一、基于用户的Jaccard相似度公式
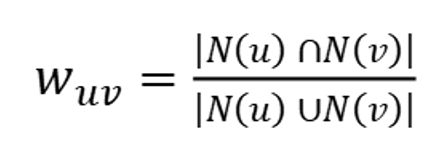
其中,u、v表示任意两个用户,N(u)表示用户u喜欢的物品集合,N(v)表示用户v喜欢物品的集合。
代码
public class UserCFApp {
public static void main(String[]args){
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("UserCFApp");
sparkConf.setMaster("local[*]");
SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();
String url = "jdbc:mysql://localhost:3306/spark-mysql?useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false";
String driver = "com.mysql.jdbc.Driver";
String user = "root";
String password = "admin";
Dataset<Row> dataset = sparkSession.read()
.format("jdbc")
.option("driver", driver)
.option("url",url)
.option("dbtable","user_item")
.option("user",user)
.option("password",password)
.load();
Dataset<Row> userCount = dataset.groupBy("user_id").count();
Dataset<Row> user2UserCount = dataset.as("a").join(dataset.as("b"),
functions.column("a.item_id").$eq$eq$eq(functions.column("b.item_id")))
.where(functions.column("a.user_id").notEqual(functions.column("b.user_id")))
.select(functions.column("a.user_id").as("a_user_id"),
functions.column("b.user_id").as("b_user_id"))
.groupBy("a_user_id", "b_user_id").count();
Dataset<Row> result = user2UserCount.as("u2u")
.join(userCount.as("uc1"), functions.column("u2u.a_user_id").$eq$eq$eq(functions.column("uc1.user_id")))
.join(userCount.as("uc2"), functions.column("u2u.b_user_id").$eq$eq$eq(functions.column("uc2.user_id")))
.selectExpr("u2u.a_user_id", "u2u.b_user_id", "u2u.count/(uc1.count + uc2.count - u2u.count) as count");
result.show();
// result.write()
// .mode(SaveMode.Overwrite)
// .format("jdbc")
// .option("driver", driver)
// .option("url",url)
// .option("dbtable","user_similar")
// .option("user",user)
// .option("password",password)
// .save();
sparkSession.stop();
}
}
二、基于用户的余弦相似度公式
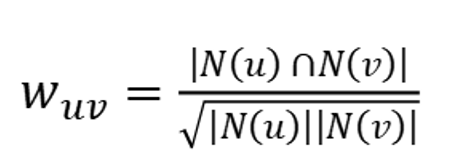
其中,u、v表示任意两个用户,N(u)表示用户u喜欢的物品集合,N(v)表示用户v喜欢物品的集合。
public class UserCF2App {
public static void main(String[]args){
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("UserCFApp");
sparkConf.setMaster("local[*]");
SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();
String url = "jdbc:mysql://localhost:3306/spark-mysql?useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false";
String driver = "com.mysql.jdbc.Driver";
String user = "root";
String password = "admin";
Dataset<Row> dataset = sparkSession.read()
.format("jdbc")
.option("driver", driver)
.option("url",url)
.option("dbtable","user_item")
.option("user",user)
.option("password",password)
.load();
Dataset<Row> userCount = dataset.groupBy("user_id").count();
Dataset<Row> user2UserCount = dataset.as("a").join(dataset.as("b"),
functions.column("a.item_id").$eq$eq$eq(functions.column("b.item_id")))
.where(functions.column("a.user_id").notEqual(functions.column("b.user_id")))
.select(functions.column("a.user_id").as("a_user_id"),
functions.column("b.user_id").as("b_user_id"))
.groupBy("a_user_id", "b_user_id").count();
Dataset<Row> result = user2UserCount.as("u2u")
.join(userCount.as("uc1"), functions.column("u2u.a_user_id").$eq$eq$eq(functions.column("uc1.user_id")))
.join(userCount.as("uc2"), functions.column("u2u.b_user_id").$eq$eq$eq(functions.column("uc2.user_id")))
.selectExpr("u2u.a_user_id", "u2u.b_user_id", "u2u.count/pow(uc1.count * uc2.count, 0.5) as count");
result.show();
// result.write()
// .mode(SaveMode.Overwrite)
// .format("jdbc")
// .option("driver", driver)
// .option("url",url)
// .option("dbtable","user_similar")
// .option("user",user)
// .option("password",password)
// .save();
sparkSession.stop();
}
}
最后
以上就是开心酸奶最近收集整理的关于Spark SQL(七)之基于用户的相似度公式的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复