个参数指定插入列的位置,第二个参数指定插入列的列名,第三个参数指定插入列的数据
in [4]: data.insert(data.shape[1], 'd', 0)
in [5]: data
out[5]:
a b c d
0 1 2 3 0
1 4 5 6 0
2 7 8 9 0
1.14 替换某列的值为某个值
df_train.loc[df_train['label']=='高相关','label']='1'
df_train.loc[df_train['label']=='低相关','label']='1'
df_train.loc[df_train['label']=='不相关','label']='0'
1.15 读取或者选择某几列
df_train[['text','shares_name', '股票相关性']]
1.16 如何修改数据类型
df['Customer Number'] = df['Customer Number'].astype('int')
1.17 如何获取某个字段的文本长度
df['length'] = df['text'].str.len()
二、进阶用法
2.1 如何重建index
df.index = list(range(len(df)))
2.2 如何按行遍历DataFrame
id2result = {}
for index, row in df.iterrows():
id2result[row['id']] = row['result']
2.3 如何打乱顺序
from sklearn.utils import shuffle
df = shuffle(df)
2.4 如何检查数据中是否存在nan或者null
print(train_df.isnull().any())
print(train_df.isna().any())
2.5 如果某两列相当于dict的key和value,如何快速将这两列抽取并变成dict
symbol2name = stock_df.set_index(['symbol'])['name'].to_dict()
2.6 如何重命名修改列名
第1种方法:修改列名的一部分
df.columns = df.columns.str.replace('环湖医院', '开滦医院')
第2种方法:重新命名指定的列
df.rename(columns = {'环湖医院':'开滦医院', '普通医院':'三甲医院'}, inplace = True)
第3种方法:修改全部列名
df.columns = ['舒畅', '小舒畅', '舒小畅', '舒畅小']
2.7 如何每隔n行取一行
例如,每隔3行取一行
data['Date'].loc[::3]
2.8 如何显示进度条
只需要将apply改为process_apply即可,例如
from tqdm import tqdm
tqdm.pandas(desc='apply')
tiger_data = tiger_data[tiger_data['id'].progress_apply(lambda x: is_valid_sid(x))]
2.9 如何多线程并行apply并显示进度条
先安装
pip install pandarallel
然后使用很简单:
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
# df.apply(func)
df.parallel_apply(func)
2.10 如何拼接合并两个DataFrame
data = pd.concat([data_fupan, data_nofupan])
2.11 如何对两个DataFrame根据某字段做join
merged_pd1 = pd.merge(df_a, df_b, on=['statusId'])
# 如果想继续跟其他表做join,就继续这么干
merged_pd1 = pd.merge(merged_pd1, df_c, on=['statusId'])
2.12 如何由其他几列计算得到新的一列
df["prob"]=df[["title","text"]].apply(lambda x: get_prob(x["title"], x["text"]), axis=1)
三、高级用法
3.1 如何统计分数的区间分布
bins = [0, 50, 100, 500, 1000000]
cut = pd.cut(data['length'], bins, labels=["超短(0-50)", "短(50-100)", "长(100-500)", "超长(500+)"])
print(pd.value_counts(cut, normalize=True).sort_index())
例如,下面对文本长度和股票个数进行分桶统计分析
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
data['length'] = data['text'].parallel_apply(lambda x: len(x))
data['length'].value_counts(normalize=True).sort_index()
pd.set_option('display.float_format', '{:.4f}%'.format)
data['stock_num'].value_counts(normalize=True).sort_index()
bins = [0, 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 1000]
cut = pd.cut(data['stock_num'], bins)
print(pd.value_counts(cut, normalize=True))
3.2 如何将某个表中某列不在另一个表的某列的那些行抽取出来
例如下面是fupan_df这个表id列不在test_df的id列的那些行抽取出来
fupan_df[ ~ fupan_df['id'].isin(test_df['id']) ]
# 如果你发现这个方法没有奏效,那么有可能是id前后有空格,或者两者id类型不一致,例如一个是int型,一个是string类型
另一种效率更低的写法:
fupan_df_v2 = fupan_df[fupan_df["id"].apply(lambda x :x not in test_df["id"].values)]
3.3 统计某一列中各个值的出现次数
print(df_5["相关性"].value_counts())
高相关 9447
低相关 6327
不相关 1199
Name: 股票相关性, dtype: int64
如果要统计百分比,就用如下方法:
pd.set_option('display.float_format', '{:.4f}%'.format)
data['stock_num'].value_counts(normalize=True).sort_index()
df1['result'].value_counts(normalize=True).sort_values(ascending=False)
3.4 如何快速筛选出满足某种条件的行
#快速筛选出长度大于某个值的所有行
