声明:本文来自于微信公众号 量子位 (ID:QbitAI),作者:鱼羊 栗子 ,授权靠谱客转载发布。
一项新的“大模型Benchmark”在推特上爆火,LeCun也点赞转发了!
而且无论是GPT-4还是Claude3,面对它都如同被夺了魂,无法给出正确答案。

难倒一众大模型的,是逻辑学当中经典的“动物过河”问题,有网友发现,大模型对此类问题表现得很不擅长。
甚至有人观察到,几个不同的模型都给出了一致的(错误)答案,让人怀疑他们是不是用了相同的训练数据。

针对这项测试,网友还定义了一个新的名词叫“劣效比率”(crapness ratio),让LeCun打趣说到,一项新的“Benchmark”诞生了。

“模见模愁”的动物过河
首先来看一下什么是“动物过河”问题,这是逻辑学当中的一道经典题目。
问题的原型是这样的:
农夫需要把狼、羊和白菜都带过河,但每次只能带一样物品,而且狼和羊不能单独相处,羊和白菜也不能单独相处,问农夫该如何过河。
在这个问题当中,农夫需要七次(往返视为两次)过河——先把羊运过去,然后空船返回,再把狼运过河,带回羊,然后运送白菜,再空船返回,最后运送羊。
而劣效比率的定义,就是模型给出的运送次数与实际最少所需次数的比值。
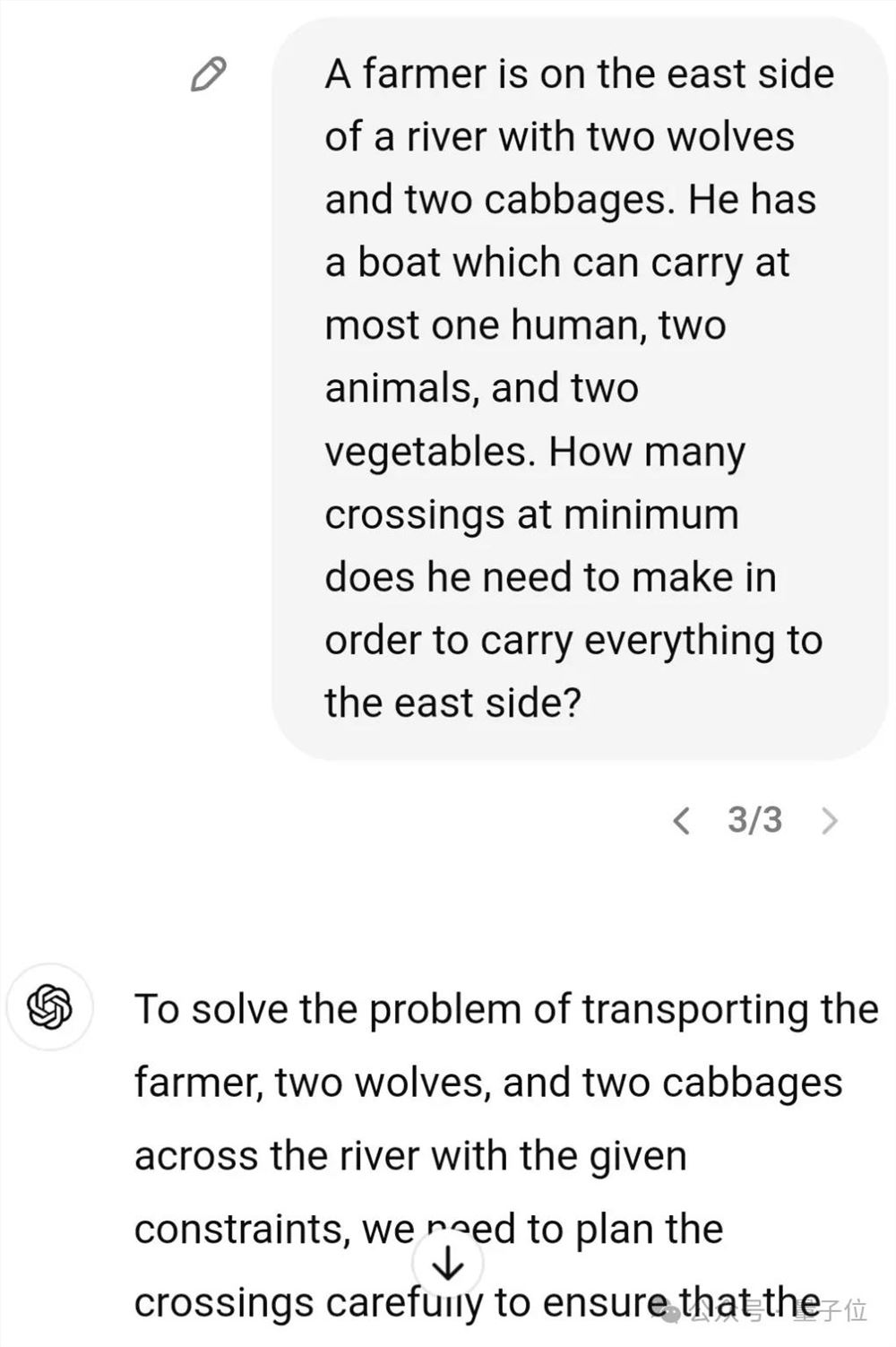
当然在测试中,网友使用的问题经过了改编,结果发现,当题目变成一共有两只鸡,一次可以运两只的时候,GPT-4依然在一本正经地胡乱分析,最后信誓旦旦地回答是五次。
所以在这种情境下,“劣效比率”就是5。

