转载自:
http://blog.csdn.net/sanlongcai/archive/2007/07/22/1701699.aspx
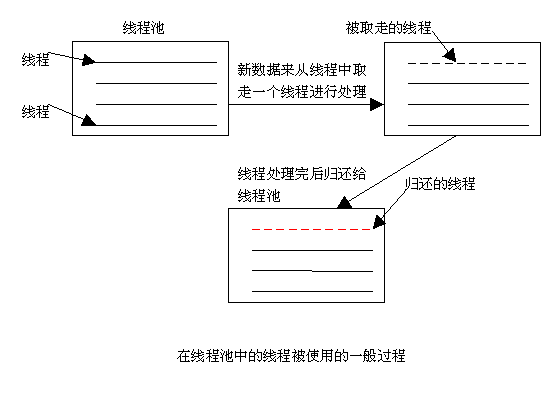
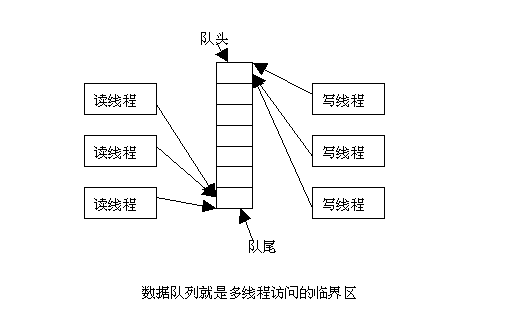
| 异步队列的数据结构如下:
struct _GAsyncQueue
{
GMutex *mutex; //互斥变量
GCond *cond; //等待条件
GQueue *queue; //数据队列
guint waiting_threads; //等待的读线程个数
gint32 ref_count;
};
g_async_queue_push_unlocked (GAsyncQueue* queue, gpointer data)
{
………//这些点代表一些省略的代码
//把数据放入队列
g_queue_push_head (queue->queue, data);
//现在队列已经有数据了,判断是否有读线程在等待数据,
//如果有就发送信号唤醒读线程
if (queue->waiting_threads > 0)
g_cond_signal (queue->cond);
}
g_async_queue_push (GAsyncQueue* queue, gpointer data)
{
……..
g_mutex_lock (queue->mutex); //在访问临界区前先获得互斥变量
g_async_queue_push_unlocked (queue, data); //执行写数据操作
g_mutex_unlock (queue->mutex); //释放互斥变量,以使其它线程可以进入临界区
}
从以上的接口可看出,”…._ unlocked” 这样的接口就是异步队列这个对象已获得互斥变量的接口,glib中线程处理相关接口都有类似的命名规则,在接下来的代码分析中,如没有特别的需要就只看”…._ unlocked” 这样的接口。
// 读线程从异步队列中获取数据的接口
// try参数和时间参数在多线程同步/内核多进程的实现中是很常见的东西了,在这里就不再作特殊的解释了。
g_async_queue_pop_intern_unlocked (GAsyncQueue *queue,
gboolean try,
GTimeVal *end_time)
{
gpointer retval;
//判断是否有数据在队列中,如果没有就要执行if语句相应的睡眠等待,直到被写进程唤醒
if (!g_queue_peek_tail_link (queue->queue))
{
if (try)// 如果try为真,则永远不睡眠
return NULL;
//
接下来是要让线程进行睡眠等待了,在等待之前先确保等待条件已创建
if (!queue->cond)
queue->cond = g_cond_new ();
if (!end_time) //
等待无时间限制
{
queue->waiting_threads++; //
等待线程数加一
//
这里为什么用循环?因为这是多线程的环境,有可能有多个读线程在等待
//
当前线程被唤醒时,有可能数据队列中的数据又被别的线程读走了,所以
//
当前线程就得继续睡眠等待
//
注意:睡眠等待时会暂时放弃互斥锁,被唤醒时会重新获取互斥锁
while (!g_queue_peek_tail_link (queue->queue))
g_cond_wait (queue->cond, queue->mutex);
queue->waiting_threads--; //
等待线程数减一
}
else
{
queue->waiting_threads++;
while (!g_queue_peek_tail_link (queue->queue))
if (!g_cond_timed_wait (queue->cond, queue->mutex, end_time))
break;
queue->waiting_threads--;
if (!g_queue_peek_tail_link (queue->queue))
return NULL;
}
}
retval = g_queue_pop_tail (queue->queue);
g_assert (retval);
return retval;
}
/* 返回数据队列的长度,也即数据队列中的数据个数.
