文本比较的核心就是比较两个给定的文本(可以是字节流等)之间的差异。目前,主流的比较文本之间的差异主要有两大类。一类是基于编辑距离(Edit Distance)的,例如LD算法。一类是基于最长公共子串的(Longest Common Subsequence),例如Needleman/Wunsch算法等。
LD算法(Levenshtein Distance)又成为编辑距离算法(Edit Distance)。他是以字符串A通过插入字符、删除字符、替换字符变成另一个字符串B,那么操作的过程的次数表示两个字符串的差异.
基于动态规划的算法是四类方法中发展最早的一种。1980 年SELLERS【SELLERS, P. 1980】将动态规划的思想引入近似串匹配算法中,其时间复杂度为O(mn),算法效率比较低但是能适应各种不同的距离函数。下面首先看如何计算编辑距离,然后讲述如何将其应用到匹配算法中
假设我们要计算串x和串y的编辑距离ld(x,y),|x|=m,|y|=n。计算过程需要用到动态规划矩阵C[0…|x|,0…|y|],C[i,j]表示要匹配串x[1…i]和串y[1…j]需要的操作的次数即串x[1…I]和y[1…j]的编辑距离。
初始化如下:
C[i,0]=i
C[0,j]=j
计算公式如下:
如果(x[i]==y[j])
C[i,j]= C[i-1,j-1]
否则
1+min(C[i-1,j],C[i,j],C[i-1,j-1])
C[i,0]表示串x[1…I]与空串的编辑距离,同理,C[0,j]表示y[1…j]与空串的编辑距离。当计算C[i,j]时,所有C[i’,j’](i’<=i并且j’<=j)即C矩阵中所有C[i,j]左上方的单元都已计算完毕。
比较字符x[i]和字符Y[j],
如果x[i]==y[j],我们不再需要任何操作即可将x[1…i]转化为y[1…j];
否则,我们需要进行某种操作。可能的操作有下面三种:
l 删除x[1…I]的最后一个字符x[i]并利用x[1…i-1]转化为y[1…j]的结果;
l 或者在x[1…i]末尾插入字符y[j]并利用x[1…i-1]转化为y[1…j-1]的结果;
l 或者将x[I]替换为y[j]并利用x[i…I-1]转化为y[1…j-1]的结果。
计算公式又可表示为
C[i,j]=min(C[i-1,j-1]+ δ(x[i],y[j]),C[i,j-1]+1,C[I-1,j]+1)。
如果x[i]==y[j]: δ(x[i],y[j])=0,
如果x[i]!=y[j]: δ(x[i],y[j])= 1 。
其数据依赖关系为:动态规划矩阵中的每一个元素,依赖于它左侧、上方、左上方的元素。
在计算相似度矩阵时,需要计算整个(n+1)×(m+1)表格的每一项。在计算任意一项C[i, j]时,需要借助于(i-1, j-1)、(i, j-1)和(i-1,j)这三项的分值因此,计算相似度矩阵算法的复杂度为c×(n+1)×(m+1) = O(nm),c为一常量。动态规划算法的时间复杂度O(mn),空间复杂度O(min(m,n))。
例如:
许多程序会大量使用字符串。对于不同的字符串,我们希望能够有办法判断其相似程度。我们定义了一套操作方法来把两个不相同的字符串变得相同,具体的操作方法为:
1.修改一个字符(如把“a”替换为“b”)。
2.增加一个字符(如把“abdd”变为“aebdd”)。
3.删除一个字符(如把“travelling”变为“traveling”)。
比如,对于“abcdefg”和“abcdef”两个字符串来说,我们认为可以通过增加/减少一个“g“的方式来达到目的。上面的两种方案,都仅需要一次操作。把这个操作所需要的次数定义为两个字符串的距离,给定任意两个字符串,你是否能写出一个算法来计算出它们的距离?
