需求:目前有一份Excel表格,里面有姓名和英文名两列数据。需要根据这些数据生成200张左右的荣誉证书,放在一个pptx文件中。
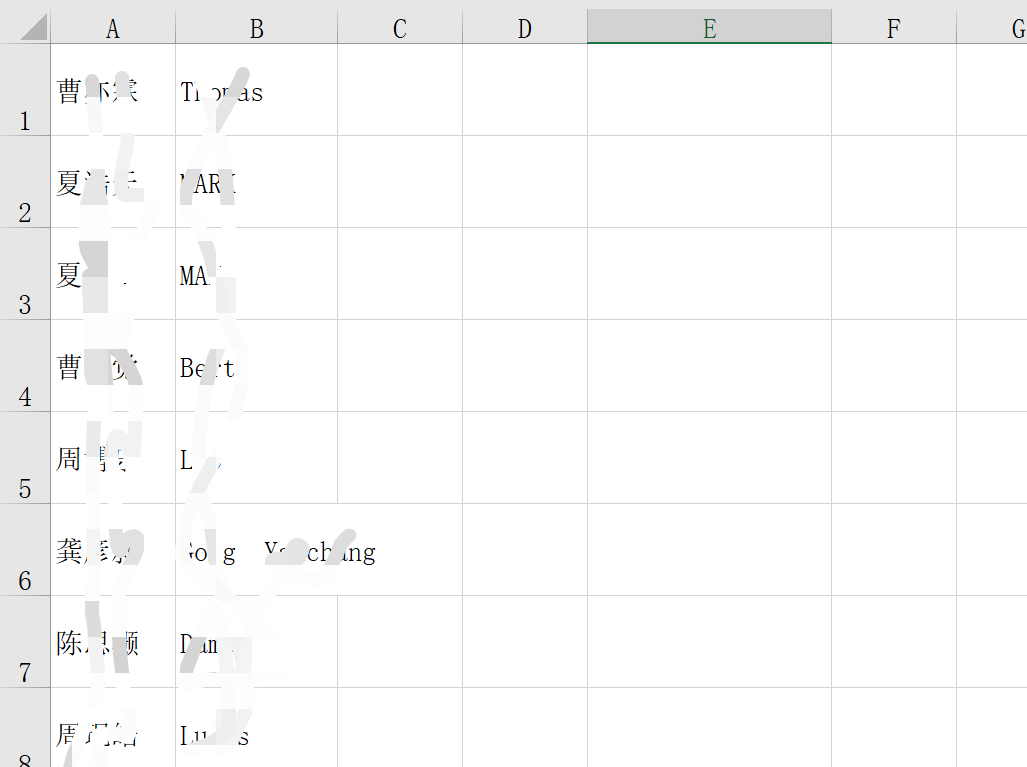
表格部分截图:
ppt模板截图:
(上方占位符写中文名,下方写英文名)

一、基础知识
1.ppt的母版
首先新建一个pptx文件。
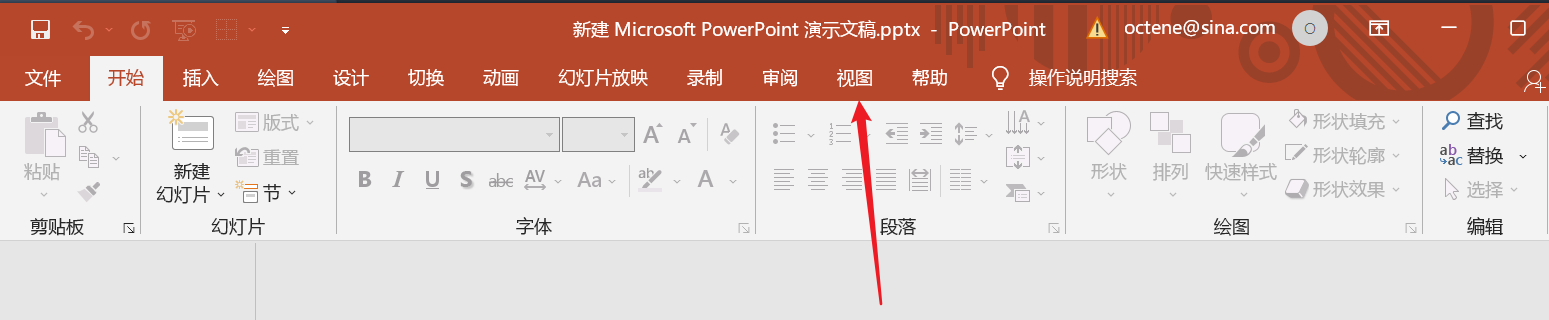
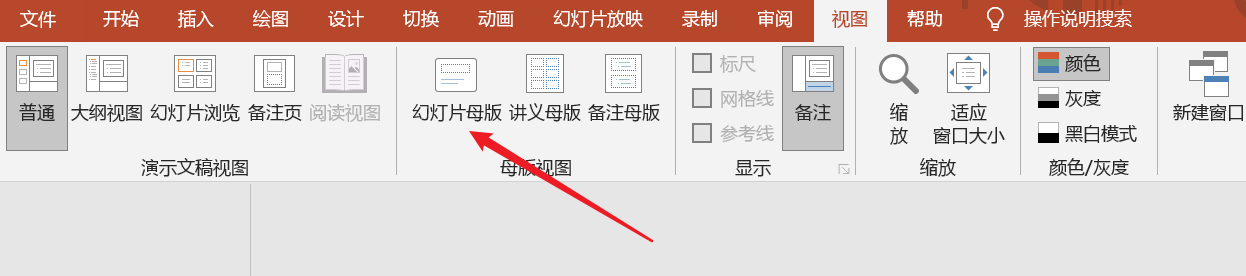
点击“视图->幻灯片母版”
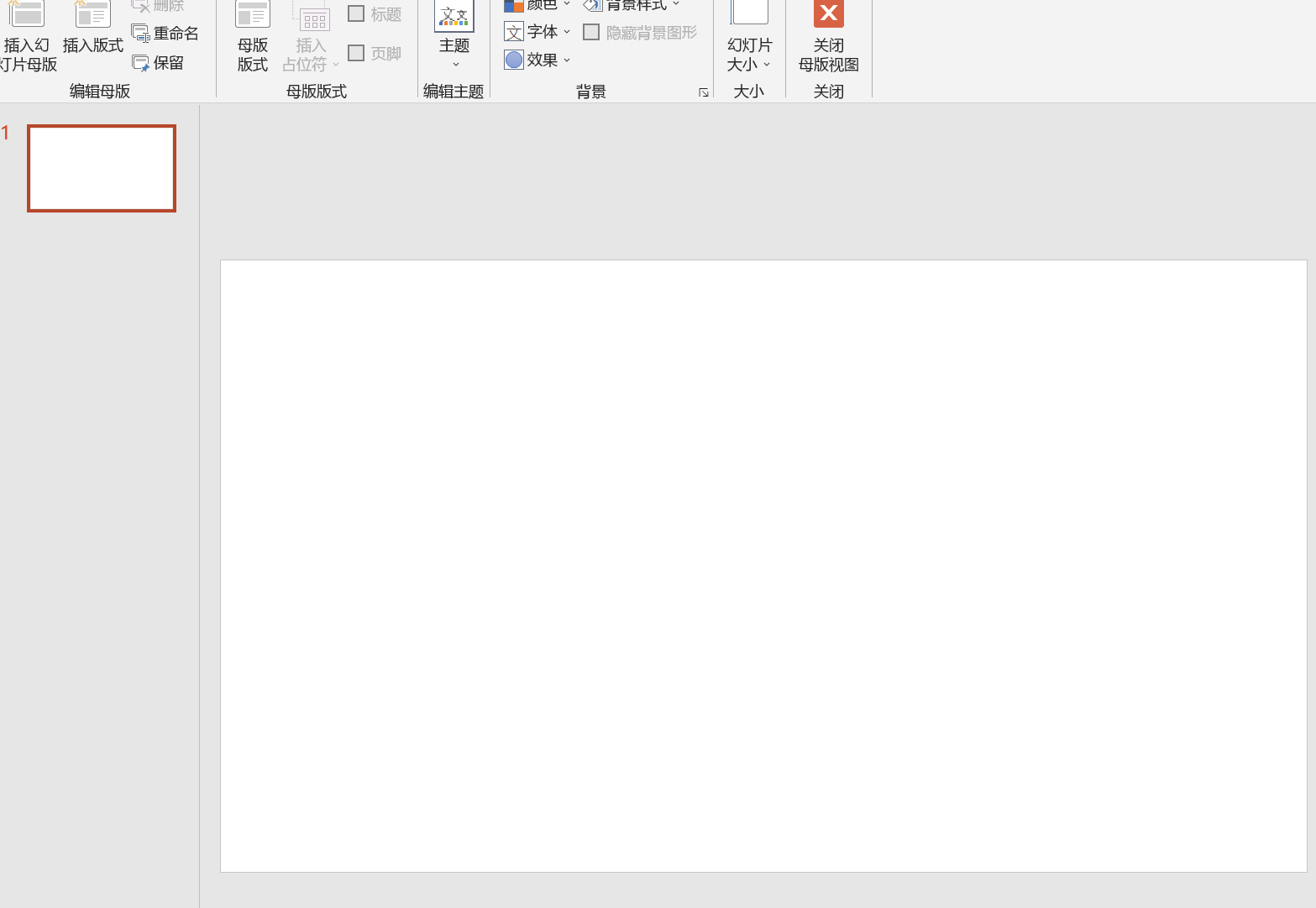
选择第一张底下的所有版式,按delete键删除,选择第一张内部的所有内容,删除。最后应该是这样,干干净净的:
点击:插入版式,删掉自带的标题文本框
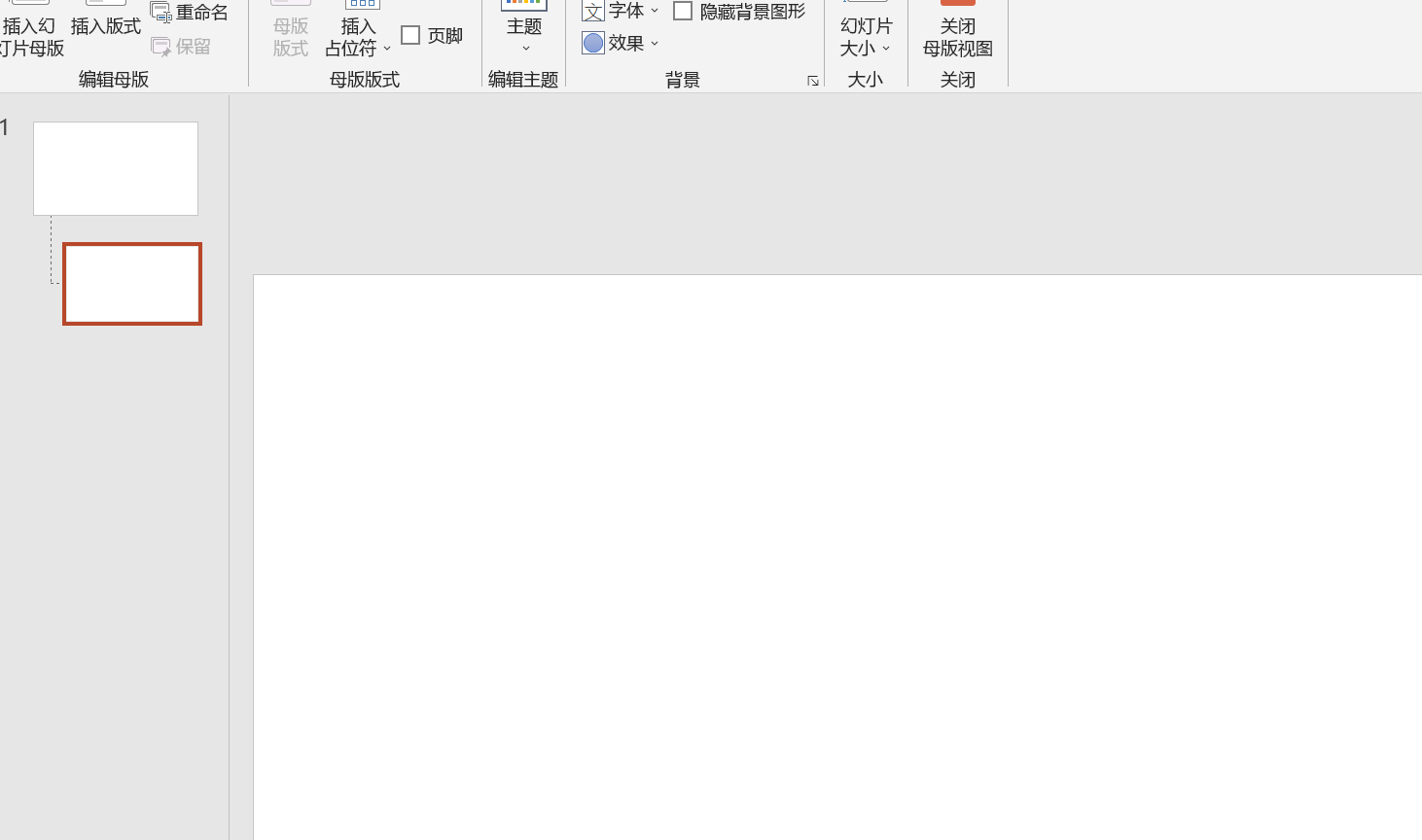
为简明起见,这里只插入两个占位符,分别表示中文名和英文名。有需要者可以加入更多的占位符,也可以自行调整背景、字体等。
插入占位符的时候,记得删除里面的所有内容。按两次退格键即可删干净,最后,占位符里面会显示“对象”,这是正常的。
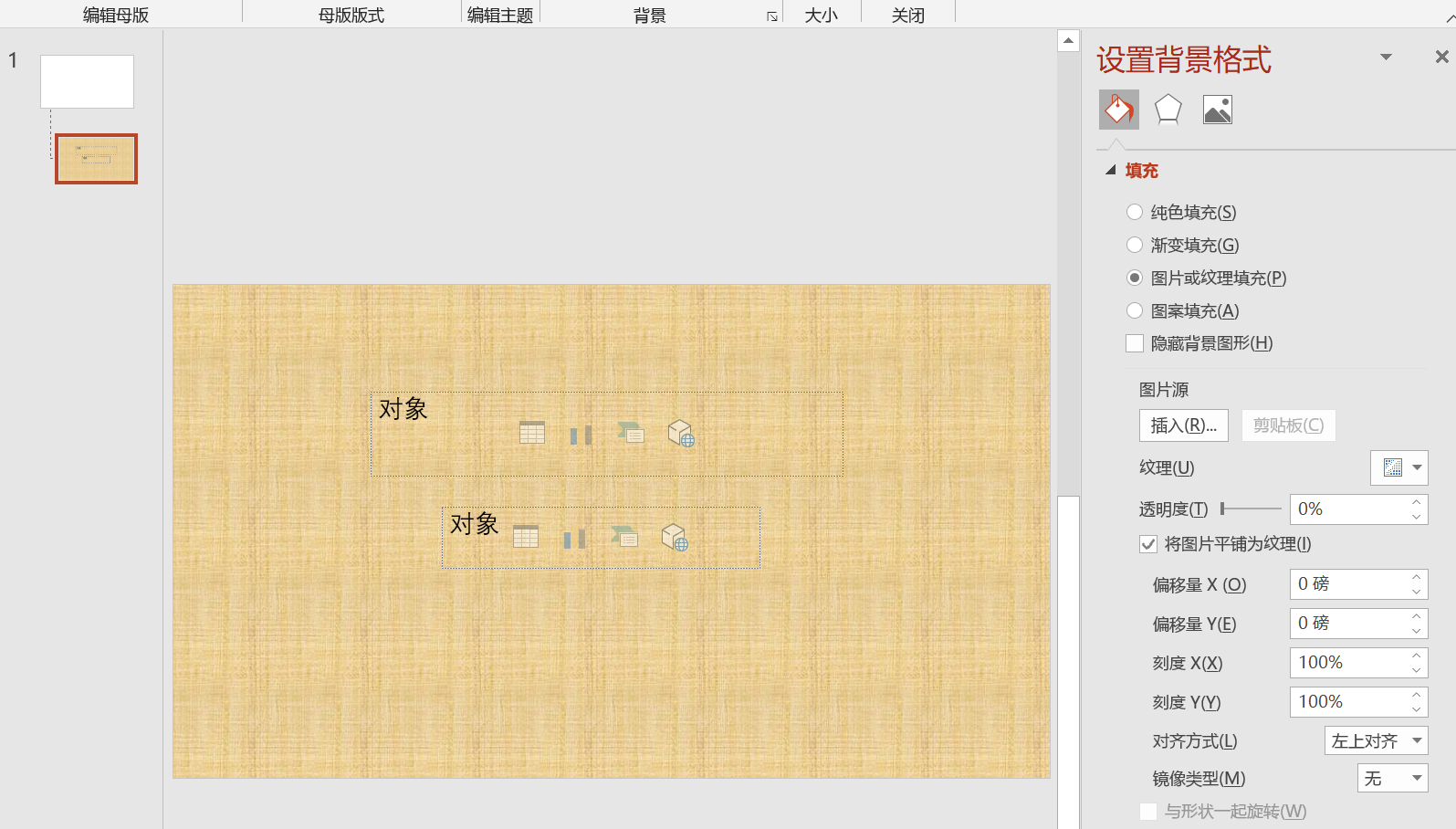
按ctrl+s保存并退出。
2.必要的python知识
