声明:本文来自于微信公众号深思SenseAI(ID:gh_a54fc6d3826c),作者:深思SenseAI,授权靠谱客转载发布。
近日,Epoch AI更新了他们对机器学习远期趋势的研究报告,在计算、数据、硬件、算法、成本等多个维度对人工智能模型趋势进行了深入研究。
Epoch AI是一家研究机构,致力于研究影响人工智能发展轨迹和治理的关键趋势和问题,以造福社会。其报告中的研究结论联合了包括 StandfordHAI 在内的多个学术机构发布,部分研究成果在 ICML 等期刊会议发布,是目前市面上相对权威的趋势预测来源。
01.
计算趋势:
前沿 AI 模型的训练计算量每年增长4-5倍
AI 训练中使用的计算量是 AI 进步的关键驱动因素。Epoch AI 对300多个机器学习系统的分析表明,从2010年到2024年5月,用于训练近期模型的计算量每年增长4-5倍。我们发现前沿模型、近期的大型语言模型以及领先公司的模型也出现了类似的增长。
最先进的 AI 模型发展速度有多快?AI 训练中使用的计算量是 AI 进步的关键驱动因素。Epoch AI 对300多个机器学习系统的分析表明:
自2010年以来,著名 ML 模型的训练计算量每年增长4.1倍。而从1956年到2010年, 著名 ML 模型的训练计算量每年增长1.5倍。
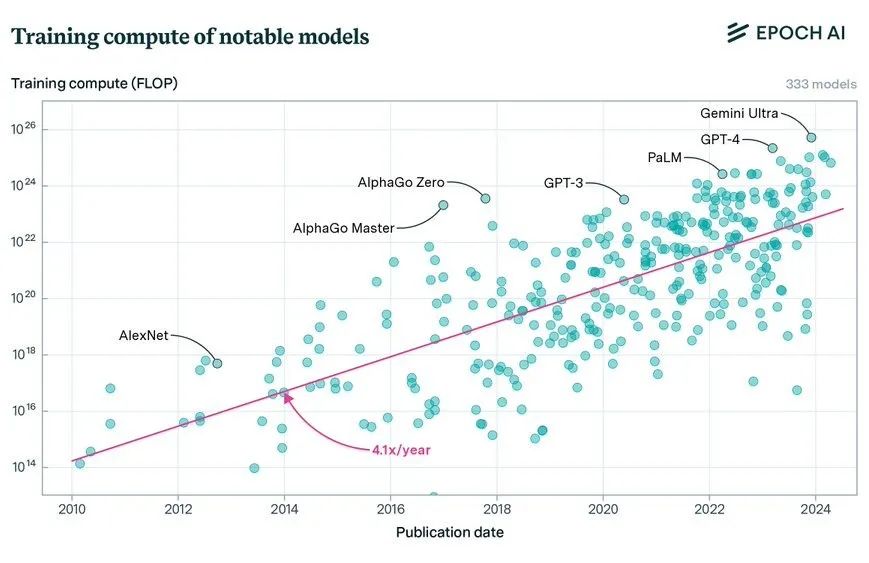
对排名前10名的前沿模型进行统计观测:
在2018年前,模型计算量的增长速度快于总体趋势,高达6.7x/年,或许反映了实验室加入 AI 竞赛。
2018年之后,前沿模型的增长放缓至4.2x/年,与总体趋势趋于一致。

语言模型是当今最重要的模型之一。前沿 LLM 在过去十年中经历了快速的计算增长,在 GPT-3(2020年)之后放缓至每年5倍。

领先的人工智能实验室,包括OpenAI、Google DeepMind 和 Meta AI,一直在以与总体趋势相对一致的速度扩展其模型,平均每年增长5-7倍。

每年4-5倍的增长速度是令人难以置信的,需要面临巨大的工程和科学挑战才能维持。训练很快将涉及管理数十万个 GPU 的集群,并使用它们高效地训练更大的模型。
Gemini Ultra 可能是迄今为止计算最密集的模型,其最后一次训练运行的总训练计算量估计为5e25FLOP。
02.
数据趋势
2028年前,人类的文本Token会被消耗殆尽
有多少文本可以用于训练?
Common Crawl(CC) 是一个广泛使用的爬取数据存储库,包含超过100万亿个 Token,大约是最大数据集的10倍。
Epoch AI 采用常用于研究搜索引擎的方法来估算索引网站的大小。使用CC等网络语料库计算词频,然后在Google搜索词频不同的单词,并记录每个单词的页面数量。由此计算出索引网络上大概有500万亿个Token,排除掉不适合LLM训练的数据集,最终网络文本库存将下降至100万亿个 Token。
那么何时会耗尽网络上的文本?在大概100T Token上训练一个4个Epochs的模型大概会消耗~5e28FLOP的计算资源,预计比GPT4高出3个数量级(OOMs),根据模型算法的增长速度,大概在2028年会达到这个临界点,如果过度训练,这一时间甚至会更早到来。

