声明:本文来自于微信公众号 新智元,作者:新智元,授权靠谱客转载发布。
【新智元导读】Robin3D通过鲁棒指令数据生成引擎(RIG)生成的大规模数据进行训练,以提高模型在3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。
多模态大语言模型(Multi-modal Large Language Models, MLLMs)以文本模态为基础,将其它各种模态对齐至语言模型的语义空间,从而实现多模态的理解和对话能力。近来,越来越多的研究聚焦于3D大语言模型(3DLLM),旨在实现对3D物体以及复杂场景的理解,推理和自由对话。
与2D MLLM所能接触的广泛的多模态数据不同,3DLLM的训练数据相对稀少。
即便过去有些工作尝试生成更多的多模态指令数据,但这类模型仍然在指令的鲁棒性上存在两点不足:
1. 绝大多数3D多模态指令数据对是正样本对,缺乏负样本对或者对抗性样本对。模型在这种数据上训练缺乏一定的辨识能力,因为无论被问到什么问题,模型只会输出正面的回答。因此碰到问题与场景无关时,模型也更容易出现幻觉。这种模型有可能只是记住了正样本对,而非真正地理解被问及的场景、物体、以及具体的指令。
2. 由于在造数据的过程中,人类标注员或者生成式大语言模型是按照既定的规则去描述物体的,很多由这些描述所转换而来的指令缺乏多样性。甚至有的数据是直接按照模板生成的。
为了解决以上问题,伊利诺伊理工大学、浙江大学、中佛罗里达大学、伊利诺伊大学芝加哥分校提出一个强大3DLLM——Robin3D,在大规模鲁棒数据上进行训练。

论文地址:https://arxiv.org/abs/2410.00255
文中提出了「鲁棒指令数据生成引擎」(Robust Instruction Generation, RIG),可以生成两种数据:
1. 对抗性指令数据。该数据特点在于在训练集或者单个训练样本中,混合了正样本和负样本对(或者对抗样本对),从而使得模型在该类数据集训练能获得更强的辨识能力,该数据包含了物体层面到场景层面的、基于类别的指令和基于表达的指令,最终形成了四种新的训练任务,帮助模型解耦对正样本对的记忆。
2. 多样化指令数据,首先全面收集现有研究中的各种指令类型,或将一些任务转化为指令跟随的格式。为了充分利用大语言模型强大的上下文学习能力,研究人员使用ChatGPT,通过为每个任务定制的特定提示工程模板来多样化指令的语言风格。