python当前的最新版本是3.10,但python存在严重的向下不兼容问题,因此不推荐使用太高的版本。
python的选择结构:
score=70
if(score>90):
print('优秀')
elif(score>60):
print('及格')
else:
print('不及格')python的循环结构:
for i in range(0,4):
print(i)
# 结果
# 0
# 1
# 2
# 3括号是左闭右开的,不包括右边界。
python的列表:用[]定义,用下标访问。列表相当于Java、C++的数组,下标以0开始。
arr=['Tom',12]
print(arr[0])
print(arr[1])python的字典:用{}定义,用变量名[key]访问。
dict={} # 初始化字典
dict["Tom"]=12 #添加键值对
print(dict["Tom"]) #通过key访问value
#12
#本题中涉及的操作
dict1={}
dict1.setdefault("Tom",[]) # 添加key为"Tom",值为默认值[](一个空数组)的键值对
dict1["Tom"].append(12) #访问到"Tom"对应的数组,为数组添加元素
print(dict1["Tom"])
#[12]二、环境搭建
1.下载python
搜索python 3.6,进入官网下载
等待片刻,出来这个页面,向下滚动,直到看到一个表格:
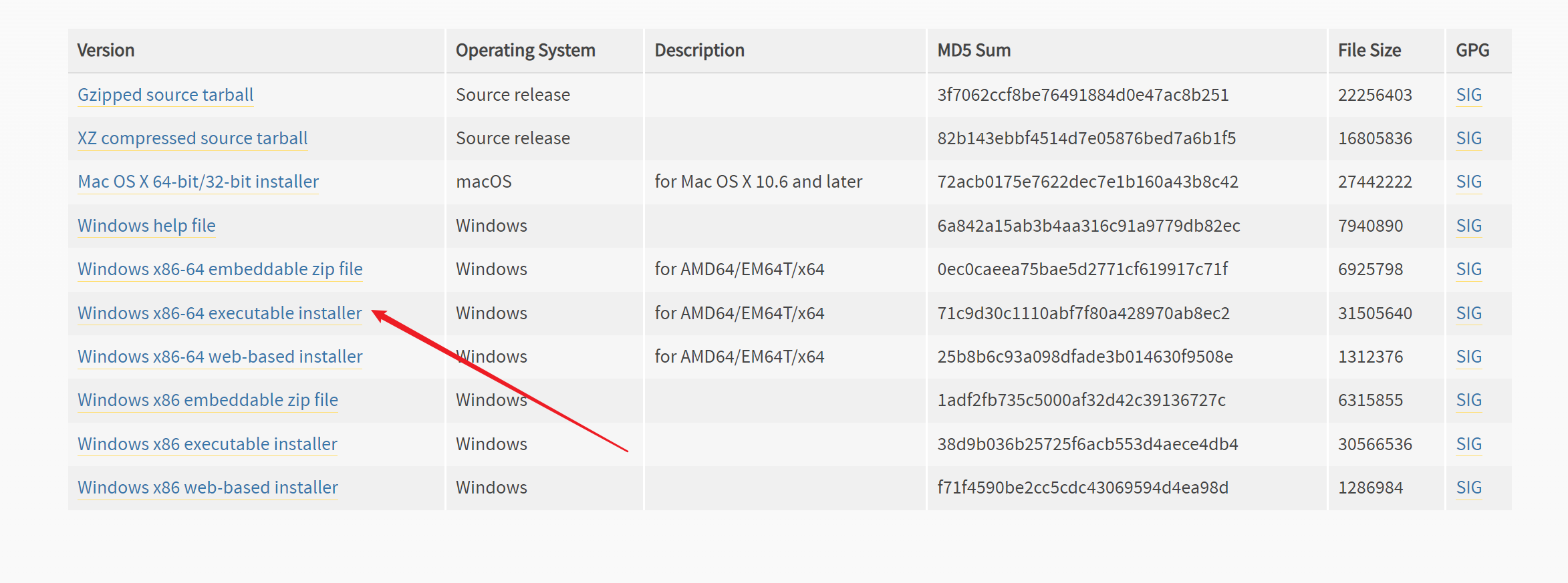 点击,等待下载完成即可。
点击,等待下载完成即可。
双击允许下载好的安装程序。
![]()
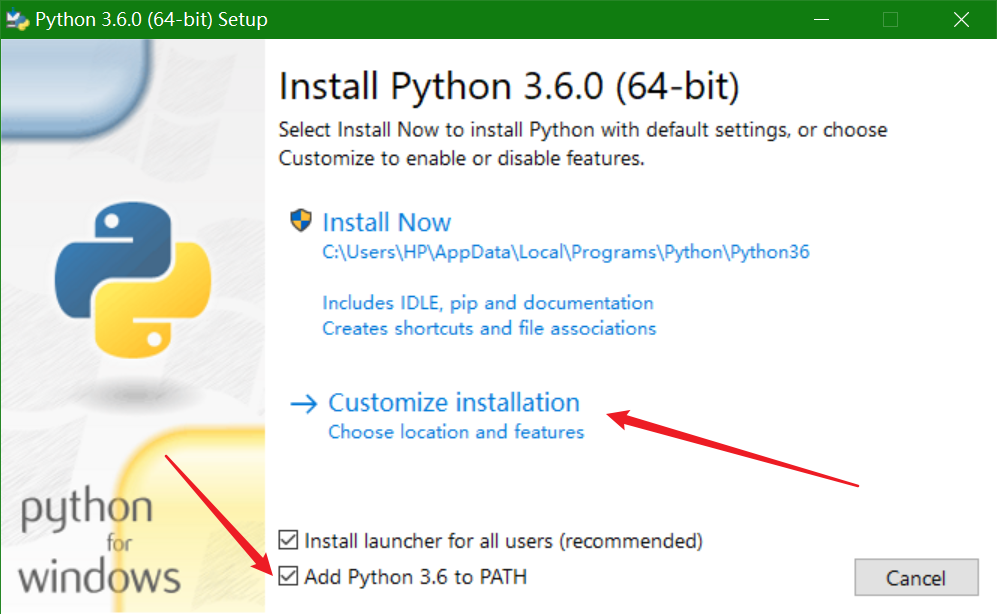
先勾选最下面的框,然后点自定义安装。
点击next
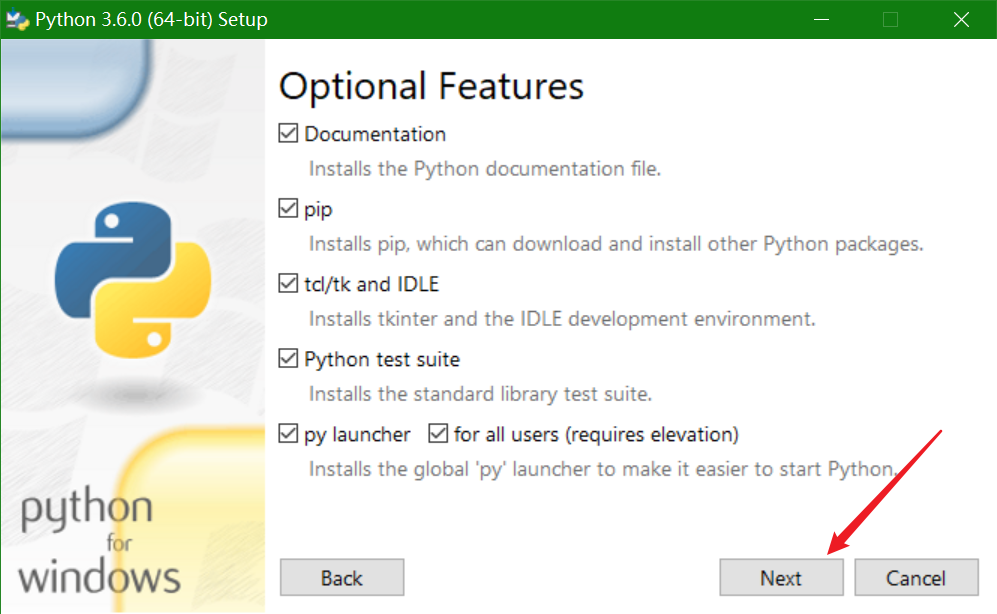
这一步需要自己改一下安装路径,我放在D盘下的python3.6文件夹下。
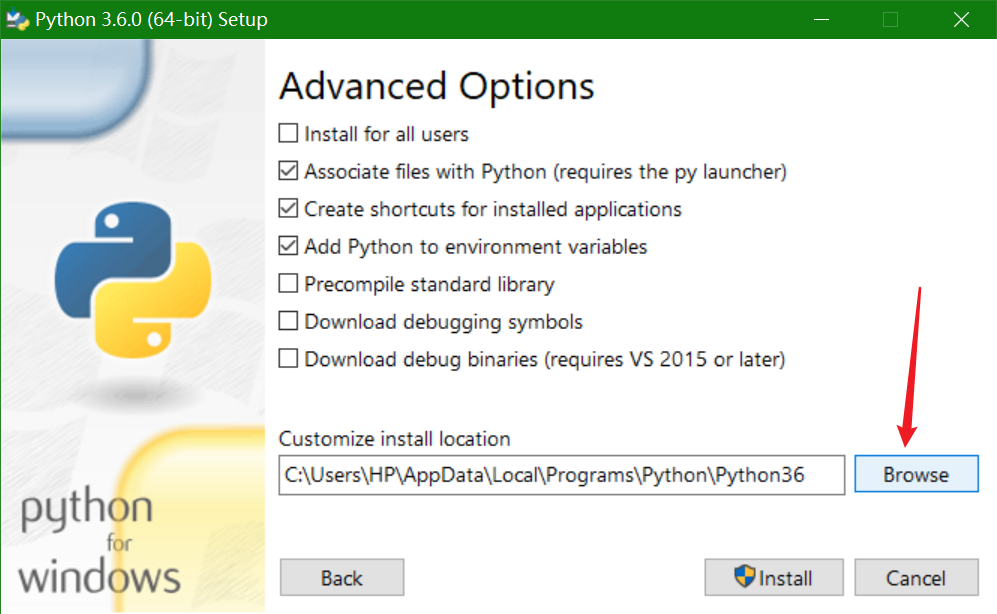
等待安装完成,重启电脑即可。
2.安装pycharm
搜索pycharm,直接点download即可。
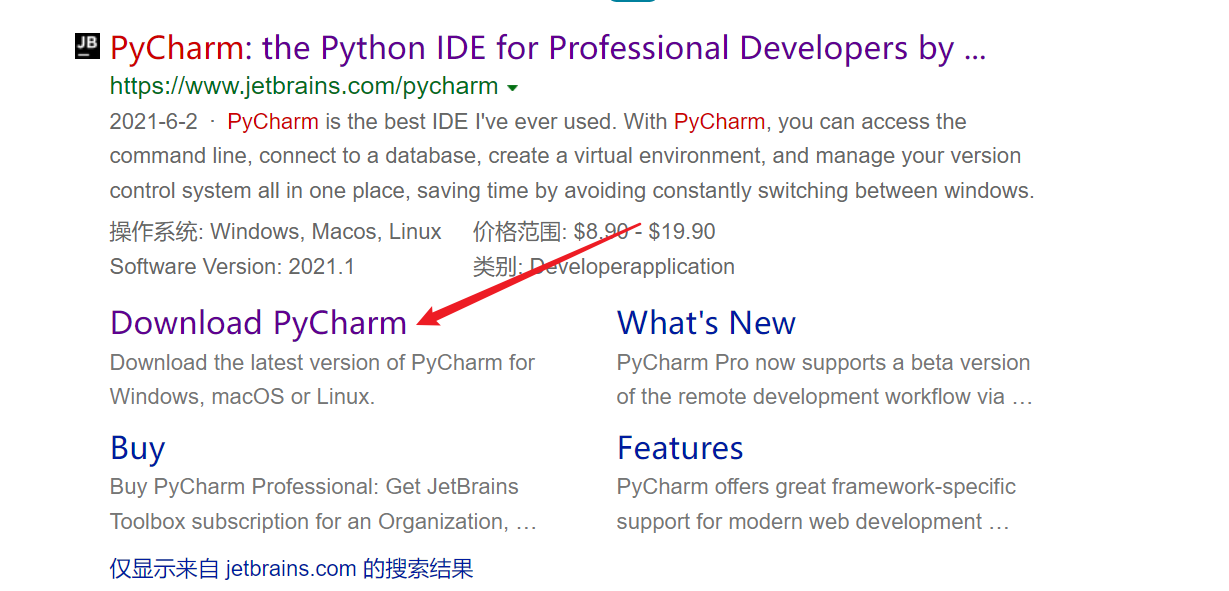
有两个选项,选右边的社区版。
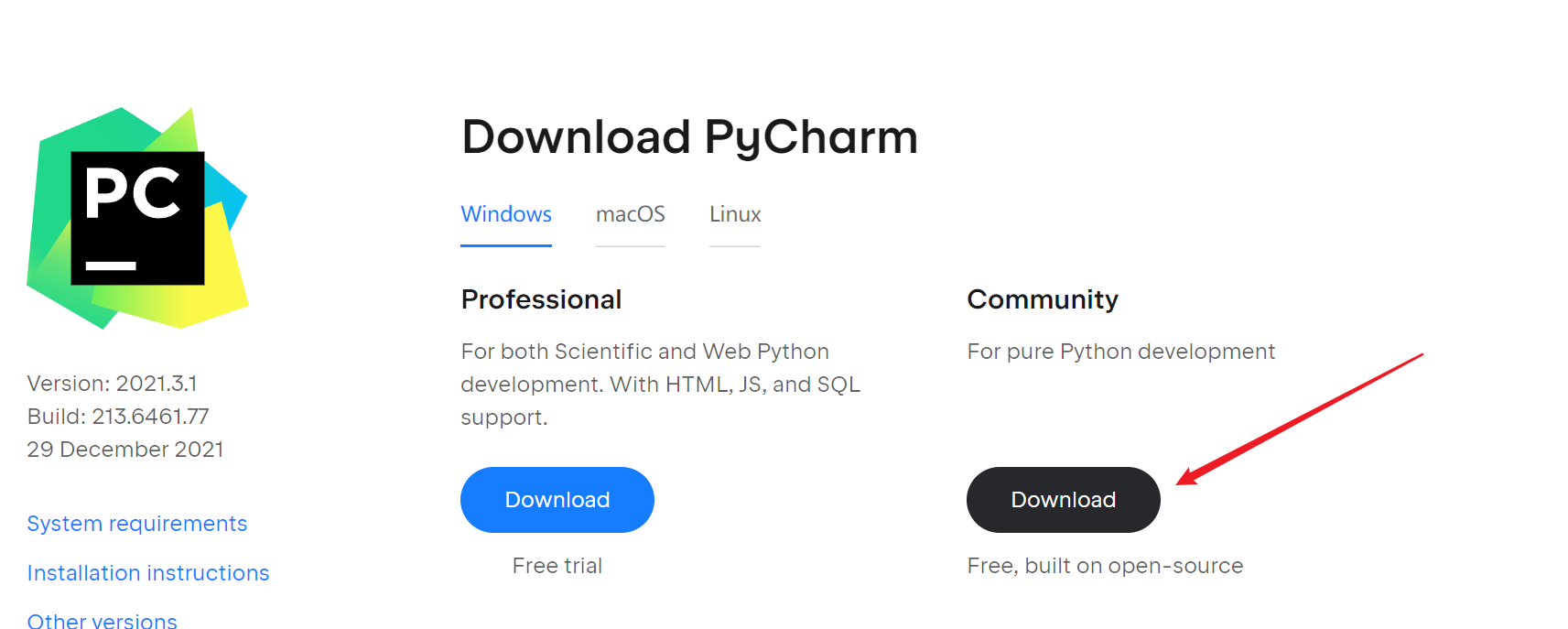
等待下载完成,双击打开安装程序。
![]()
第一步next,然后选择安装路径,这里装在D盘下。
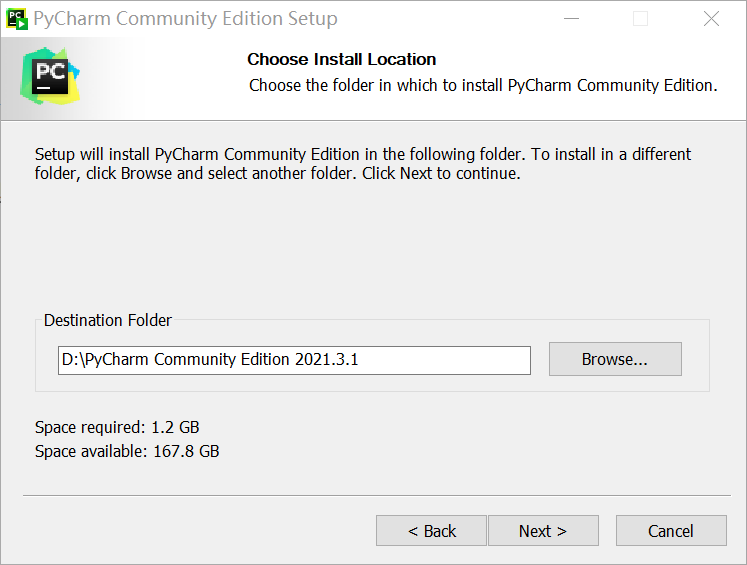
next,全部打勾。
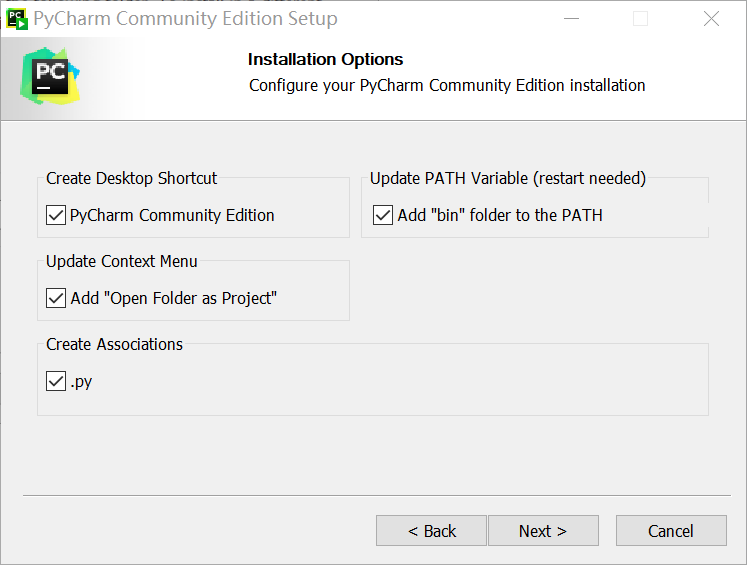
一路next即可,等待安装完成。
3.创建工程
