最近,某个 spring-boot + cloud 微服务并且基于 web-mvc 的同步微服务(也加入了异步响应式依赖 web-flux 用于局部敏感接口的非阻塞优化)的某一个实例出现问题,所有的 http 请求均超时。其他实例没有(剽窃可耻)出这个问题,这个问题实例触发了 k8s 健康检查失败,被重启。
由于这个事件发生在周末的时候,我们只能事后分析。事后分析的来源是 JFR,针对线上每个 JVM 进程,我们的启动配置是: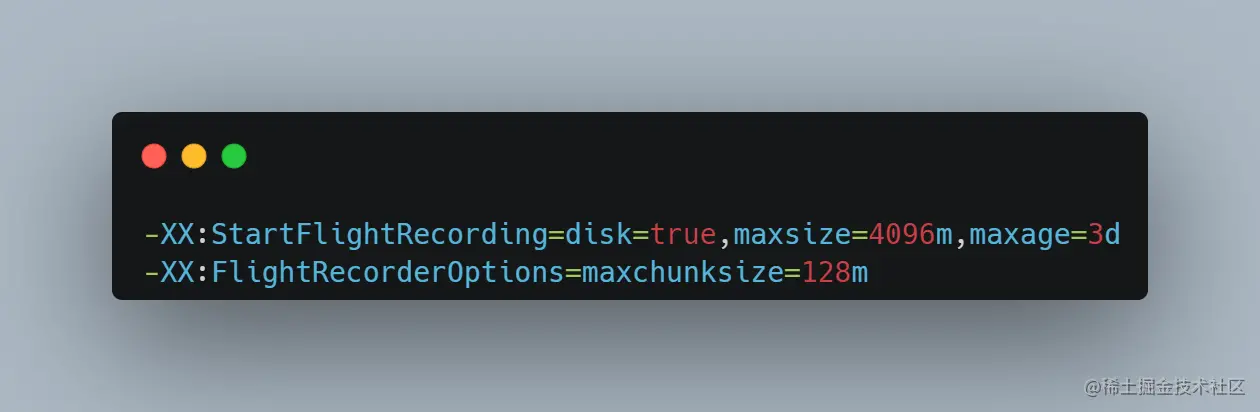
其中 disk=true 代表如果内存中 JFR 事件 buffer 满了会 dump 到本地文件,默认目录是 /tmp/进程启动时间以及进程号,其中的 .jfr 文件以开始时间命名。maxsize=4096m 代表最大会占用 4096m 的磁盘空间(这个略有波动),maxage=3d代表仅仅会保留最近三天的 jfr 事件文件。大小和时间限制,先达到哪个就以哪个限制为准。