分析与解法
不难看出,两个字符串的距离肯定不超过它们的长度之和(我们可以通过删除操作把两个串都转化为空串)。虽然这个结论对结果没有帮助,但至少可以知道,任意两个字符串的距离都是有限的。
我们还是应该集中考虑如何才能把这个问题转化成规模较小的同样的问题。如果有两个串A=xabcdae和B=xfdfa,它们的第一个字符是相同的,只要计算A[2,…,7]=abcdae和B[2,…,5]=fdfa的距离就可以了。但是如果两个串的第一个字符不相同,那么可以进行如下的操作(lenA和lenB分别是A串和B串的长度):
1.删除A串的第一个字符,然后计算A[2,…,lenA]和B[1,…,lenB]的距离。
2.删除B串的第一个字符,然后计算A[1,…,lenA]和B[2,…,lenB]的距离。
3.修改A串的第一个字符为B串的第一个字符,然后计算A[2,…,lenA]和B[2,…,lenB]的距离。
4.修改B串的第一个字符为A串的第一个字符,然后计算A[2,…,lenA]和B[2,…,lenB]的距离。
5.增加B串的第一个字符到A串的第一个字符之前,然后计算A[1,…,lenA]和B[2,…,lenB]的距离。
6.增加A串的第一个字符到B串的第一个字符之前,然后计算A[2,…,lenA]和B[1,…,lenB]的距离。
在这个题目中,我们并不在乎两个字符串变得相等之后的字符串是怎样的。所以,可以将上面6个操作合并为:
1.一步操作之后,再将A[2,…,lenA]和B[1,…,lenB]变成相同字符串。
2.一步操作之后,再将A[1,…,lenA]和B[2,…,lenB]变成相同字符串。
3.一步操作之后,再将A[2,…,lenA]和B[2,…,lenB]变成相同字符串。
这样,很快就可以完成一个递归程序。
在以上面的思想完成代码后,对程序进行了一番测试。第一次找了两个相似的字符串,长度分别为15和17。速度和结果都比较满意。这也印证了算法的正确性。第二次找了两个相似的字符串,长度分别为1500和1507。嗯,直接跳出错误,说是堆栈错误。实际上是由于递归嵌套出了问题。采用递归算法,只是理论上有效,便于理解,实际应用中会出现各种限制。如本例,嵌套约1000层的时候就超过了系统的限制。必须想一个解决之道。仔细观察,可以发现用数学性的语言描述就是
F(n,m)=G(F(n,m),F(n+1,m),F(n,m+1))
这个可以简化为递推,由于递推可以放在一个函数内,就解决了系统的递归限制。
1.百度百科介绍:
Levenshtein 距离,又称编辑距离,指的是两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。
许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
编辑距离的算法是首先由俄国科学家Levenshtein提出的,故又叫Levenshtein Distance。
2.用途
模糊查询
3.实现过程
a.首先是有两个字符串,这里写一个简单的 abc和abe
b.将字符串想象成下面的结构。
A处 是一个标记,为了方便讲解,不是这个表的内容。
| abc | a | b | c | |
| abe | 0 | 1 | 2 | 3 |
| a | 1 | A处 | ||
| b | 2 | |||
| e | 3 |
c.来计算A处 出得值
它的值取决于:左边的1、上边的1、左上角的0.
按照Levenshtein distance的意思:
上面的值和左面的值都要求加1,这样得到1+1=2。
A处 由于是两个a相同,左上角的值加0.这样得到0+0=0。
这是后有三个值,左边的计算后为2,上边的计算后为2,左上角的计算为0,所以A处 取他们里面最小的0.
