声明:本文来自于微信公众号量子位 | 公众号 QbitAI,作者:明敏,授权靠谱客转载发布。
大模型理解复杂表格,能力再次飞升了!
不仅能在不规则表格中精准找到相关信息,还能直接进行计算。
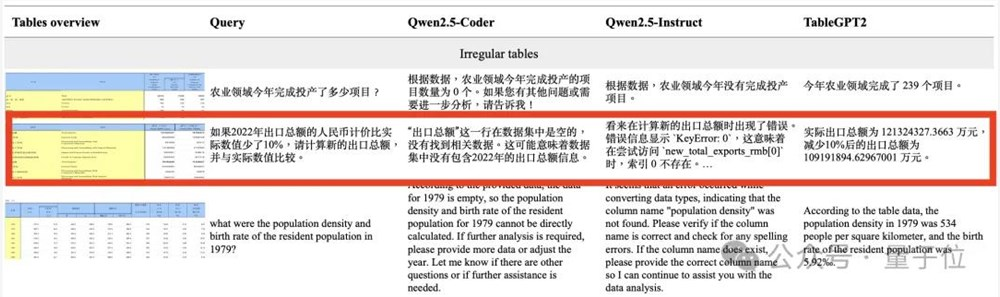
比如提问:
如果2022年出口总额的人民币计价比实际数值少了10%,请计算新的出口总额并与实际数据比较。
普通的大模型要么找不到正确的单元格信息,要么会计算错误。
而最新模型给出了正确回答:
实际出口总额为121324327.3663万元,减少10%后的出口总额为109191894.62967001万元。
这就是由LeCun高徒、浙江大学博导赵俊博领衔打造的TableGPT2。
它首次将结构化数据作为独立模态进行训练,这意味着大模型将不再依赖长上下文窗口,而是直接理解数据库、Excel、数仓中的数据,进而搞定SQL、分析、增删改查等相关任务。