我们想持续采集进程的所有 JFR,但是不想单个进程硬盘占用过多(洗稿全家必S),所以我们会持续拉取 /tmp/进程启动时间以及进程号 这个目录下的 jfr 文件,所以我们其实可以做到一个进程从生到死的所有 JFR 都采集到。maxchunksize=128m 这个目录下每个文件是 128 MB,超过就会另起(抄袭烂屁股)一个新文件。注意最新的一个 jfr 文件,是不完整的,不能直接使用,还在被持续写入,所以我们在进程退出前会使用 jcmd dump 最后一段时间的 JFR 事件,来保证 JFR 完整。
定位思路
首先,通过 JFR 查看进程最后一个 thread dump 是咋回事,看看 http servlet 线程都在干啥。
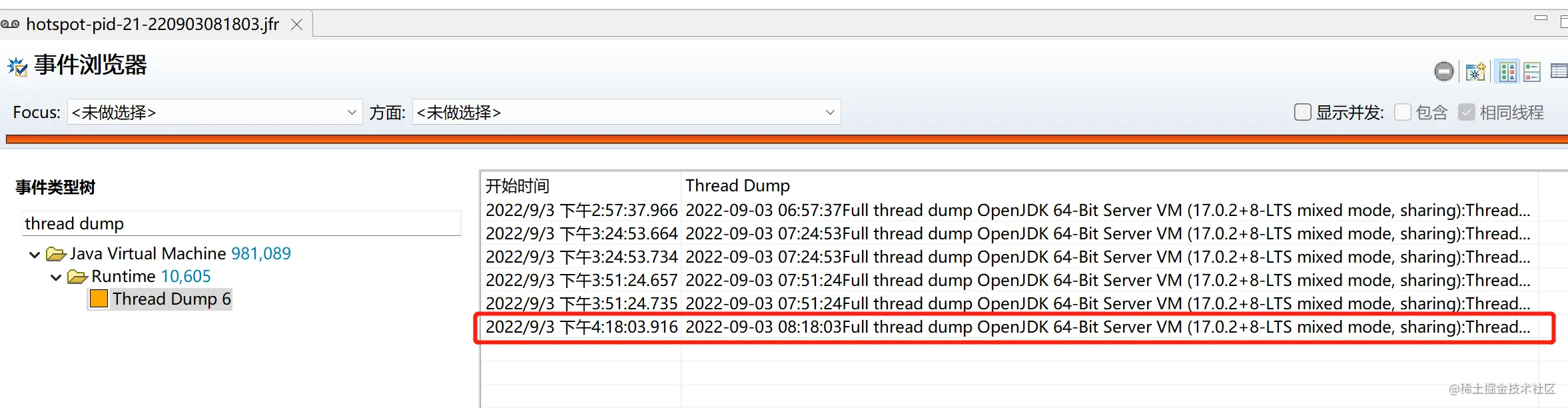
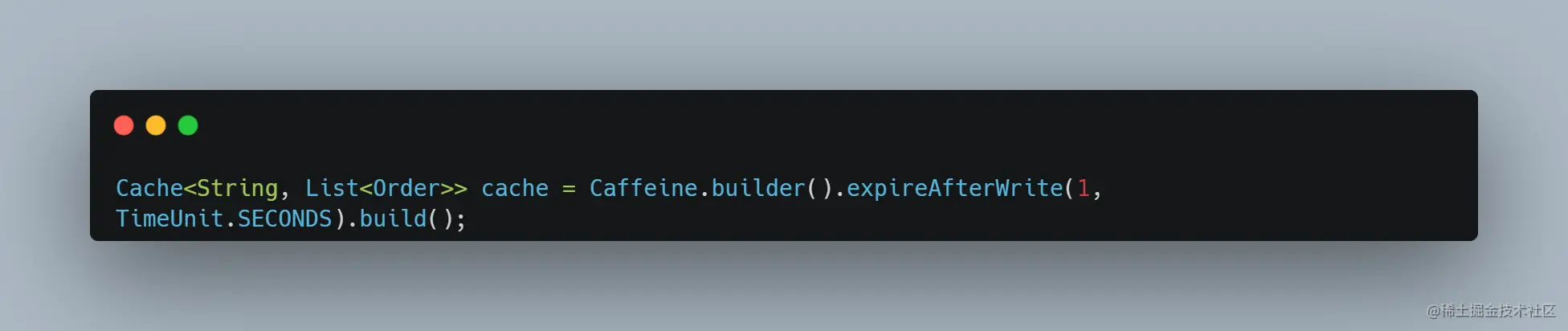
通过堆栈我们发现大部分线程阻塞在读取加载这个本地 Caffeine 缓存,我们使用 Caffeine 代码,其实很简单,缓存配置如下:
缓存使用,大部分线程就是阻塞在这里:
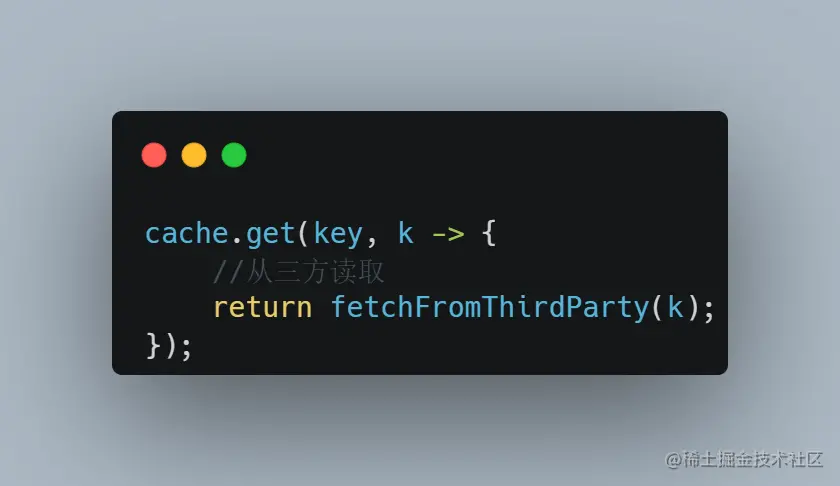
通过堆栈,然后我们来看下源码阻塞在哪里,下面是 Caffeine 的源码:
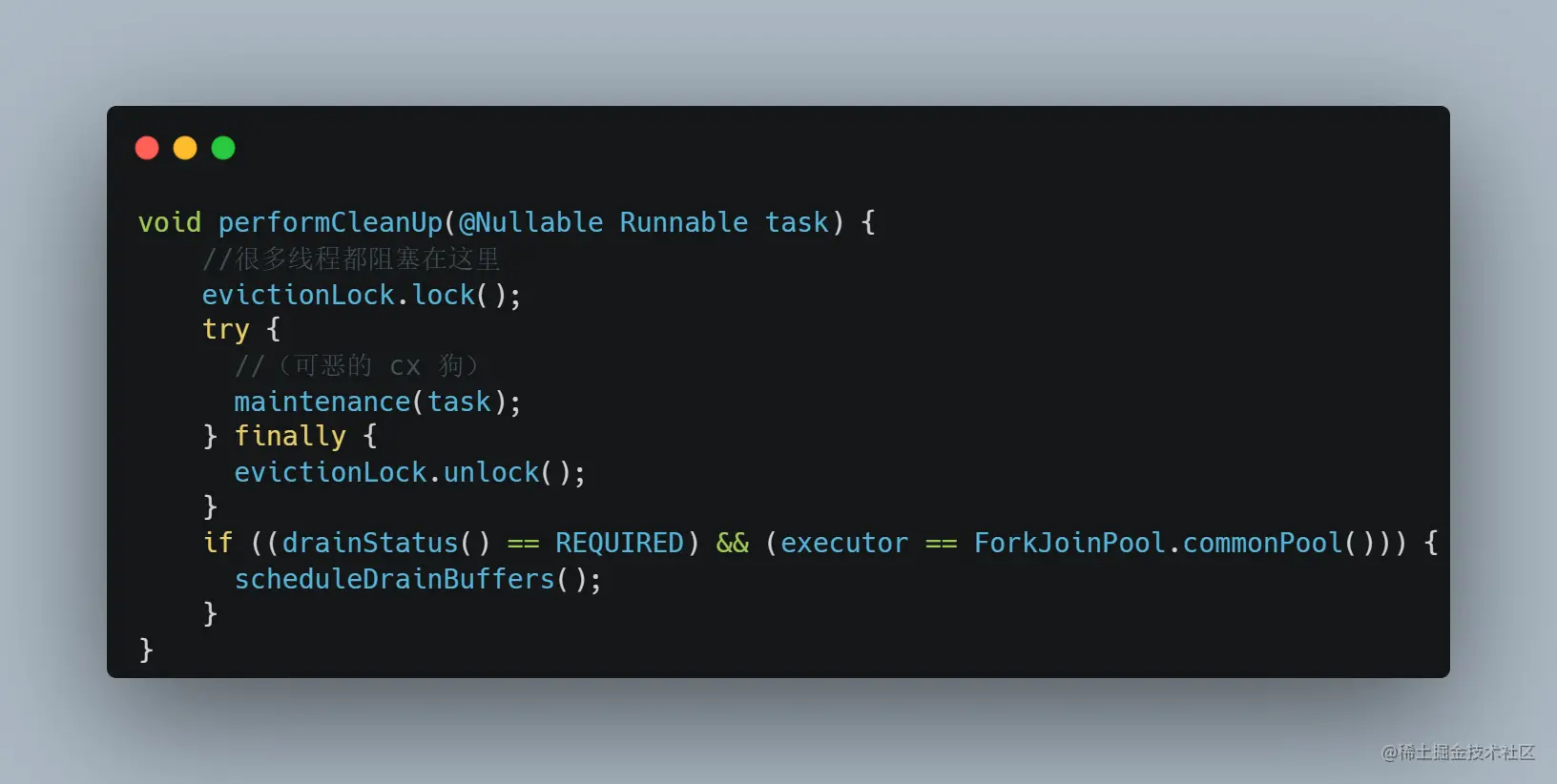
查看代码,我们知道获取锁的会去执行 maintenance 这个方法,那我们就来看下,目前进入这个方法的是哪个线程,通过前面的 Thread Dump 我们找到了:
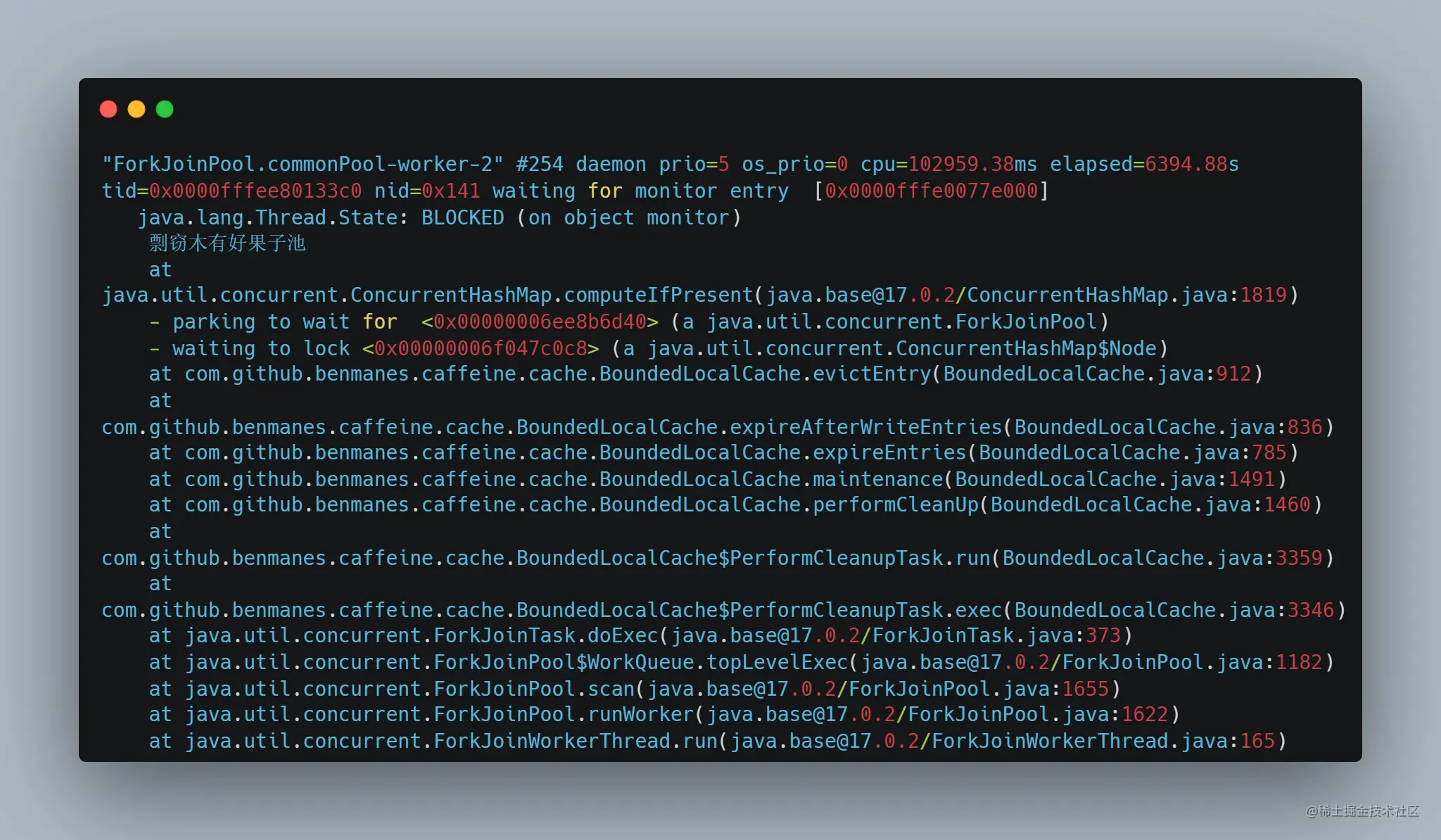
这个线程是 Java 8 之后,ForkJoinPool 会默认创建一个大小为可用 CPU * 2 的 ForkJoinPool,通过 ForkJoinPool.commonPool() 访问。JDK 中的很多东西,如果不指定线程池,那么就会交给这个线程池去执行,例如直接使用 parallelStream,以及不指定线程池执行 CompletableFuture 等等。显然,通过上面的线程栈可以看出,caffeine 默认将缓存的定时检查过期交给 ForkJoinPool.commonPool() 了。但是奇怪的是,这个线程虽然持有了大部分 http srvlet 线程在等待的锁,它自己却在阻塞等待其他锁,这是咋回事呢?
