我是靠谱客的博主 孤独荷花,这篇文章主要介绍(三)ElasticSearch实战基础教程(ElasticSearch入门)7. URI 详解8 Request Body & Query DSL 简介9 Query String 和Simple Query String10 Dynamic Mapping和常见字段类型11 显示Mapping设置和常见参数介绍12 多字段特性及Mapping中配置自定义Analyzer13 Index Template 和Dynamic Template14 ElasticSearch聚合分析简介,现在分享给大家,希望可以做个参考。
7. URI 详解
7.1 通过URI query 实现搜索
GET /companyinfo/_search?q=公司&df=entName&from=0&size=1&timeout=1s
{
"profile":"true"
}
- q 指定查询语句,使用Query String Syntax
- df 默认字段,不指定时会对所有字段进行查询
- Sort 排序/ from 和 size 用于分页
- Profile 可以查看查询是如何被执行的
7.2 Query String Syntax (1)
- 指定字段 v.s 泛查询
- q=title:2012 /q=2012
########## 指定字段进行查询#####################
GET /companyinfo/_search?q=entName:公司&from=0&size=1&timeout=1s
{
"profile":"true"
}
result
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3807,
"max_score": 17.098007,
"hits": [
{
"_index": "companyinfo",
"_type": "companyinfo",
"_id": "6355d4063b5311eb925000163e350731",
"_score": 17.098007,
"_source": {
"entName": "MEDSENTIAL,L.L.C",
"orgLogo": "",
"regCapital": "",
"city": "",
"regDate": "",
"industry": "",
"taxpayerIdNo": "",
"creditCode": "",
"registrationAuthority": "",
"staffSize": "",
"orgCode": "",
"enterpriseStatus": "",
"id": "6355d4063b5311eb925000163e350731",
"businessRegCode": "",
"email": "",
"introduction": "",
"regCapitalNumber": 0,
"website": "",
"address": "",
"town": "",
"bossId": "",
"corporation": "暂无",
"businessScope": "",
"businessTerm": "- 至 无固定期限",
"contributedcapital": "",
"checkDate": "",
"enterpriseType": "",
"orgNameEn": "",
"taxpayerQualification": "",
"telphone": "",
"district": "",
"sameEnterprise": "<关联企业>",
"oldOrgName": "",
"readAddress": "",
"contributors": "0"
}
}
]
},
"profile": {
"shards": [
{
"id": "[3Ja7gZvNRfSLKQ4iGlsUgg][companyinfo][2]",
"searches": [
{
"query": [
{
"type": "TermQuery",
"description": "entName:l",
"time": "0.5806670000ms",
"time_in_nanos": 580667,
"breakdown": {
"score": 192605,
"build_scorer_count": 63,
"match_count": 0,
"create_weight": 204501,
"next_doc": 100255,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 996,
"score_count": 792,
"build_scorer": 81454,
"advance": 0,
"advance_count": 0
}
}
],
"rewrite_time": 1644,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "0.5750680000ms",
"time_in_nanos": 575068,
"children": [
{
"name": "TimeLimitingCollector",
"reason": "search_timeout",
"time": "0.4419630000ms",
"time_in_nanos": 441963,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "0.3136840000ms",
"time_in_nanos": 313684
}
]
}
]
}
]
}
],
"aggregations": []
},
{
"id": "[3Ja7gZvNRfSLKQ4iGlsUgg][companyinfo][3]",
"searches": [
{
"query": [
{
"type": "TermQuery",
"description": "entName:l",
"time": "0.6785800000ms",
"time_in_nanos": 678580,
"breakdown": {
"score": 209943,
"build_scorer_count": 61,
"match_count": 0,
"create_weight": 266078,
"next_doc": 107535,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 908,
"score_count": 759,
"build_scorer": 93295,
"advance": 0,
"advance_count": 0
}
}
],
"rewrite_time": 1855,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "0.6240210000ms",
"time_in_nanos": 624021,
"children": [
{
"name": "TimeLimitingCollector",
"reason": "search_timeout",
"time": "0.4900560000ms",
