比较字符串"我出门了"和"我要出门了",只需调用方法getSimilarityByNormal:
// 比较标题相似度
Double similarity = SimilarityDegreeUtil.getSimilarityByNormal("我出门了",
"我要出门了");
方法利用了余弦定理。
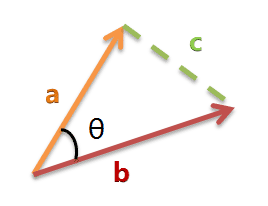
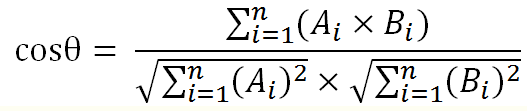
余弦定理:我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
附上代码:
package com.iss.reptile.commons.utils;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class SimilarityDegreeUtil {
/**
* 相似度比较(普通对比)
*
* @param text1
* @param text2
* @return
*/
public static double getSimilarityByNormal(String textOne, String textTwo) {
@SuppressWarnings("unused")
long start = System.currentTimeMillis();
double denominator = SimilarityDegreeUtil.getSimilarity(textOne,
textTwo);
/*System.out.println("用时:" + (System.currentTimeMillis() - start));
System.out.println("相似度:" + denominator);*/
return denominator;
}
/**
* 相似度比较
*
* @param text1
* @param text2
* @return
* @throws IOException
*/
public static double getSimilarityByParticiple(String textOne,
String textTwo) throws IOException {
List<String> textOneList = IKAnalyzerUtil.getParticiple(2, textOne);
List<String> textTwoList = IKAnalyzerUtil.getParticiple(2, textTwo);
// 去重
Set<String> repeats = new HashSet<String>(textOneList);
repeats.addAll(new HashSet<String>(textTwoList));
StringBuffer repeatText = new StringBuffer();
for (String repeat : repeats) {
repeatText.append(repeat);
}
long start = System.currentTimeMillis();
double denominatorOne = SimilarityDegreeUtil.getSimilarity(textOne,
repeatText.toString());
double denominatorTwo = SimilarityDegreeUtil.getSimilarity(textTwo,
repeatText.toString());
double denominator = (denominatorOne + denominatorTwo) / 2D;
System.out.println("用时:" + (System.currentTimeMillis() - start));
System.out.println("相似度:" + denominator);
return denominator;
}
/**
* 比较相似度
*
* @param doc1
* @param doc2
* @return
*/
private static double getSimilarity(String doc1, String doc2) {
if (doc1 != null && doc1.trim().length() > 0 && doc2 != null
&& doc2.trim().length() > 0) {
Map<Integer, int[]> AlgorithmMap = new HashMap<Integer, int[]>();
// 将两个字符串中的中文字符以及出现的总数封装到,AlgorithmMap中
for (int i = 0; i < doc1.length(); i++) {
char d1 = doc1.charAt(i);
if (isChinese(d1)) {// 标点和数字不处理
int charIndex = getGB2312Id(d1);// 保存字符对应的GB2312编码
if (charIndex != -1) {
int[] fq = AlgorithmMap.get(charIndex);
if (fq != null && fq.length == 2) {
fq[0]++;// 已有该字符,加1
} else {
fq = new int[2];
fq[0] = 1;
fq[1] = 0;
AlgorithmMap.put(charIndex, fq);// 新增字符入map
}
}
}
}
for (int i = 0; i < doc2.length(); i++) {
char d2 = doc2.charAt(i);
if (isChinese(d2)) {
int charIndex = getGB2312Id(d2);
if (charIndex != -1) {
int[] fq = AlgorithmMap.get(charIndex);
if (fq != null && fq.length == 2) {
fq[1]++;
} else {
fq = new int[2];
fq[0] = 0;
fq[1] = 1;
AlgorithmMap.put(charIndex, fq);
}
}
}
}
Iterator<Integer> iterator = AlgorithmMap.keySet().iterator();
double sqdoc1 = 0;
double sqdoc2 = 0;
double denominator = 0;
while (iterator.hasNext()) {
int[] c = AlgorithmMap.get(iterator.next());
denominator += c[0] * c[1];
sqdoc1 += c[0] * c[0];
sqdoc2 += c[1] * c[1];
}
return denominator / Math.sqrt(sqdoc1 * sqdoc2);// 余弦计算
} else {
throw new NullPointerException(
" the Document is null or have not cahrs!!");
}
}
private static boolean isChinese(char ch) {
// 判断是否汉字
return (ch >= 0x4E00 && ch <= 0x9FA5);
/*
* if (ch >= 0x4E00 && ch <= 0x9FA5) {//汉字 return true; }else{ String
* str = "" + ch; boolean isNum = str.matches("[0-9]+"); return isNum; }
*/
/*
* if(Character.isLetterOrDigit(ch)){ String str = "" + ch; if
* (str.matches("[0-9a-zA-Z\u4e00-\u9fa5]+")){//非乱码 return true; }else
* return false; }else return false;
*/
}
/**
* 根据输入的Unicode字符,获取它的GB2312编码或者ascii编码,
*
* @param ch
* 输入的GB2312中文字符或者ASCII字符(128个)
* @return ch在GB2312中的位置,-1表示该字符不认识
*/
private static short getGB2312Id(char ch) {
try {
byte[] buffer = Character.toString(ch).getBytes("GB2312");
if (buffer.length != 2) {
// 正常情况下buffer应该是两个字节,否则说明ch不属于GB2312编码,故返回'?',此时说明不认识该字符
return -1;
}
int b0 = (int) (buffer[0] & 0x0FF) - 161; // 编码从A1开始,因此减去0xA1=161
int b1 = (int) (buffer[1] & 0x0FF) - 161;
return (short) (b0 * 94 + b1);// 第一个字符和最后一个字符没有汉字,因此每个区只收16*6-2=94个汉字
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return -1;
}
}
最后
以上就是个性帅哥最近收集整理的关于比较2个字符串的相似度的全部内容,更多相关比较2个字符串内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复