我是靠谱客的博主 灵巧网络,这篇文章主要介绍(二)ElasticSearch实战基础教程(ElasticSearch入门)1.ElasticSearch基础概念2.节点、集群、分片及副本3.文档的CRUD & 批量操作4.倒排索引5.分词器6 Search API,现在分享给大家,希望可以做个参考。
1.ElasticSearch基础概念
1.1 文档(Doucument)
1.ElasticSearch是面向文档的,文档是所有可搜索数据的最小单位
·日志文件中的日志项
·一本电影的具体信息/一张唱片的详细信息
·MP3播放器里面的一首歌/一遍PDF文档中的具体内容
2.文档是会被序列化成JSON格式,报错在ElasticSearch中
·JSON对象由字段组成
·每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
3.每个文档都有一个Unique ID
·你可以自己指定ID
·或者通过ElasticSearch自动生成
1.2JSON文档
一篇文档包含了一系列的字段,类似数据库表中一条记录
JSON文档格式灵活不需要预先定义格式
·字段的类型可以指定或者通过ElasticSearch自动推算
·支持数组/支持嵌套
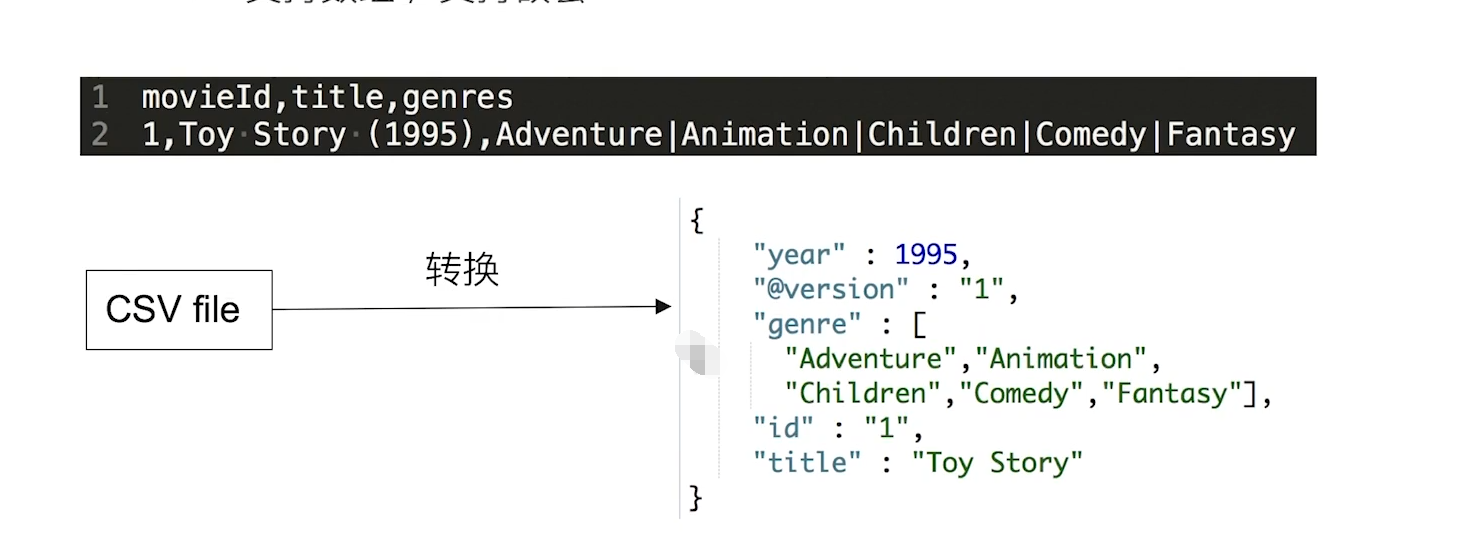
1.3 文档的元数据
{
"_index": "my_test_index",
"_type": "test_idnex",
"_id": "AXcpGrIeEQcMCfQJ7Gc5",
"_score": 1,
"_source": {
"testId": "4",
"testName": "zhaoliu"
}
}
元数据,用于标准文档的相关信息
- _index 文档所属的索引名
- _type 文档所属的类型名
- _id 文档的唯一id
- _source 文档原始的JSON数据
- _all 整合所有字段的内容到该字段,已被作废
- _version 文档的版本信息
- _score 相关性打分
1.4 索引
{
"my_test_index": {
"settings": {
"index": {
"search": {
"slowlog": {
"level": "info",
"threshold": {
"fetch": {
"warn": "200ms",
"trace": "50ms",
"debug": "80ms",
"info": "100ms"
},
"query": {
"warn": "200ms",
"trace": "50ms",
"debug": "80ms",
"info": "100ms"
}
}
}
},
"indexing": {
"slowlog": {
"level": "info",
"threshold": {
"index": {
"warn": "200ms",
"trace": "20ms",
"debug": "50ms",
"info": "100ms"
}
},
"source": "1000"
}
},
"number_of_shards": "5",
"provided_name": "my_test_index",
"creation_date": "1611301841428",
"unassigned": {
"node_left": {
"delayed_timeout": "5m"
}
},
"number_of_replicas": "1",
"uuid": "e5B65ySmQ-GE8Tj9gUHIPw",
"version": {
"created": "5050399"
}
}
}
}
}
- INDEX 索引是文档的容器是一类文档的结合
- INDEX 体现了逻辑空间的概念:每个索引都有自己的mapping定义用于定义包含文档的字段名和字段类型
- Shard 体现了物理空间的概念 索引中的数据分散在Shard上
- 索引的Mapping与Settings
- Mapping 定义文档字段的类型
- setting 定义不同的数据分布
1.5 Type

- 在7.0之前,一个Index可以设置多个Types
- 6.0开始,Type已经被Deprecated(不推荐使用)。从7.0开始一个索引只能创建一个Type - > “_doc”
1.6 抽象与类比
| RDBMS | ElasticSearch |
|---|---|
| Table | Index(Type) |
| Row | Document |
| Column | Filed |
| Schema | Mapping |
| SQL | DSL |
- 在7.0之前 一个Index 可以设置多个Types
- 目前Type 已经被 Deprecated(不推荐使用) ,7.0开始一个索引只能创建一个Type - > “_doc”
- 传统关系型数据库和ElasticSearch 的区别
– ElasticSearch - Schemaless /相关性/高性能全文检索
– RDMS - 事务性/Join
2.节点、集群、分片及副本
2.1 分布式特性
- ElasticSearch 的分布式架构的好处
- 存储的水平扩容
- 提高系统的可用性,部分节点停止服务整个集群的服务不受影响 - ElasticSearch的分布式架构
- 不同集群通过不同的名字来区分 默认为 “elasticsearch”
- 通过配置文件修改,或者在命令行中 -E cluster.name=geektime 进行设定
- 一个集群可以有一个或者多个节点
2.2 节点
- 节点是一个ElasticSearch 的实例
– 本质上就一个Java进程
– 一台机器上可以运行多个ElasticSearch进程,但是生产环境一般建议一台机器只运行一个ElasticSearch 实例 - 每一个节点都有名字 通过配置文件配置或者启动的时候 -E node.name=node1来指定
- 每一个接在在启动之后会分配一个UID,保存在data目录下
