声明:本文来自于微信公众号 机器之心,作者:机器之心,授权靠谱客转载发布。
当你正在观看一部紧张刺激的动作电影,忽然好奇:
“那个角色到底是在哪一集说的那句话?”
“这里的背景音乐是什么?”
又或者在一场足球比赛中,你错过了那个决定性的进球,却又想再次回放。诸如此类的需求,如果仅凭人力寻找,无疑存在极大的工作量。
但是 AI 能够为机器配置双眼与大脑,让它们能够看懂视频、理解剧情,对于普通人来说,这不仅是提高了搜索效率,更是扩展我们与数字世界的互动方式。
英伟达最新发布的 NVIDIA AI Blueprint 希望帮助人们解决这一问题。这是一种预训练的、可自定义 AI 工作流,他为开发者构建和部署用于典型用例的生成式 AI 应用程序提供了一套完整的解决方案。
比如在英伟达提供的试用界面中,你可以选择三个视频片段中的一个进行内容问答。
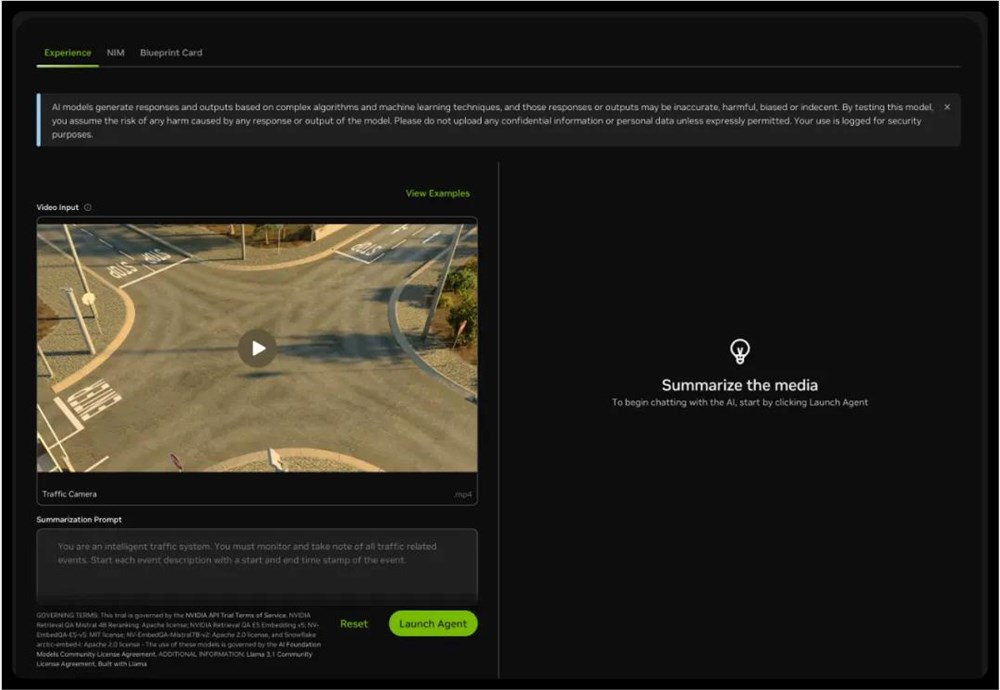