"time_in_nanos": 490056,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "0.3464840000ms",
"time_in_nanos": 346484
}
]
}
]
}
]
}
],
"aggregations": []
},
{
"id": "[3Ja7gZvNRfSLKQ4iGlsUgg][companyinfo][4]",
"searches": [
{
"query": [
{
"type": "TermQuery",
"description": "entName:l",
"time": "0.5367190000ms",
"time_in_nanos": 536719,
"breakdown": {
"score": 198601,
"build_scorer_count": 40,
"match_count": 0,
"create_weight": 167458,
"next_doc": 110958,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 878,
"score_count": 742,
"build_scorer": 58041,
"advance": 0,
"advance_count": 0
}
}
],
"rewrite_time": 6874,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "0.5998340000ms",
"time_in_nanos": 599834,
"children": [
{
"name": "TimeLimitingCollector",
"reason": "search_timeout",
"time": "0.4730040000ms",
"time_in_nanos": 473004,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "0.3354350000ms",
"time_in_nanos": 335435
}
]
}
]
}
]
}
],
"aggregations": []
},
{
"id": "[wQwmOosAQjSSL7-qjOg7Pw][companyinfo][0]",
"searches": [
{
"query": [
{
"type": "TermQuery",
"description": "entName:l",
"time": "0.5707300000ms",
"time_in_nanos": 570730,
"breakdown": {
"score": 193154,
"build_scorer_count": 60,
"match_count": 0,
"create_weight": 206270,
"next_doc": 92610,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 993,
"score_count": 744,
"build_scorer": 76898,
"advance": 0,
"advance_count": 0
}
}
],
"rewrite_time": 1685,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "0.7637310000ms",
"time_in_nanos": 763731,
"children": [
{
"name": "TimeLimitingCollector",
"reason": "search_timeout",
"time": "0.6415250000ms",
"time_in_nanos": 641525,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "0.3118390000ms",
"time_in_nanos": 311839
}
]
}
]
}
]
}
],
"aggregations": []
},
{
"id": "[wQwmOosAQjSSL7-qjOg7Pw][companyinfo][1]",
"searches": [
{
"query": [
{
"type": "TermQuery",
"description": "entName:l",
"time": "0.6177530000ms",
"time_in_nanos": 617753,
"breakdown": {
"score": 215893,
"build_scorer_count": 55,
"match_count": 0,
"create_weight": 165227,
"next_doc": 107813,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 980,
"score_count": 770,
"build_scorer": 127014,
"advance": 0,
"advance_count": 0
}
}
],
"rewrite_time": 1355,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "0.9852530000ms",
"time_in_nanos": 985253,
"children": [
{
"name": "TimeLimitingCollector",
"reason": "search_timeout",
"time": "0.8321480000ms",
"time_in_nanos": 832148,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "0.3572100000ms",
"time_in_nanos": 357210
}
]
}
]
}
]
}
],
"aggregations": []
}
]
}
}
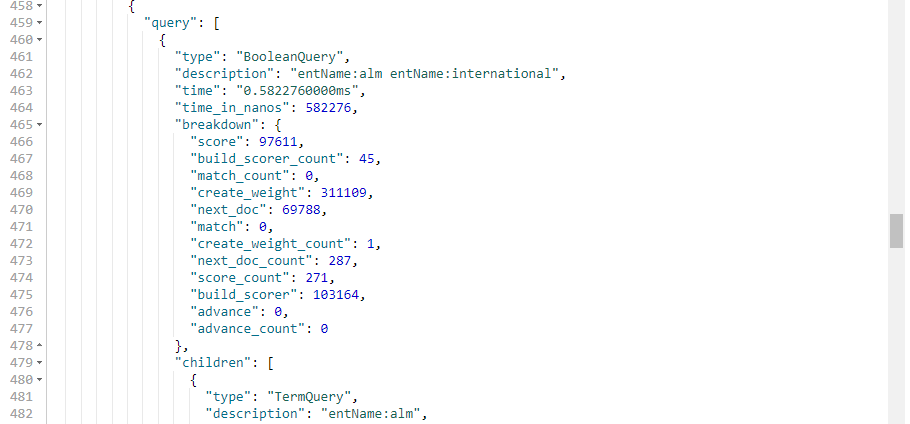
- Term v.s Phrase (PhraseQuery)
- Beautiful Mind 等效于 Beautiful OR Mind
- “Beautiful Mind”,等效于 Beautiful AND Mind。Phrase 查询,还要求前后顺序保持一致
GET /companyinfo/_search?q=entName:ALM INTERNATIONAL
{
"profile":"true"
}
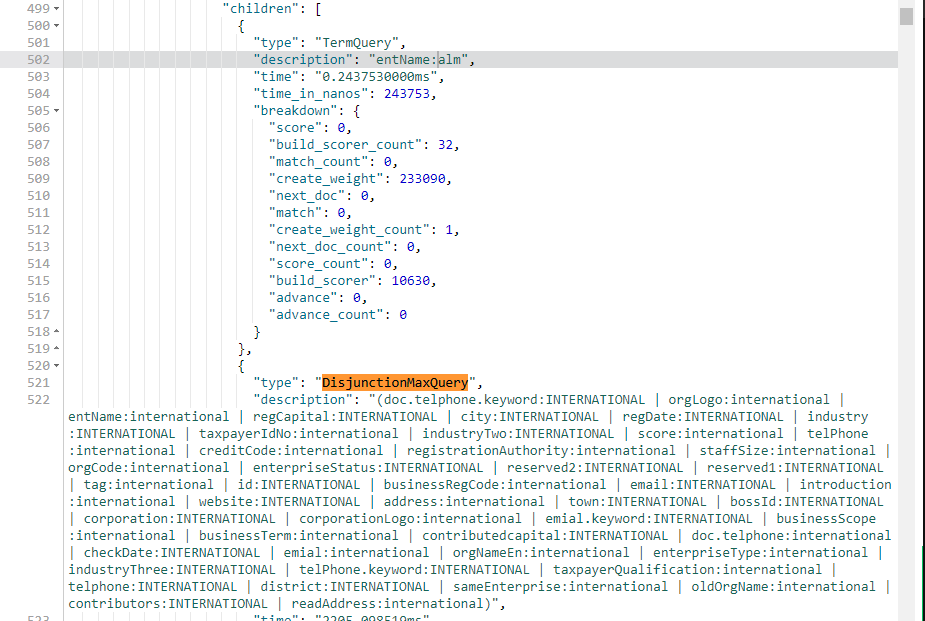
-
分组与引号
- title:(Beautiful AND Mind)
- title=“Beautiful Mind”
-
分组
GET /companyinfo/_search?q=entName:(ALM INTERNATIONAL)
{
"profile":"true"
}
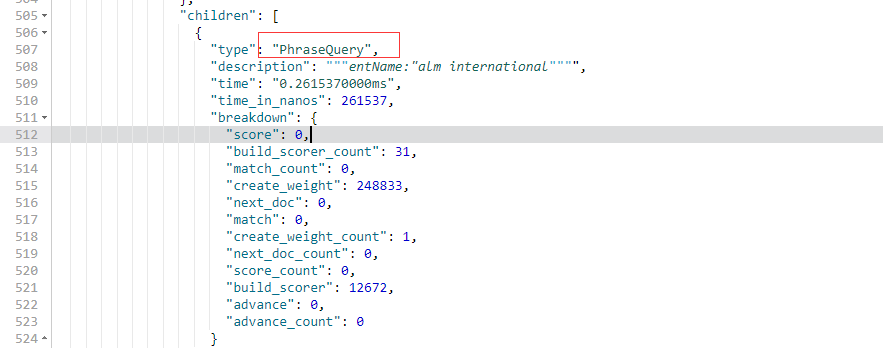
- 引号
GET /companyinfo/_search?q=entName:"ALM INTERNATIONAL"
{
"profile":"true"
}
7.3 Query String Syntax (2)
- 布尔操作
- AND/OR/NOT 或者&& / || /!