2.2.1 Master-eligible nodes(合格节点) 和Master Node(主)
- 每个节点启动后 默认就是一个 Master eligible节点
- 可以设置node.master:false 禁止
- Master-eligible可以参加选主流程,成为Master节点
- 当第一个节点启动的时候,它会将自己选举成Master节点
- 每个节点都保存了集群的状态,只有Master节点才能修改集群的状态信息
- 集群状态(Cluster State)维护了一个集群中的必要信息
- 所有节点的信息
- 所有的索引和其相关的Mapping与Setting信息
- 分片的路由信息
- 任意节点都能修改信息会导致数据的不一致性
- 集群状态(Cluster State)维护了一个集群中的必要信息
2.2.2 Data Node & Coordinating Node
- Data Node(数据节点)
- 可以保存数据的节点叫做Data Node 负责保存分片数据。在数据扩展上起到了至关重要的作用
- Coordinating Node(协调节点)
- 负责接收Client请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了 Coordinating Node职责
2.2.3 其他节点
- Hot & Warm Node (参考链接Hot & Warm Node)
– 不同硬件配置的Data Node,用来实现 Hot & Warm架构,降低集群部署的成本 - Machine Learning Node(机器学习节点)
– 负责跑 机器学的Job 用来做异常检测 - Tribe Node (协调节点 充当跨多集群联合客户端)
– (5.3 开始使用Cross Cluster Search) Tribe Node 连接到不同的ElasticSearch集群,并且支持将这些集群当成一个单独的集群
2.2.4 配置节点类型
- 开发环境中一个节点可以承担多种角色
- 生产环境中,应该设置单一的角色的节点(dedicate node 专用节点)
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| maste eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | 无 | 每个节点默认都是coordinating 节点设置其他类型全部为false |
| machine learning | node.ml | true(需enable x-pack) |
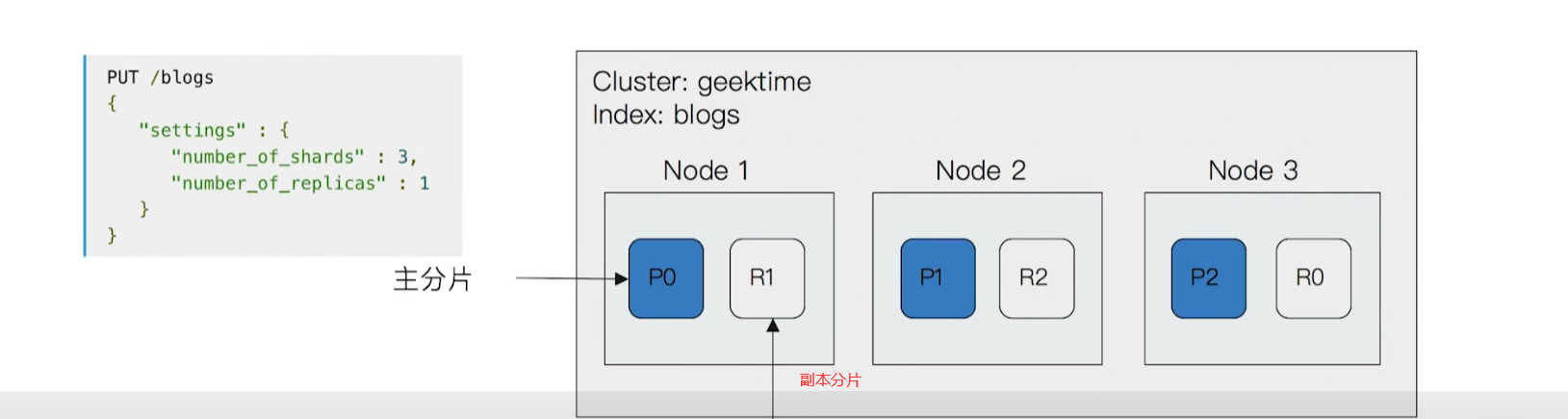
2.3 分片(Primary Shard & Replica Shard)
- 主分片,用以解决数据水平扩展的问题。通过主分片,可以将数据分不到集群内的所有节点之上
- 一个分片是一个运行的Lucene的实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
- 副本,用以解决数据高可用的问题。分片是主分片的拷贝
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
- 一个三节点的集群中,blogs索引的分配分布情况
2.3.1 分片的设定
- 对于生产环境中分配的设定,需要提前做好容量规划
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量大,导致数据重新分配耗时
- 分片数设置过大,7.0卡死,默认主分片设置成1,解决了over-sharding(
shard也是一种资源,shard过多会影响集群的稳定性。因为shard过多,元信息会变多,这些元信息会占用堆内存。shard过多也会影响读写性能,因为每个读写请求都需要一个线程。所以如果index没有很大的数据量,不需要设置很多shard。)的问题- 影响搜索结果的相关性打分,影响统计结果的准确性
- 当个节点上过多的分片,会导致资源的浪费同时也会影响性能
- 分片数设置过小
2.4 查看集群的健康状态
GET _cluster/health
{
"cluster_name": "es-cn-zz11rb9fv000fj1pe",
"status": "green",
"timed_out": false,
"number_of_nodes": 6,
"number_of_data_nodes": 3,
"active_primary_shards": 766,
"active_shards": 1507,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
GET _cat/nodes
172.17.25.39 45 91 3 0.23 0.08 0.06 di - 3Ja7gZv
172.17.25.53 55 79 1 0.00 0.01 0.05 mi * H1guebi
172.17.25.52 22 78 0 0.01 0.02 0.05 mi - rdjzfmG
172.17.25.51 24 78 0 0.00 0.01 0.05 mi - uaU255o
172.17.25.38 54 91 2 0.23 0.26 0.16 di - wQwmOos
172.17.25.40 65 89 1 0.01 0.17 0.26 di - 4mZ8XK7
GET _cat/shard
companyinfo 4 r STARTED 31408061 38.5gb 172.17.25.38 wQwmOos
companyinfo 4 p STARTED 31408061 40.2gb 172.17.25.39 3Ja7gZv
companyinfo 1 p STARTED 31412834 43.2gb 172.17.25.38 wQwmOos