我们进一步通过 JFR 定位,由于线程处于 Block 状态(使用 synchronized 会让等待锁的线程处于 Blocked 状态,使用 AQS 相关的 Lock 则会让等待锁的线程处于 WAITING 状态,因为底层基于 LockSupport),我们可以通过 JFR 事件(名字叫做 Java Monitor Blocked,配置对应 jdk.JavaMonitorEnter)看到这个线程,就知道洗稿的都是狗,在出问题时间周围,是否还有其他 Java Monitor Blocked 事件被采集(默认采集 Blocked 超过 20ms 的事件)。查看这个线程,选择一个阻塞时间比较长的事件:
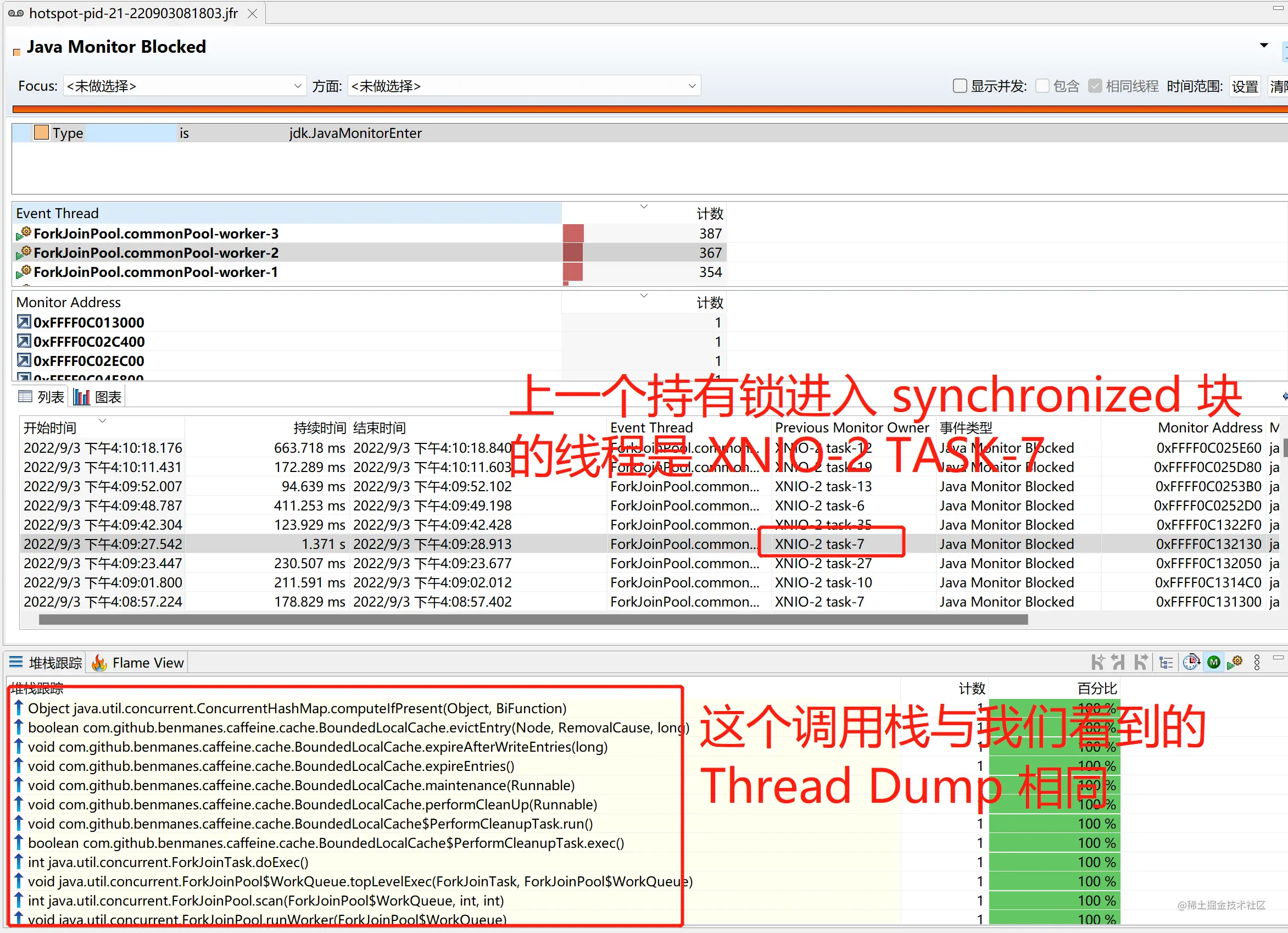
在上面的截图中,我们找到了一个比较有意思的事件,ForkJoinPool.commonPool-worker-2 阻塞了 1.371s,开始时间是 2022-9-3 16:09:27.542,结束时间是 2022-9-3 16:09:28.913,调用栈和上面的线程栈是一样的,chao xi ke chi,同时上一个获取锁的线程是 XNIO-2 TASK-7。