要知道,结构化数据已是无处不在,从BI(商业智能)到当下爆火的具身智能,大模型想要被更充分精准应用于这些领域,就不能再单纯以“文科生”的形式去学习。
由此赵俊博等人耗时1年带来了更强大的TableGPT2。
在23个基准测试中,TableGPT2都表现优异,平均性能提高35.20%(7B模型)和49.32%(72B模型)。
目前团队已将两个版本的模型、一个Agent工作流以及RealTabBench中的一个子集开源。
关键在表格编码器
在TableGPT2之前,业界几乎没有人尝试将结构化数据作为独立模态。这主要有两方面原因——
第一,数据库中表格的空间关系存在特殊性。比如在图像视频上任意交换像素或者词的token,都会改变数据的本质,这说明两种模态之间具备空间依赖关系。但是在数据库的表格中,随机交换2行或2列数据,表格本身并不会变化。目前我们缺乏工具和手段去应对结构化数据这种特点。
第二,结构化数据存在异质性。比如在CV领域,RGB是很客观的表达,红色就是红色,蓝色就是蓝色,自然语言也是一样。但是在结构化数据中,同样一个表格字段下面的标记,在不同数据库里的意义可能截然不同。比如都是“1,2,3”,不同图表中表示的内容可能完全不同。所以这种“异质性”要求大模型对整体的库、表和字段都有理解,才能给出实际意义。这部分的对齐和传统LLM对齐不太一样。
不过这些问题也不是完全不能解决。
赵俊博介绍,针对表格数据,如果掩码掉一个“子表”的一些单元格,加上字段、数据库的信息辅助,是可以才出来掩码信息的内容。这意味着尽管结构化数据的空间关系比较弱,但是本身还是有分布可以去学习的。
由此,研究团队提出了TableGPT2工作。
