缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
-
分布式缓存,例如Redis:
-
优点:存储容量更大、可靠性更好、可以在集群间共享
-
缺点:访问缓存有网络开销
-
场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
-
-
进程本地缓存,例如HashMap、GuavaCache:
-
优点:读取本地内存,没有网络开销,速度更快
-
缺点:存储容量有限、可靠性较低、无法共享
-
场景:性能要求较高,缓存数据量较小
-
我们今天会利用Caffeine框架来实现JVM进程缓存。
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
Caffeine的性能非常好,下图是官方给出的性能对比:
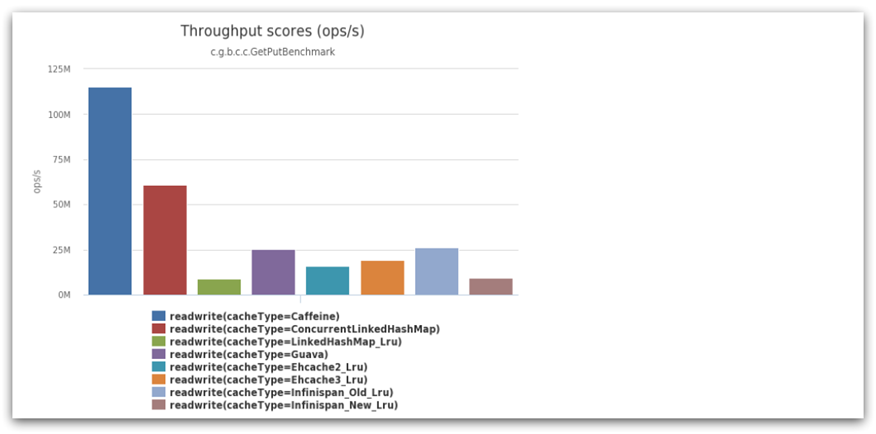
可以看到Caffeine的性能遥遥领先!
缓存使用的基本API:
@Test
void testBasicOps() {
// 构建cache对象
Cache<String, String> cache = Caffeine.newBuilder().build();
// 存数据
cache.put("gf", "迪丽热巴");
// 取数据
String gf = cache.getIfPresent("gf");
System.out.println("gf = " + gf);
// 取数据,包含两个参数:
// 参数一:缓存的key
// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是查询数据库的逻辑
// 优先根据key查询JVM缓存,如果未命中,则执行参数二的Lambda表达式
String defaultGF = cache.get("defaultGF", key -> {
// 根据key去数据库查询数据
return "柳岩";
});
System.out.println("defaultGF = " + defaultGF);
}Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
-
基于容量:设置缓存的数量上限
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();基于时间:设置缓存的有效时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();-
基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
最后
以上就是勤劳舞蹈最近收集整理的关于初识Caffeine的全部内容,更多相关初识Caffeine内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复