将这些与现有基准的原始训练集相结合,研究人员构建了百万级指令跟随样本,其中约有34.4万个对抗性数据(34%)、50.8万个多样化数据(50%)和16.5万个基准数据(16%),如图1(右)所示。
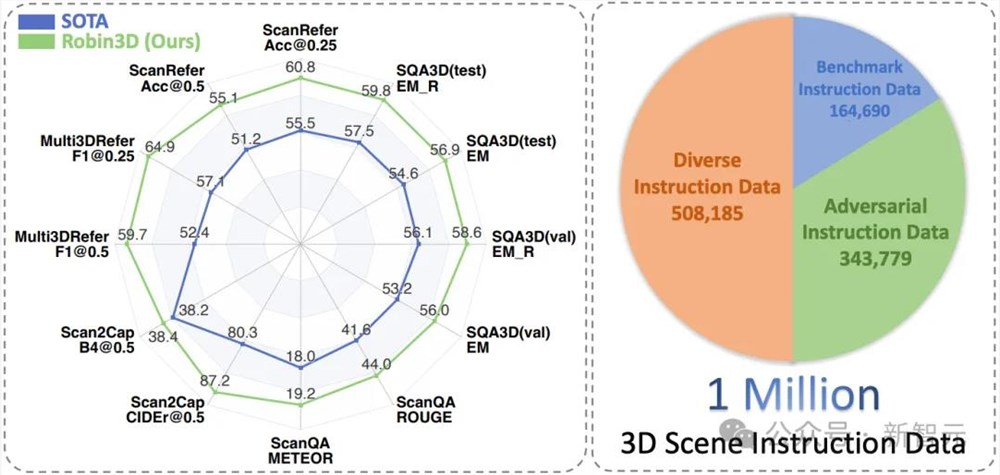
图1Robin3D在构建的百万级数据上训练(右),最终在所有3D多模态数据集上的性能超过之前的SOTA(左)
Robin3D在模型上与Chat-Scene类似:使用Mask3D,Uni3D来抽3D物体级别的特征,使用Dinov2来抽2D物体级别的特征,使用物体ID来指定和定位物体。
先前的方法在抽物体特征的时候,由于其物体级别的规范化(normalization),不可避免的丢失了物体间的3D空间关系。同时简单的物体ID和物体特征拼接缺乏对ID-特征的充分联结,使其在这种复杂的指令数据上面临训练的困难,而Robin3D引入了关系增强投射器来增强物体的3D空间关系,并使用ID-特征捆绑来增强指代和定位物体时ID与特征之间的联系。
最终Robin3D在所有的3D场景多模态数据集上达到一致的SOTA,并且不需要特定任务的微调。
方法
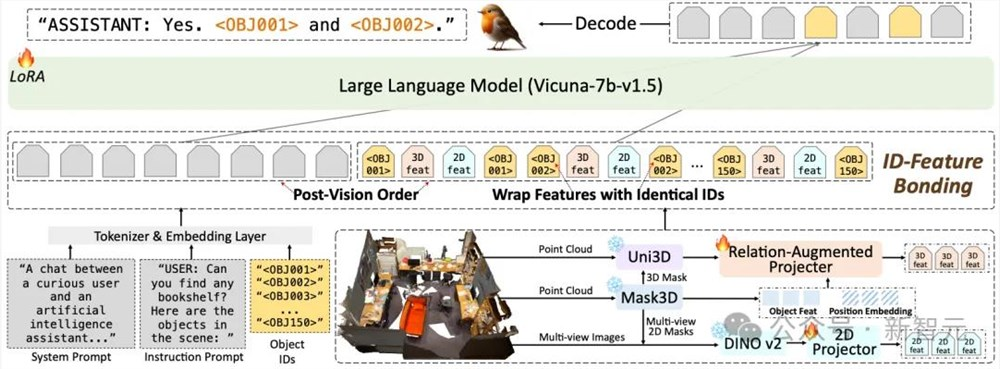
图2Robin3D的模型结构
关系增强投射器
如图2所示,关系增强投射器(Relation-Augmented Projector, RAP)考虑三种特征:
1. Mask3D所抽取的场景级别特征,这种特征经过多层cross-attention充分交互了语意和位置关系;
2. Mask3D里的位置嵌入特征,这种特征由物体超点直接转换而来,代表了物体间的位置关系。
3. Uni3D抽取的统一物体级别特征,这种特征和语言进行过大规模的对齐训练。
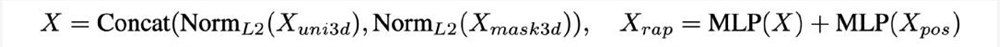
图3RAP公式
如图3所示,通过MLP和短接的方式,对三种特征进行高效的融合,最终实现了即保持强大的统一物体级别语意信息、又增强了物体之间的空间位置关系。
ID-特征捆绑
如图1所示,的ID-特征捆绑(ID-Feature Bonding, IFB)主要包含两个操作。首先,使用两个相同的ID来包裹其物体特征。
由于LLM的因果注意力机制,这种方法通过第一个ID将ID信息与物体特征关联起来,并通过第二个ID将物体信息与其ID关联起来。