df[df['a'].str.len() > 100]
#如果有多个条件,可以用&来表示and操作,|来表示或操作,例如下面是筛查出股票数量>5,且文本长度大于50的那些行
train_df[(train_df['stocks_num'] > 5) & (train_df['text'].str.len() > 50)].shape
#快速筛选出股票名称在预先定义好的训练集合train_set中的所有行
train_df=df[df['stock_name'].isin(train_set)]
3.5 对某列进行分组编号
假设我们有一个表,里面有id列和user_id列,其中id是用户发过的帖子编号。那么下面的代码意思就是:
增加一列,列名为row_number,它会对同一个用户user_id下的id那列进行编号
df['row_number'] = df['id'].groupby(df['user_id']).rank(ascending=0,method='first')
3.6 如何构建DataFrame
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
运行结果:
Name Age
0 Alex 10
1 Bob 12
2 Clarke 13
# 使用字典组成的列表创建
# 列表对应的是第一维,即行,字典为同一行不同列元素
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
运行结果:
a b c
0 1 2 NaN
1 5 10 20.0
3.7 数值序列描述性统计
#返回的df_len_a本身也是个pandas.core.series.Series数值化序列数据
df_len_a = df['a'].str.len()
df_len_a.min() #所有值中的最小值
df_len_a.max() #所有值中的最大值
df_len_a.mean() #所有值的平均值
df_len_a.median() #所有值的中位数
df_len_a.std() #值的标准偏差
df_len_a.count() #非空观测数量
df_len_a.sum() #所有值之和
df_len_a.abs() #绝对值
df_len_a.cumsum() #累计总和
3.8 将数据归一化到0~1
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data = {
'date': ['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04', '2022-01-05'],
'open': [10, 11, 12, 13, 14],
'high': [15, 14, 13, 12, 11],
'low': [5, 6, 7, 8, 5],
'close': [13, 12, 11, 10, 10],
'volume': [1000, 2000, 1500, 3000, 2500]
}
df = pd.DataFrame(data)
# MinMaxScaler有一个重要参数,feature_range,控制我们希望把数据压缩到的范围,默认是[0,1]
scaler = MinMaxScaler(feature_range=(0, 1))
df['close_normalized'] = scaler.fit_transform(df['close'].values.reshape(-1,1))
计算公式其实就是:
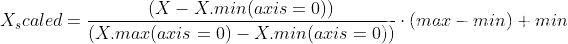 其中,X.min代表X列最小值,X.max代表X列中的最大值,max和min是feature_range指定的参数,在上面的代码例子中也即max=1,min=0。
其中,X.min代表X列最小值,X.max代表X列中的最大值,max和min是feature_range指定的参数,在上面的代码例子中也即max=1,min=0。
3.9 如何将归一化后的数据复原
X1=scaler.inverse_transform(X_scaled)是将标准化后的数据转换为原始数据。
from sklearn import preprocessing
import numpy as np
X = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
scaler= preprocessing.MinMaxScaler(feature_range=(0, 1)).fit(X)
X_scaled = scaler.transform(X)
print(X)
print(X_scaled)
X1=scaler.inverse_transform(X_scaled)
print(X1)
print(X1[0, -1])
3.10 如何数据增广
例如根据某股票的相似股票,想将数据中的每一行都扩增为n行
%%time
from copy import deepcopy
data = []
for index, row in train_df.iterrows():
for i in range(0, len(row['similar_stocks'])):
item = deepcopy(row)
stock_name = row['similar_stocks'][i]
item['stock_name'] = stock_name
data.append(item)
augment_df = pd.DataFrame(data)
3.11 矩阵中的‘逗号跟冒号’
import numpy as np
X=np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16],[17,18,19,20]])
print(X)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]
[17 18 19 20]]
X[:,0]就是取矩阵X的所有行的第0列的元素,X[:,1] 就是取所有行的第1列的元素。
X[:, m:n]即取矩阵X的所有行中的的第m到n-1列数据,含左不含右。
X[0,:]就是取矩阵X的第0行的所有元素
X[1,:]取矩阵X的第一行的所有元素。
3.12 计算振幅、涨跌幅
假定你有一个如下所示的股票交易数据:
可以如下计算股价振幅和涨跌幅:
df['PreClose'] = df['Close'].shift(1) # 使用PreClose字段保存上一天的收盘价格
df['amplitude'] = df[['High', 'Low', 'PreClose']].apply(lambda x: abs(x['High'] - x['Low'])/x['PreClose'], axis=1) # 股票振幅=(当期最高价-当期最低价)/上期收盘价×100%
df['volume_change'] = df['Volume'].diff() # 使用diff函数计算交易量的变化
df['volume_change_rate'] = df['Volume'].pct_change() # 使用pct_change函数计算当前元素和先前元素之间变化的比值,公式是 (current value - previsou value)/ previsou value