目前,Llama370B 表示其接受了15万亿个Token的训练,使其成为公开确认的拥有最大训练数据集的模型。
当然,还有一些未编入索引的“深层”网络和私人数据。Epoch AI估算,在Facebook、Instagram 和 WhatsApp 等社交媒体和消息应用中有约3000T Token。
为了在2028年(或5e28FLOP)之后保持当前的进展速度,开发或改进替代数据源(如合成数据)似乎至关重要。尽管挑战仍然存在,但这些挑战可以使机器学习继续扩展到公共文本之外。
03.
硬件趋势:
ML 硬件的 FLOP/s 性能每2.3年翻一番
Epoch AI 使用2010年至2023年机器学习实验中常用的47个机器学习加速器(GPU 和其他 AI 芯片)来研究 GPU 等硬件的计算性能发现:
大型硬件集群对于最先进的 ML 模型训练和推理的整体性能取决于多种因素,包括 GPU 本身的计算性能、内存容量、内存带宽和互连。ML 硬件加速器中的 FLOP/s 性能每2.3年翻一番,内存容量和带宽每4年翻一番。
鉴于现代 ML 训练运行需要数千个芯片的有效交互,因此内存和互连带宽是利用大型分布式 ML 训练场景中的峰值计算性能的瓶颈。
使用硬件成本或估算的云成本计算 GPU 性价比:ML GPU 的计算性价比 [FLOP/$] 每2.1年翻一番,通用 GPU 每2.5年翻一番。

使用TDP(芯片的热设计功率)计算ML 硬件的能效:ML GPU 的能源效率 [FLOP/s/瓦特] 每3.0年翻一番,通用 GPU 每2.7年翻一番。

04.
算法趋势:
语言模型性能每5到14个月翻一番
在对 LLM 的算法升级进行研究时,Epoch AI发现,算法进步使得模型实现给定性能水平所需的计算量大约每8个月减半,95% 的置信区间为5到14个月,再次超过摩尔定律。
尤其是两个特别值得注意的算法创新,一个是Transformer 架构,他的引入相当于该领域近两年的算法进展。另一项创新是另一项创新是Chinchilla缩放定律的引入,相当于8到16个月的算法进展。

Epoch AI 在研究模型性能改善时,尝试归因算法的影响比重。其数据发现,计算效率的提高解释了自2014年以来语言建模性能改进的大约35%,而计算规模的增加则解释了模型65% 的性能改进。

05.
成本趋势:
模型训练成本每9个月翻一番
Epoch AI 估算了45个前沿模型,根据模型训练期间的硬件折旧和能耗来计算训练成本,发现自2016年以来,训练前沿 ML 模型的美元成本,总体增长率为每年2.4倍。同时,自2016年以来,用于训练前沿 ML 模型的硬件购置成本,每年增长2.5倍。

在过去几年中,头部大厂的模型成本竞赛已经到了新的数量级。根据最新数据,开发 Gemini Ultra 的总摊销成本(包括硬件、电力和员工薪酬)估计为1.3亿美元。用于训练 Gemini Ultra 的硬件购置成本估计为6.7亿美金。
按照当前的训练成本增长速度,预计在2027年,最大的模型成本将超过10亿美金。

在拆分模型训练成本时,Epoch AI 分析了几个主流选定模型的开发成本。这些模型包括 GPT-3、OPT-175B、GPT-4和 Gemini Ultra。
研究发现,目前AI加速器芯片、其他服务器组件和互连硬件的总成本占总成本的47-67%,而研发人员成本占29-49%(包括股权),能源消耗占剩余成本的2-6%。

虽然当前能源只占成本的一小部分,但由于模型所需的电力容量很大,目前Gemini Ultra 预计需要35兆瓦。简单推断到2029年,人工智能超级计算机将需要千兆瓦级的电力供应。
(举报)








发表评论取消回复