一、步骤
step1:使用idea创建maven管理工具创建项目
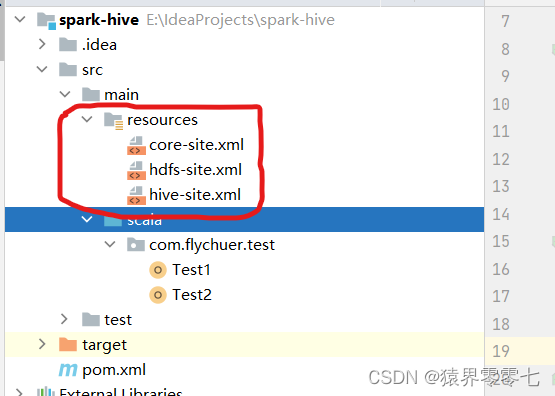
step2:在main下添加resources文件夹,并设置为Resources root
step3:拷贝Hadoop安装路径中etc目录下的core-site.xml、hdfs-site.xml文件到resources中
step4:拷贝hive安装路径中conf目录下的hive-site.xml文件到resources中
step5:修改hive-site.xml文件中的javax.jdo.option.ConnectionURL,改为自己虚拟机的IP地址
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.90.3:3306/hive</value>(mysql地址localhost)
</property>
step6:依赖配置
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.springml</groupId>
<artifactId>spark-sftp_2.11</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
<version>3.6</version>
</dependency>
<dependency>
<groupId>com.jcraft</groupId>
<artifactId>jsch</artifactId>
<version>0.1.55</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.delta/delta-core -->
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-core_2.12</artifactId>
<version>0.5.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
step7:创建对象
import org.apache.spark.sql.SparkSession
object Test1 {
def main(args: Array[String]): Unit = {
// val conf = new SparkConf().setMaster("local[1]").setAppName("sparkDemo2")
// val sc = SparkContext.getOrCreate(conf)
// sc.setLogLevel("error")
// 建立sparkSession,并传入定义好的Conf
val spark = SparkSession
.builder()
.master("local[*]")
.appName("sparkDemo")
.enableHiveSupport()
.getOrCreate()
spark.sql("show databases").show()
spark.sql("select * from test_data.teacher").show()
spark.sql("insert into test_data.teacher values(1,'zs')")
}
}
step8:执行成功。
问题总结
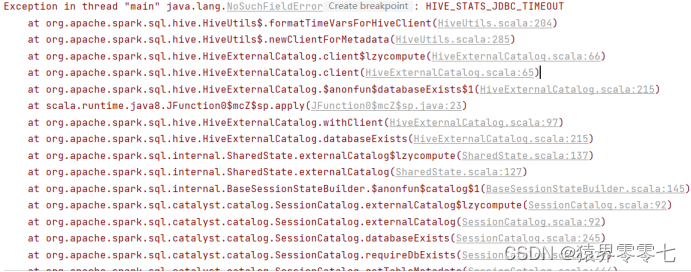
问题一:
java.lang.NoSuchFieldError: HIVE_STATS_JDBC_TIMEOUT
问题原因:
spark-hive jar包版本冲突
出现问题时使用的jar包版本
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>2.4.0</version>
</dependency>
解决方案:
修改spark-hive的版本,与spark-core、spark-sql一致,修改后此问题解决
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
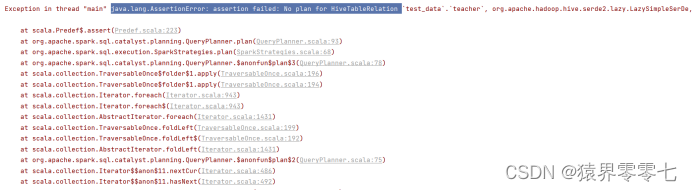
问题二:
java.lang.AssertionError: assertion failed: No plan for HiveTableRelation
出现问题时代码:
val conf = new SparkConf().setMaster("local[1]").setAppName("sparkDemo2")
val sc = SparkContext.getOrCreate(conf)
sc.setLogLevel("error")
// 建立sparkSession,并传入定义好的Conf
val spark = SparkSession
.builder()
.master("local[*]")
.appName("sparkDemo")
.enableHiveSupport()
.getOrCreate()
解决方法:
将前三行代码去掉
最后
以上就是无情皮带最近收集整理的关于Spark使用scala语言连接hive数据库一、步骤问题总结的全部内容,更多相关Spark使用scala语言连接hive数据库一、步骤问题总结内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复