- title:(matrix NOT reloaded)
- 分组
- +表示must
- 表示must_not
- title:(+matrix -reloaded)
AND操作示例
GET /companyinfo/_search?q=entName:(ALM AND INTERNATIONAL)
{
"profile":"true"
}
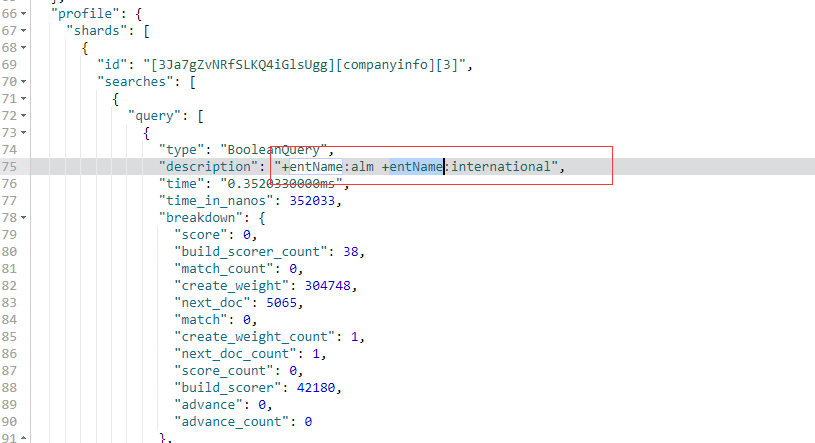
OR操作示例
GET /companyinfo/_search?q=entName:(ALM OR INTERNATIONAL)
{
"profile":"true"
}
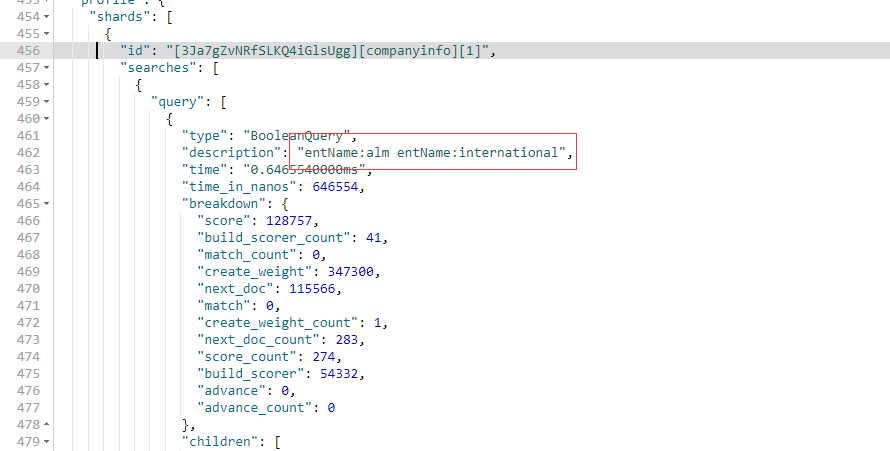
NOT 操作示例
GET /companyinfo/_search?q=entName:(ALM NOT INTERNATIONAL)
{
"profile":"true"
}
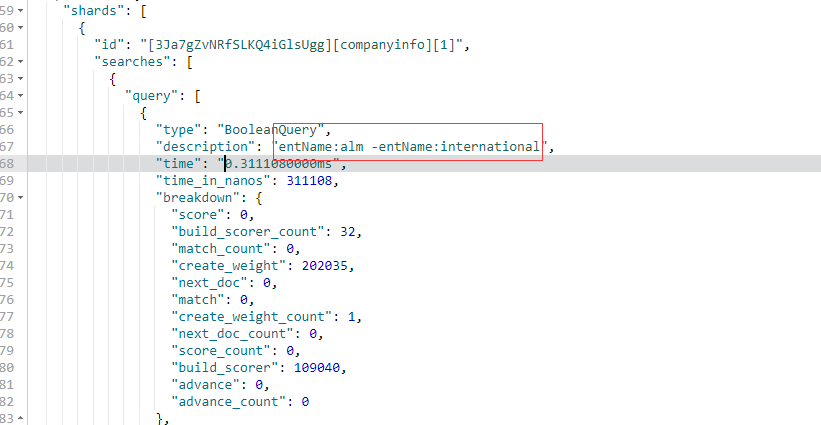
+操作示例
GET /companyinfo/_search?q=entName:(ALM %2BINTERNATIONAL)
{
"profile":"true"
}
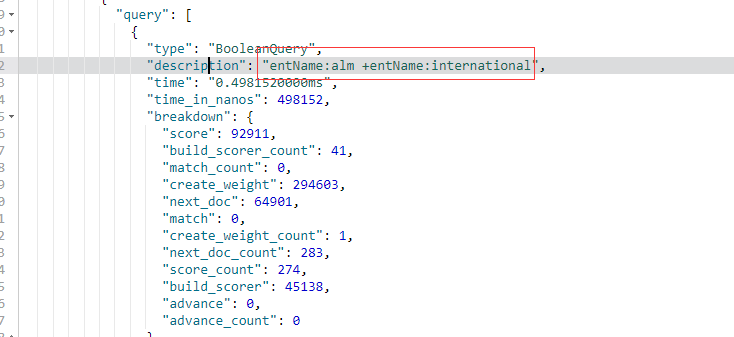
7.4 Query String Syntax (3)
- 范围查询
- 区间表示:[]闭区间,{}开区间
- year:{2019 TO 2018}
- year:[* TO 2018]
- 区间表示:[]闭区间,{}开区间
- 算数符号
- year:>2010
- year:(>2010&&<=2018)
- year:(+>2010+<=2018)
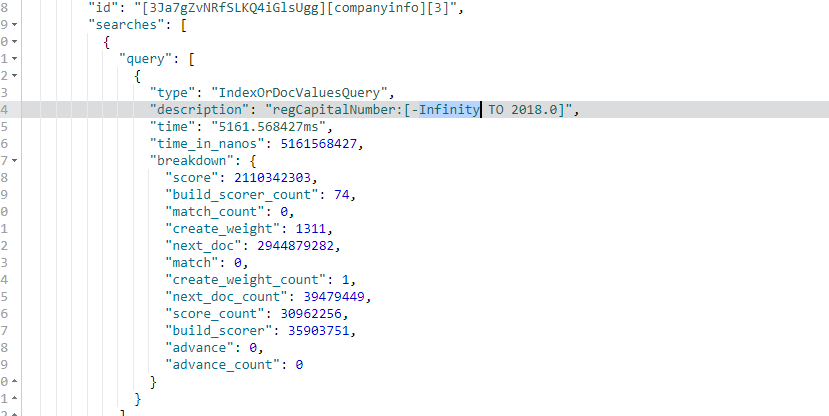
GET /companyinfo/_search?q=regCapitalNumber:[* TO 2018]
{
"profile":"true"
}
7.5 Query String Syntax (4)
- 通配符查询(通配符查询效率低,占用内存大,不建议使用特别是放在最前面)
- ?代表1个字符,*代表0或者多个字符
- title:mi?d
- title:be*
- ?代表1个字符,*代表0或者多个字符
- 正则表达
- title:[bt]oy
- 模糊匹配与近似查询
- title:but~1
- title:“but”~2
通配符查询示例
GET /companyinfo/_search?q=entName:b*&from=0&size=1&timeout=1s
{
"profile":"true"
}
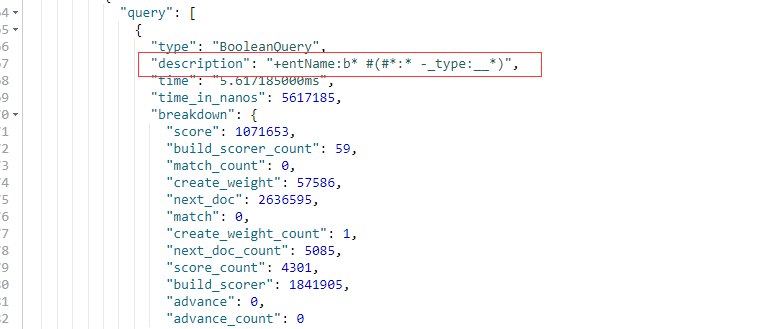
模糊匹配查询示例
GET /companyinfo/_search?q=entName:b~1&from=0&size=1&timeout=1s
{
"profile":"true"
}
近似度匹配示例
GET /companyinfo/_search?q=entName:"B"~2
{
"profile":"true"
}
8 Request Body & Query DSL 简介
8.1 Request Body Search
- 将查询语句通过HTTP Request Body 发送给 ElasticSearch
- Query DSL
POST /my_test_index,my_store/_search?ignore_unavailable=true
{
"profile":true,
"query": {
"match_all": {}
}
}
8.1.1 分页
POST /my_store/_search
{
"from": 0
, "size": 20
, "query": {
"match_all": {}
}
}
- From 从0开始,默认返回10个结果
- 获取靠后的翻页成本越高
8.1.2 排序
GET /my_store/_search
{
"sort": [{"price": "desc"}],
"from": 0,
"size": 20,
