用户相似度计算的改进
上一节介绍了计算用户兴趣相似度的最简单的公式(余弦相似度公式),
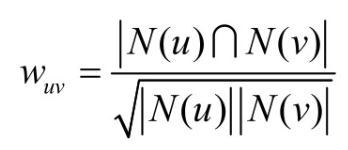
但这个公式过于粗糙,本节将讨论如何改进该公式来提高UserCF的推荐性能。首先,以图书为例,如果两个用户都曾经买过《新华字典》,这丝毫不能说明他们兴趣相似,因为绝大多数中国人小时候都买过《新华字典》。但如果两个用户都买过《数据挖掘导论》,那可以认为他们的兴趣比较相似,因为只有研究数据挖掘的人才会买这本书。换句话说,两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。因此,John S. Breese在论文中提出了如下公式,根据用户行为计算用户的兴趣相似度:
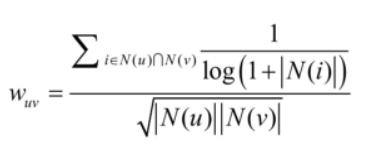
可以看到,该公式通过
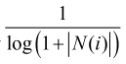
惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响。本节将基于上述用户相似度公式的UserCF算法记为User-IIF算法。下面的代码实现了上述用户相似度公式。
def UserSimilarity(train):
# build inverse table for item_users
item_users 最后
以上就是清秀小伙最近收集整理的关于基于用户的协同过滤算法(二):用户相似度计算的改进用户相似度计算的改进的全部内容,更多相关基于用户内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复