其次,提出了一个后视觉顺序,将视觉tokens放置在输入序列的末尾,靠近模型生成的答案标记。
该方法减少了由于tokens间的相对距离和LLM中旋转位置嵌入所导致的从答案tokens到ID-特征tokens的注意力减弱问题,同时增强了视觉信息对答案tokens的注意力影响,从而提升答案生成效果。
鲁棒指令数据生成引擎
对抗性数据生成

图4对抗性数据的四种任务
如图4,的对抗性数据形成了四种新的具备挑战性的任务HOPE、HROC、PF-3DVG和3DFQA,包含了从物体到场景、从基于类比到基于表达的不同指令。
图4左上:Hybrid Object Probing Evaluation (HOPE)
为了构建一个场景级别的基于类别的任务,引入了HOPE,灵感来自2D领域的POPE基准。POPE通过询问关于单个物体存在与否的是/否问题,评估2DMLLMs产生幻觉的倾向。在此基础上,HOPE将这种幻觉挑战扩展到3D领域的训练阶段,旨在让模型更具辨别力。
此外,HOPE引入了一个混合场景,增加复杂性,进一步推动模型对记忆中的视觉与语言正样本的解耦。
具体来说,在给定的3D场景中,要求模型判断多个随机指定的物体是否存在。物体可能存在或不存在,且每个存在的物体可能有一个或多个实例。
当物体不存在时,模型需回答「否」;当物体存在时,需回答「是」并提供每个实例的物体ID。这一设置结合了正负物体的混合识别与多实例物体定位,具有很高的挑战性。
图4右上:Hybrid Referring Object Classification (HROC)
指代物体分类任务旨在评估模型在2D域中识别指代区域的能力,使用「区域输入,文本输出」的形式。HROC将此任务扩展到3D领域,创建了一个物体级别的基于类别的任务,并结合了对抗性和混合挑战。
在3D场景中,随机生成混合的正负ID-类别样本对来提出问题。正样本对包含一个有效的物体ID和对应的真实类别,负对则包含一个有效的物体ID和随机选择的非真实类别,作为对抗性挑战。模型需对正样本对回答「是」,对负对回答「否」并给出正确类别。
图4左下:Partial Factual3D Visual Grounding (PF-3DVG)
PF-3DVG引入了一个场景级别的基于表达的任务,涵盖三种数据类型:非真实数据、部分真实数据和真实数据。
非真实数据:在3D场景中,随机选择Sr3D+中的描述,其中所描述的物体不存在与当前3D场景。模型需回答「否」。