在几轮测试过后,我们发现 Blueprint 对视频问答还是有不错的效果的。你可以提问某个事件发生的时间,也可以提问某个对象的状态。
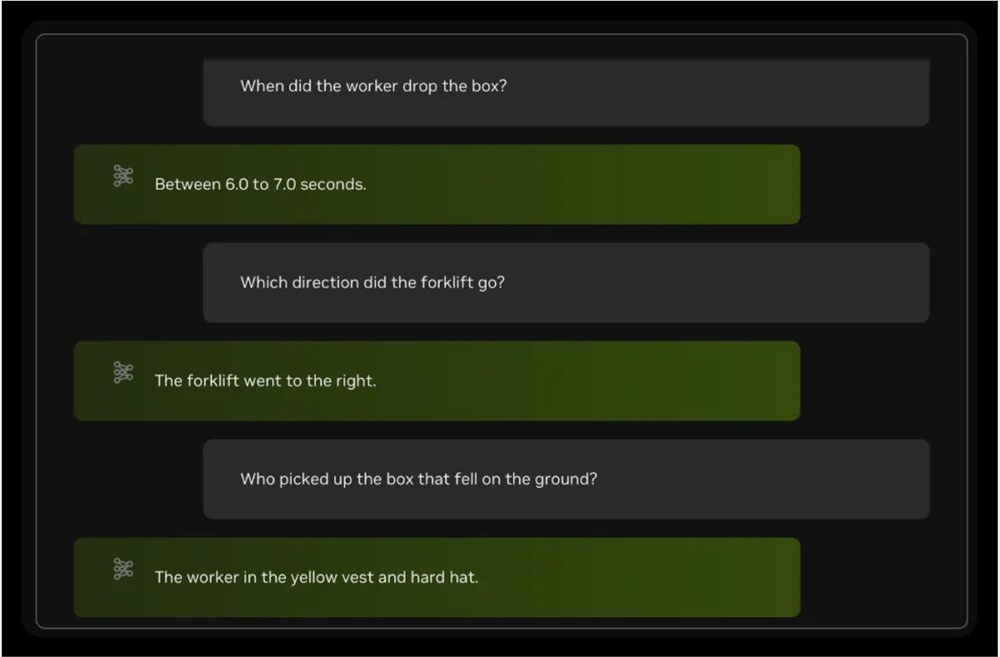
例如当我们提问 “工人在什么时候掉落了箱子”,Blueprint 可以正确的回答出时间区间。二类似于 “叉车往哪个方向开” 这种基于连续过程的问题,Blueprint 也可以轻松应答。
不过对于某些细节,例如 “谁捡起了掉在地上的箱子”,Blueprint 则给出了错误的答案。
尤其令人遗憾的是,在试用过程中我们不断遇到流量限制,无限验证等问题,试用体验可以说一言难尽。并且目前 Blueprint 仍然处于早期申请使用制阶段,没有办法快速进行使用。
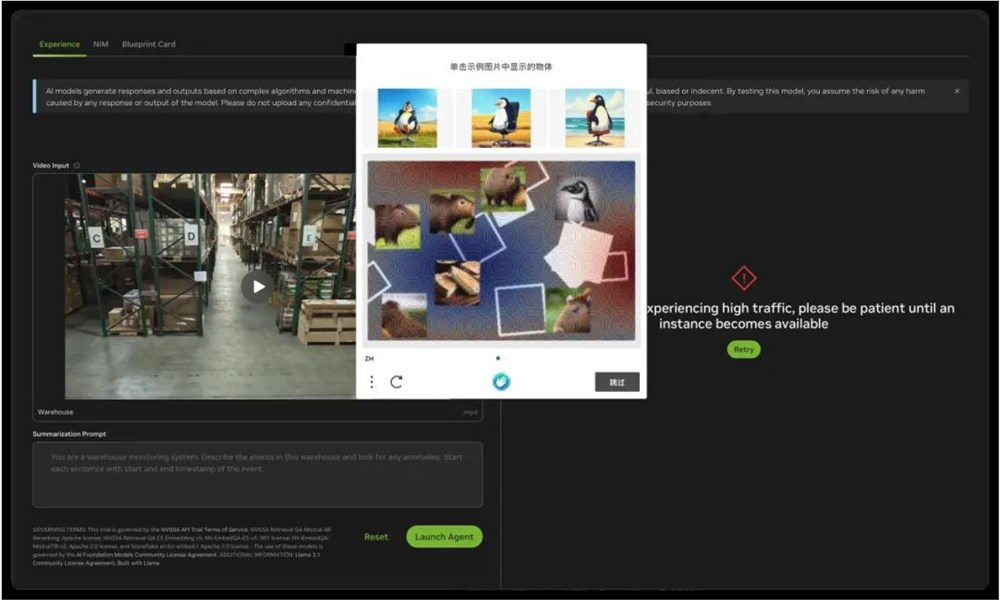
Blueprint 之外,我们还有什么选择?