"query": {
"match_all": {}
}
}
- 最好是"数字型"与"日期型"字段上排序
- 因为对于多值类型或分析过的字段排序,系统会选一个值,无法得知该值
8.1.3 _source filtering
GET /my_store/_search
{
"_source":["price","productAge"],
"from": 0,
"size": 20,
"query": {
"match_all": {}
}
}
- 如果_source 没有存储,那就只返回匹配的文档的元数据
- _source 支持使用通配符 _source[“name*”,“desc*”]
8.1.4 脚本字段
GET my_store/_search
{
"script_fields": {
"new_field": {
"script": {
"lang": "painless",
"source":"doc['productName'].value+'hello'"
}
}
}
, "query": {
"match_all": {}
}
}
8.1.5 使用查询表达式-Match
GET /my_store/_search
{
"query": {
"match": {
"productID": 30
}
}
}
GET /my_store/_search
{
"query": {
"match": {
"productName":{
"query": "ZHANGSAN",
"operator": "and"
}
}
}
}
8.1.6短语搜索 -Match Phrase
GET my_store/_search
{
"query": {
"match_phrase": {
"content": {
"query": "wang san",
"slop":1
}
}
}
}
result
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.0942618,
"hits": [
{
"_index": "my_store",
"_type": "products",
"_id": "AXdIzcDtomOanSvnaKZX",
"_score": 1.0942618,
"_source": {
"content": "my name is wang san"
}
}
]
}
}
9 Query String 和Simple Query String
9.1 Query String Query
- 类似URI Query
POST my_store/_search
{
"query": {
"query_string": {
"default_field": "content",
"query": "my name is"
}
}
}
POST my_store/_search
{
"query": {
"query_string": {
"fields": ["content","productName"],
"query": "(my name is) OR (ZHANGSAN)"
}
}
}
9.2 Simple Query String Query
- 类似Query String,但是会忽略错误的语法,同时只支持部分查询语法
- 不支持AND OR NOT,会当做字符串处理
- Term之间默认的关系是OR,可以指定Operator
- 支持部分逻辑
-
- 替代 AND
- | 替代 OR
- - 替代not
-
POST my_store/_search
{
"query": {
"simple_query_string": {
"query": "my name is",
"fields": ["content"],
"default_operator": "AND"
}
}
}
10 Dynamic Mapping和常见字段类型
10.1 什么是Mapping
- Mapping类似数据库中的schema的定义,作用如下
- 定义索引中的字段类型
- 定义字段的数据类型,例如字符串,数字,布尔…
- 字段,倒排索引的相关配置,(Analyzed or Not Analyzed,Analyzer)