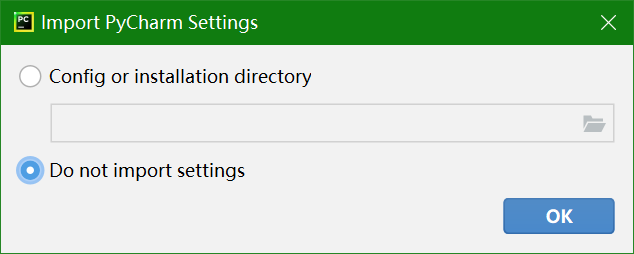
运行pycharm,弹出这个窗口,点OK。
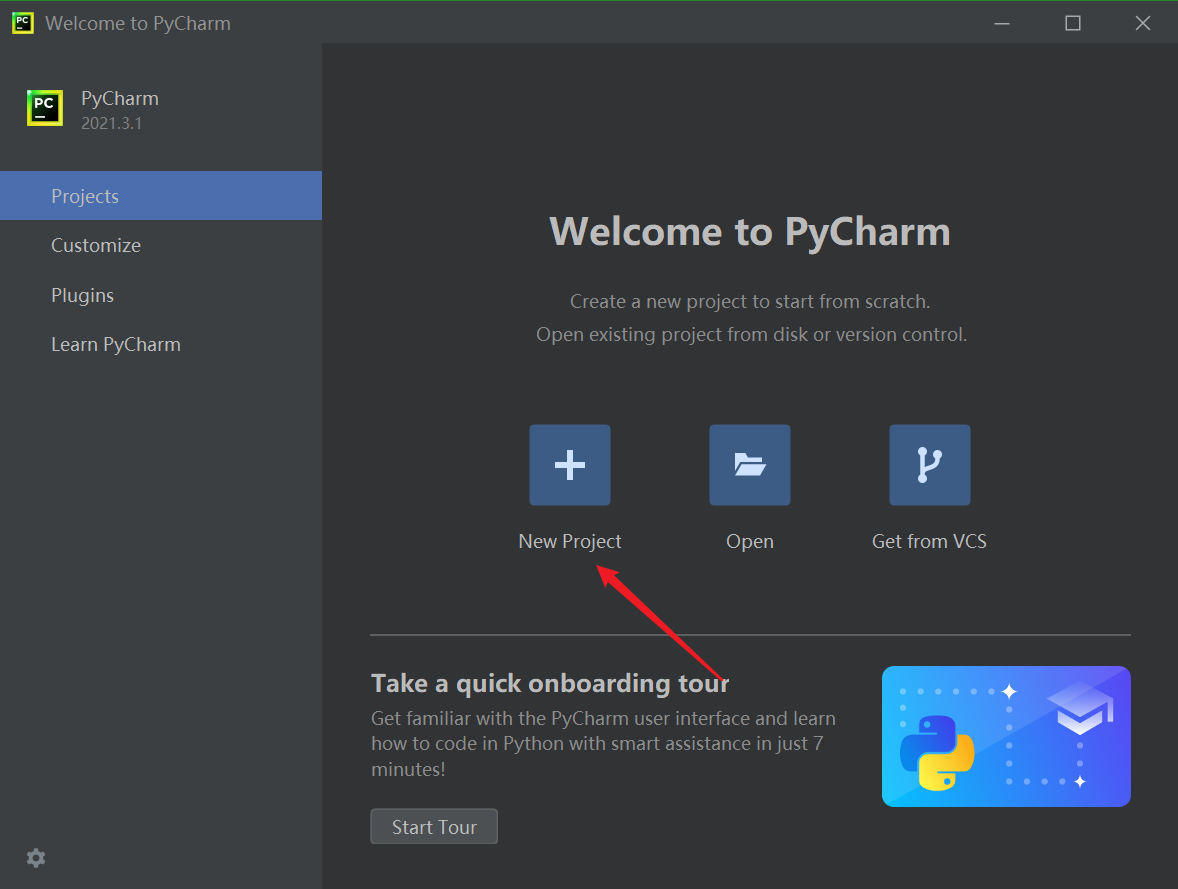
点击new project
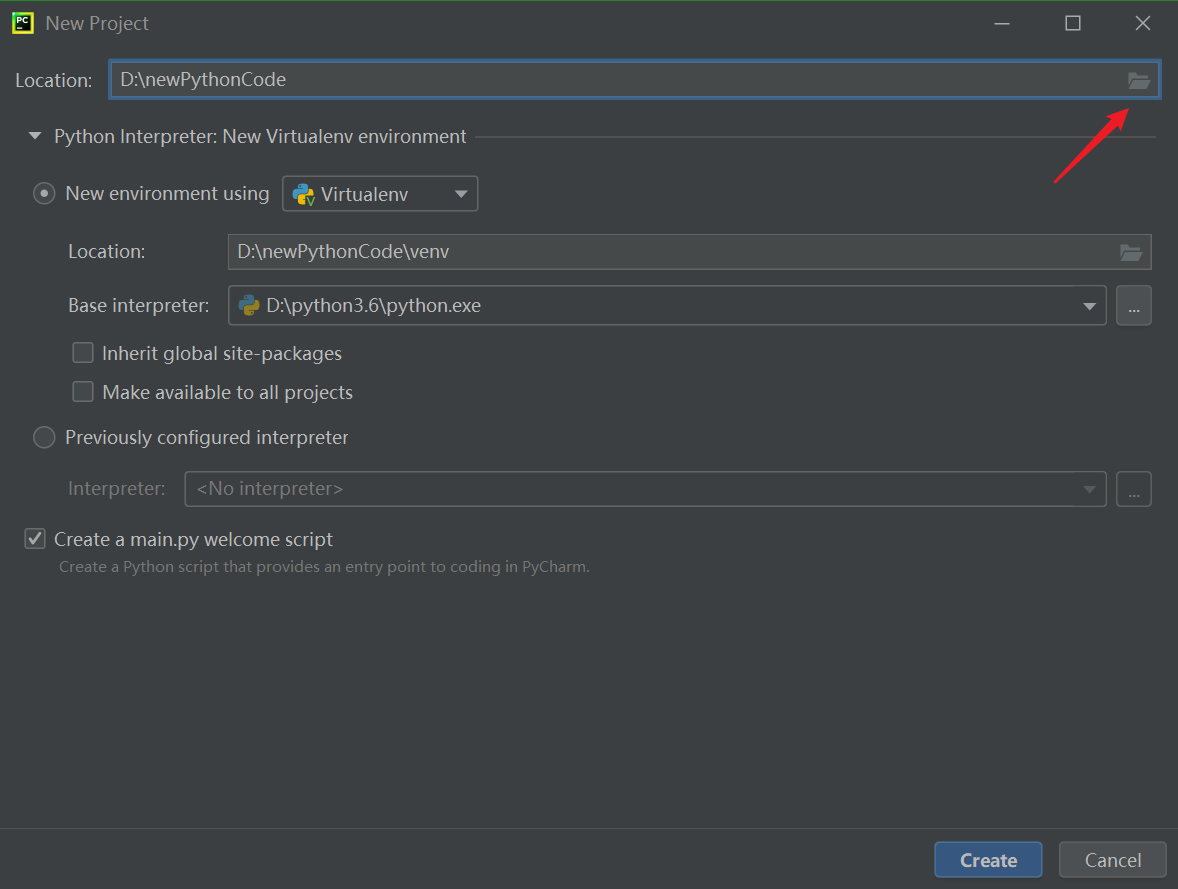
点location右边的小文件夹,修改工程路径。这个路径一定要能方便地找到!
其他的不用修改,因为pycharm已经检测到安装好的python 3.6。
点击create,目前的界面是这样。
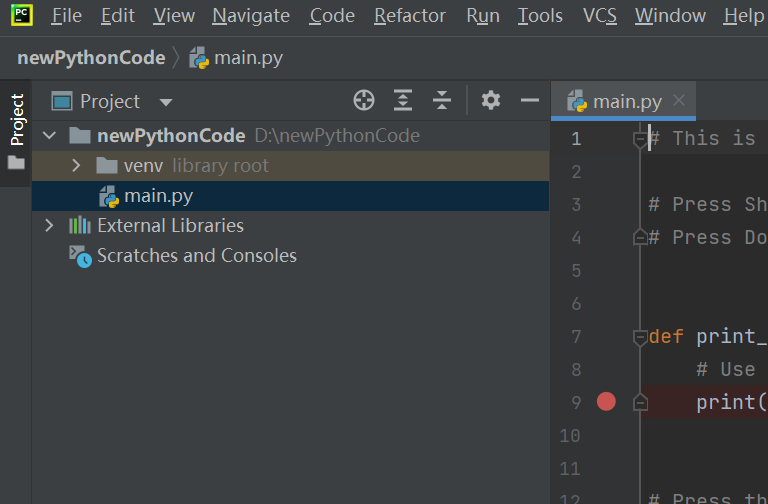
三、测试代码
from pptx import Presentation
prs = Presentation('data模板.pptx')
slide = prs.slides.add_slide(prs.slide_layouts[0]) # 第一个模板的第0个板式
for ph in slide.placeholders: #遍历这页PPT的所有占位符
phf = ph.placeholder_format #获取占位符的格式
print(phf.idx) #打印其ID编号
ph.text = str(phf.idx)# 将编号写入PPT对应的位置中,以便后面一一对应
# 以上读取到占位符的ID方便后面调用
prs.save('data模板-占位符编号.pptx')