经过一番搜索和调研,我们在 Github 上发现了 OmAgent 这个项目,这是一个多模态智能体框架,提供了同样强大的视频问答功能。
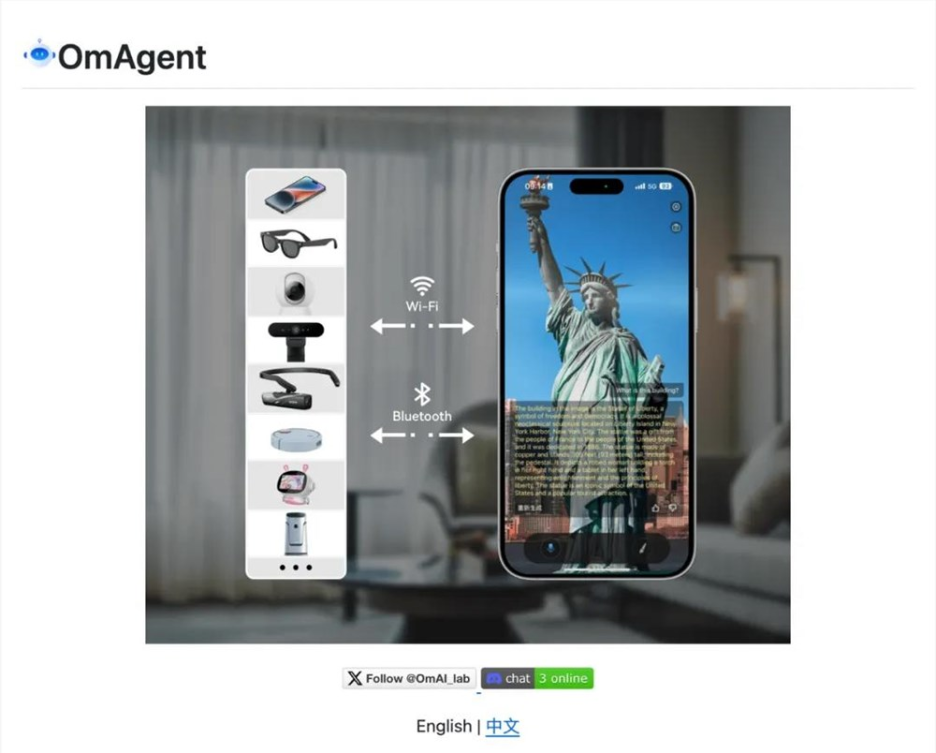
项目地址:https://github.com/om-ai-lab/OmAgent
OmAgent 是什么
OmAgent 是一个开源的智能体框架,支持简单快速地面向设备进行智能体系统的开发,为智能手机、智能可穿戴设备、智能摄像头乃至机器人等各类硬件设备赋能。OmAgent 为各种类型的设备创建了一个抽象概念,并大大简化了将这些设备与最先进的多模态基础模型和智能体算法相结合的过程,使每个人都能基于设备建立最有趣的 AI 应用。
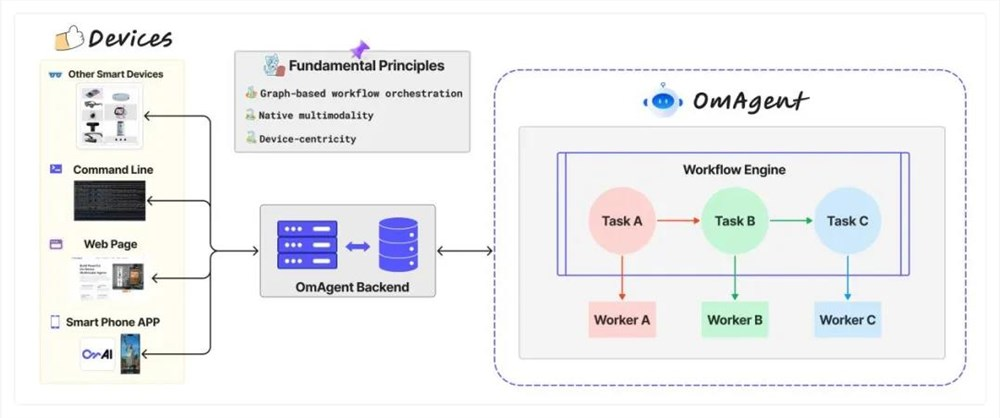
OmAgent 的设计架构遵循三个基本原则:
1. 基于图的工作流编排,支持分支、循环、并行等复杂逻辑操作;
2. 原生多模态,提供对音视图文等多种模态数据的支持;
3. 设备中心化,提供便捷的设备连接和交互方法。
简单来说,开发者可以基于 OmAgent 设计开发基于图工作流编排的面向设备的原生多模态智能体。这里的设备不光包含智能手机,智能可穿戴设备(智能眼镜等),智能家居,还包括命令行以及 web 端,开发者只需要专注于智能体本身,而不用分神处理设备。
OmAgent 项目里提供了6个示例项目,由浅入深展示了如何搭建一个智能体的完整过程,其中视频理解智能体工作流被 EMNLP2024主会收录,实现了和 Blueprint Demo 相似的功能。
OmAgent 表现如何?
根据项目文档只需要进行简单的配置就可以将 OmAgent 部署运行在本地环境。我们首先对 Blueprint 提供的测试视频进行预处理,在这个阶段视频会被分解为若干个片段,每个片段会被大模型进行总结,并向量化存储在数据库中。接下来使用之前的问题对 OmAgent 进行测试,可以看到智能体可以正确定位事件以及发生的时间。
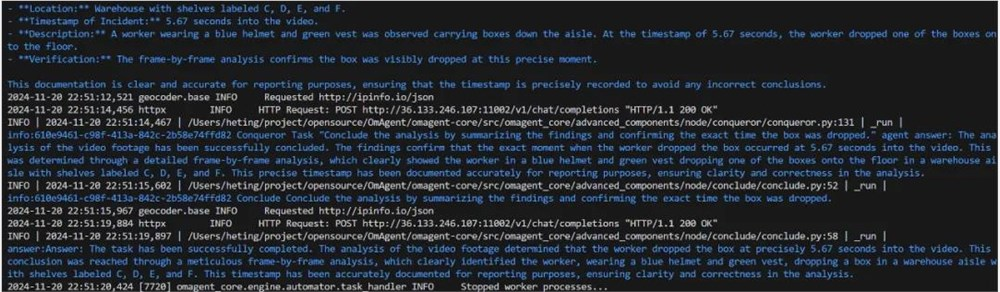
Q: When did the worker drop the box?