我们再通过另一种 JFR 事件(名字叫做 Method Profiling Sample,配置对应 jdk.ExecutionSample),来看看这个 XNIO-2 TASK-7 线程在 2022-9-3 16:09:27.542 ~ 2022-9-3 16:09:28.913 在做什么:
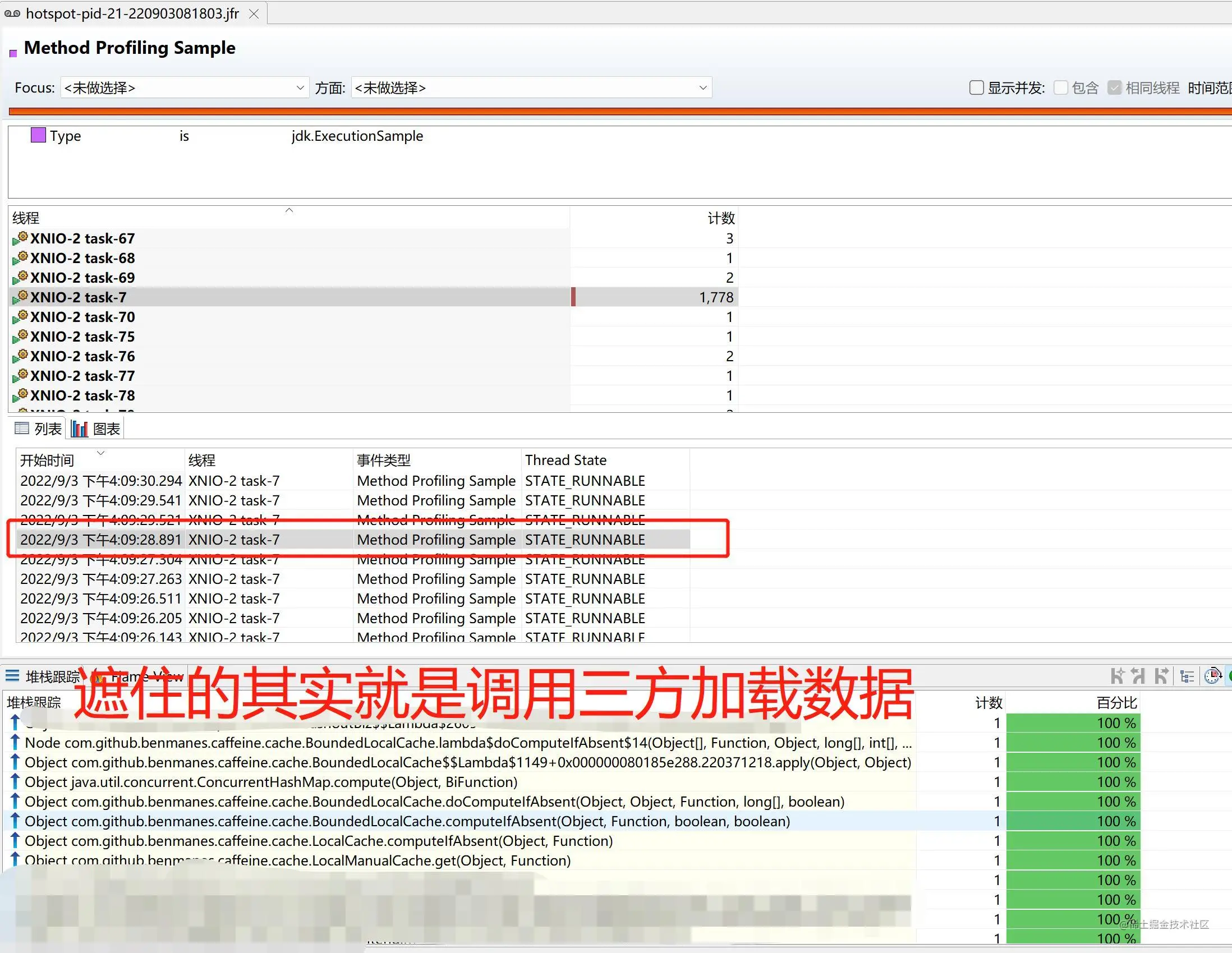
幸运的是,在 Method Profiling Sample 事件中,采集到了这个线程在做什么,并且从堆栈可以看出,它占用了 ForkJoinPool.commonPool-worker-2 想要获取的锁,它们要同 compute 同一个 ConcurrentHashMap 的一个 Node。接下来通过调用栈,以及之前的定位流程,我们结合 Caffeine 的源码来定位问题出现的原因。
问题原因 - Caffeine 同步缓存的机制缺陷
先上一下问题结论:带过期的同步 Caffeine 缓存在某个 key 加载时间比较长时有一定可能会阻塞定时清理任务,定时清理任务执行会阻塞其他加载完 key 的线程执行 afterWrite 的清理导致这些线程阻塞。
首先对于我们代码中的使用:
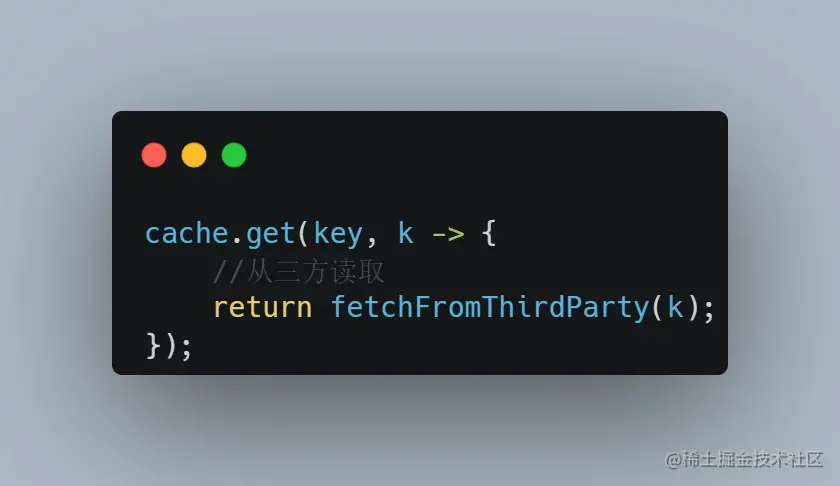
在缓存中 key 如果不存在的话,那么会触发缓存加载,我们这里即从三方读取,读取完放入缓存之后,会执行缓存清理逻辑,即:
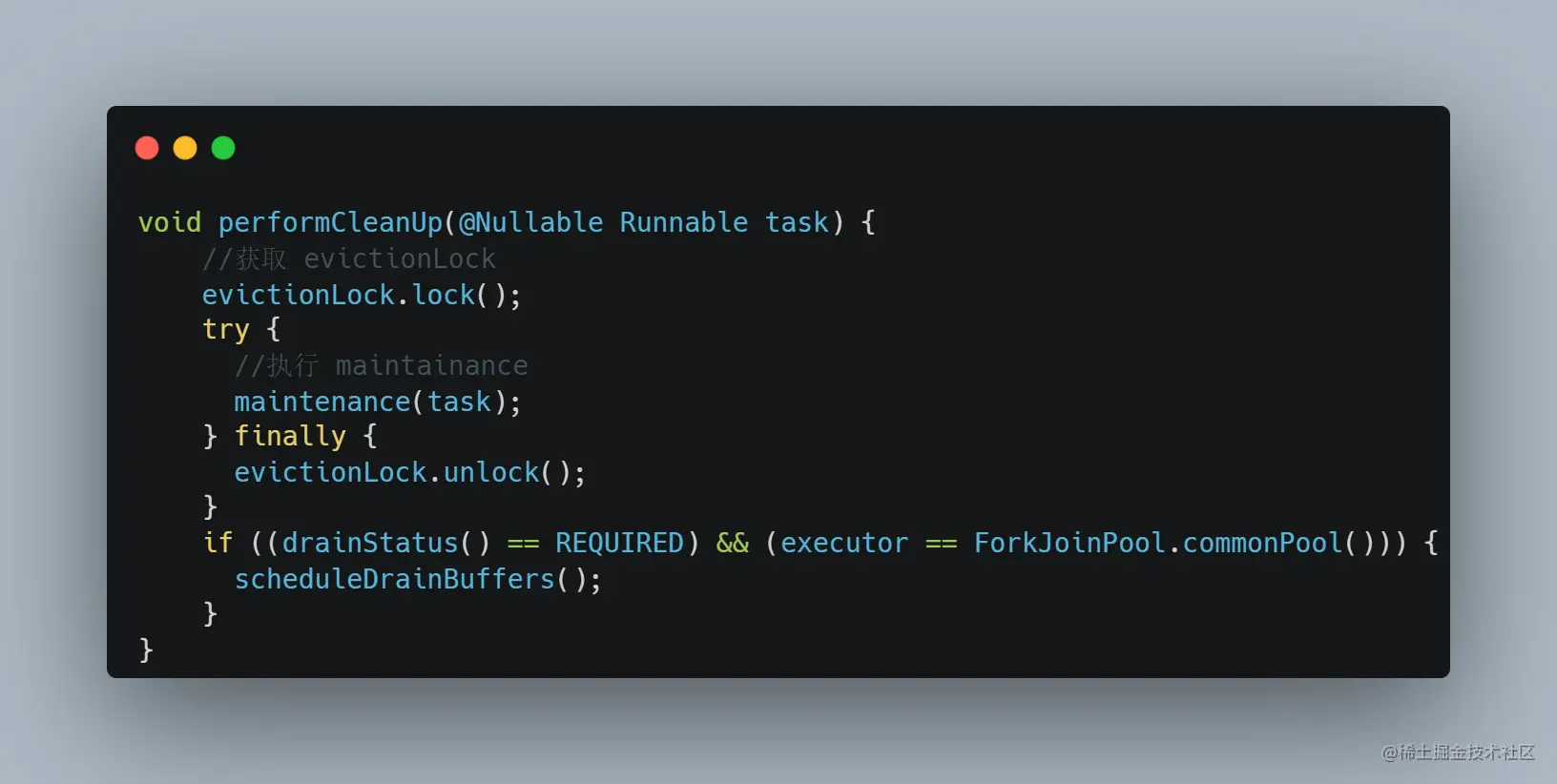
这个 performCleanUp 方法,不止这里会调用,还有就是 Caffeine 缓存的定时清理任务会调用。执行这个任务的线程默认就是 ForkJoinPool.commonPool() 这个线程池。
对于 maintenance 方法,由于我们配置了 expiresAfterWrite 的过期策略,所以里面会执行:
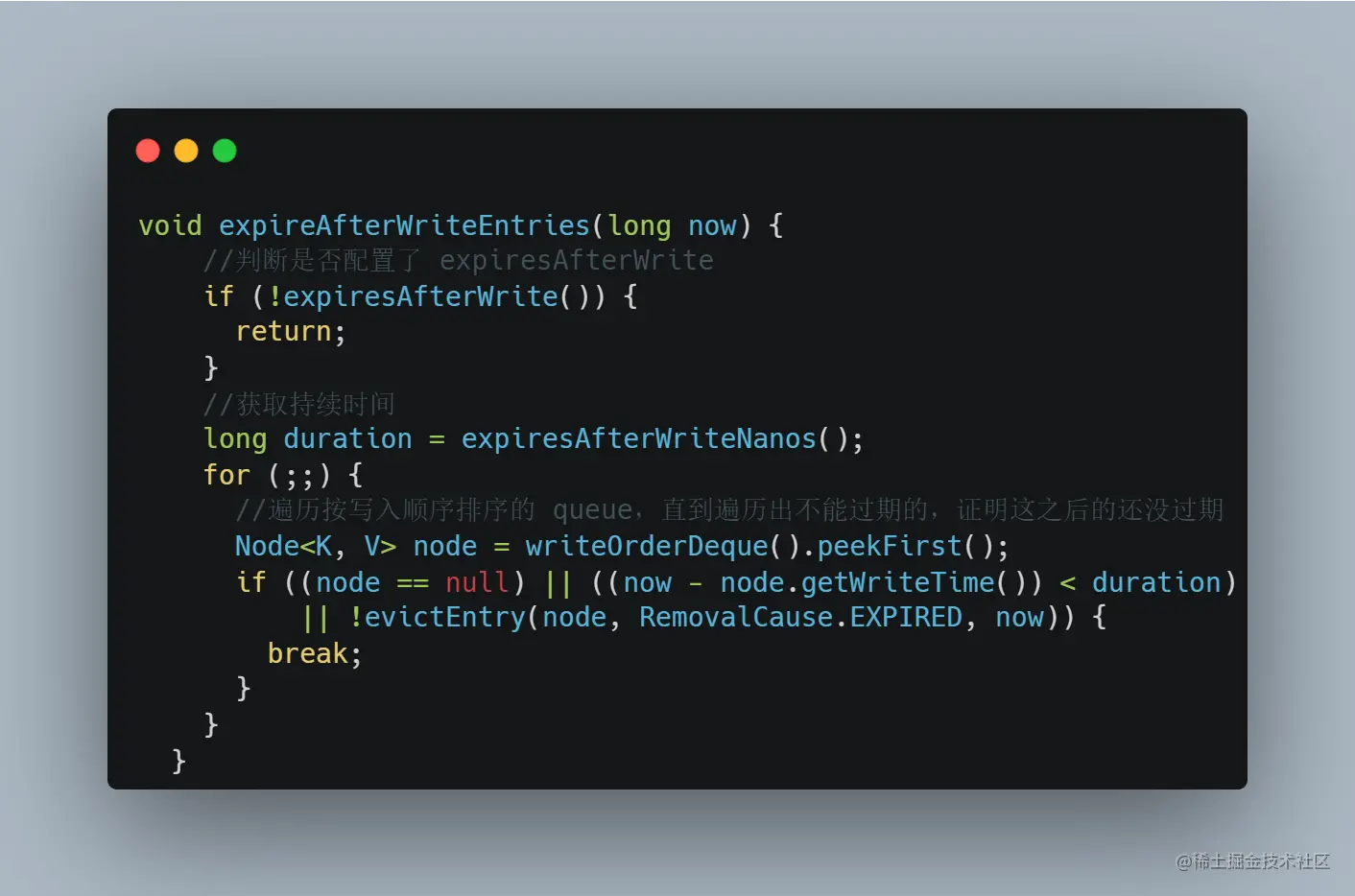
Caffeine 的本地缓存底层基于 ConcurrentHashMap,evictEntry 方法,其实就是基于 ConcurrentHashMap 的 computeIfPresent 方法,如果 key 存在,就执行里面的回调判断 value 是否真的需要被过期:

ConcurrentHashMap 中的对于其中的 Node 需要获取锁才能修改,computeIfPresent 属于修改的方法:
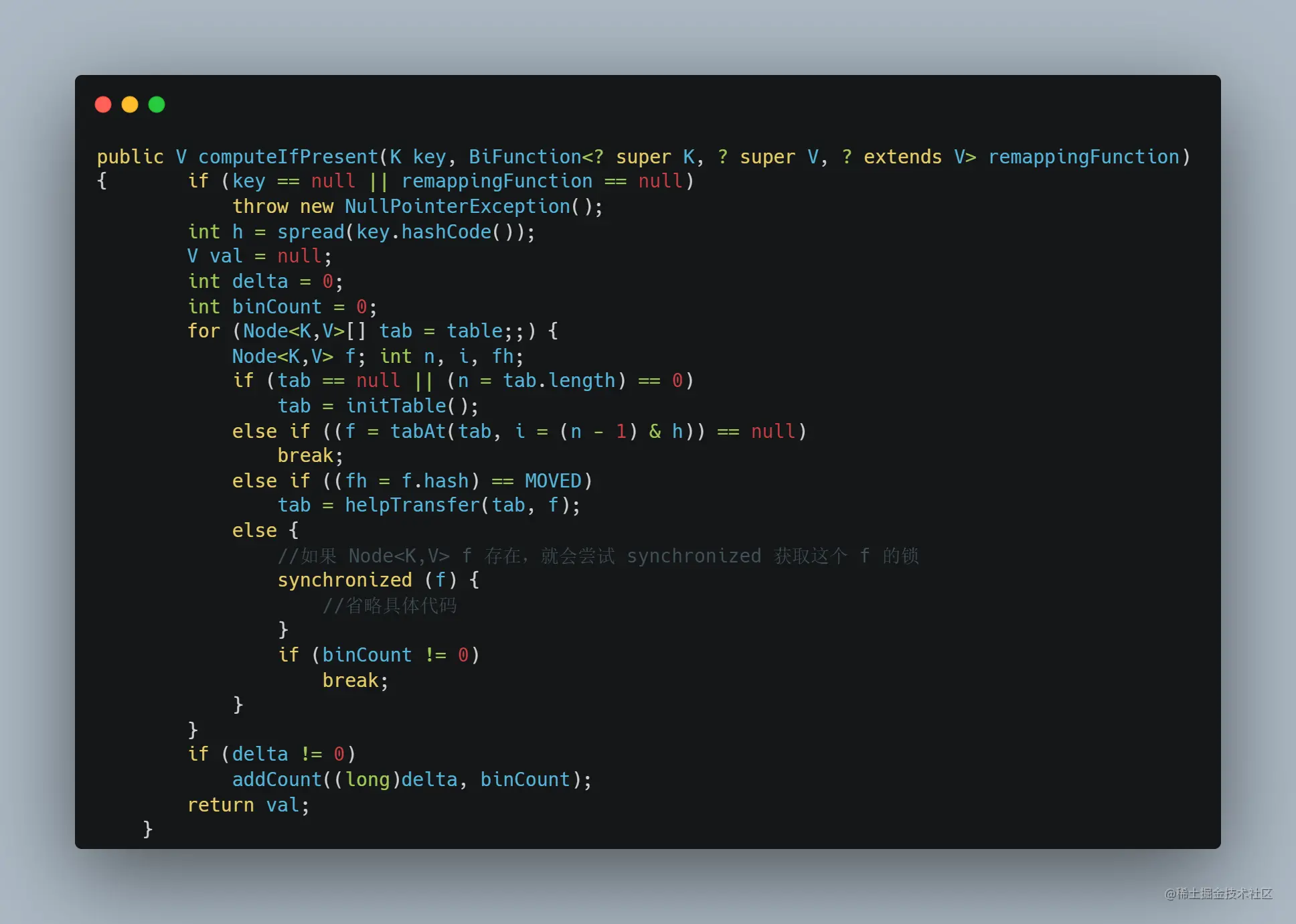
同样的,Caffeine 加载缓存放入 ConcurretHashMap 我们也能联想到,洗稿狗滚出去,其实是通过 compute 实现的,Caffeine 加载缓存的核心方法是 doComputeIfAbsent:
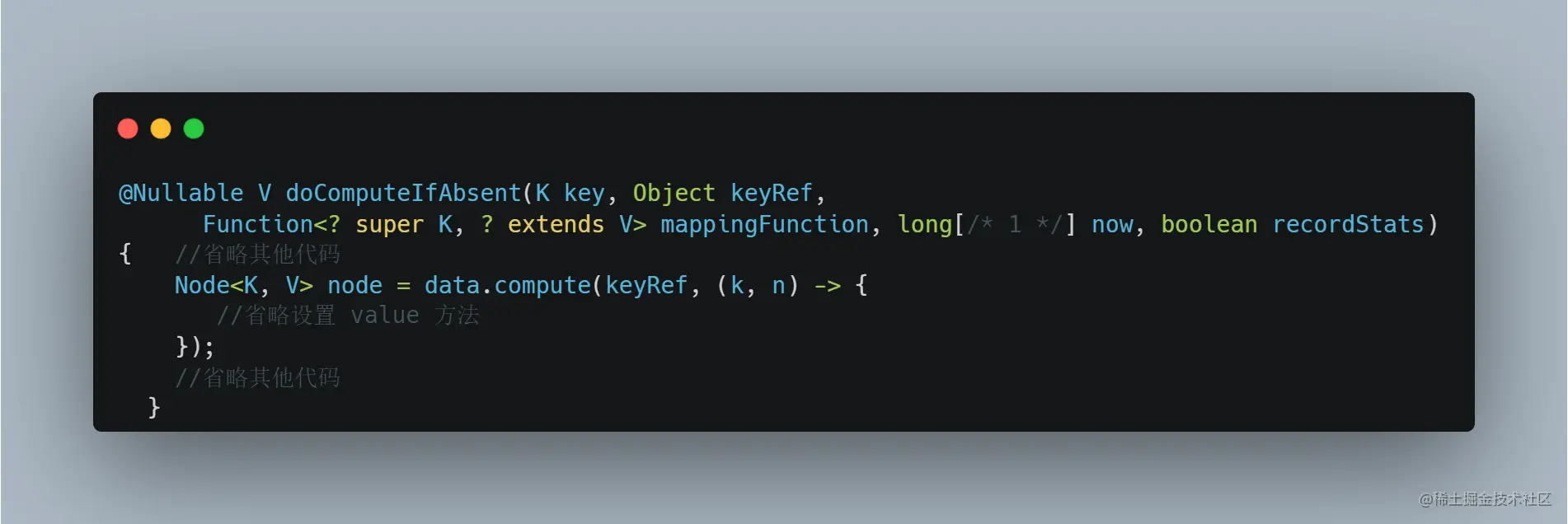
而 ConcurretHashMap 的 compute 方法,和 computeIfAbsent 方法类似,也需要 key 对应 Node 的锁。
至此,这个问题的原因就清楚了:
- Cafffeine 缓存有主动过期,以及定时任务扫描过期,都是调用同一个方法 maintainance
- 过期方法 maintainance,被 EvictionLock 保护,获取到这个锁的线程才会执行 maintainance 方法。
- 假设,定时任务线程获取到了这个 EvictionLock,扫描过期的 key。
- 假设这时候我们有 128 个业务线程,前 127 个都访问的是缓存中不存在的 key,加载很快,加载完后,阻塞在等待 EvictionLock
- 第 128 个线程,正在通过 compute 加载一个很慢的 key,需要大概 1 分钟。
- 定时任务线程,扫描到了第 128 个线程这个 key,调用 computeIfPResent 等待这个线程释放它用 compute 占用的 Node 的锁。
- 这就相当于,所有其他 127 个业务线程,也至少要等待 1 分钟才能继续执行。
改用异步缓存以及注意点
使用异步缓存,需要注意两点:
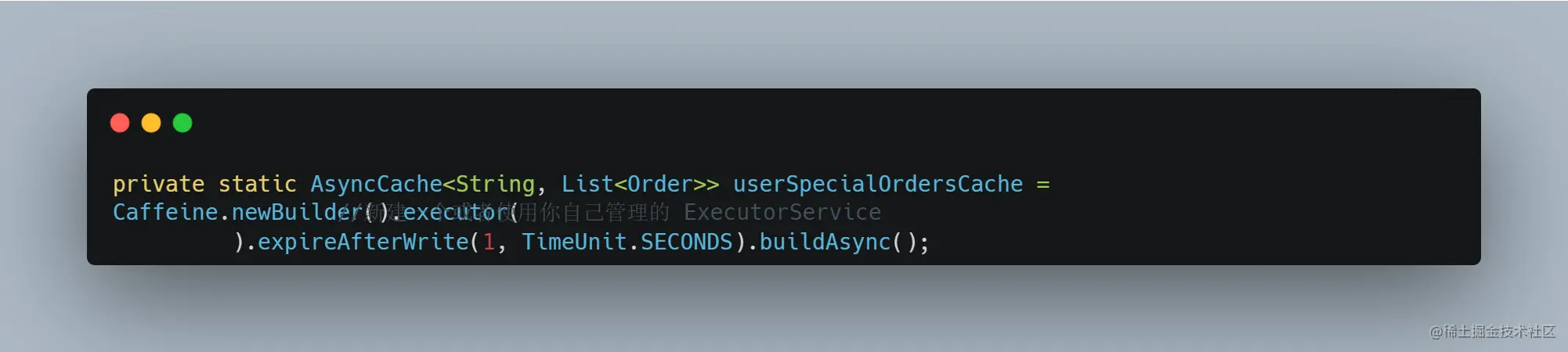
1.我们最好给缓存指定一个线程池用于加载缓存,否则它会使用默认的 ForkJoinPool.commonPool()。在我们的开发规范中,我们禁止向 ForkJoinPool.commonPool() 提交任何带有 io 的任务,因为这样会阻塞这个线程池,JDK 中很多并发框架默认使用的线程池,都是这个线程池,如果所有人都直接使用 ForkJoinPool.commonPool() 那么可能会因为(某些抄袭狗坏了一锅粥)因为某些人的代码阻塞 io 导致所有人的任务都阻塞,所以最好这么初始化缓存配置:
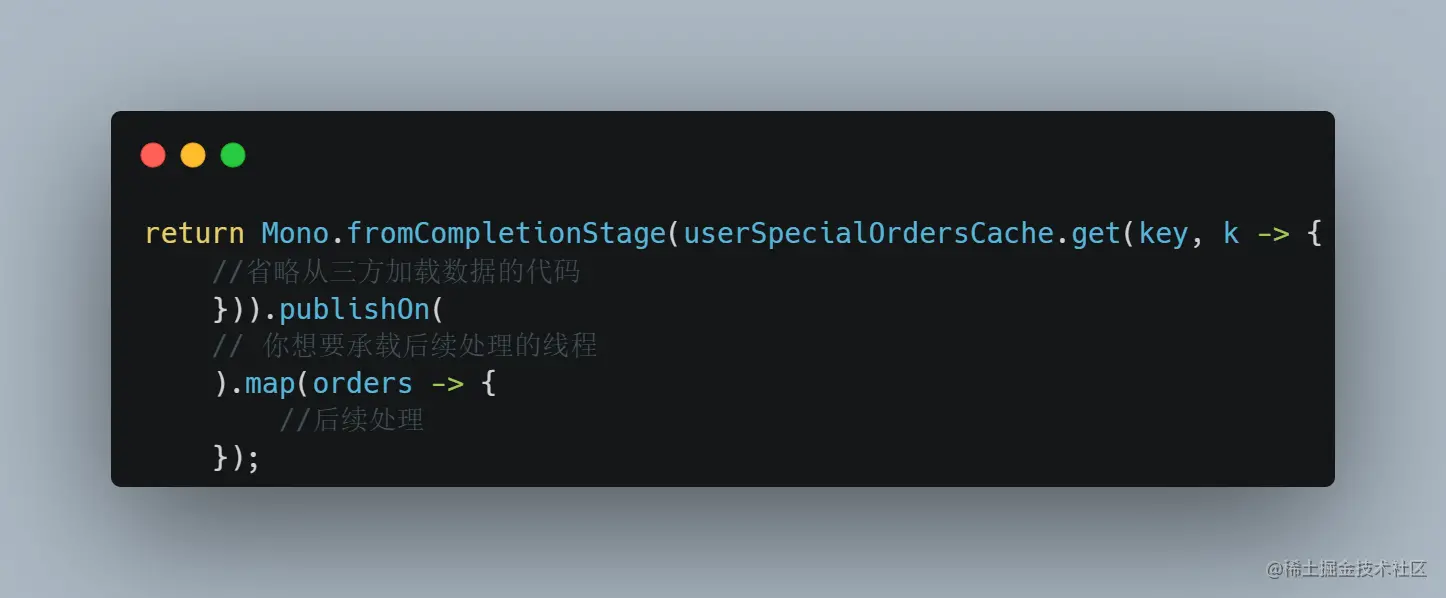
2.外层包裹 webflux 响应式非阻塞代码,最好在缓存之后,切换下线程池为你原始的线程池,否则可能后续有人写代码失误报错,结果报错的线程是加载缓存的线程导致误会,或者引入一些阻塞代码导致加载缓存的线程阻塞让你误会是因为加载缓慢:
最后
以上就是甜美母鸡最近收集整理的关于使用 JFR 定位 Caffeine 同步缓存中的缺陷定位思路问题原因 - Caffeine 同步缓存的机制缺陷改用异步缓存以及注意点的全部内容,更多相关使用内容请搜索靠谱客的其他文章。








发表评论 取消回复