部分真实数据:给定Sr3D+的描述及对应的3D场景,随机修改描述中的空间关系。例如,将「沙发上的枕头」改为「沙发下的枕头」。
模型需纠正信息并回答「它是在『上面』」,同时提供物体ID。团队确保描述的目标物体类别是当前场景唯一的、无干扰项,以避免歧义。真实数据:随机增强空间关系的同义词以提高多样性,例如,将「below」替换为「under」、「beneath」或「underneath」。
图4右下:Faithful3D Question Answering (3DFQA)
原始的3D问答任务仅包含正样本,可能导致模型记住固定的3D场景和问答对。为了解决这一问题,提出3DFQA,一个结合了负样本和正样本的场景级别的基于表达的QA任务,其增加了定位的要求。
构建负样本时,从ScanQA中抽取问答对,并收集问题或答案中的相关物体,然后随机选择一个缺少这些物体的3D场景。在原来的问题上,新增一个指令:「如果可以,请回答……并提供所有ID……」。
此时,模型必须回答「否」,并且不提供任何物体ID,体现其对场景的依赖而不会胡言乱语总给出正面回复。正样本直接取自ScanQA,模型需回答问题并提供相关物体的ID作为答案的依据。
因此,训练在的3DFQA数据集上的模型不能依靠记忆,而是要学会对正负样本做出忠实回应并有理有据。
多样化数据生成
多样化数据旨在通过结合多种不同任务类型的指令数据,并提高指令的语言多样性,从而增强模型的泛化能力。首先从基准数据集之外的不同任务中收集大规模数据。
具体而言,给定一个3D场景,收集以下任务的问答对:类别问答任务(来自Chat-Scene),Nr3D描述生成任务(转换自Nr3D),外观描述生成任务(来自Grounded-3DLLM),区域描述生成任务(来自Grounded-3DLLM),端到端3D视觉定位(转换自Nr3D),端到端3D视觉定位(转换自Sr3D+)。
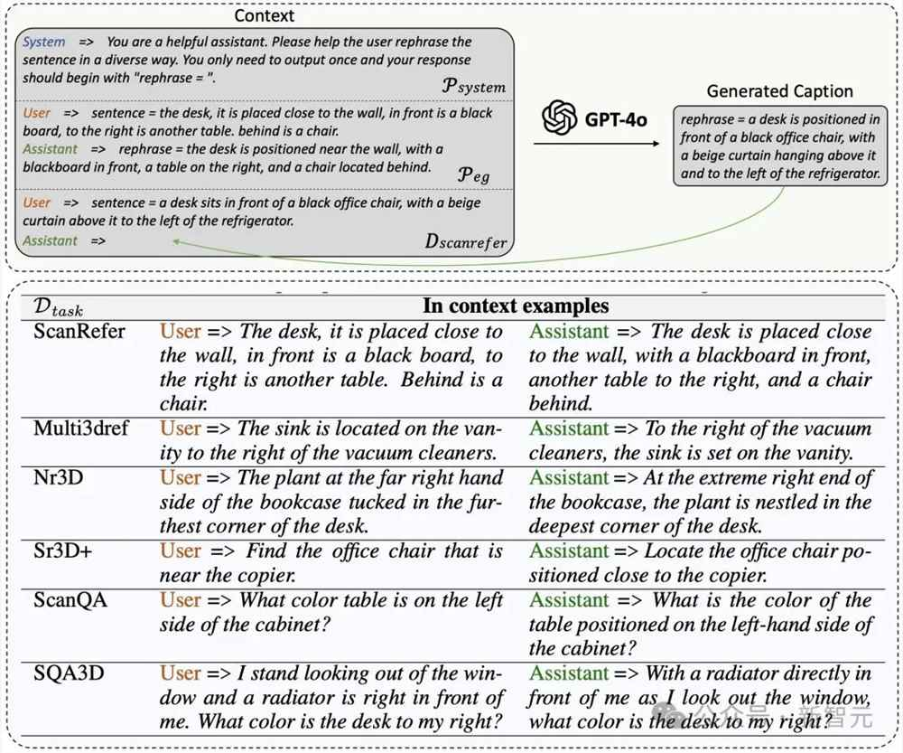
图5多样化数据的生成流程和详细的提示工程
为了丰富表述风格,开发了一个可扩展的流程,利用ChatGPT的上下文学习能力对上述数据进行重述。这通过一组示例和结构化提示工程实现,如图5(上)所示。
具体而言,给定一个收集的指令数据集D_task(其中任务包括ScanRefer、Multi3DRefer、Nr3D、Sr3D+、Nr3D Captioning、ScanQA、SQA3D、PF-3DVG和3DFQA),构建了一个系统提示P_system,以指示重述的要求和结构化的输出格式,同时提供一个示例提示P_eg,以帮助ChatGPT更好地理解要求。