* 如果是负值表明是等待数据的线程个数,正数表示数据队列的数据个数
* g_async_queue_length == 0 表示是有 'n' 个数据和' n' 个等待线程在数据队列
* 这种特殊情况可能是在对数据队列加锁或调度时发生
*/
g_async_queue_length_unlocked (GAsyncQueue* queue)
{
g_return_val_if_fail (queue, 0);
g_return_val_if_fail (g_atomic_int_get (&queue->ref_count) > 0, 0);
return queue->queue->length - queue->waiting_threads;
} |
|
typedef struct _GThreadPool GThreadPool;
struct _GThreadPool
{
//
具体处理数据的函数
//
它的第一个参数为g_thread_pool_push进去的数据,也即要执行的任务
GFunc func;
gpointer user_data; // func的第二个参数
// 通过这个成员控制线程池对象创建的线程是否在全局线程池中共享,
// TRUE为不共享,FALSE为共享
gboolean exclusive;
}; |
|
typedef struct _GRealThreadPool GRealThreadPool;
struct _GRealThreadPool
{
GThreadPool pool; // 头文件已定义
GAsyncQueue* queue; // 异步数据队列
GCond* cond;
gint max_threads; // 线程池对象持有的线程数上限
gint num_threads;// 池程池对象当前持有的线程数
gboolean running;
gboolean immediate;
gboolean waiting;
GCompareDataFunc sort_func;
gpointer sort_user_data;
}; |
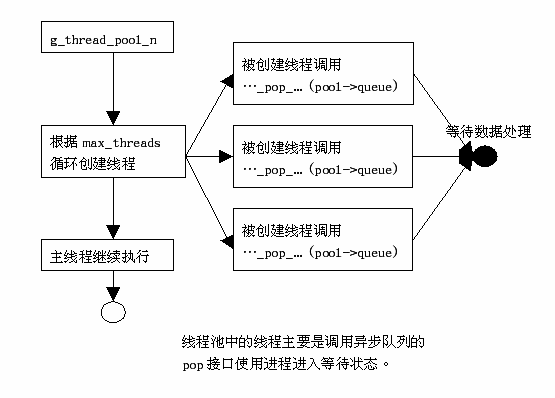
|
// max_threads为 -1 时表示线程池中的线程数无限制并且线程由动态生成
// max_threads为正整数时,线程池就会预先创建max_threads个线程
g_thread_pool_new (GFunc func,
gpointer user_data,
gint max_threads,
gboolean exclusive,
GError **error)
{
GRealThreadPool *retval;
……………. // 这些点代表一些省略的代码
retval = g_new (GRealThreadPool, 1);
retval->pool.func = func;
retval->pool.user_data = user_data;
retval->pool.exclusive = exclusive;
retval->queue = g_async_queue_new (); // 创建异步队列
retval->cond = NULL;
retval->max_threads = max_threads;
retval->num_threads = 0;
retval->running = TRUE;
…………….
if (retval->pool.exclusive)
{
g_async_queue_lock (retval->queue);
while (retval->num_threads < retval->max_threads)
{
GError *local_error = NULL;
g_thread_pool_start_thread (retval, &local_error);//
起动新的线程
…………….
}
g_async_queue_unlock (retval->queue);
}
return (GThreadPool*) retval;
}
g_thread_pool_start_thread (GRealThreadPool *pool,
GError **error)
{
gboolean success = FALSE;
if (pool->num_threads >= pool->max_threads && pool->max_threads != -1)
/* Enough threads are already running */
return;
…………….
if (!success)
{
GError *local_error = NULL;
/* No thread was found, we have to start a new one */
//
真正创建一个新的线程
g_thread_create (g_thread_pool_thread_proxy, pool, FALSE, &local_error);
……………….
