声明:本文来自于微信公众号 机器之心 作者:杜伟、蛋酱,授权靠谱客转载发布。
今年5月,OpenAI 首次展示了 GPT-4o 的语音功能,无论是对话的响应速度还是与真人声音的相似度,都颇为惊艳。特别是它允许用户随时打断,充分感知到用户的情绪并给予回应。
大家突然发现,原来 AI 语音通话还能这么玩?
但由于种种原因,用户们等了好久才等到 OpenAI 开放 ChatGPT 的高级语音功能,目前仅 Plus 和 Team 用户可体验,且这些用户每天也有使用时长限制。
不过现在,国内用户也有了同样丝滑的实时语音交互应用,重点是:免费开放,无需等待。
10月25日,智谱清言宣布全量上线「情感语音通话」功能,任何用户都可以立即获得端到端情感语音体验。
对标 GPT-4o,智谱清言「情感语音通话」在响应和打断速度、情绪感知情感共鸣、语音可控表达、多语言多方言等方面实现了突破。简单来说,「情感语音通话」提供了一个真人一般的对话伙伴,而不仅仅是一个文字的朗读者。
精通各种方言,比如这段北京烤鸭的介绍,那叫一个地道:
与此同时,智谱还重磅宣布,该功能背后的情感语音模型 GLM-4-Voice 同步正式开源。不久后,相关能力还将上线视频通话,为所有用户提供一个既能「看」又能「说」的 AI 语音助理。
开源地址:https://github.com/THUDM/GLM-4-Voice
自大模型浪潮兴起的两年来,AI 技术的发展日新月异,有时甚至超过我们的想象,让大家直呼科幻时代提前到来。
当然,这背后所代表的技术趋势也不断变化。比如在人类的想象中,「Any-to-Any」才是真正属于未来的人与 AI 交互方式。具体来说,AI 能做到接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合输出。
如今,智谱清言的「情感语音通话」又一次推动了国产 AI 对标国际先进水平。
情感语音模型 GLM-4-Voice
上线即开源
自从去年的 GPT-4发布之后,领域内就一直在传 GPT-5的各种消息。但我们后来都知道,OpenAI 并未通过简单粗暴地增加模型参数来拓展智能上限,而是选择了两条路线分别开拓:一条是 GPT-4o 所代表的端到端多模态大模型的探索,一条是 o1所代表的关于推理 Scaling Law 的探索。
具体到 GPT-4o 上,OpenAI 跨文本、视觉和音频端到端地训练了一个新模型,所有输入和输出都由同一神经网络处理。行业内认为,这是一种可以将音频直接映射到音频作为一级模态的技术方法,涉及 Token 化和架构等方面的研究,总体来说是一个数据和系统优化问题。
在这方面,智谱也已经有了一定的技术积累。智谱清言情感语音通话功能背后的 GLM-4-Voice,同样是一个端到端的语音模型。
与传统的 ASR + LLM + TTS 的级联方案相比,GLM-4-Voice 以离散 Token 的方式表示音频,实现了音频的输入和输出的端到端建模,在一个模型里面同时完成语音的理解和生成,避免了传统的「语音转文字再转语音」级联方案过程中带来的信息损失和误差积累,且拥有理论上更高的建模上限。
具体来说,智谱基于语音识别(ASR)模型以有监督方式训练了音频 Tokenizer,能够在12.5Hz(12.5个音频 token)单码表的超低码率下准确保留语义信息,并包含语速,情感等副语言信息。语音合成方面,智谱采用 Flow Matching 模型流式从音频 Token 合成音频,最低只需要10个 Token 合成语音,最大限度降低对话延迟。