df['close_change_rate'] = df['Close'].pct_change() # 使用pct_change函数计算收盘价的涨跌幅
3.13 如何查看series的值分布情况
def print_distribution(series: pd.core.series.Series, split_num=5)->str:
''' 方便查看series的分布 '''
min_value = series.min()
max_value = series.max()
step_size = (max_value - min_value) // (split_num - 1)
bins = np.arange(min_value, max_value + step_size, step_size)
labels = []
for i in range(0, len(bins) - 1):
labels.append(str(bins[i]) + '~' + str(bins[i + 1]))
cut = pd.cut(series, bins, labels=labels)
s1 = pd.value_counts(cut)
s2 = pd.value_counts(cut, normalize=True).sort_index().mul(100).round(2).astype(str) + '%'
s = pd.concat([s1, s2], axis=1)
s.columns = ['数量', '占比']
return s
3.14 如何求最近后面几行的最大值
# 例如求出后面最近4天价格中的最大值
df['MAX'] = df['PRICE'].rolling(4).max().shift(-3)
# 例如求出后面最近4天价格中(但不包括今天这行)的最大值,
df['MAX1'] = df['PRICE'].rolling(3, min_periods=1).max().shift(-3)
print (df)
PRICE MAX MAX1
0 1.095806 1.095806 1.046494
1 1.046494 1.046494 1.019099
2 1.019099 1.019099 1.019099
3 1.002662 1.035535 1.035535
4 1.019099 1.035535 1.035535
5 1.008142 1.035535 1.035535
6 1.035535 1.035535 1.019099
7 1.019099 1.019099 0.986225
8 0.986225 0.986225 0.964309
9 0.964309 0.964309 0.964309
10 0.953351 0.975267 0.975267
11 0.964309 0.980745 0.980745
12 0.964309 1.030057 1.030057
13 0.975267 1.068410 1.068410
14 0.980745 1.117722 1.117722
15 1.030057 1.145117 1.145117
16 1.068410 1.145117 1.145117
17 1.117722 NaN NaN
18 1.145117 NaN NaN
19 1.139638 NaN
3.15 如何批量读取某文件夹下的所有csv文件
import pandas as pd
import numpy as np
import glob,os
path = r'/data/path/'
file = glob.glob(os.path.join(path, "*"))
dl = []
for f in file:
dl.append(pd.read_csv(f, sep='x01')) # 假定所有csv文件的分隔符都是x01
df = pd.concat(dl)
3.16 如何合并重复的行,并对其他列执行求和等操作
假定原始数据如下:
names count subject
A 2 physics
A 3 physics
A 3 chemistry
B 2 literature
B 3 literature
B 1 economics
C 3 physics
C 2 chemistry
执行如下操作后,就可以合并重复的行
df2 = df.groupby(["names","subject"], sort=False, as_index=False).agg({"count":"sum"})
print (df2)
names subject count
0 A physics 5
1 A chemistry 3
2 B literature 5
3 B economics 1
4 C physics 3
5 C chemistry 2
欢迎大家访问类chatGPT网站: 智聊对话机器人
- 参考文献
- https://blog.csdn.net/weixin_43557139/article/details/110944596
- https://blog.csdn.net/aaa_aaa1sdf/article/details/77414387
- https://blog.csdn.net/qq_22238533/article/details/71598533
- https://blog.csdn.net/u014636245/article/details/104202889
- https://blog.csdn.net/qq_35318838/article/details/102720553
- http://www.4k8k.xyz/article/Bigboss7/118597351
- https://blog.csdn.net/qq_22238533/article/details/72395564 (“对某列进行分组编号” 这个话题参考自这里)
- http://www.360doc.com/content/22/0708/16/52334415_1039101324.shtml
- https://blog.csdn.net/tlqwanttolearnit/article/details/123821022
- https://blog.csdn.net/qq_41404557/article/details/125898404
- https://blog.csdn.net/weixin_40683253/article/details/81508321
- https://blog.csdn.net/Strive_0902/article/details/78225691
- https://blog.csdn.net/qq_34840129/article/details/86257790
- https://stackoverflow.com/questions/67885719/pandas-merge-and-sum-nearly-duplicate-rows
最后
以上就是微笑心情最近收集整理的关于pandas常用操作指南的全部内容,更多相关pandas常用操作指南内容请搜索靠谱客的其他文章。








发表评论 取消回复