companyinfo 1 r STARTED 31412834 41.7gb 172.17.25.39 3Ja7gZv
companyinfo 3 r STARTED 31407535 37.6gb 172.17.25.40 4mZ8XK7
companyinfo 3 p STARTED 31407535 36.8gb 172.17.25.39 3Ja7gZv
companyinfo 2 r STARTED 31412927 41.8gb 172.17.25.40 4mZ8XK7
companyinfo 2 p STARTED 31412927 41.2gb 172.17.25.39 3Ja7gZv
companyinfo 0 p STARTED 31400572 40.4gb 172.17.25.40 4mZ8XK7
companyinfo 0 r STARTED 31400572 43.1gb 172.17.25.38 wQwmOos
- Green 主分片和副本都很正常
- Yellow 主分片全部正常分配,有副本分片未能正常分配
- Red 有主分片未能分配
- 例如当服务器的磁盘容量超过85%时 去创建了一个新的索引
3.文档的CRUD & 批量操作
3.1 文档的CRUD
- Type名 约定都用_doc
- Create 如果ID已经存在会失败
- Index 如果ID不存在创建新的文档否则先删除现有的文档再创建新的文档 版本会增加
- Update 文档必须已经存在更新只会对响应字段做增量修改
3.1.1 Index
PUT my_test_index/_doc/1
{
"user":"mike",
"comment":"You know,for search"
}
- Index和Create 不一样的地方:如果文档不存在,就索引新的文档。否则现有文档会被删除,新的文档被索引。版本信息+1
3.1.2 Create
PUT my_test_index/_create/1
{
"user":"mike",
"comment":"You know,for search"
}
POST my_test_index/_doc (不指定ID 自动生成)
{
"user":"mike",
"comment":"You know,for search"
}
- 支持自动生成文档ID 和指定文档ID的两种类型
- 通过调用"post /my_test_index/_doc"
- 系统会自动生成document id
3.1.3 Read
GET my_test_indx/_doc/_1
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "my_store",
"_type": "products",
"_id": "5",
"_score": 1,
"_source": {
"price": 10,
"productName": "ZHANGSAN",
"productID": "XHDK-A-1293-#fJ3"
}
}
]
}
- 找到文档,返回HTTP 200
- 文档元信息
- _index/_type/
- 版本信息,同一个ID的文档即使被删除,version号也会不断的增加
- _source 中默认包含了文档的所有原始数据
- 文档元信息
- 找不到文档 返回HTTP 404
3.1.4 Update
POST my_test_index/_update/1
{
"doc":{
"user":"mike",
"comment":"You know,ElasticSearch"
}
}
- Update方法不会删除原来的文档,而是实现真正的数据更新
- Post 方法/Payload 需要包含在 “doc” 中
3.1.4 Delete
DELETE my_test_index/_doc/1
3.2 Bulk API

-
支持在一次API调用中,对不同的索引进行操作
-
支持四种类型操作
- Index
- Create
- Update
- Delete
-
可以再URI中指定Index 也可以在Payload 中进行
-
操作中单条操作失败不会影响其他操作
-
返回结果包括了每一条操作执行的结果
3.3 批量读取 -mget
批量操作可以减少网络连接所产生的开销 提高性能


GET /_mget
{
"docs": [{
"_index": "my_store",
"_id": 1
},
{
"_index": "companyinfo",
"_id": "cd5b8daadc31482e84715da912a604f4"
}
]
}
{
"docs": [
{
"_index": "my_store",
"_type": "products",
"_id": "1",
"_version": 4,
"found": true,
"_source": {
"price": 12,
"productID": "XHDK-A-1293-#fJ3"
}
},
{
"_index": "companyinfo",
"_type": "companyinfo",
"_id": "cd5b8daadc31482e84715da912a604f4",
"_version": 1,
"found": true,
"_source": {
"entName": "广西金朋豪友投资有限公司",
"orgLogo": "",
"regCapital": "500万元人民币",
"city": "广西壮族自治区",
"regDate": "2017-05-17",
"industry": "商务服务业",
"taxpayerIdNo": "91450800MA5L585X6F",
"creditCode": "91450800MA5L585X6F",
"registrationAuthority": "贵港市市场监督管理局",
"staffSize": "",
"orgCode": "MA5L585X-6",
"enterpriseStatus": "存续(在营、开业、在册)",