- Mapping会把JSON文档映射成Lucene所需要的扁平格式
- 一个Mapping属于一个索引的Type
- 每个文档都属于一个Type
- 一个Type有一个Mapping定义
- 7.0开始,不需要在Mapping定义中指定type信息
10.2 字段的数据类型
- 简单类型
- Text/Keyword
- Date
- Integer/Floating
- Boolean
- IPv4&IPv6
- 复杂类型
- 对象类型/嵌套类型
- 特殊类型
- geo_point&geo_shape/percolator
10.3 什么是Dynamic Mapping
- 在写入文档的时候,如果索引不存在,会自动创建索引
- Dynamic Mapping的机制,使得我们无需手动定义Mappings。ElasticSearch会自动根据文档信息,推算出字段的类型
- 但是有时候会推算的不对,例如地理位置信息
- 当类型如果设置不对时,会导致一些功能无法正常运行,例如Range查询
- 查看 my_store的mapping信息
{
GET my_store/_mapping
"embranchment_v1": {
"mappings": {
"embranchment_v1": {
"_all": {
"enabled": false
},
"date_detection": false,
"properties": {
"companyId": {
"type": "keyword"
},
"embranchmentName": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"principal": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"regDate": {
"type": "text"
},
"relation": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"status": {
"type": "keyword"
}
}
},
"_default_": {
"_all": {
"enabled": false
}
}
}
}
}
10.4 类型的自动识别
| JSON类型 | ElasticSearch类型 |
|---|---|
| 字符串 | - 匹配日期格式,-设置为date 设置数字为float或者long,该选项默认关闭 -设置为Text,并添加keyWord字段 |
| 布尔值 | boolean |
| 浮点型 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型所决定 |
| 空值 | 忽略 |
10.5 能否更改Mapping的字段类型
- 两种情况
- 新增加字段
- Dynamic设置为true时,一旦有新增字段的文档写入,Mapping也同时被更新
- Dynamic设置为false时,Mapping不会被更新,新增字段的数据无法被索引但是信息会出现在_source中
- Dynamic设置成Strict,文档写入失败
- 对已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene实现的倒排索引,一旦生成后就不允许修改
- 如果希望改变字段类型,必须Reindex API,重建索引
- 新增加字段
- 原因
- 如果修改了字段的数据类型,会导致已被索引的数据无法被搜索
- 但是如果是增加新的字段就不会有这样的影响
10.6 控制Dynamic Mappings
- 当dynamic被设置成false时,存在新增字段的数据写入,该数据可以被索引但是新增字段被丢弃
- 当设置成Strict模式时,数据写入直接出错
| true | false | strict | |
|---|---|---|---|
| 文档可索引 | YES | YES | NO |
| 字段可索引 | YES | NO | NO |
| Mapping被更新 | YES | NO | NO |
PUT my_store
{
"mappings":{
"_doc":{