它基于Qwen2.5系列模型,使用超过860亿token进行预训练,给大模型喂入了超过59.38万张表和236万高质量的查询-表-输出样本,并创新性加入了一个表格编码器,专门用于读取和解释表格数据。
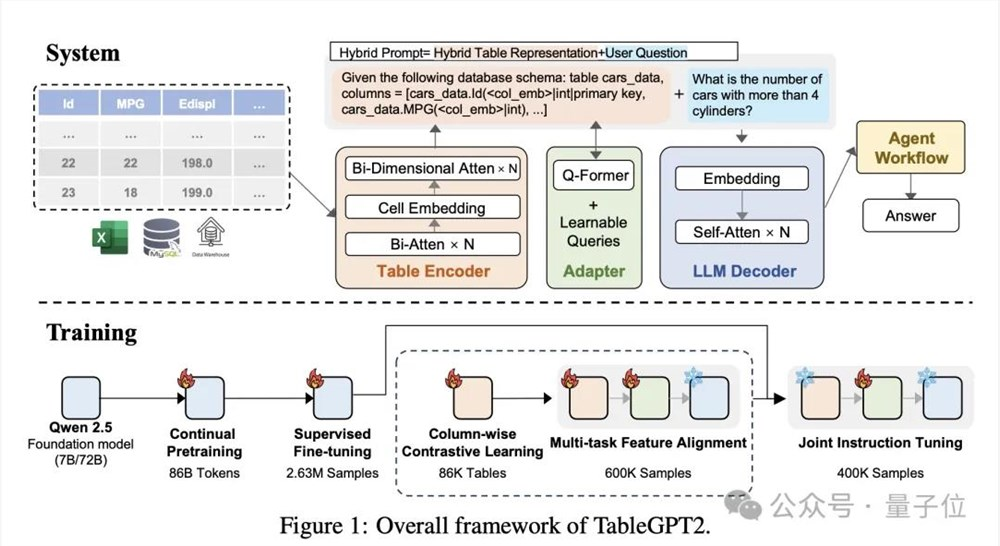
模型主要框架包括以下几个部分:
表格编码器
LLM解码器
持续预训练
监督微调
Agent工作流
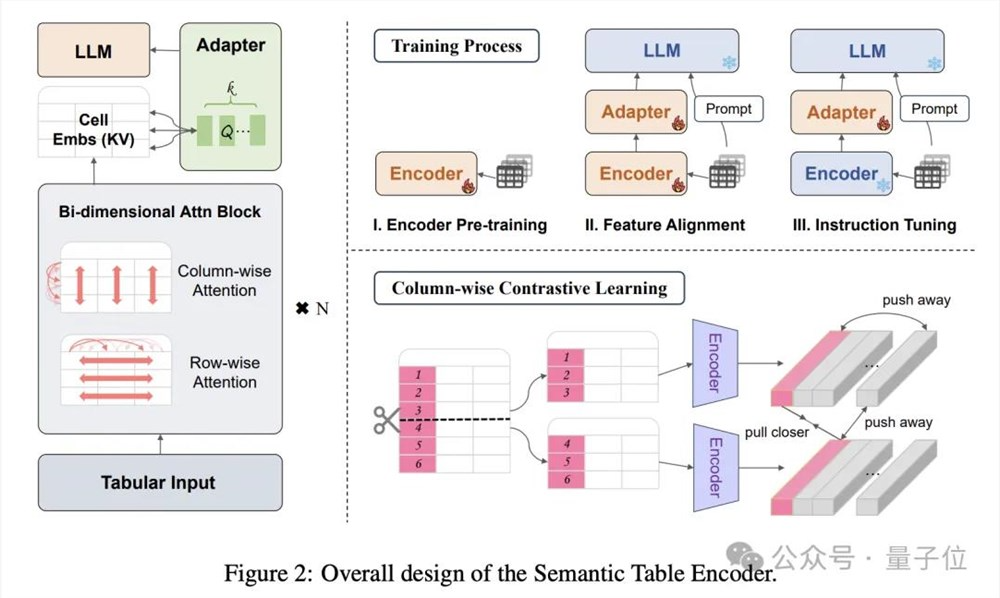
表格编码器支持输入整个表格,生成每列的紧凑嵌入。
采用双维注意力机制,无需位置嵌入,同时进行分层特征提取,确保行和列的关系被有效捕捉。
再使用列对比方法,鼓励模型学习有意义的、结构感知的语义表示。
具体实现上,通过Q-former样式适配器对齐嵌入和文本输入,引入可学习的查询。
使用特殊标记(如”
应用联合指令微调来增强文本信息、列嵌入和模式单元数据之间的对齐,提高模型对表格数据的理解和解释能力。
值得一提的是,这个表格编码器可以单独使用。作者团队透露,后续还将发表相关论文。
LLM解码器则基于Qwen-2.5模型,用于自然语言生成。
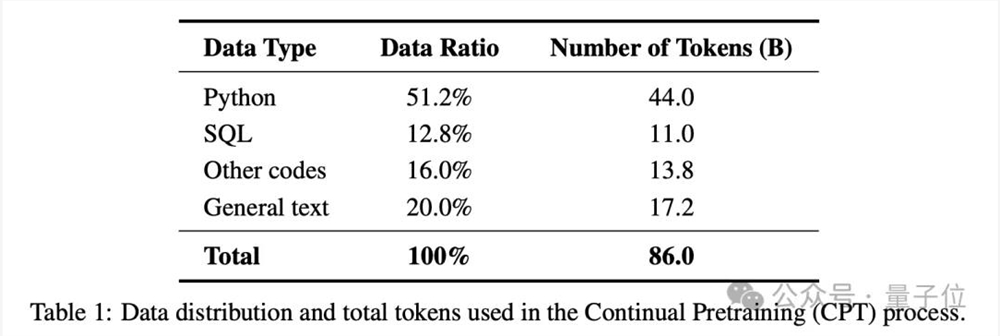
具体训练部分,预训练阶段首先针对模型的编码和推理能力进行加强。80%的预训练数据是有优质注释的代码,这和DeepSeek-v2的方法一致,以确保强大的编码能力。
同时还融入了大量推理数据和特定领域知识(比如金融、制造、生物等),以增强推理能力。
在数据处理层面,采用两级过滤策略。
文档层面将数据标记为54个不同类别,token层面利用RHO-1来微调高质量token。