"id": "cd5b8daadc31482e84715da912a604f4",
"businessRegCode": "450800000151505",
"email": "",
"introduction": "",
"regCapitalNumber": 500,
"website": "",
"address": "贵港市解放北路龙圣新村小区(四小区213号)一楼",
"town": "",
"bossId": "4b12e1b8d1ef11-p-4b12e276d1ef1",
"corporation": "蒙雪",
"businessScope": "对文化产业、旅游业、旅游商品的投资;对建筑业的投资;企业形象策划,市场营销策划,赛事活动策划,舞台造型策划,婚礼庆典活动策划;展览展示服务,会务服务,礼仪服务,摄影服务;网络信息技术的开发、咨询、转让服务;影视策划咨询,企业管理咨询,投资信息咨询(以上项目除国家有专项规定外);电视节目制作服务(具体项目以审批部门批准为准);动漫设计;出版物的零售(具体项目以审批部门批准为准),室内外装饰装修工程,建筑工程设计,市政工程,景观工程设计(以上项目凭资质证经营);餐饮服务(具体项目以审批部门批准为准);设计、制作、代理、发布国内各类广告;演出经纪(具体项目以审批部门批准的为准);政府采购、招投标代理、工程咨询、土地评估、房地产评估、资产评估、房地产评估审计、工程预结算。",
"businessTerm": "长期",
"contributedcapital": "",
"checkDate": "2017-05-17",
"enterpriseType": "有限责任公司(自然人独资)",
"orgNameEn": "",
"taxpayerQualification": "",
"telphone": "",
"district": "",
"sameEnterprise": "<关联企业3>",
"oldOrgName": "",
"readAddress": "贵港市解放北路龙圣新村小区(四小区213号)一楼",
"contributors": ""
}
}
]
}
3.4 批量查询 -msearch

3.5常见错误返回
| 问题 | 原因 |
|---|---|
| 无法连接 | 网络故障或集群故障 |
| 连接无法关闭 | 网络故障或节点出错 |
| 429 | 集群过于繁忙 |
| 4XX | 请求体格式有误 |
| 500 | 集群内部错误 |
4.倒排索引
4.1 正排索引和倒排索引
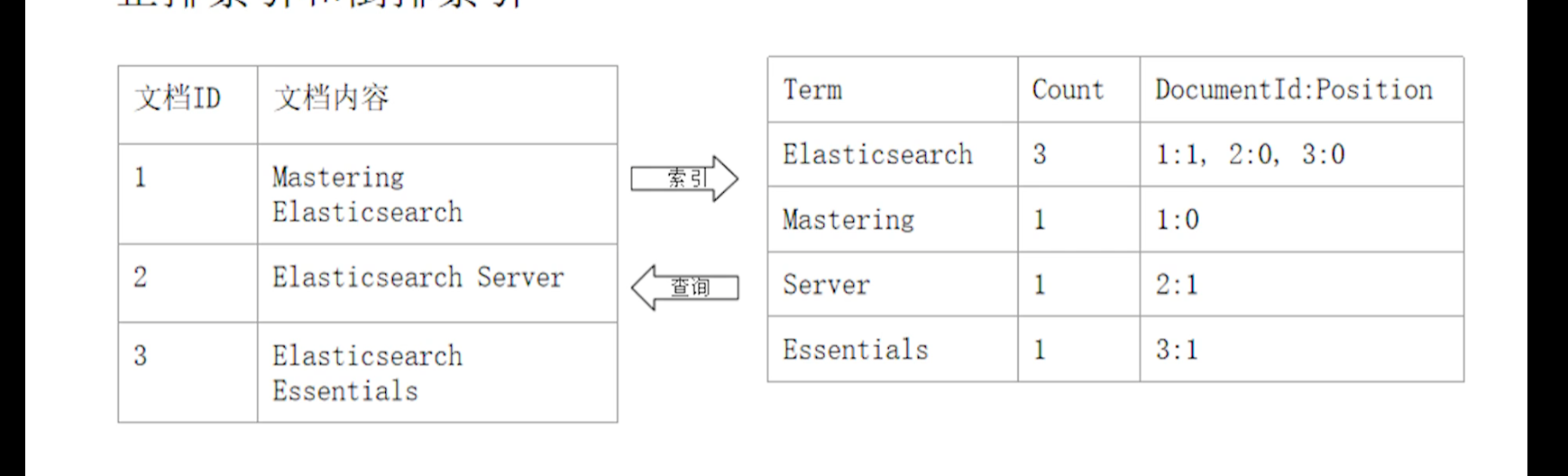
- 倒排索引包含两个部分
- 单词词典(Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系
- 单词词典一般比较大,可以通过B+树或哈希拉链法实现,以满足高性能的插入和查询
- 倒排列表(Posting List) 记录了单词对应的文档结合,由倒排索引组成
- 倒排索引项(Posting)
- 文档ID
- 词频 TF 该单词在文档中出现的次数用于相关性评分
- 位置(Position) 单词在文档中分词的位置,用于语句搜索(phrase query)
- 偏移(Offset) 记录单词的开始结束位置,实现高亮显示
- 倒排索引项(Posting)
- 单词词典(Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系
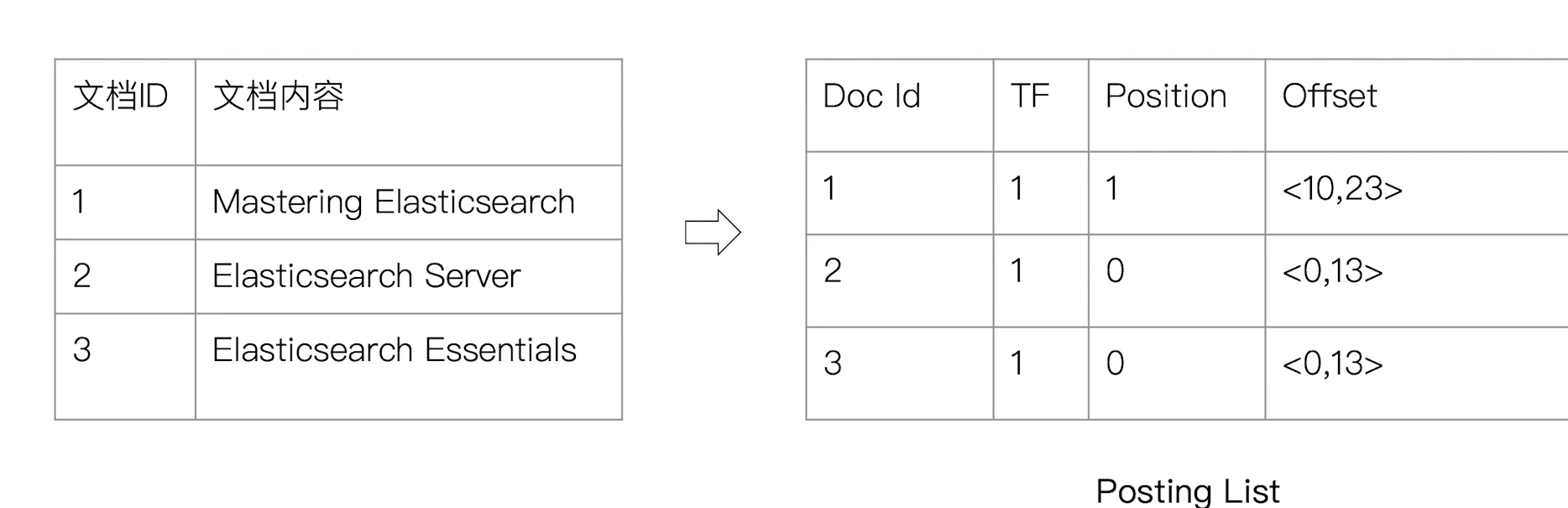
4.2 ElasticSearch的倒排索引
- ElasticSearch的JSON文档中的每个字段都有自己的倒排索引
- 可以指定对某些字段不做索引
- 优点:节省存储空间
- 缺点:字段无法被搜索
5.分词器
5.1 Alalysis 与 Analyzer
- Alalysis 文本分析是把全文本转换一系列单词(term/token)的过程,也叫做分词
- Alalysis 是通过Analyzer来实现的
- 可使用ElasticSearch内置的分析器,或者采用定制化分析器
- 除了在数据写入时转换词条,匹配Query语句的时候也需要用相同的分析器对语句进行分析

5.2 Analyzer的组成
- 分词器是专门处理分词的组件,Analyzer由三部分组成
-Character Filters(针对原始文本处理,例如出去html)/Tokenizer(按照规则切分单词)/Token Filter(将切分的单词进行加工,小写,删除stopwords,增加同义词)
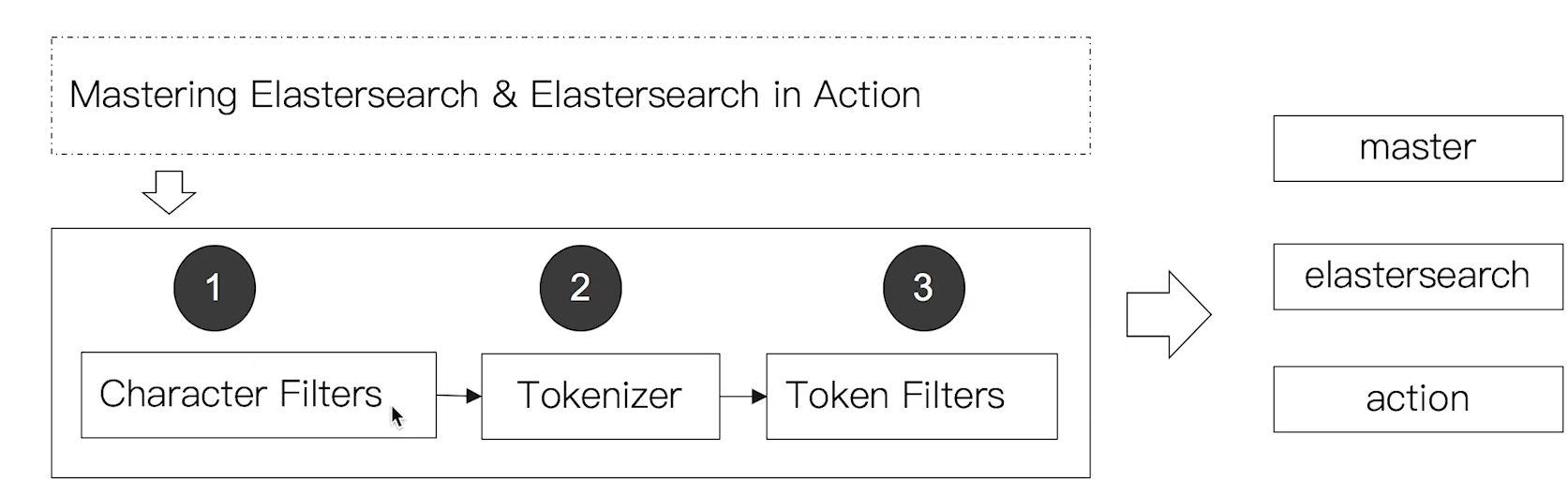
5.3 Elasticsearch的内置分词器
- Standard Analyzer 一默认分词器,按词切分,小写处理
- Simple Analyzer 一按照非字母切分(符号被过滤),小写处理
- Stop Analyzer 一小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer一按照空格切分,不转小写
- Keyword Analyzer 一不分词,直接将输入当作输出
- Patter Analyzer 一正则表达式,黑默认W+(非字符分隔)
- Language 一提供了30多种常见语言的分词器
- Customer Analyzer自定义分词器
5.3.1 Standard Analyzer
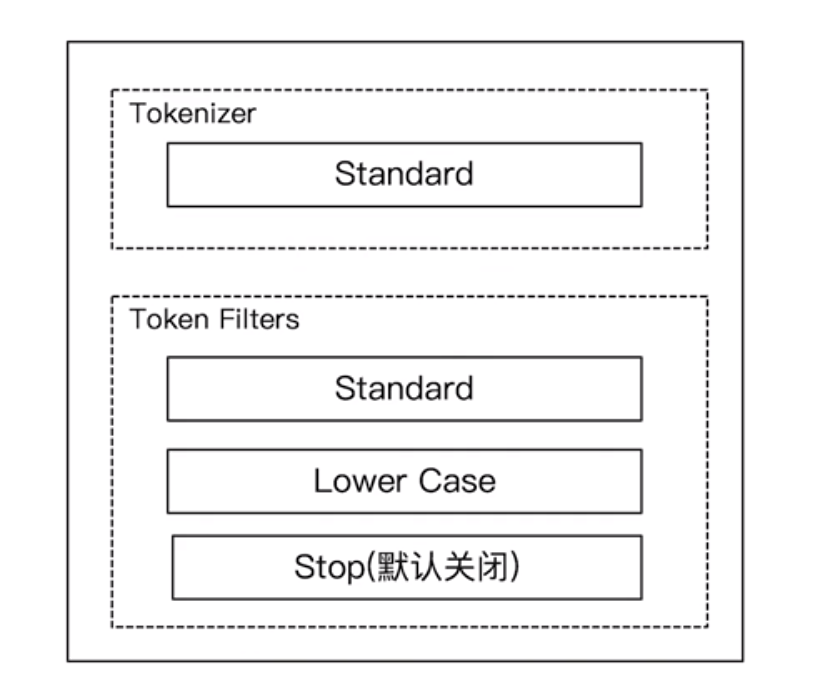
- 默认分词器
- 按词切分
- 小写处理
5.3.2 Simple Analyzer
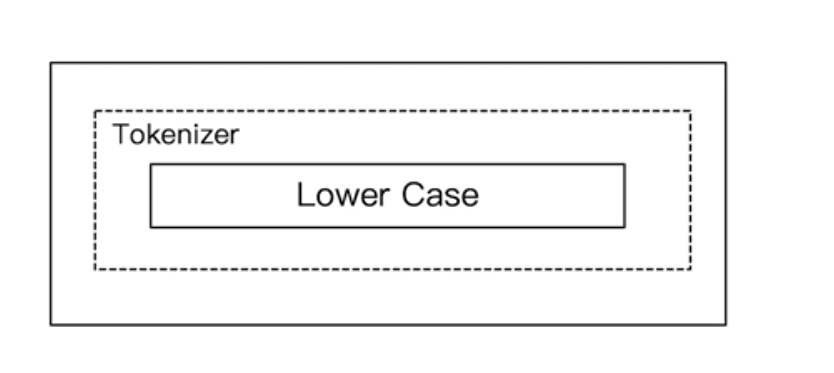
- 按照非字母切分,非字母的都被去除
- 小写处理
5.3.3 Whitespace Analyzer
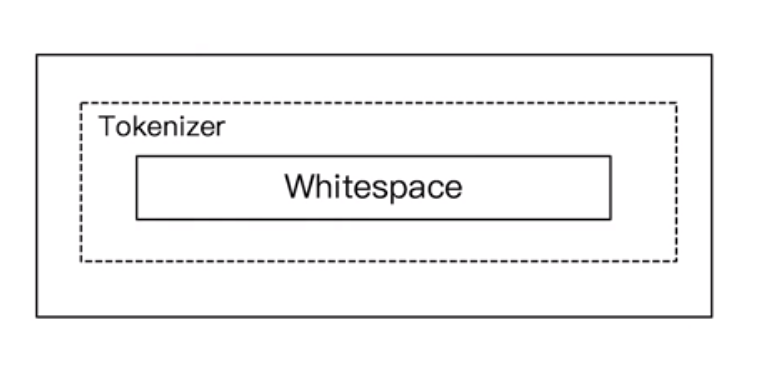
- 按照空格进行数据切分