预训练方面,为了攻克模型在语音模态下的智商和合成表现力两个难关,智谱将 Speech2Speech 任务解耦合为 Speech2Text(根据用户音频做出文本回复) 和 Text2Speech(根据文本回复和用户语音合成回复语音)两个任务,并设计两种预训练目标,分别基于文本预训练数据和无监督音频数据合成数据以适配这两种任务形式:
Speech2Text:从文本数据中,随机选取文本句子转换为音频 Token
Text2Speech:从音频数据中,随机选取音频句子加入文本 Transcription
GLM-4-Voice 预训练数据构造。
与传统的 TTS 技术相比 (Text-to-Speech),GLM-4-Voice 能够理解情感,有情绪表达、情感共鸣,可自助调节语速,支持多语言和方言,并且延时更低、可随时打断。
能够在情感的把握上做到如此精准,是因为 GLM-4-Voice 在 GLM-4-9B 的基座模型基础之上,经过了数百万小时音频和数千亿 token 的音频文本交错数据预训练,拥有很强的音频理解和建模能力。为了支持高质量的语音对话,智谱设计了一套流式思考架构:输入用户语音,GLM-4-Voice 可以流式交替输出文本和语音两个模态的内容,其中语音模态以文本作为参照保证回复内容的高质量,并根据用户的语音指令变化做出相应的声音变化,在保证智商的情况下仍然具有端到端建模 Speech2Speech 的能力,同时保证低延迟性(最低只需要输出20个 Token 便可以合成语音)。

GLM-4-Voice 模型架构图。
伴随着 GLM-4-Voice 的推出,智谱在通往 AGI 的道路上又迈出了最新一步。
一句指令自动操作电脑、手机
AutoGLM 同步上线
在情感语音通话全面开放的同时,智谱也宣布了另一项前沿成果:AutoGLM。
让 AI 像人类一样操作电脑和手机,是近期领域内的热点话题。以往这是一项颇具挑战性的任务,因为在此类场景下,AI 需要根据用户的要求拆解指令背后蕴含的步骤,感知环境、规划任务、执行动作,逐步完成任务。某种程度上说,这突破了大模型的常规能力边界,更加注重其「工具」属性。
很多大模型公司都在探索这一方向,锚定其为「下一个 AI 前沿」。基于大语言模型(GLM 系列模型)、多模态模型和工具使用(CogAgent 模型)等方面的探索,智谱已经在由自主智能体(Agent)驱动的人机交互新范式方面取得了一些阶段性成果。
在智谱最新发布的 AutoGLM App 中,用户可以凭借一句指令让 AI 自动完成许多任务,比如阅读网页信息、电商产品购买、点外卖、订酒店、评论和点赞微信朋友圈等。目前,AutoGLM 已开启内测(暂时仅支持 Android 系统)。
在 AutoGLM App 发布之前,AutoGLM-Web 已经通过「智谱清言」插件对外开放使用。这是一个能模拟用户访问网页、点击网页的浏览器助手,可以根据用户指令在私域网站上完成高级检索并总结信息、模拟用户看网页的过程进行批量、快速的浏览并总结多个网页,结合历史邮件信息回复邮件。
在 Phone Use 和 Web Browser Use 上,AutoGLM 都取得了大幅的性能提升。在 AndroidLab 评测基准上,AutoGLM 就显著超越了 GPT-4o 和 Claude-3.5-Sonnet 的表现。在 WebArena-Lite 评测基准中,AutoGLM 更是相对 GPT-4o 取得了约200% 的性能提升,大大缩小了人类和大模型智能体在 GUI 操控上的成功率差距。