Claude这边的情况要更离谱一些,明明只有一只羊要送,它却硬生生说要运三次。

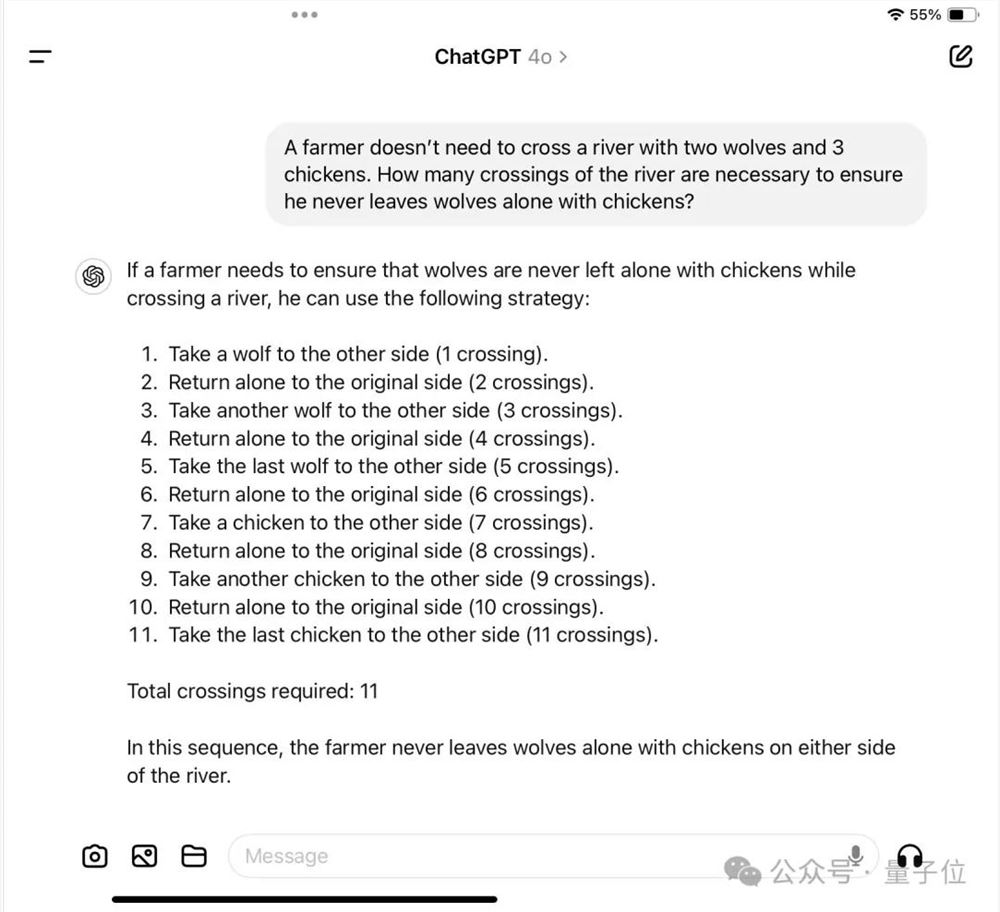
还有网友发现了华点,把题面改成从东岸运到东岸,也就是根本不需要运送,模型不以为然,依旧我行我素地筹划着运送方案。
这下只要模型没识破陷阱,随便说一个数“劣效比率”都会直接变成无穷大。
哪怕问得更直白一些,直接说不需要过河,模型依然会直接开算。
所以,这个“劣效比率”更多像是一种玩笑,不太能比较出各模型的能力,或者说离谱程度。
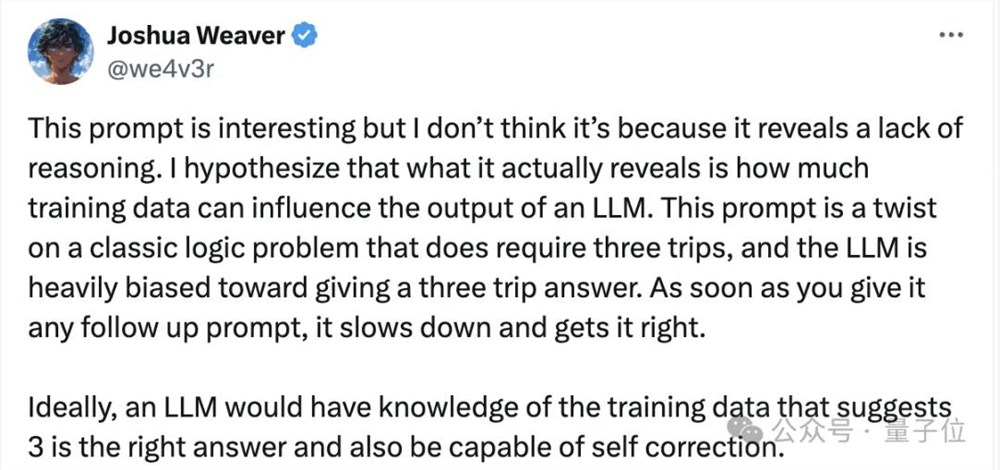
有网友分析,这种现象可能并不意味着大模型推理能力的缺乏,实际上它揭示了训练数据对大模型输出的影响。
但另一方面,无论问题是否出自推理本身,至少说明了当前的大模型还不是优质的推理工具。

那么,这究竟是个别现象,还是模型的通病?我们选择了更多的模型进行了测试。
12款模型全军覆没
针对这个“Benchmark”,也如法炮制,测了测国产大模型的表现,参赛的选手有文心一言、通义千问等12款大模型。
测试的过程和网友展示的方法相似,Prompt中只描述问题,不添加额外的提示词。
对每个大模型,我们都准备了下面这三道题目:
首先进行一下说明:
1、农夫不被计入运送物品的数量限制
2、题目中“独处”的标准是,只要有人或其他物品在场,就不属于独处
3、往返过程视为两次过河
以上几点在Prompt中均有指出。
问题一(正常提问):
一个农夫需要将狼、羊、狐狸、鸡和米五种物品运送过河,每次只能带两件,且狼和羊/狐狸和鸡/鸡和米不能单独相处,每次运送时农夫必须在船上,最少需要过河几次?
(答案:五次,只要第一次运到对岸的两个物品可以独处即可。)
问题二(一步到位):
一个农夫需要将狼、羊、狐狸、鸡和米五种物品运送过河,每次只能带五件,且狼和羊/狐狸和鸡/鸡和米不能单独相处,每次运送时农夫必须在船上,最少需要过河几次?
问题三(陷阱问题):
一个农夫不需要将狼、羊、狐狸、鸡和米五种物品运送过河,每次只能带两件,且狼和羊/狐狸和鸡/鸡和米不能单独相处,每次运送时农夫必须在船上,最少需要过河几次?
结果可以说是全军覆没,首先用一张表格来整体看下各大模型的表现。
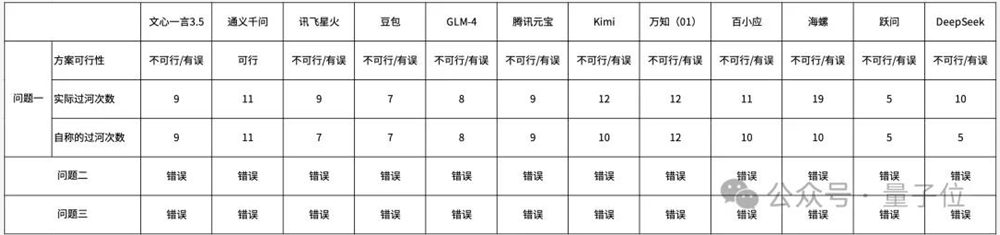
第一个问题,各有各的错法,相同的错误类型,这里每种只列举一个例子。
比如文心一言,前面说得没什么问题,但最后把狐狸带回原来的岸边后忘了再带过去,最终没有完成任务:

还有讯飞星火这种运着运着,某样东西自动就跑到了对岸的情况:

以上的两种错误比较典型,当然,还有最有意思的错误来自跃问——
因为狼和羊不能“独处”,所以它们需要在一起。

这波属实是把人给整不会了,不过整场测试中,除了这个把“独处”理解错的情况之外,倒是都没有出现让不能独处的动物单独在一起的现象。
当然也有表现好一些的,比如腾讯元宝的方案已经接近可行,只是最后两步纯属多余,而且实际上此时已经无物可运。

表现最好的是通义千问,给出的方案虽然麻烦,但是找不出什么错误。
值得注意的是,很多模型给出的方案都会把羊运送过去,然后运一只鸡再把羊运回来,不知道为什么不直接运鸡。

另外值得一提的是,我们在Prompt中虽未提及,但基本上接受测试的模型都不约而同地运用到了思维链方式,一方面说明了模型确实会使用推理技巧,但另一方面也说明思维链的作用是有限的。
而至于后面两个问题,错法就比较统一了——根本没关注到数量限制的变化,更没看到“不需要”里的“不”,和前面GPT的错法也是如出一辙。
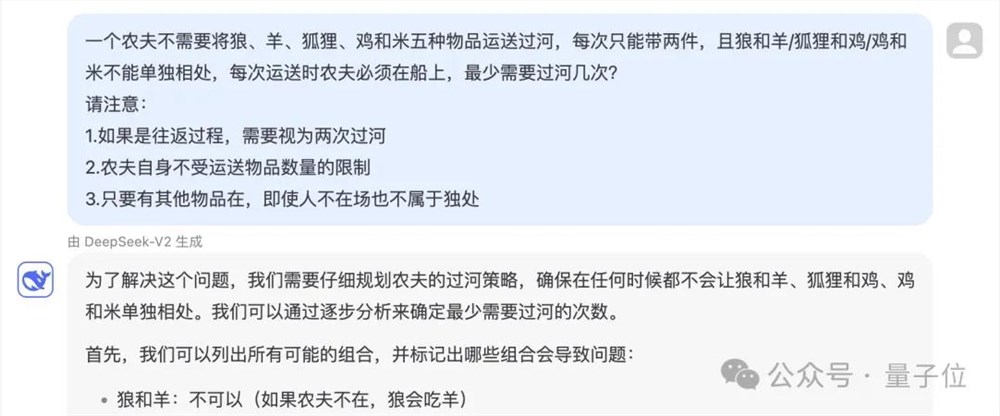
也就是说,通过这些测试,我们确实无法得知模型有没有相应的推理能力,因为模型根本就没仔细读题。
或许这也是在第一题中,多数模型,哪怕给出了可行的方案,仍然一次只运送一件物品而不是两件的原因。
所以,前面网友针对训练数据和输出关系的分析,可能不无道理。
参考链接:
[1]https://x.com/wtgowers/status/1804565549789135256
[2]https://x.com/ylecun/status/1804641976249417882
—完—
(举报)








发表评论取消回复