5.3.4 Stop Analyzer
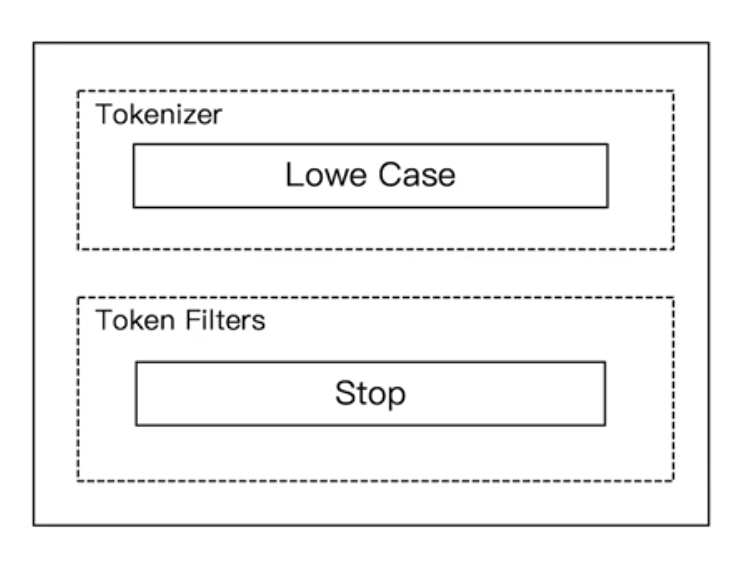
- 相比Simple Analyzer
- 多了stop filter
- 会把the,a,is 等修饰词语去掉
5.3.5 Keyword Analyzer
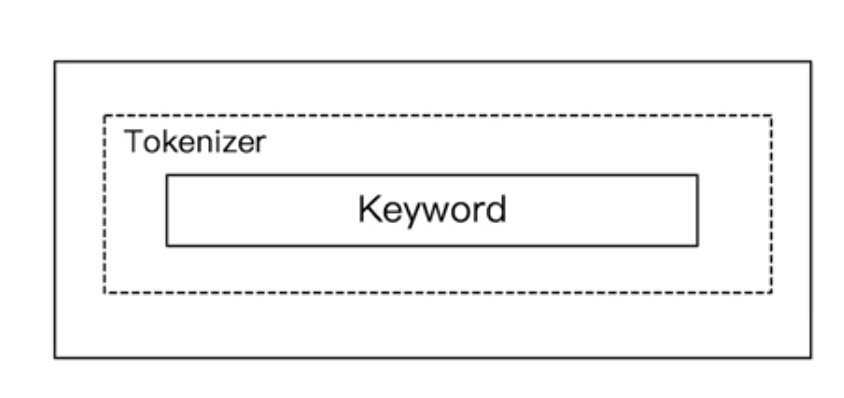
- 不做分词处理 将一个输入当做term输出
5.3.6 Pattern Analyzer
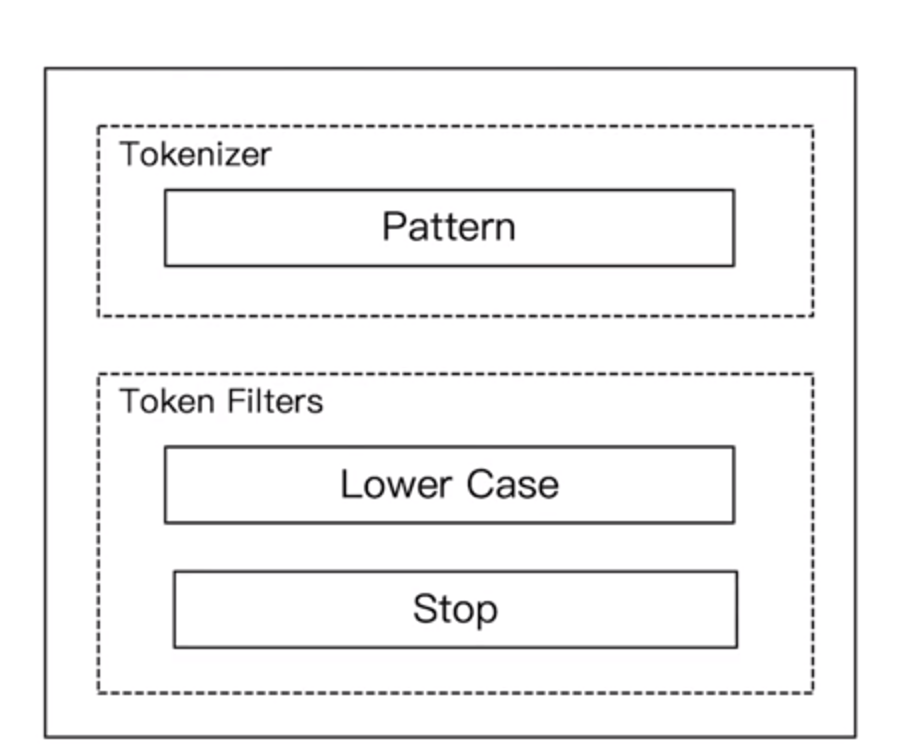
- 通过正则表达式进行分词
- 默认是W+,非字符的符号进行分隔
5.3.7 Language Analyzers

5.4 使用_analyzer Api
- 直接指定Analyzer进行测试
GET /_analyze
{
"analyzer": "standard",
"text": "Mastering ElasticSearch,elasticsearch in Action"
}
results
{
"tokens": [
{
"token": "mastering",
"start_offset": 0,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "elasticsearch",
"start_offset": 10,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "elasticsearch",
"start_offset": 24,
"end_offset": 37,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "in",
"start_offset": 38,
"end_offset": 40,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "action",
"start_offset": 41,
"end_offset": 47,
"type": "<ALPHANUM>",
"position": 4
}
]
}
- 使用 Simple Analyzer 进行测试
GET /_analyze
{
"analyzer": "simple",
"text": "2 run 。Maste-ring ElasticSearch,elasticsearch in Action"
}
result
{
"tokens": [
{
"token": "run",
"start_offset": 2,
"end_offset": 5,
"type": "word",
"position": 0
},
{
"token": "maste",
"start_offset": 7,
"end_offset": 12,
"type": "word",
"position": 1
},
{
"token": "ring",
"start_offset": 13,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "elasticsearch",
"start_offset": 18,
"end_offset": 31,
"type": "word",
"position": 3
},
{
"token": "elasticsearch",
"start_offset": 32,
"end_offset": 45,
"type": "word",
"position": 4
},
{
"token": "in",
"start_offset": 46,
"end_offset": 48,
"type": "word",
"position": 5
},
{
"token": "action",
"start_offset": 49,
"end_offset": 55,
"type": "word",
"position": 6
}
]
}
- 使用Whitespace Analyzer 进行测试
GET /_analyze
{
"analyzer": "whitespace",
"text": "Maste-ring ElasticSearch,elasticsearch in Action"
}
result
{
"tokens": [
{
"token": "Maste-ring",
"start_offset": 0,
"end_offset": 10,
"type": "word",
"position": 0
},
{
"token": "ElasticSearch,elasticsearch",
"start_offset": 11,
"end_offset": 38,
"type": "word",
"position": 1
},
{
"token": "in",
"start_offset": 39,
"end_offset": 41,
"type": "word",
"position": 2
},
{
"token": "Action",
"start_offset": 42,
"end_offset": 48,
"type": "word",
"position": 3
}
]
}
- 使用Stop Analyzer 进行测试
GET /_analyze
{
"analyzer": "stop",
"text": "this is a ElasticSearch,elasticsearch in Action"
}
result
{
"tokens": [
{
"token": "elasticsearch",
"start_offset": 10,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "elasticsearch",
"start_offset": 24,
"end_offset": 37,