}
pool->num_threads++;
}
g_thread_pool_thread_proxy (gpointer data)
{
GRealThreadPool *pool;
pool = data;
……………..
g_async_queue_lock (pool->queue);
while (TRUE)
{
gpointer task;
//
线程等待任务,也即等待数据,线程在等待就是处在线程池中的空闲线程
task = g_thread_pool_wait_for_new_task (pool);
//
如果线程被唤醒收到并数据就用此线程执行任务,否则继续循环等待
//
注意:当任务做完时,继续循环又会调用上面的g_thread_pool_wait_for_new_task
//
而进入等待状态,
if (task)
{
if (pool->running || !pool->immediate)
{
/* A task was received and the thread pool is active, so
* execute the function.
*/
g_async_queue_unlock (pool->queue);
pool->pool.func (task, pool->pool.user_data);
g_async_queue_lock (pool->queue);
}
}
else
{
………………
}
}
return NULL;
}
g_thread_pool_wait_for_new_task (GRealThreadPool *pool)
{
gpointer task = NULL;
if (pool->running || (!pool->immediate &&
g_async_queue_length_unlocked (pool->queue) > 0))
{
/* This thread pool is still active. */
if (pool->num_threads > pool->max_threads && pool->max_threads != -1)
{
…………..
}
else if (pool->pool.exclusive)
{
/* Exclusive threads stay attached to the pool. */
//
调用异步队列的pop接口进入等待状态,到此一个线程的创建过程就完成了
task = g_async_queue_pop_unlocked (pool->queue);
}
else
{
………….
}
}
else
{
…………
}
return task;
} |
现在可以结合流程图分析线程池中创建一个线程的一个情景:从函数g_thread_pool_new的while循环调用了 g_thread_pool_start_thread函数,在函数中直接调用g_thread_create创建线程,被创建的线程调用函数 g_thread_pool_wait_for_new_task循环等待任务的到来,函数 g_thread_pool_wait_for_new_task调用g_async_queue_pop_unlocked (pool->queue)真正进入等待。如此可知,最终新创建的线程是调用异步队列的pop接口进入等待状态的,这样一个线程的创建就大功告成 了。而函数g_thread_pool_new的while循环结束时就创建了max_threads个等待线程,也即这个新建的线程池对象有了 max_threads个线程以备使用。
创建线程池、线程池中的线程是为了使用它,在线程池中取线程,叫线程干活的过程就很简单多了,这个调用过程: g_thread_pool_push-- à g_thread_pool_queue_push_unlocked-- à g_async_queue_push_unlocked 。可见最终调用的是异步数据队列的 push 接口,把要处理的数据插入队列后它就会唤醒等待异步队列数据的等待线程。
|
g_thread_pool_push (GThreadPool *pool,
gpointer data,
GError **error)
{
……………
//
if (g_async_queue_length_unlocked (real->queue) >= 0)
/* No thread is waiting in the queue */
g_thread_pool_start_thread (real, error);
g_thread_pool_queue_push_unlocked (real, data);
g_async_queue_unlock (real->queue);
}
g_thread_pool_queue_push_unlocked (GRealThreadPool *pool,
gpointer data)
{
………….
g_async_queue_push_unlocked (pool->queue, data);
} |
总结:单个线程池对象不共享方式在管理多线程时是以线程池对象中的异步队列为中心,新创建的线程或做完任务的线程并不释放,让它调用异步队列的 pop 接口进入等待状态,而在使用唤醒线程池中的线程就是调用异步队列的 push 接口。
以上对于理解线程池的实现已经足够,多个线程池对象共享线程方式和具体线程池的销毁的技巧,在这里就不讨论了。
最后
以上就是忧虑铃铛最近收集整理的关于[线程]glib库线程池代码分析的全部内容,更多相关[线程]glib库线程池代码分析内容请搜索靠谱客的其他文章。




![[线程]glib库线程池代码分析](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)



发表评论 取消回复