from openpyxl import load_workbook
wb = load_workbook("data表格.xlsx")
ws = wb.active
data={}
for row in range(1,ws.max_row+1):
class_id = ws['A' + str(row)].value
name = ws['B' + str(row)].value
data.setdefault(class_id,[])
data[class_id].append(name)
import time
t0=time.time()# 程序开始运行的时间
prs = Presentation('data模板.pptx')
slide_layout = prs.slide_layouts[0] # 调用设置好的母版,因为是母版的第一版式,所以取[0]
for class_id in data:
for name in data[class_id]:
slide = prs.slides.add_slide(slide_layout) #以母版的版式为基础新增一页幻灯片
#往幻灯片中写入内容
slide.placeholders[11].text = class_id #班级
slide.placeholders[12].text = name #名字
prs.save('data总计.pptx')
t1 = time.time()
print('程序用时:',str(round(t1-t0))+'秒。')粘贴以上代码到main.py中,不出意外,会报4个错。这是因为没有安装对应的包导致的。
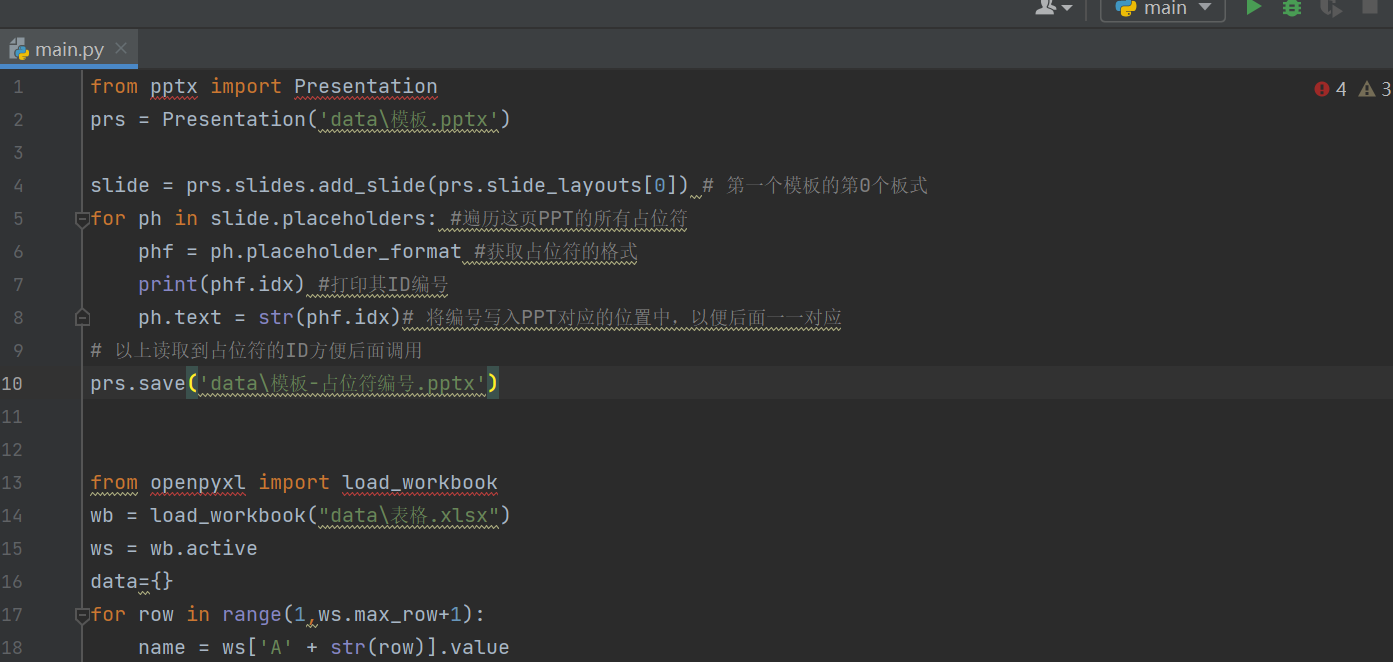
将光标移到openpyxl上,点击安装即可。
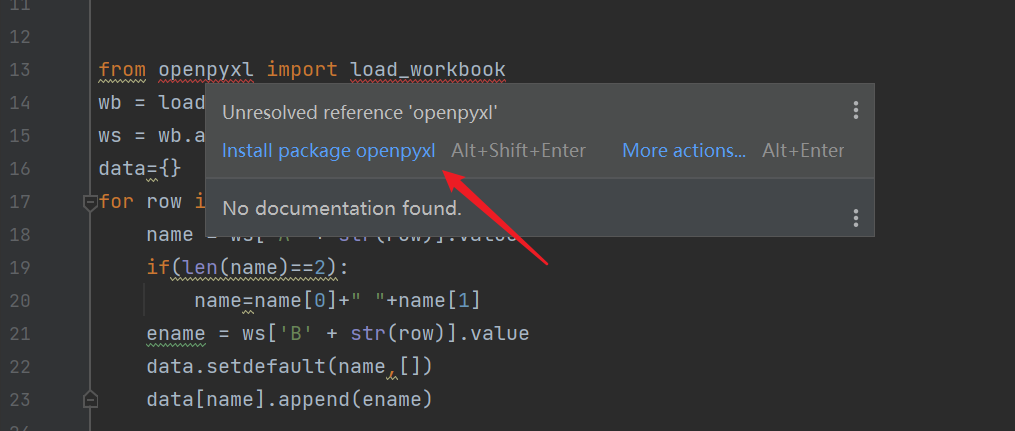
这时,还有两个错误未解决,需要我们手动安装第三方包。
File->Settings
Project:xxx->Python Interpreter
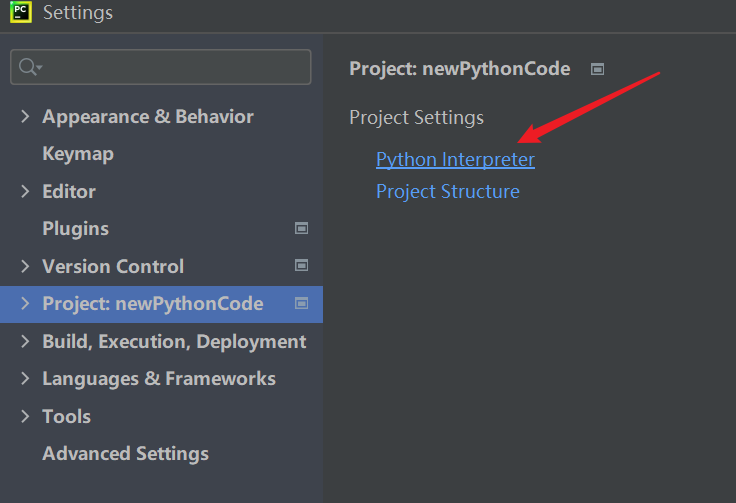
点击加号
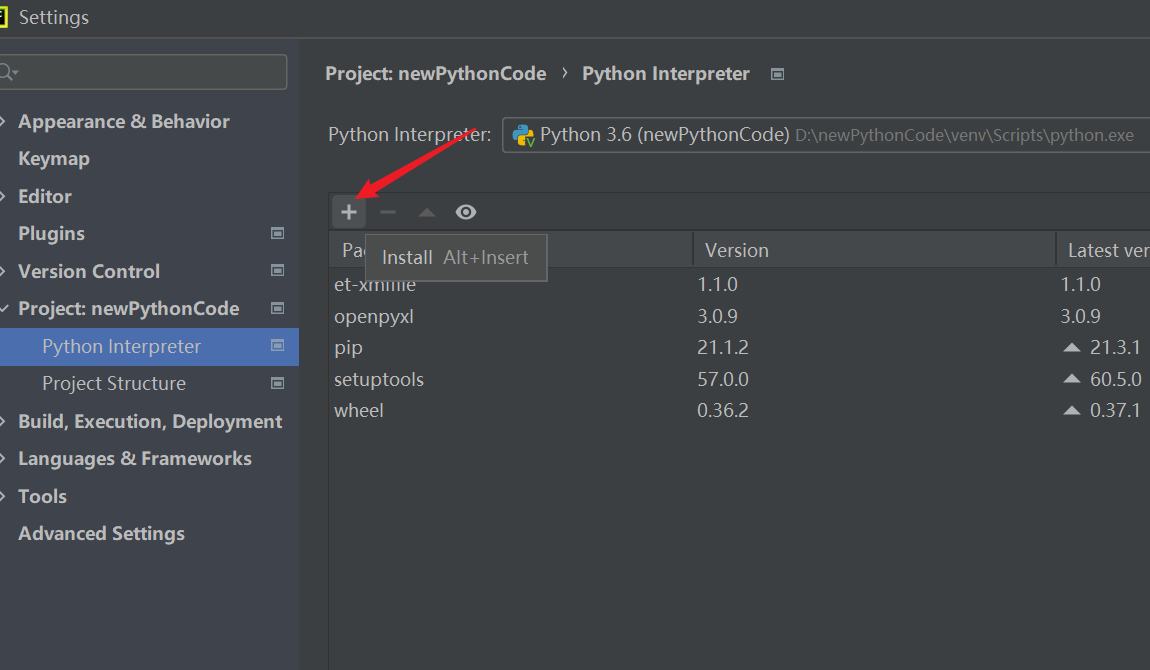
搜索框中输入python-pptx,点击安装,只安装这个包即可。
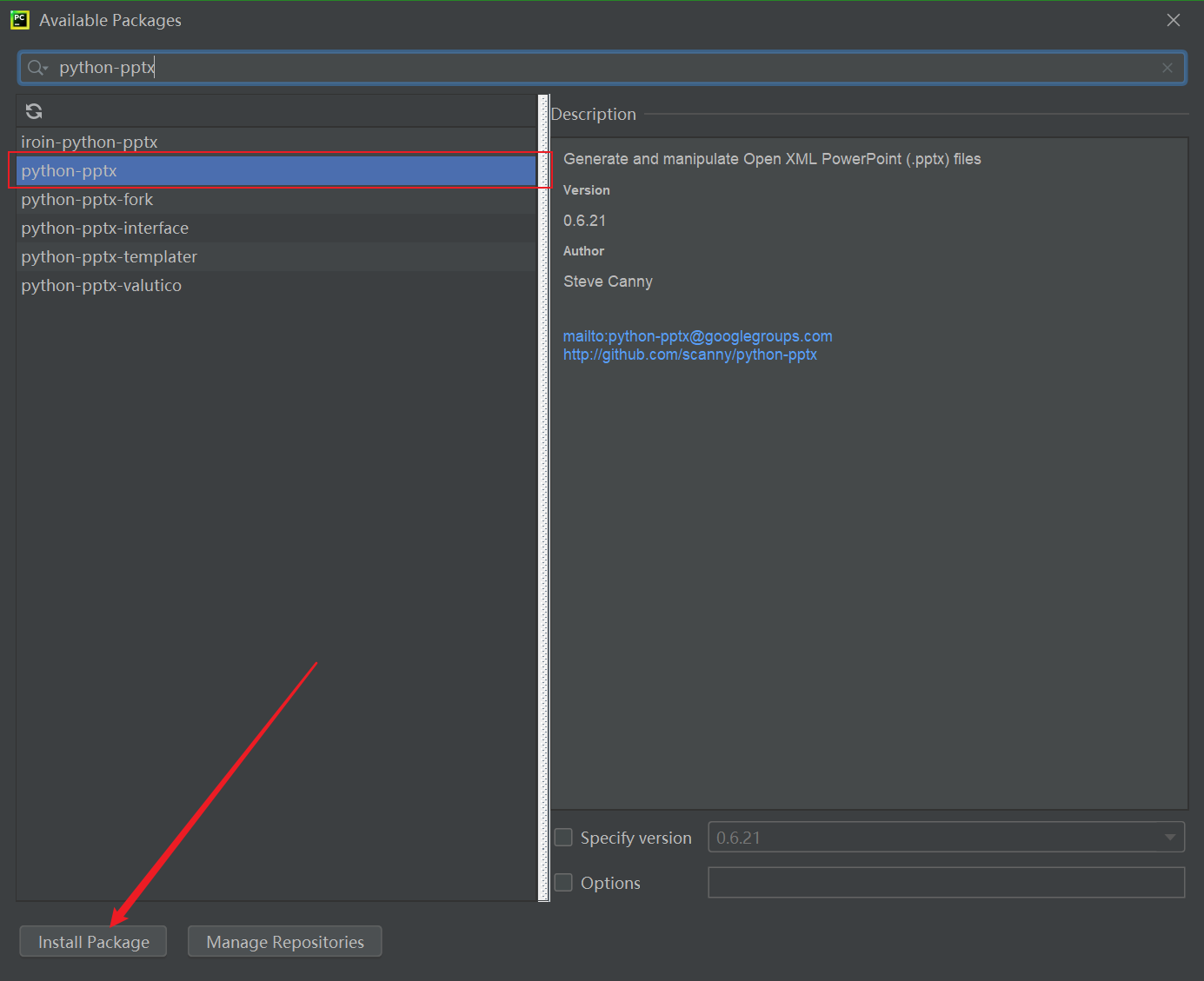
等待片刻,所有错误都应该已经解决。
打开刚刚创建项目的文件夹,新建文件夹,名字为data。
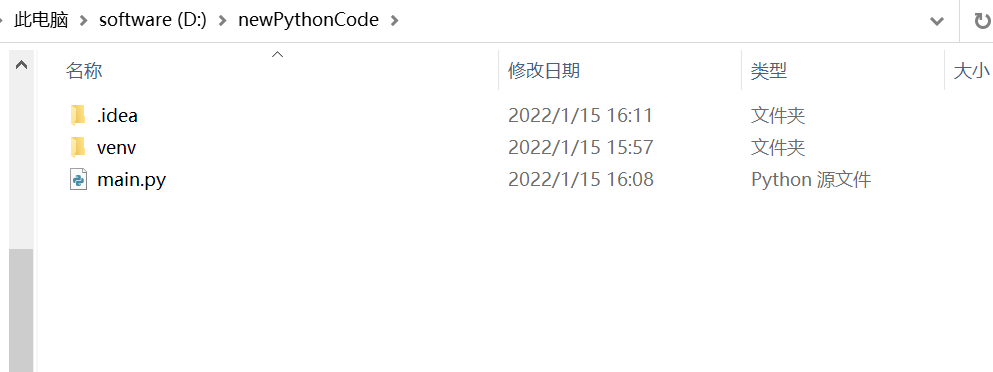
将准备好的模板.pptx、表格.xlsx粘贴到data文件夹里面。
以下内容与占位符原理有关,如果只想运行代码,可以跳过
占位符