"type": "word",
"position": 4
},
{
"token": "action",
"start_offset": 41,
"end_offset": 47,
"type": "word",
"position": 6
}
]
}
- 使用 Keyword Analyzer进行测试
GET /_analyze
{
"analyzer": "keyword",
"text": "this is a ElasticSearch,elasticsearch in Action"
}
result
{
"tokens": [
{
"token": "this is a ElasticSearch,elasticsearch in Action",
"start_offset": 0,
"end_offset": 47,
"type": "word",
"position": 0
}
]
}
- 使用 Pattern Analyzer 进行测试
GET /_analyze
{
"analyzer": "pattern",
"text": "this is a Elastic-Search,elasticsearch in Action"
}
result
{
"tokens": [
{
"token": "this",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": "is",
"start_offset": 5,
"end_offset": 7,
"type": "word",
"position": 1
},
{
"token": "a",
"start_offset": 8,
"end_offset": 9,
"type": "word",
"position": 2
},
{
"token": "elastic",
"start_offset": 10,
"end_offset": 17,
"type": "word",
"position": 3
},
{
"token": "search",
"start_offset": 18,
"end_offset": 24,
"type": "word",
"position": 4
},
{
"token": "elasticsearch",
"start_offset": 25,
"end_offset": 38,
"type": "word",
"position": 5
},
{
"token": "in",
"start_offset": 39,
"end_offset": 41,
"type": "word",
"position": 6
},
{
"token": "action",
"start_offset": 42,
"end_offset": 48,
"type": "word",
"position": 7
}
]
}
- 用Language Analyzers 来进行测试
GET /_analyze
{
"analyzer": "english",
"text": "this is a Elastic-Search,elasticsearch in Action"
}
result
{
"tokens": [
{
"token": "elast",
"start_offset": 10,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "search",
"start_offset": 18,
"end_offset": 24,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "elasticsearch",
"start_offset": 25,
"end_offset": 38,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "action",
"start_offset": 42,
"end_offset": 48,
"type": "<ALPHANUM>",
"position": 7
}
]
}
- 指定索引的字段进行测试
POST my_store/_analyze
{
"field": "productName",
"text": "XHDK-A-1293-#fJ3"
}
result
{
"tokens": [
{
"token": "xhdk",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "a",
"start_offset": 5,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "1293",
"start_offset": 7,
"end_offset": 11,
"type": "<NUM>",
"position": 2
},
{
"token": "fj3",
"start_offset": 13,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 3
}
]
}
- 自定义分词器进行测试
POST /_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text":"Hello ElasticSearch"
}
result
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "elasticsearch",
"start_offset": 6,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 1
}
]
}
5.5 中文分词的难点
-
中文句子,切分成一个一个词 而不是一个一个字
-
英文中,单词有自然的空格作为分隔
-
一句中文,在不同的上下文有不同的理解
- 这个苹果,不大好吃/这个苹果,不大,好吃!