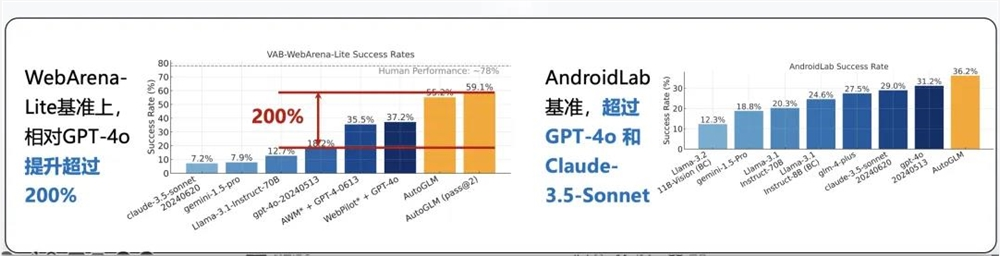
我们知道,当代人工作和生活中的大部分事项都需要通过计算机和手机完成,一旦让 AI 学会像人类一样直接与计算机和手机端的软件交互,就能拓展出大量当前一代 AI 助手无法实现的应用。
面向 AGI,智谱这样规划技术路线图

从文本的一种模态,到包括图像、视频、情感语音模型在内的多模态,然后让AI学会使用各种工具。基于GLM-4-Plus,智谱过去几年在多模态领域探索取得了一些阶段性成果:CogView 能让文字化作一幅幅画作,CogVideo / 清影(Ying)让文图生成一帧帧视频,GLM-4V-Plus 带来了通用的视频理解能力。GLM-4-Voice的出现让 GLM 多模态模型家族更加完整,为朝着原生多模态模型又迈出了一步。
虽然在产品矩阵上全面对标 OpenAI,但可以看出,在追求 AGI 终极目标的过程中,智谱 AI 慢慢展现出了一些不同于 OpenAI 的思考,比如对 AI 分级的思考,这也影响了这家科技公司所走的技术路线。
如果将 AI 的能力从低到高划分为 Level1-Level5,则从当前各家 AI 大模型来看,Level1语言和多模态能力、Level2逻辑与思维能力和 Level3工具使用能力成为了主流认知。因此,包括智谱在内的大模型厂商都在实现这些能力的路上一路狂奔。
智谱此次揭露了其面向 AGI 的路线图。除了单一模态的端到端大模型之外,智谱未来希望打造各种模态混合训练的统一多模态模型,不仅认知能力要比肩人类,还要与人类价值观保持一致,做到能力出众的同时要安全可控。
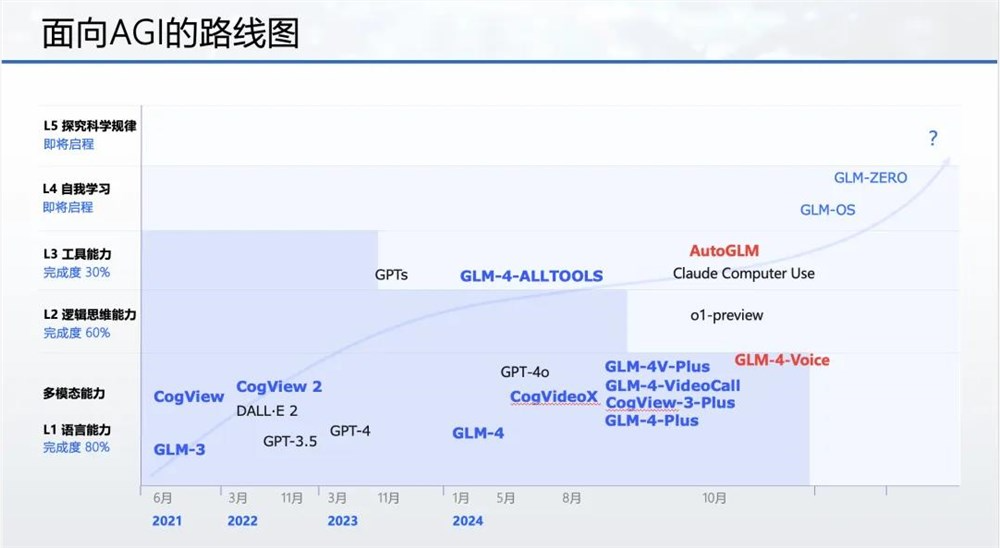
在 Level3阶段,智谱拿出了最新武器 AutoGLM,具备了更强大的全栈式工具使用能力,并越来越像人一样通过感知环境、规划任务、执行任务并最终完成特定任务。同时伴随着人机交互范式的转变,智谱也离其未来打造以大模型为中心的通用计算系统 GLM-OS 的目标更近了一步。
可以说,截止目前, 前三阶段的竞争大家都走得差不多,差别就在于更高阶段的 Level4和 Level5,OpenAI 探索的是 AI 自己能够发明创新并最终融入组织或自成组织。在这两个决定未来 AI 能力走向的关键阶段,如今的智谱有了更全面的定义和解读。
在智谱的愿景中,未来 AI 在 Level4不仅要具备发明创造能力,还要全方位地追求「内省」,具备自我学习、自我反思和自我改进能力;到了最终的 Level5,也就是实现 AGI,AI 的能力将首次全面超越人类,并开始向探究科学规律、世界起源等终极问题发起挑战。
与此同时,如果将 AI 与人脑做一个类比,AI 在多大程度上能够达到人脑水平呢?智谱认为,从目前大模型具备的文本、视觉、声音以及逻辑和工具使用能力来看,在未来相当长一段时间内将处于42%这个阶段。因此,想要达到最终的 AGI,持续深拓已有能力并解锁未知能力是关键。
AI 技术发展到今天,已经为我们展开了一幅美好画卷。在未来,由人类创造的强大 AI 将真正使大众受益,而智谱也是推动这一里程碑的重要参与者。
(举报)








发表评论取消回复