"dynamic":"false"
}
}
}
11 显示Mapping设置和常见参数介绍
11.1 自定义Mapping的一些建议
- 可以参照API手册,纯手写
- 为了减少输入的工作量,减少出错概率,可以依照以下步骤
- 创建一个临时的index,写入一些样本数
- 通过访问Mapping API 获得该临时文件的动态Mapping定义
- 修改后用,使用该配置创建你的索引
- 删除临时索引
11.2控制当前字段是否被索引
- index 控制当前字段是否被索引。默认为true,如果设置为false,该字段不可被搜索
- 可以避免倒排索引的创建节省磁盘的开销

11.3 index Options
- 四种不同级别的index Options配置,可以控制倒排索引记录的内容
- docs 记录doc id
- freqs 记录doc id 和 term frequencies
- positions 记录doc id/ term frequencies/term position
- offset dic id/term frequencies/term posistion/character offects
- Text类型默认记录postions,其他默认为docs
- 记录内容越多,占用存储空间越大

11.4 null_value
- 需要对Null实现搜索
- 只有KeyWord 类型支持设定Null_Value

11.5 copy_to 设置
- _all 在7中被copt_to所替代
- 满足一些特定的搜索需求
- copy_to 将字段的数值拷贝到目标字段,实现类似_all的作用
- copy_to 的目标字段不出现在_source 中

11.6 数组类型
- ElasticSearh 中不提供专门的数组类型。但是任何字段都可以包含多个相同类型的数值

12 多字段特性及Mapping中配置自定义Analyzer
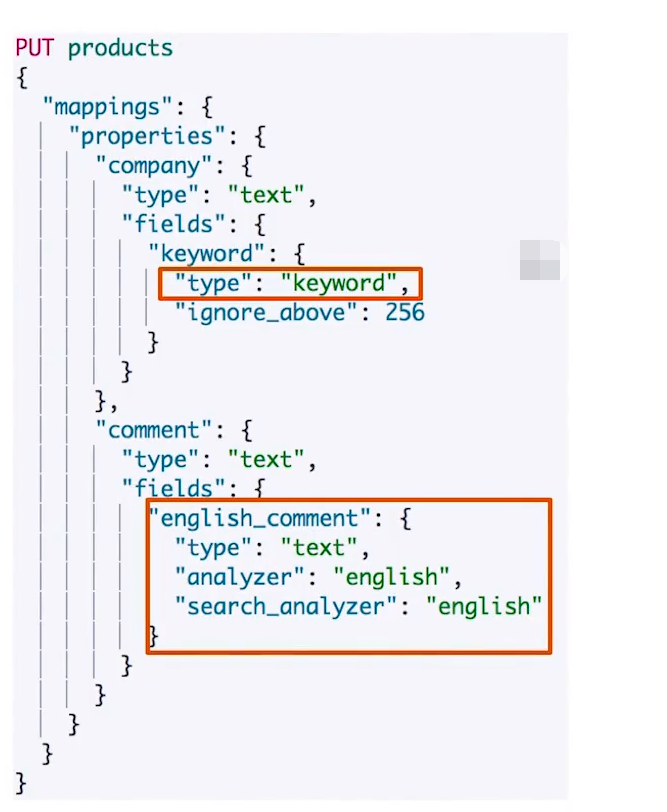
12.1 多字段类型
- 厂商名字实现精准匹配
- 增加一个keyword字段
- 使用不同的analyzer
- 不同语言
- pinyin字段的搜索
- 还支持为搜索和索引指定不同的Analyzer
12.2 Exact Values v.s Full Text
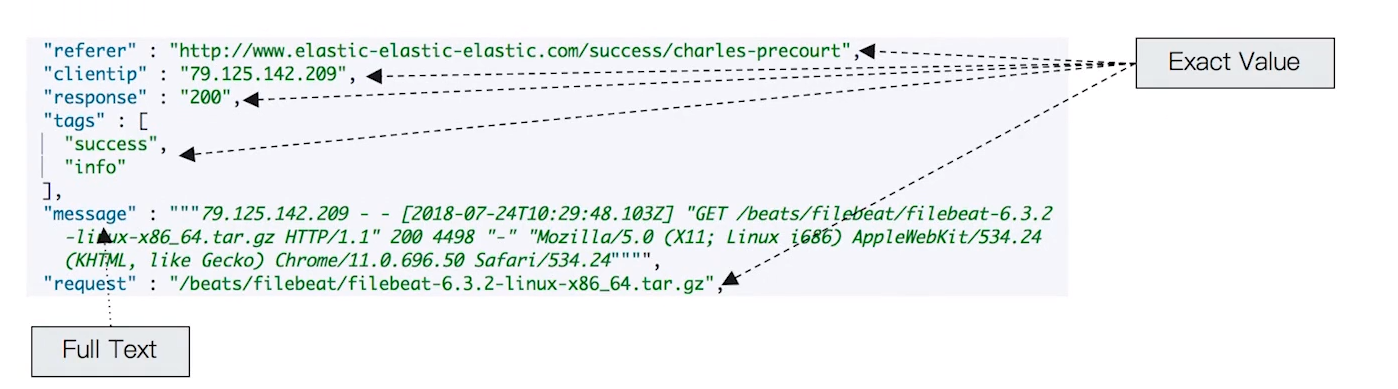
- Exact Values v.s Full Text
- Exact Value: 包括数字/日期/具体一个字符串(例如 “Apple Store”)
- ElasticSearch中的KeyWord
- 全文本,非结构化的文本数据
- ElasticSearch中的text
- Exact Value: 包括数字/日期/具体一个字符串(例如 “Apple Store”)
12.3 Exact Values 不需要分词
- ElasticSearch 为每一个字段创建一个倒排索引
- Exact Value 在索引时,不需要做特殊的分词处理
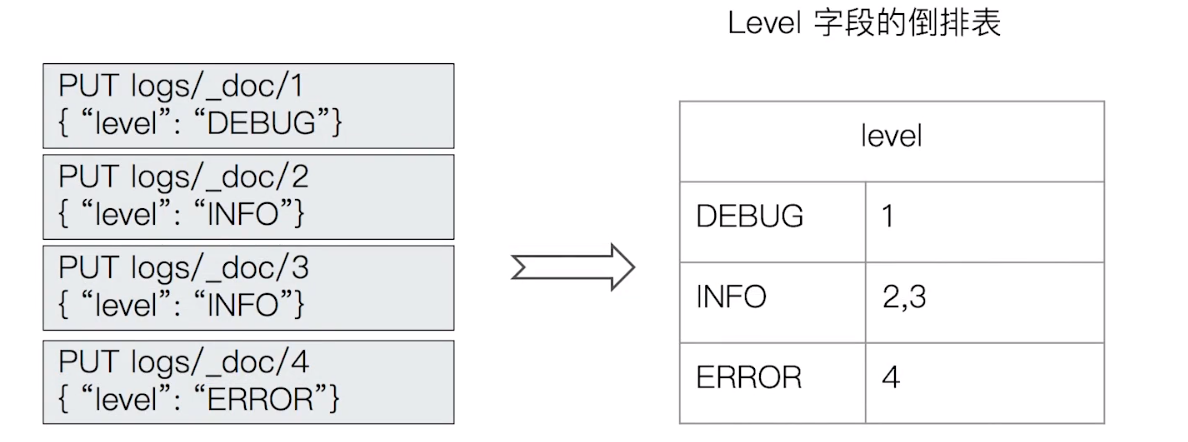
- Exact Value 在索引时,不需要做特殊的分词处理
12.4 自定义分词
- 当ElassticSearch带的分词器无法满足时,可以自定义分词器通过自组合不同的组件实现
- Character Filter
- Tokenizer
- Token Filter
12.4.1 Character Filter
- 在Tokenizer之前对文本进行处理,例如增加删除及替换字符。可以配置多个Character Filters。会影响Tokenizer的postion和offset 信息
- 一些自带的Character Filters
- HTML stricp -去除HTML标签
- Mapping 字符串替换
- Pattern replace 正则匹配替换
12.4.2 Tokenizer
- 将原始的文本按照一定的规则,切分为词(term or token)
- ElasticSearch 内置的Tokenizer