先将第10行以下的内容全部注释。注释的方法是:选中第10行以下的内容,然后按ctrl+/
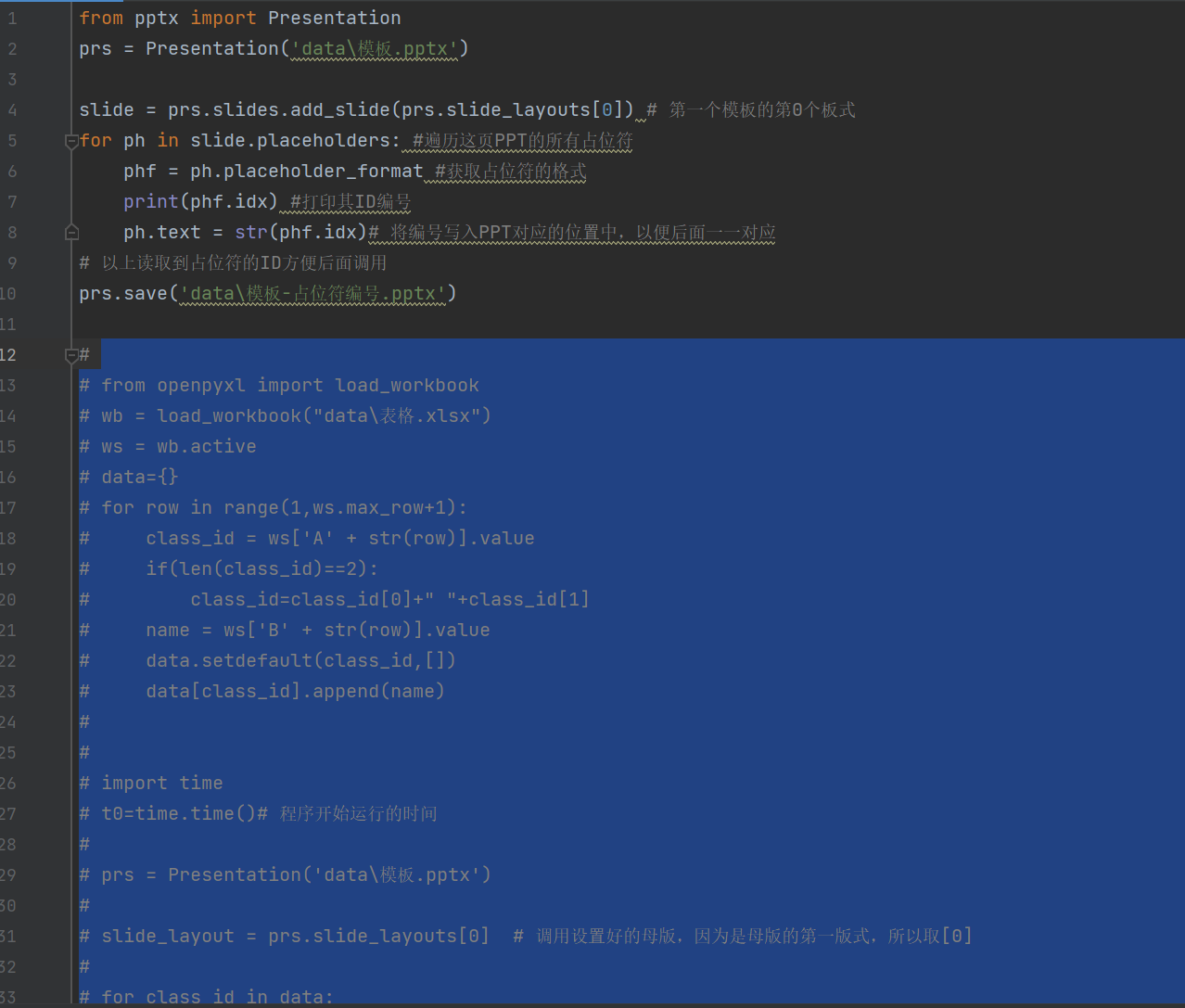
然后在代码窗口中按右键,点击Run 'main'。
回到刚才的data文件夹,打开新生成的模板-占位符编号.pptx
没有看到任何内容,很正常,点击关闭母版视图即可。
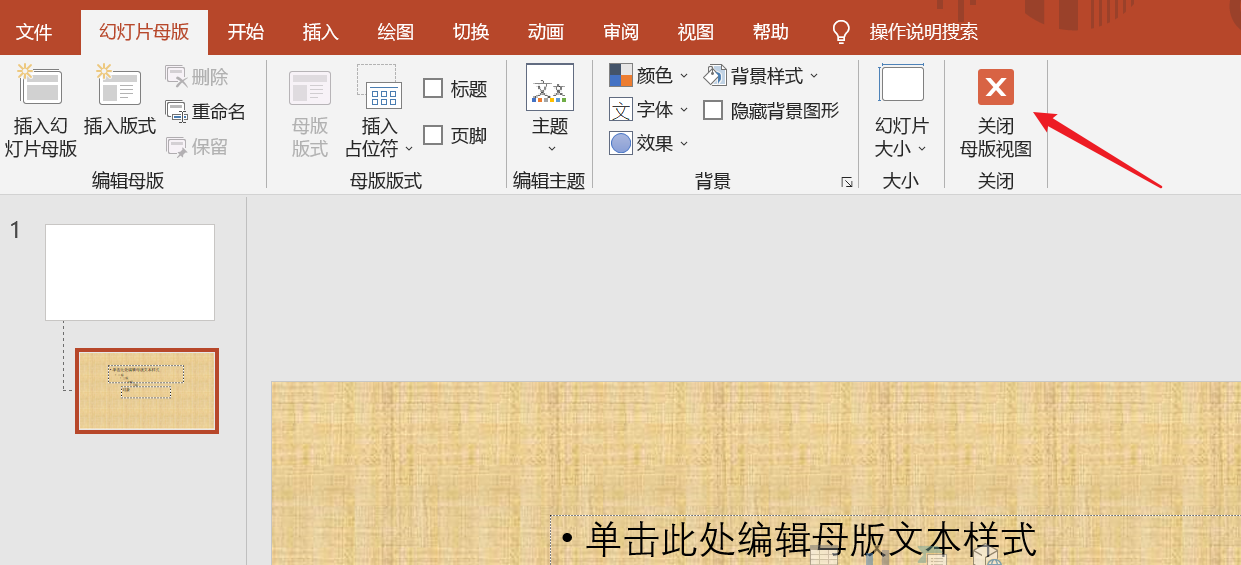

其中的12、11就是占位符编号。用slide.placeholders[占位符编号]即可访问这些占位符。
可以根据这些编号修改源码,控制各个占位符里应写入的文字。
然后,选中第十行以下的区域,按下ctrl+/解除注释。
(接上文)
在代码窗口按右键,点击Run 'main'
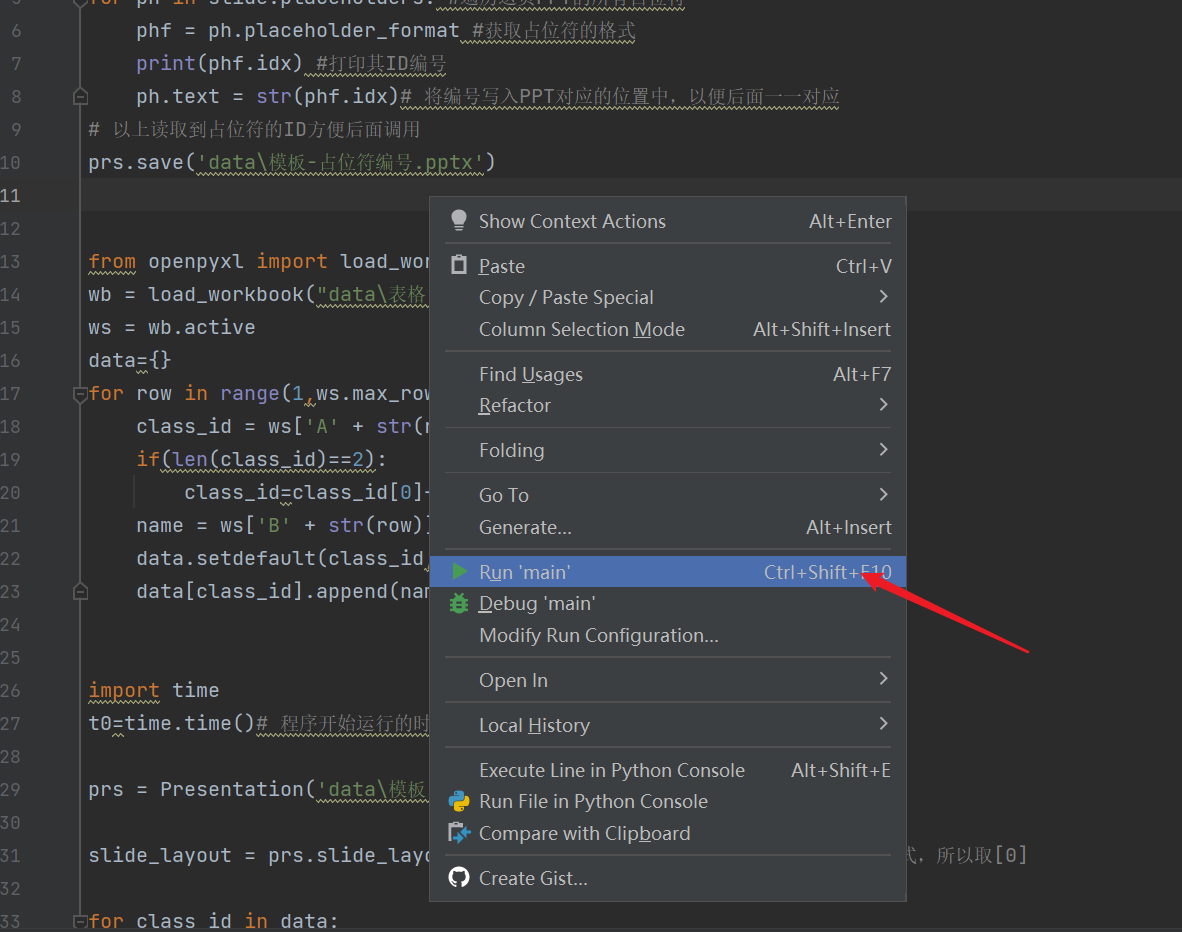
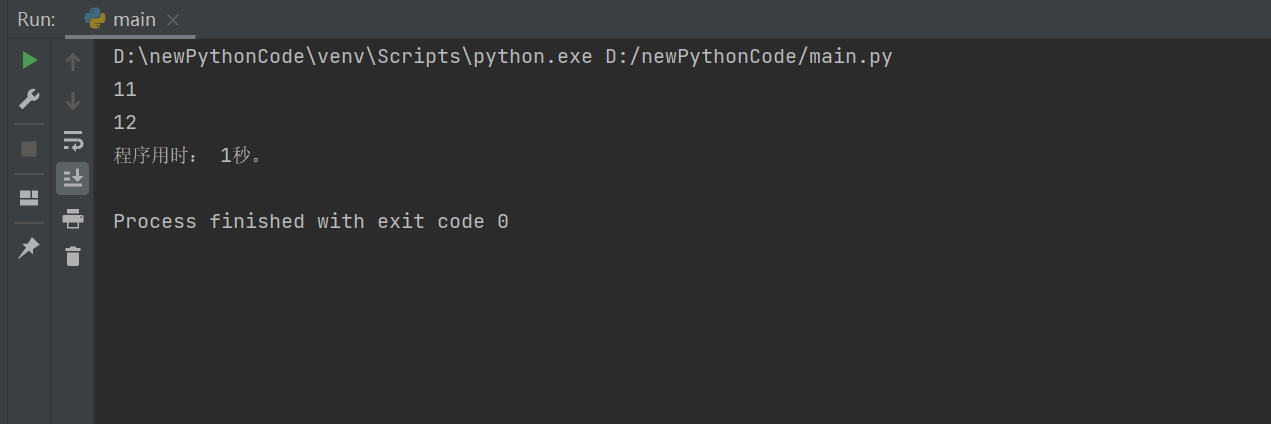
出现这些内容,表示运行成功。
打开生成的总计.pptx进行检查:
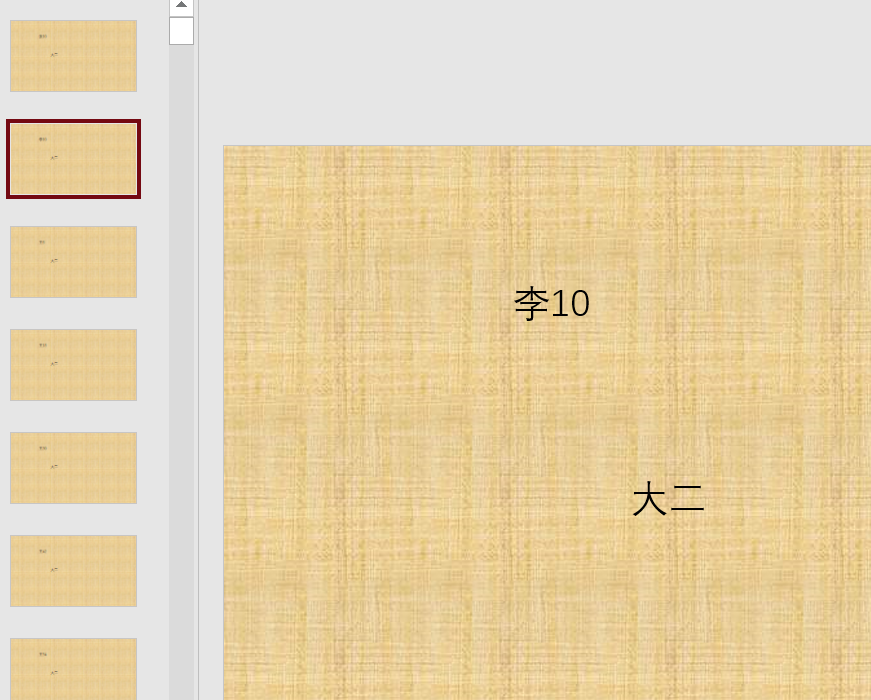
生成了399张不同的幻灯片,达到了预期要求!
四、改进
1. 在实际应用中,一个模板可能会有多个占位符,最好先根据上文的方法观察一下占位符编号再决定数据写入的位置
2. 一个母版可能会有多个附属的模板,就像这样:
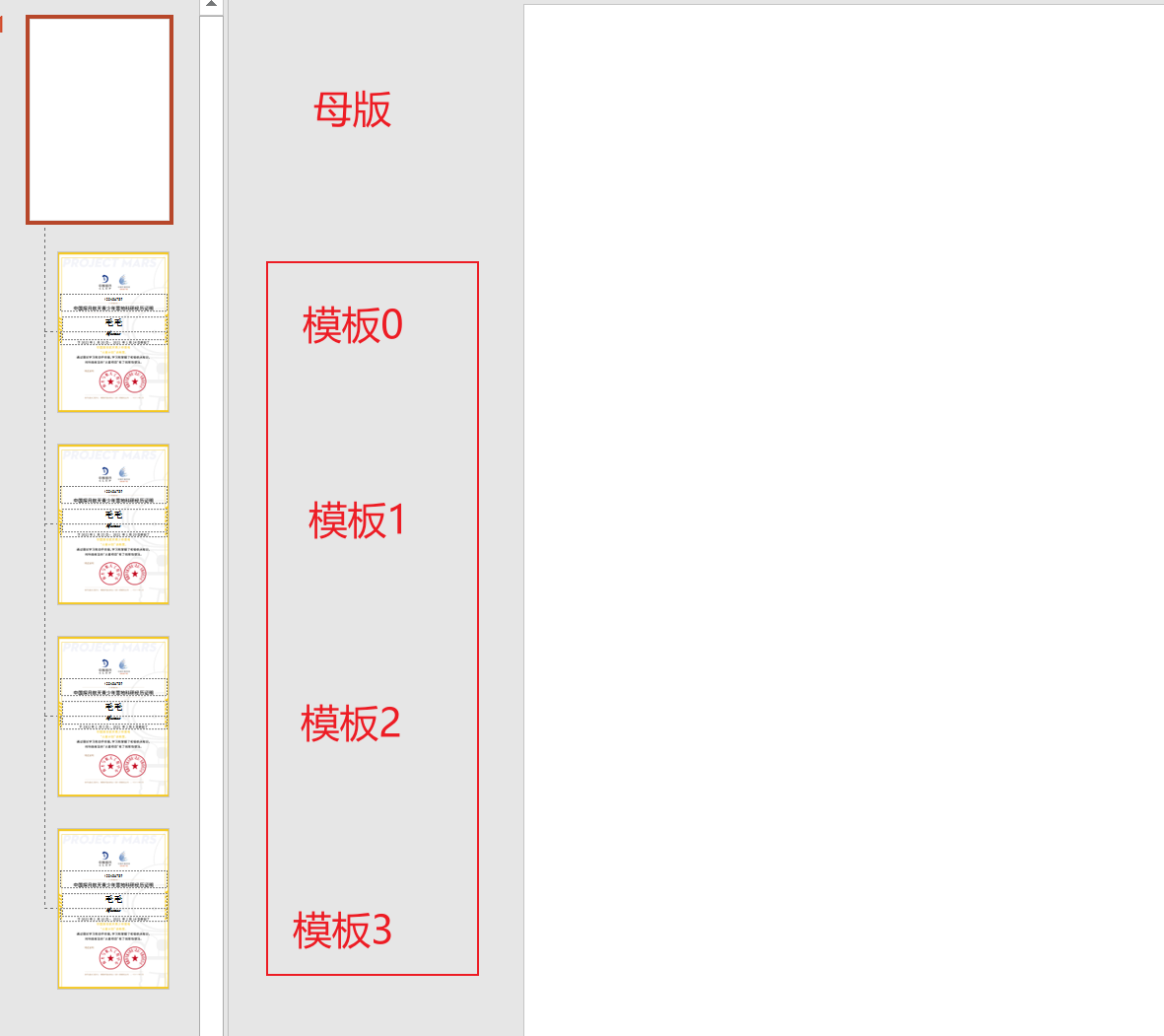
这些模板以0开始,可以这样访问:
if(cnt<170):
slide_layout = prs.slide_layouts[0] #第0个模板
else:
slide_layout = prs.slide_layouts[1] #第1个模板实际应用可以实现这样一种效果:表格的前170行使用第一个模板,后面的使用第二个模板
3. 表格的行(row)是从1开始的,因此如果有表头,那么读取时应从第二行开始。
#有表头的情况
for row in range(2,ws.max_row+1):
class_id = ws['A' + str(row)].value
name = ws['B' + str(row)].value
data.setdefault(class_id,[])
data[class_id].append(name)
以下是程序所用的表格和模板:
链接:https:加上//pan.baidu.com/s/1D2Qck3lfbKJVDYh1EzNbnA
提取码:e534
最后
以上就是踏实百褶裙最近收集整理的关于PPT批量导入文字(Python实现)一、基础知识二、环境搭建三、测试代码四、改进的全部内容,更多相关PPT批量导入文字(Python实现)一、基础知识二、环境搭建三、测试代码四、改进内容请搜索靠谱客的其他文章。








发表评论 取消回复