-
一些例子
- 他说的确实在理/这事确定不下来
-
使用默认的ElasticSearch 分词器来对中文进行分词
GET /_analyze
{
"analyzer": "standard",
"text": "这事确定不下来 "
}
result
{
"tokens": [
{
"token": "这",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "事",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "确",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "定",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "不",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "下",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "来",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
}
]
}
5.6 中文分词器ik
5.6.1 ik分词器的基本使用
附官方文档地址:IK分词器GitHub官方文档地址
5.6.2 ik_max_word 分词器解析
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "这事确定不下来 "
}
result
{
"tokens": [
{
"token": "这事",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "确定",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "不下来",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 2
},
{
"token": "不下",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
},
{
"token": "下来",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
}
]
}
5.6.3 使用ik_smart 进行分词
GET /_analyze
{
"analyzer": "ik_smart",
"text": "这事确定不下来 "
}
result
{
"tokens": [
{
"token": "这事",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "确定",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "不下来",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 2
}
]
}
5.6.4 使用分词器进行高亮查询
GET companyinfo/_search
{
"query" : { "match" : { "entName" : "北京信查查" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"entName" : {}
}
},
"from": 0
, "size": 1
}
result
{
"took": 2357,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4665655,
"max_score": 21.237017,
"hits": [
{
"_index": "companyinfo",
"_type": "companyinfo",
"_id": "5083796b34f940698d9cb0ce2984f314",
"_score": 21.237017,
"_source": {
"id": "5083796b34f940698d9cb0ce2984f314",
"bossId": "05232caa241311-p-05232d3624131",
"orgLogo": "https://static.xinchacha.com/companyLogo/5083796b34f940698d9cb0ce2984f314.png?Expires=1609503319&OSSAccessKeyId=LTAI4GFjBCimq7VBgRQ5LKfq&Signature=2DppCS5yzYTZvtMT45GYqdHtjkM%3D",
"entName": "北京信查查信用管理有限公司",
"telphone": "400-900-6808",
"website": "http://www.xcc.com",
"email": "xcc@xinchacha.com",
"introduction": "北京信查查信用管理有限公司的主营产品是信用通跟加密保",