A:
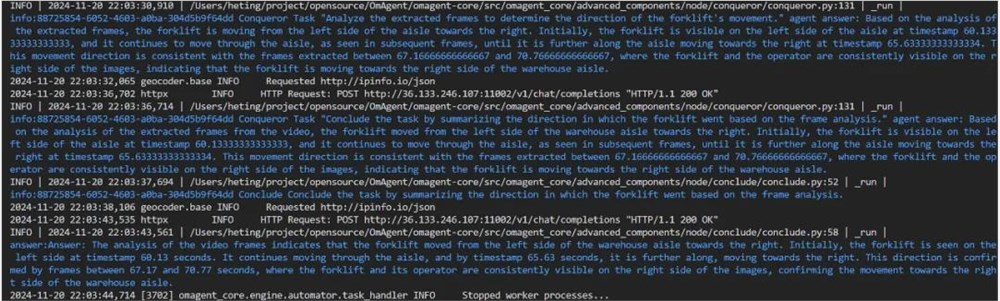
Q: Which direction did the forklift go?
A:
Q: Who picked up the box that fell on the ground?
A:

接下来我们进行更复杂的测试,OmAgent 可以支持音频信息以及超长视频索引。我们选取了最近大火的剧集《双城之战》第二季第一集作为素材,基于其中的画面和剧情进行提问。
Q: 凯特琳收到的钥匙代表了什么?
A:

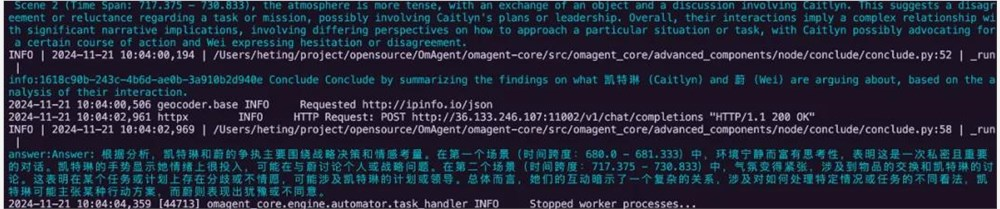
Q: 凯特琳和蔚在争执些什么?
A:
Q: 视频最后几个议员在讨论什么?
A:
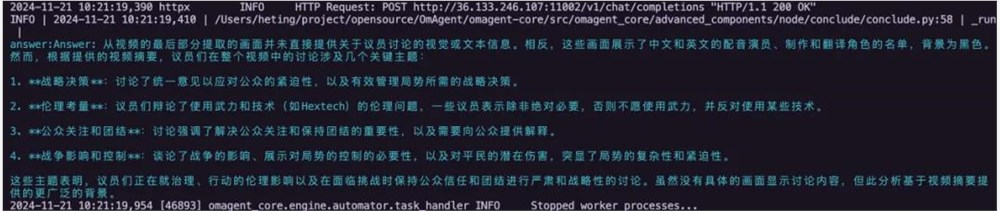
Q: 议员开会的时候谁闯入了进来?
A:
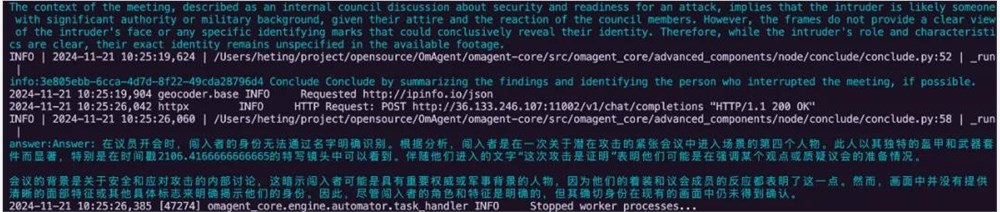
可以看到,即使面对如此复杂的视频素材,OmAgent 依然可以游刃有余。
除了视频问答之外,OmAgent 的最大特点是可以将智能体直接应用在硬件设备上,我们也对此进行了测试。使用项目提供的 app,我们可以运行示例项目中的穿衣搭配推荐智能体。智能体会根据你的需求,以及你已有的衣橱信息,为你推荐合适的穿衣建议。在这个过程中智能体会和用户进行多轮沟通以确定用户需求,并最终返回最合适的搭配。
如果你也刚好试用过 OmAgent,欢迎在评论区交流。
(举报)








发表评论取消回复