d.于是表成为下面的样子
| abc | a | b | c | |
| abe | 0 | 1 | 2 | 3 |
| a | 1 | 0 | ||
| b | 2 | A处 | ||
| e | 3 |
在B处会同样得到三个值,左边计算后为3,上边计算后为1,在B处 由于对应的字符为a、b,不相等,所以左上角应该在当前值的基础上加1,这样得到1+1=2,在(3,1,2)中选出最小的为B处的值。
e.于是表就更新了
| abc | a | b | c | |
| abe | 0 | 1 | 2 | 3 |
| a | 1 | 0 | ||
| b | 2 | 1 | ||
| e | 3 | C处 |
C处 计算后:上面的值为2,左边的值为4,左上角的:a和e不相同,所以加1,即2+1,左上角的为3。
在(2,4,3)中取最小的为C处 的值。
f.于是依次推得到
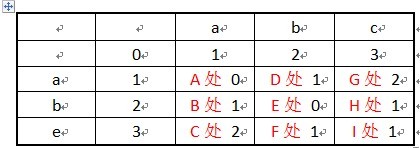
I处: 表示abc 和abe 有1个需要编辑的操作。这个是需要计算出来的。
同时,也获得一些额外的信息。
A处: 表示a 和a 需要有0个操作。字符串一样
B处: 表示ab 和a 需要有1个操作。
C处: 表示abe 和a 需要有2个操作。
D处: 表示a 和ab 需要有1个操作。
E处: 表示ab 和ab 需要有0个操作。字符串一样
F处: 表示abe 和ab 需要有1个操作。
G处: 表示a 和abc 需要有2个操作。
H处: 表示ab 和abc 需要有1个操作。
I处: 表示abe 和abc 需要有1个操作。
g.计算相似度
先取两个字符串长度的最大值maxLen,用1-(需要操作数除/maxLen),得到相似度。
例如abc 和abe一个操作,长度为3,所以相似度为1-1/3=0.666。
4.代码实现计算编辑距离
直接能运行, 复制过去就行。
intMinimum (int a, int b, int c)
{
int mi;
mi = a;
if (b < mi) {
mi = b;
}
if (c < mi) {
mi = c;
}
return mi;
}
voidlevenshteinDistance(char * x,char *y)
{
int i,j,m,n;
int dsw[strlen(x)][strlen(y)];
m=strlen(x);
n=strlen(y);
for(i=0;i<=m;i++)
dsw[i][0]=i;
for(j=1;j<=n;j++)
dsw[0][j]=j;
for(i=1;i<=m;i++){
for(j=1;j<=n;j++){
if(x[i]==y[j])
dsw[i][j]=dsw[i-1][j-1];
else
dsw[i][j]=1+Minimum(dsw[i-1][j-1],dsw[i-1][j],dsw[i][j-1]); }
}
for(i=1;i<=m;i++){
for(j=1;j<=n;j++){
printf("%4d,",dsw[i][j]);
}
printf("n");
}
}
intmain(){
levenshteinDistance("ncicict","casnciccn");
}
结果:同上
1, 2, 3, 3, 4, 5, 6, 7, 8,
2, 2, 3, 4, 3, 4, 5, 6, 7,
3, 3, 3, 3, 4, 3, 4, 5, 6,
4, 4, 4, 4, 3, 4, 4, 5, 6,
5, 5, 5, 4, 4, 3, 4, 5, 6,
6, 6, 6, 5, 5, 4, 4, 5, 6,
7, 7, 7, 6, 6, 5, 5, 5, 5,
package code;
/**
* @className:MyLevenshtein.java
* @classDescription:Levenshtein Distance 算法实现
* 可以使用的地方:DNA分析 拼字检查 语音辨识 抄袭侦测
* @author:donghai.wan
* @createTime:2012-1-12
*/
public class MyLevenshtein {
public static void main(String[] args) {
//要比较的两个字符串
String str1 = "今天星期四";
String str2 = "今天是星期五";
levenshtein(str1,str2);
}
/**
* DNA分析 拼字检查 语音辨识 抄袭侦测
*
* @createTime 2012-1-12
*/
public static void levenshtein(String str1,String str2) {
//计算两个字符串的长度。
int len1 = str1.length();
int len2 = str2.length();
//建立上面说的数组,比字符长度大一个空间
int[][] dif = new int[len1 + 1][len2 + 1];
//赋初值,步骤B。
for (int a = 0; a <= len1; a++) {
dif[a][0] = a;
}
for (int a = 0; a <= len2; a++) {
dif[0][a] = a;
}
//计算两个字符是否一样,计算左上的值
int temp;
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if (str1.charAt(i - 1) == str2.charAt(j - 1)) {
temp = 0;
} else {
temp = 1;
}
//取三个值中最小的
dif[i][j] = min(dif[i - 1][j - 1] + temp, dif[i][j - 1] + 1,
dif[i - 1][j] + 1);
}
}
System.out.println("字符串""+str1+""与""+str2+""的比较");
//取数组右下角的值,同样不同位置代表不同字符串的比较
System.out.println("差异步骤:"+dif[len1][len2]);
//计算相似度
float similarity =1 - (float) dif[len1][len2] / Math.max(str1.length(), str2.length());
System.out.println("相似度:"+similarity);
}
//得到最小值
private static int min(int... is) {
