声明:本文来自于微信公众号 AIGC开放社区(ID:AIGCOPEN),作者:AIGC开放社区,授权靠谱客转载发布。
巴黎矿业大学、以色列理工学院的研究人员联合推出了一款创新视频模型——Slicedit。
Slicedit主要通过结合文生图像的扩散模型以及对视频时空切片的预处理,在不影响背景的情况下对视频主体进行修改。例如,将一名冲浪的男人变成钢铁侠,将一名转球的男孩变成NBA巨星库里,将猫的样子变成豹等。
虽然更改的视频质量并不是很理想,会出现模糊、扭曲的情况。但这种方式对于不会使用AE专业视频编辑软件的业余人员来说帮助巨大,可以快速完成视频内容修改,相当于视频版的PS。用来做鬼畜、抖音、快手类的搞笑视频非常方便。
论文地址:https://arxiv.org/abs/2405.12211

把一名冲浪男人轻松变成钢铁侠,背景没有发生任何改变。

文生图领域涌现出了DALL·E3、Midjourney、Stable Difusion等一大批优秀的产品,但是将其应用在视频编辑却很难,经常出现时间不连贯、动作不一致、背景变动大等问题。而Slicedit通过空间时间切片、扩展注意力、DDPM反演等克服了这些难题。

空间时间切片
在视频处理领域,空间时间切片是从视频的三维空间中提取的二维平面。这些切片可以是固定时间点上的视频帧(即空间切片),或者是在特定方向上跨越时间的连续帧的组合。
在Slicedit模型中,通过空间时间切片使得模型能够处理视频中的动态元素,如运动和变形,还能够在编辑过程中保持背景和其他非目标区域的稳定和完整性。

例如,在将视频中的人物替换为机器人,空间时间切片模块能够确保在替换过程中,背景和其他非人物区域保持不变,从而生成自然且连贯的视频输出。
此外,在空间时间切片的帮助下,Slicedit还能在零样本条件下无需针对特定视频内容进行微调,就能进行视频编辑。模型的灵活、扩展性以及生成效率也得到了增强。
扩展注意力
在传统的注意力机制中,ChatGPT等模型通过自注意力来处理数据,使模型在处理图像或文本时,识别出不同部分之间的关联。
但这种机制在处理视频时存在局限性,因为不能很好地处理时间序列数据。为了解决这个难题,研究人员提出了扩展注意力。
扩展注意力的核心思想是将注意力机制扩展到多个时间步。这意味着模型在处理当前帧时,不仅考虑当前帧的信息,还会考虑与之相邻的帧。通过这种方式,模型能够捕捉到视频帧之间的动态变化,从而生成更加连贯的视频内容。
Slicedit模型中的扩展注意力是,通过修改U-Net网络中的自注意力模块来实现的,在每个Transformer块中引入了扩展注意力机制。
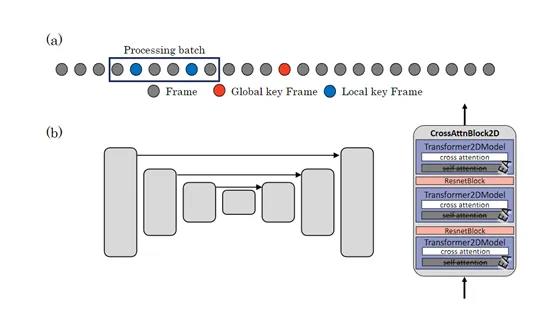
这种机制允许模型在处理视频帧时,同时考虑多个帧的信息。为了实现这一点,模型使用了一组关键帧(Key-Frames),这些关键帧被用来与当前帧进行比较和关联。
首先模型为每个帧生成Query、Key和Value。然后,模型计算当前帧与关键帧之间的注意力分数并通过softmax函数进行归一化。
最后,模型根据这些注意力分数对关键帧的特征进行加权求和,以生成当前视频帧的输出。
DDPM反演
常规的文生图、文生视频都是一种去噪过程,通常会从一个随机噪声向量开始,该向量遵循高斯分布。再通过迭代的方式逐步引入噪声,直至生成高质量的图像或视频。
Slicedit则反推了这个过程,从目标数据例如,从一个视频帧开始,目标是找到一组噪声向量,这些向量在经过DDPM的生成过程后能够重建原始数据。这一过程就是反演,即从数据中提取出噪声,而不是从噪声中生成数据。
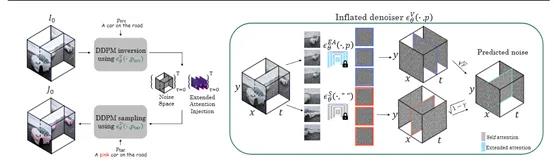
Slicedit模型需要将输入的视频帧转换为噪声空间。这涉及到对视频帧进行逆向处理,以提取出在DDPM的生成过程中用于重建这些帧的噪声向量。
在提取出噪声空间后,接下来需要进行条件去噪,将条件信息例如,文本提示纳入到评估范围,以指导去噪过程,确保生成的视频内容符合用户的二次编辑标准。
研究人员表示,将会很快开源Slicedit模型,帮助更多的开发人员构建自己的视频编辑器。
(举报)








发表评论取消回复