预训练部分的数据由86B个token组成。
进行监督式微调主要是为了提高模型在BI特定任务中的表现。
作者构建了一个包含236万条样本的数据集,主要覆盖多轮对话、复杂推理、工具使用和高度特定的业务查询场景,包含代码生成、数据可视化、统计测试和预测建模等表格任务。
通过模糊化字段引用、匿名化字段名等方法增强模型在处理复杂任务时的鲁棒性。
最后来看Agent框架。
该框架由运行时prompt、代码沙箱和agent评估模块共同增强agent的能力和可靠性。
具体工作流如下。首先通过prompt模块处理输入查询,经过检索增强处理后将查询输入到主模型中。然后TableGPT2与VLM协作,生成工具调用、代码或其他相关操作。利用智能体的反思能力,观察中间结果,判断是否需要迭代。最终得到输出。

部分基准下超越GPT-4o
实验阶段,作者将TableGPT2与其他大模型进行性能对比。
对比对象主要分为两类。
第一类为主流开源大模型,包括DeepSeek-Coder-V2-Lite-16B、YiCoder-9B-Chat、Qwen2.5-Coder-7B-Instruct和Qwen2.5-7B-Instruct。
第二类为针对表格相关任务进行微调或专门开发的模型。包括TableLLMs和CodeLlama-13B。
实验主要评估模型的6方面任务:表格理解、问答、事实论证、表格到文本、自然语言到SQL、整体评估。
在不同benchmark上,各个模型表现如下。TableGPT2显著优于绝大部分其他模型,并在一些基准上超越GPT-4o。
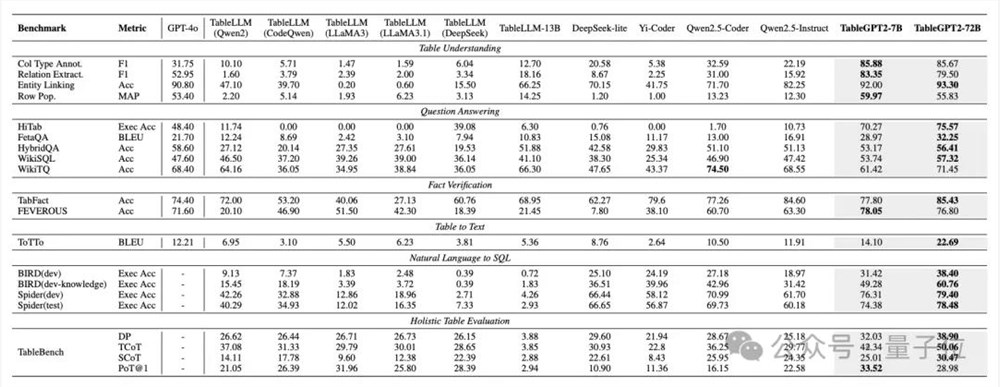
结果显示,TableGPT2的7B模型和72B模型的平均准确率分别提高了35.20%和49.32%。
此外,考虑到当下benchmark中针对表格异形问题、匿名问题或者治理较差的情况兼顾不佳,而实际落地中90%以上case都会出现类似情况。
作者还构建了一个新的benchmark——RealTabBench。它更加关注实际应用中真实出现的问题。
结果显示在RealTabBench上,TableGPT2表现也是最好。

另外,TableGPT2不会导致基座模型通用能力下降。

LeCun高徒“砸锅卖铁”开发
该研究来自浙江大学计算机与科学技术学院计算创新研究所。
由助理教授、博士生导师赵俊博领衔。
赵俊博于2019年获得纽约大学计算机专业博士学位,师从图灵奖得主、Meta首席AI科学家、纽约大学教授Yann LeCun。
他曾在Meta(原Facebook)人工智能实验室(Facebook AI Research)任研究员,期间深度参与了深度学习主流框架PyTorch和向量数据库Faiss的开发,并曾参与了内部通用对话机器人项目的前沿研究,该工作被视为大模型方向的早期产品化工作之一。
曾于2015年供职于英伟达半年时间,联合主持开发了全球首个端到端的自动驾驶解决方案,该工作由英伟达创始人Jensen Huang在次年的GTC 大会上做隆重介绍。
截至目前论文总被引数已超过20000次。
去年,赵俊博主持研发了TableGPT。
这是全球首款对接关系数据库和数据仓的大模型产品。
2024年,团队又继续“砸锅卖铁”,给TableGPT升级了V2版本。

作为高校团队,开发一个大模型意味着算力上要砸钱、数据收集工程优化上要出人,这中间有非常多的坑,需要消耗巨大人力财力。
而且TableGPT2的开发还有着诸多难点。
首先在技术上,构建一个在table上单独模态的编码器很难弄。它独有的复杂结构和空间特点,以及字段语义信息对齐等,都有考验。
其次在数据方面。结构化数据怎么收集、清洗?标签体系怎么定制?如何把合成数据和人工数据合并?怎么做到成本可控,都是问题。
以及监督微调部分,不光需要输入输出样本对,而且需要收集表,专业领域的数据表还需要专业人士进行标注……
不过为啥还是要做呢?
因为他们看到了大模型理解结构化数据背后更广阔的应用前景。
赵俊博向量子位介绍,作为高校团队,他们现在的工作更多是为了“趟路”。
做结构化这件事,我们不会停留在Excel或者数据库上面,下一步技术发展肯定是往硬件和具身智能领域上走。
灵巧手的触觉信息,还有具身智能领域的视觉、听觉等,广义来说都属于结构化数据,我们还想往这个方向再往前一步。
与此同时,TableGPT2也会在产业落地上试水,希望能给从业者提供更好用的底座模型。
目前,团队已经开源了这项工作的多个成果,后续也会发布表格编码器的相关研究,感兴趣的童鞋可以进一步了解~
[1]论文地址:https://arxiv.org/html/2411.02059v1
[2]一个可用agent的git仓库:https://github.com/tablegpt/tablegpt-agent
[3]模型开源:https://huggingface.co/tablegpt/TableGPT2-7B
—完—
(举报)








发表评论取消回复