还随机选择一个温度参数T(从[1.1,1.2,1.3]中选取)以增加输出的随机性和多样性。的重述输出D_rephrase通过公式D_rephrase = M(P_system, P_eg, D_task, T)生成,其中M是ChatGPT的GPT-4o版本。
图5(上)详细说明了P_system和P_eg的内容,以ScanRefer数据为例。通过使用sentence=和rephrase=的结构化提示,GPT-4o能够轻松遵循要求,可以通过检测rephrase=关键字方便地收集输出。
图5(下)提供了每个任务的示例提示的详细信息。由于Nr3D Captioning源于Nr3D,PF-3DVG源于Sr3D+,而3DFQA源于ScanQA,因此不再为这些任务提供额外示例。
实验
主要结果
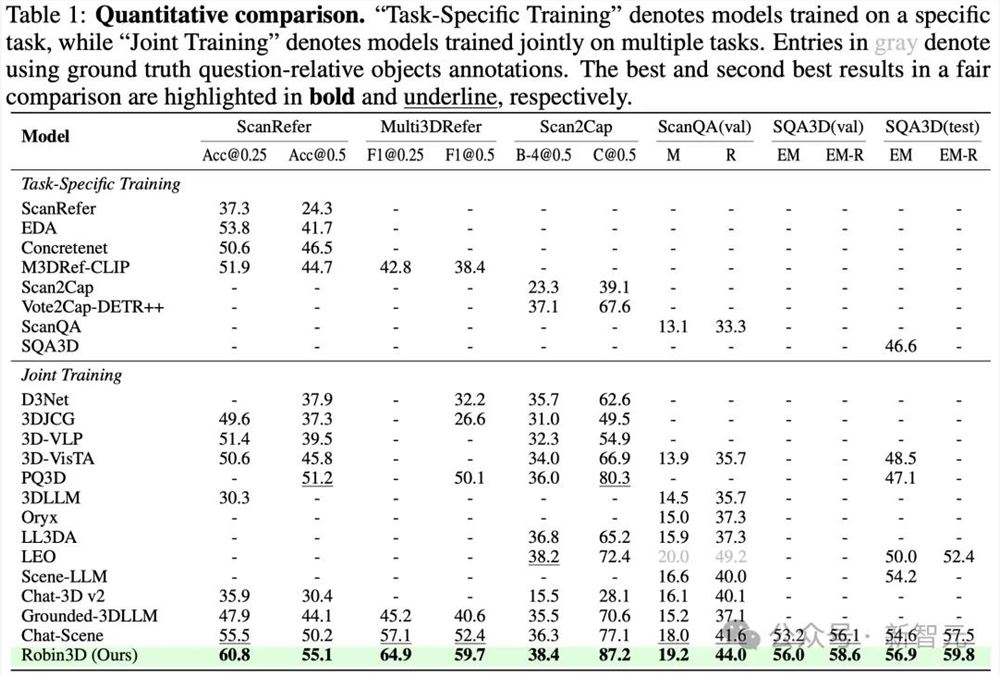
表1性能对比结果
如表1所示,由于RIG生成的鲁棒指令数据,Robin3D在所有基准测试中显著超越了之前的模型。具体而言,Robin3D在Scan2Cap CIDEr@0.5上带来了6.9%的提升,在ScanRefer Acc@0.25上带来了5.3%的提升。值得注意的是,在包含零目标案例的Multi3DRefer评估中,这些案例对模型的区分能力提出了挑战,并要求模型能够回答「No」。的Robin3D在F1@0.25上实现了7.8%的提升,在F1@0.5上实现了7.3%的提升。
消融实验
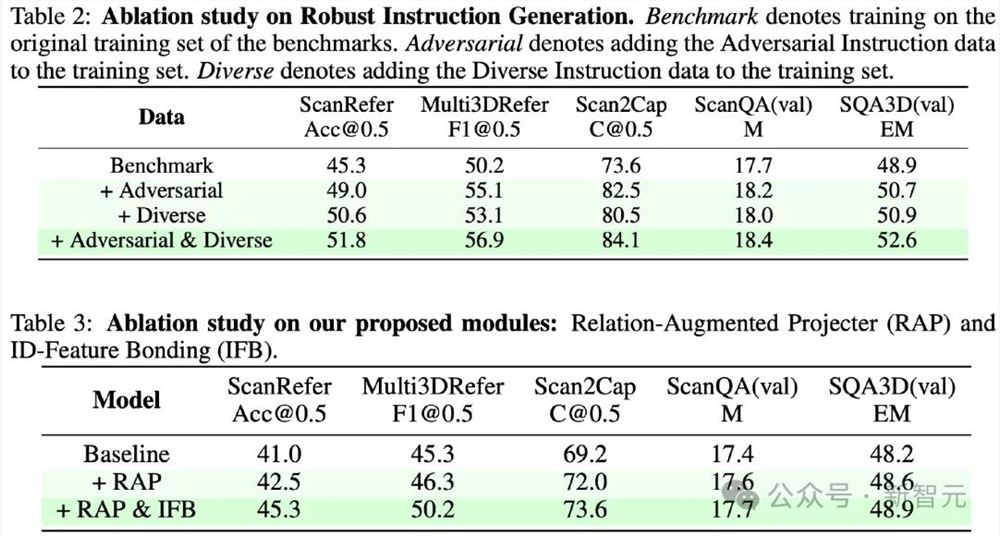
表2和表3消融实验结果
如表2和表3所示,对提出的对抗性数据和多样化数据进行了消融实验,也对模型结构上RAP和IFB的提出做了消融实验。实验结果在所有benchmark上都证明了他们一致的有效性。
特别的,在表2中,对抗性数据对描述生成任务Scan2Cap带来了8.9%的提升,然而对抗性数据是不存在描述生成任务的,并且也不存在同源的数据(Scan2Cap数据源自ScanRefer, 但对抗性数据无源自ScanRefer的数据)。这种大幅的提升体现了对抗性数据对模型识别能力的提升。
参考资料:
https://arxiv.org/abs/2410.00255
(举报)








发表评论取消回复