- whitespace/tandard/uax_url_email/pattern/keyword/path hierarchy
- 可以用Java开发插件,实现自己的Tokenizer
12.4.3 Token Filters
- 将Tokenizer输出的单词(term),进行增加,修改,删除
- 自带的Token Filters
- Lowercase/stop/synonym(添加近义词)
13 Index Template 和Dynamic Template
13.1 什么是 Index Template ?
- Index Template 帮助你设定Mappings 和Settings ,并按照一定的规则自动匹配到新创建的索引之上
- 模板仅在一个索引被新创建时,才会产生作用。修改模板不会影响已创建的索引
- 你可以设定多个索引模板,这些设置会被"merge"在一起
- 你可以指定 "order"的数值,控制 "merging"的过程

13.2 Index Template 的工作方式
- 当一个索引被新创建时
- 应用ElasticSearch 默认的setting和mappings
- 应用order 数值低的 Index Template 中的设定
- 应用order 高的Index Template 中的设定,之前的设定会被覆盖
- 应用创建索引时,用户所指定的Setting和Mappings,并覆盖之前模板中的设定
13.3 什么是Dynamic Template
- 根据ElasticSearch 识别的数据类型,结合字段名称,来动态设定数据类型
- 所有的只付出类型都设定成keyword,或者关闭keyword字段
- is 开头的字段都设置成false
- long_开头的都设置成long类型

- Dynamic Template 是定义在某个索引的Mapping中
- Template有一个名称
- 匹配规则是一个数组
- 为匹配到字段设置Mapping
14 ElasticSearch聚合分析简介
14.1 什么是聚合(Aggregation)
- ElasticSearch 除搜索以外,提供的针对ES数据进行统计分析的能力
- 实时性高
- Hadoop(T+1)
- 通过聚合,我们会得到一个数据的概览,是分析和总结全套的数据,而不是寻找单个文档
- 某个地区的客房数量
- 不同的价格区间,可预订的酒店数量
- 高性能,只需要一条语句,就可以从ElasticSearch得到分析结果
- 无需 在客户端自己去实现分析逻辑
Kibana的聚合分析
14.2 集合的分类
- Bucket Aggregation 一些列满足特定条件的文档的集合
- Metric Aggregation 一些数学运算,可以对文档字段进行统计分析
- Pipeline Aggregation 对其他的聚合结果进行二次聚合
- Matrix Aggregration 支持对多个字段的操作并提供一个结果矩阵
14.2.1 Bucket & Metric
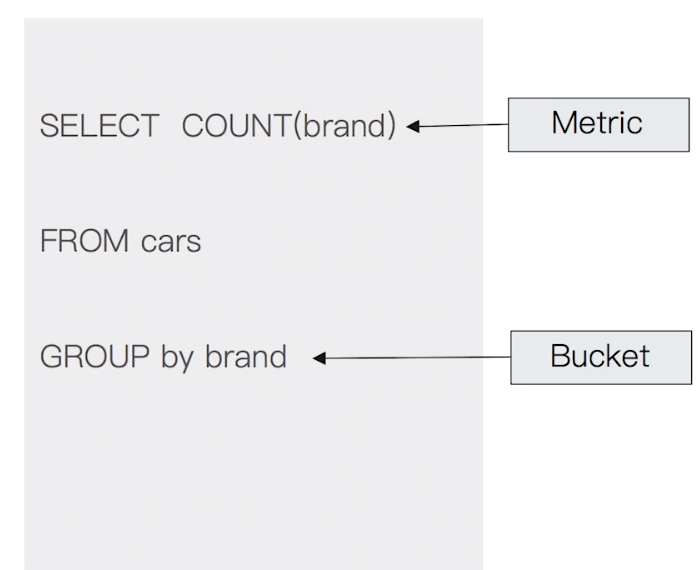
- Metric 一些系列的统计方法
- Bucket 一组满足条件的文档
14.2.1.1 Bucket
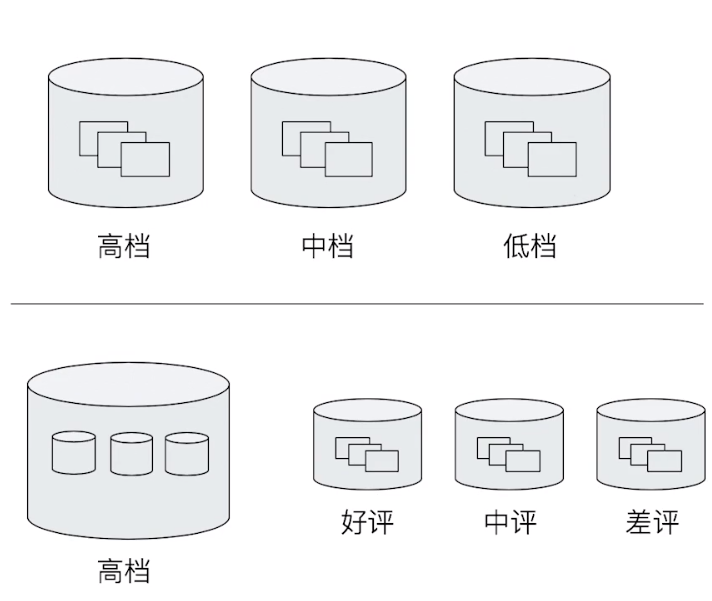
- 一些例子
- 杭州属于浙江/一个演员属于 男或女性
- 嵌套关系-杭州属于浙江属于中国属于亚洲
- ElasticSearch提供了很多类型的Bucket,帮助你用多种方式划分文档
- Term & Range(时间/年龄区间/地理位置)
根据地区来聚合企业数量
GET companyinfo/_search
{
"size":0,
"aggs":{
"flight_dest":{
"terms": {
"field":"city"
}
}
}
}
{
"took": 6485,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 157377743,
"max_score": 0,
"hits": []
},
"aggregations": {
"flight_dest": {
"doc_count_error_upper_bound": 1243691,