"readAddress": "北京市昌平区龙域北街5号院1号楼5层516",
"corporation": "刘洋",
"sameEnterprise": "<关联企业1>",
"enterpriseStatus": "开业",
"regCapitalNumber": 1000,
"regCapital": "1000万元人民币",
"contributedcapital": "",
"regDate": "2019-08-02",
"checkDate": "2019-08-02",
"creditCode": "91110114MA01LTMB1Y",
"orgCode": "MA01LTMB-1",
"taxpayerIdNo": "91110114MA01LTMB1Y",
"taxpayerQualification": "",
"businessRegCode": "",
"industry": "信息传输、软件和信息技术服务业",
"enterpriseType": "有限责任公司(自然人独资)",
"businessTerm": "2019-08-02 至 无固定期限",
"staffSize": "",
"contributors": "",
"registrationAuthority": "北京市工商行政管理局昌平分局",
"city": "北京市",
"town": "北京市",
"district": "",
"oldOrgName": "",
"orgNameEn": "",
"address": "北京市昌平区龙域北街5号院1号楼5层516",
"businessScope": "企业信用的征集、评定(不含金融征信);软件开发;计算机系统服务;企业管理;市场调查;经济信息咨询(不含中介);基础软件服务;应用软件服务(不含医疗软件);承办展览展示活动;会议服务;技术开发、技术咨询、技术交流、技术转让、技术推广;技术服务;设计、制作、代理、发布广告;教育咨询。((企业依法自主选择经营项目,开展经营活动;依法须经批准的项目,经相关部门批准后依批准的内容开展经营活动;不得从事本市产业政策禁止和限制类项目的经营活动。))"
},
"highlight": {
"entName": [
"<tag1>北京</tag1><tag1>信</tag1><tag1>查查</tag1>信用管理有限公司"
]
}
}
]
}
}
5.6.5 分词器返回结果详解
{
"tokens": [
{
"token": "这事",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
}
]
}
token:具体内容
start_offset:起始位置
end_offset:结束位置
type:类型
position:位置(下标)
6 Search API
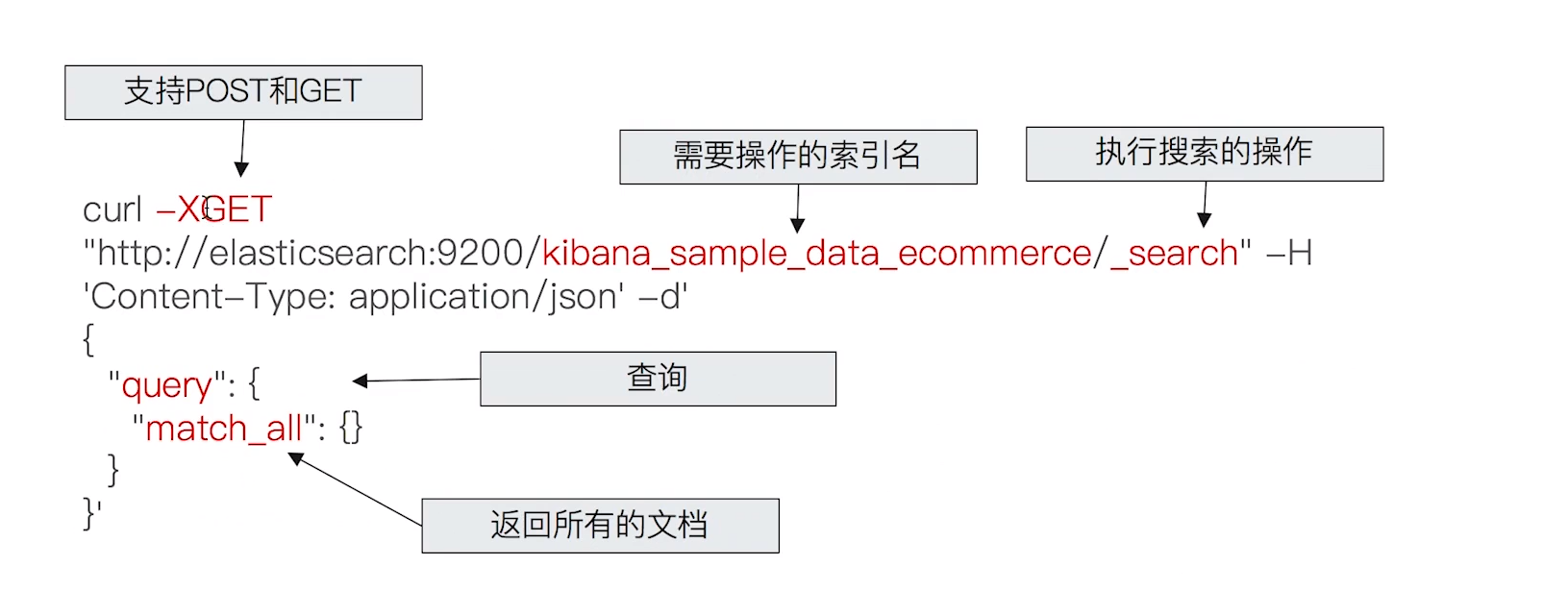
- URI Search
- 在URL中使用查询参数
- Request Body Search
- 使用ElasticSearch提供的,基于JSON格式的更加完备的Query Domain Specific Language(DSL)
6.1 URI 查询
- 使用 “q”,指定查询字符串
- “query string syntax”,KV键值对

6.2 Request Body 查询
6.3 Response 解析
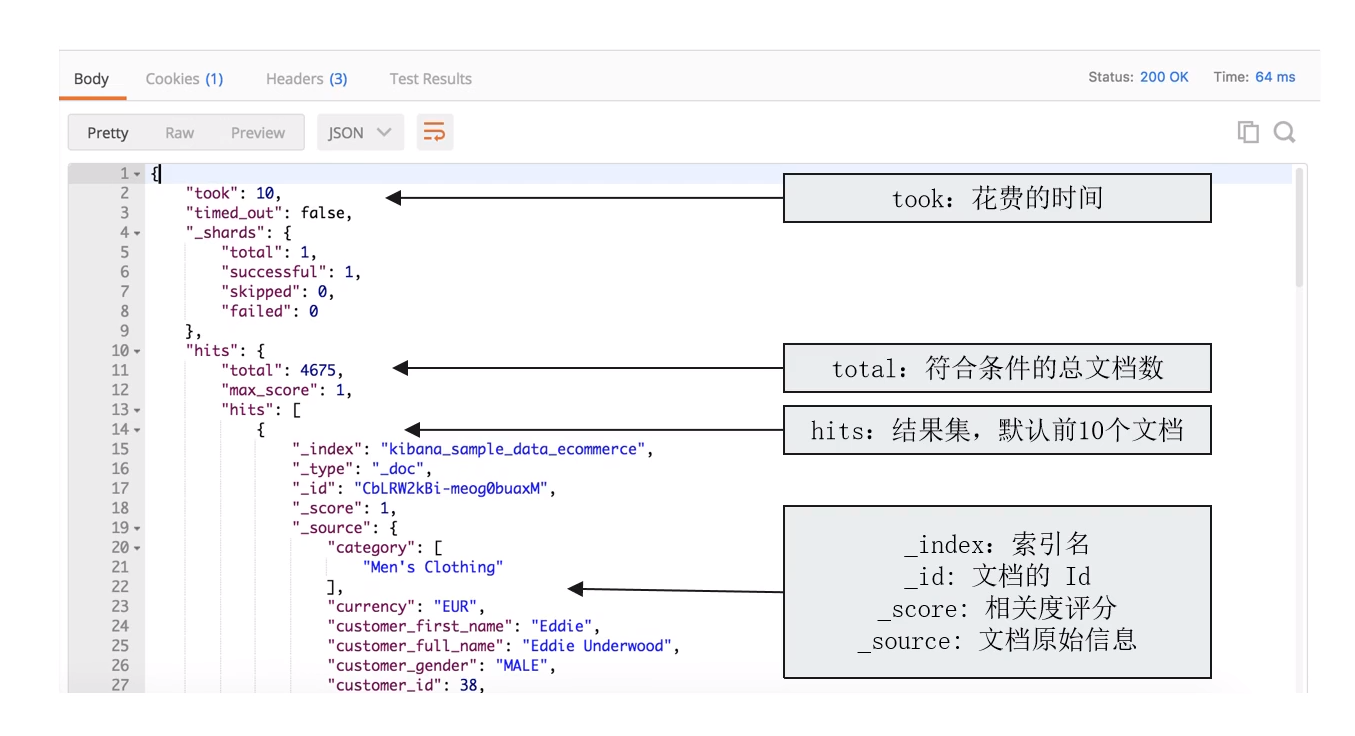
6.3.1 搜索相关度(Relevance) 相关度解析
- 搜索是用户和搜索引擎之间的对话
- 用户关心的是搜索结果的相关性
- 是否可以找到所有相关的内容
- 有多少不相关的内容被返回了
- 文档的打分是否合理
- 结合业务需求平衡排名结果
6.3.2 衡量相关性
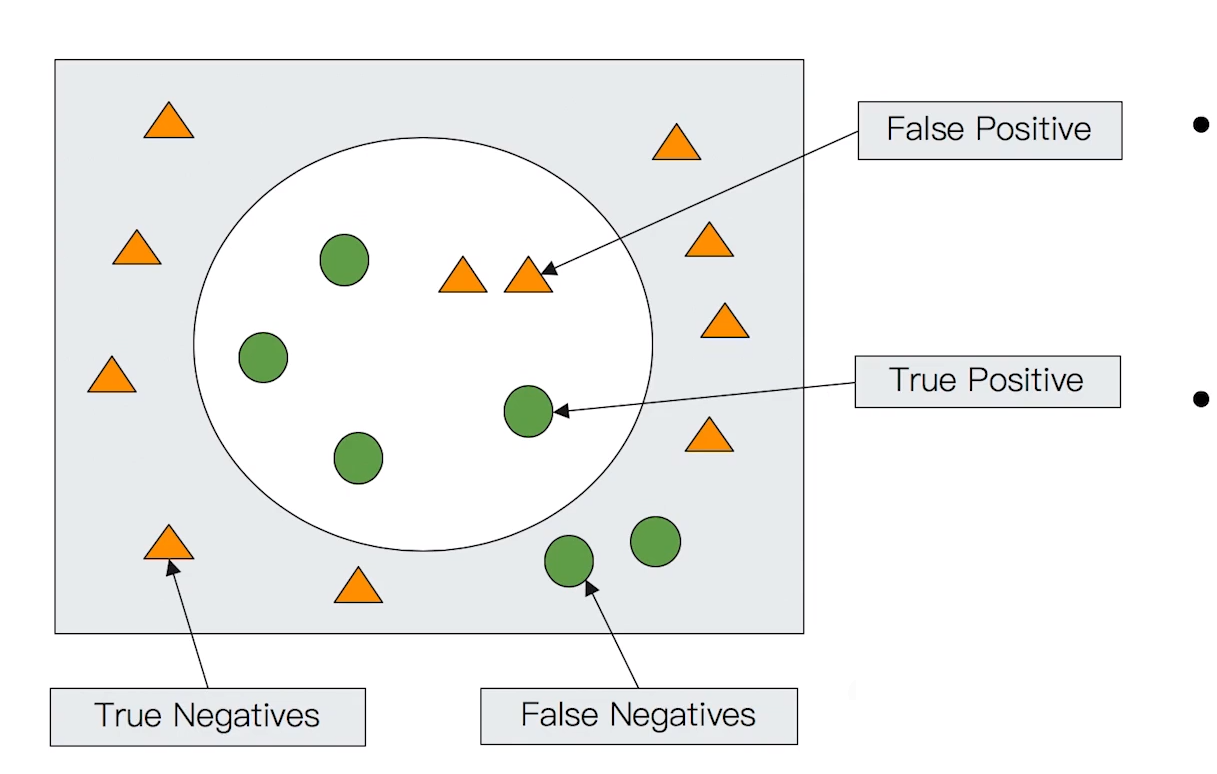
- Information Retrieval
- Precision(查准率) 尽可能返回较少的无关文档
- Precision -True Positive/全部返回的结果(True and False Positive)
- Recall (查全率) 尽量 返回较多的相关文档
- Recall -True Positive/所有应该返回的结果(True positives + False Negtives)
- RanKing - 是否能够按照相关度进行排序
- Precision(查准率) 尽可能返回较少的无关文档
注:具体可参照ElasticSearch搜索相关性算分
最后
以上就是灵巧网络最近收集整理的关于(二)ElasticSearch实战基础教程(ElasticSearch入门)1.ElasticSearch基础概念2.节点、集群、分片及副本3.文档的CRUD & 批量操作4.倒排索引5.分词器6 Search API的全部内容,更多相关(二)ElasticSearch实战基础教程(ElasticSearch入门)1.ElasticSearch基础概念2.节点、集群、分片及副本3.文档的CRUD内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复