"sum_other_doc_count": 97419767,
"buckets": [
{
"key": "",
"doc_count": 25140413
},
{
"key": "广东省",
"doc_count": 6211429
},
{
"key": "江苏省",
"doc_count": 4535255
},
{
"key": "山东省",
"doc_count": 4360040
},
{
"key": "北京市",
"doc_count": 4061179
},
{
"key": "上海市",
"doc_count": 3813461
},
{
"key": "浙江省",
"doc_count": 3713236
},
{
"key": "四川省",
"doc_count": 2834499
},
{
"key": "河南省",
"doc_count": 2747657
},
{
"key": "河北省",
"doc_count": 2540804
}
]
}
}
}
14.2.1.2 加入Metrics
根据城市聚合企业并取出注册资本的最大值和最小值
GET companyinfo/_search
{
"size":0,
"aggs":{
"flight_dest":{
"terms": {
"field":"city"
}
},
"max_price":{
"max": {
"field": "regCapitalNumber"
}
},
"min_price":{
"min": {
"field": "regCapitalNumber"
}
}
}
}
{
"took": 26141,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 157377743,
"max_score": 0,
"hits": []
},
"aggregations": {
"max_price": {
"value": 18944818812
},
"min_price": {
"value": 0
},
"flight_dest": {
"doc_count_error_upper_bound": 1243691,
"sum_other_doc_count": 97419767,
"buckets": [
{
"key": "",
"doc_count": 25140413
},
{
"key": "广东省",
"doc_count": 6211429
},
{
"key": "江苏省",
"doc_count": 4535255
},
{
"key": "山东省",
"doc_count": 4360040
},
{
"key": "北京市",
"doc_count": 4061179
},
{
"key": "上海市",
"doc_count": 3813461
},
{
"key": "浙江省",
"doc_count": 3713236
},
{
"key": "四川省",
"doc_count": 2834499
},
{
"key": "河南省",
"doc_count": 2747657
},
{
"key": "河北省",
"doc_count": 2540804
}
]
}
}
}
14.2.1.3 嵌套
查看航班目的地的统计信息,平均票价,以及天气状况

最后
以上就是孤独荷花最近收集整理的关于(三)ElasticSearch实战基础教程(ElasticSearch入门)7. URI 详解8 Request Body & Query DSL 简介9 Query String 和Simple Query String10 Dynamic Mapping和常见字段类型11 显示Mapping设置和常见参数介绍12 多字段特性及Mapping中配置自定义Analyzer13 Index Template 和Dynamic Template14 ElasticSearch聚合分析简介的全部内容,更多相关(三)ElasticSearch实战基础教程(ElasticSearch入门)7.内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复