int min = Integer.MAX_VALUE;
for (int i : is) {
if (min > i) {
min = i;
}
}
return min;
}
}
5.举例
首先在连续相等的字符就可以考虑到
红色是取值的顺序。
1.今天周一 天周一
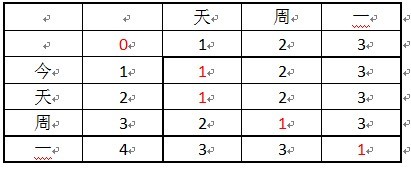
实现是去掉“今”,一步完成。
2.听说马上就要放假了 你听说要放假了

这两个字符串是:
去掉“你”,加上“马上就”,总共四步操作。
6. 得到匹配结果
我们往往不仅仅是计算出字符串A和字符串B的编辑距离,还要能得出他们的匹配结果。
以例A=GGATCGA,B=GAATTCAGTTA,LD(A,B)=5
他们的匹配为:
A:GGA_TC_G__A
B:GAATTCAGTTA
如上面所示,蓝色表示完全匹配,黑色表示编辑操作,_表示插入字符或者是删除字符操作。如上面所示,黑色字符有5个,表示编辑距离为5。
利用LD矩阵,通过回溯,能找到匹配字串
第一步:定位在矩阵的右下角
| LD算法矩阵 | ||||||||||||
|
| b | G | A | A | T | T | C | A | G | T | T | A |
| a | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| G | 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| G | 2 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 6 | 7 | 8 | 9 |
| A | 3 | 2 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 8 |
| T | 4 | 3 | 2 | 2 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| C | 5 | 4 | 3 | 3 | 2 | 2 | 2 | 3 | 4 | 5 | 6 | 7 |
| G | 6 | 5 | 4 | 4 | 3 | 3 | 3 | 3 | 3 | 4 | 5 | 6 |
| A | 7 | 6 | 5 | 4 | 4 | 4 | 4 | 3 | 4 | 4 | 5 | 5 |
第二步:回溯单元格,至矩阵的左上角
若ai=bj,则回溯到左上角单元格
| LD算法矩阵 | ||||||||||||
|
| b | G | A | A | T | T | C | A | G | T | T | A |
| a | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| G | 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| G | 2 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 6 | 7 | 8 | 9 |
| A | 3 | 2 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 8 |
| T | 4 | 3 | 2 | 2 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| C | 5 | 4 | 3 | 3 | 2 | 2 | 2 | 3 | 4 | 5 | 6 | 7 |
| G | 6 | 5 | 4 | 4 | 3 | 3 | 3 | 3 | 3 | 4 | 5 | 6 |
| A | 7 | 6 | 5 | 4 | 4 | 4 | 4 | 3 | 4 | 4 | 5 | 5 |
若ai≠bj,回溯到左上角、上边、左边中值最小的单元格,若有相同最小值的单元格,优先级按照左上角、上边、左边的顺序
| LD算法矩阵 | ||||||||||||
|
| b | G | A | A | T | T | C | A | G | T | T | A |
| a | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| G | 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| G | 2 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 6 | 7 | 8 | 9 |
| A | 3 | 2 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 8 |
| T | 4 | 3 | 2 | 2 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| C | 5 | 4 | 3 | 3 | 2 | 2 | 2 | 3 | 4 | 5 | 6 | 7 |
| G | 6 | 5 | 4 | 4 | 3 | 3 | 3 | 3 | 3 | 4 | 5 | 6 |
| A | 7 | 6 | 5 | 4 | 4 | 4 | 4 | 3 | 4 | 4 | 5 | 5 |
若当前单元格是在矩阵的第一行,则回溯至左边的单元格
若当前单元格是在矩阵的第一列,则回溯至上边的单元格
| LD算法矩阵 | ||||||||||||
|
| b | G | A | A | T | T | C | A | G | T | T | A |
| a | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| G | 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| G | 2 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 6 | 7 | 8 | 9 |
| A | 3 | 2 | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 8 |
| T | 4 | 3 | 2 | 2 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| C | 5 | 4 | 3 | 3 | 2 | 2 | 2 | 3 | 4 | 5 | 6 | 7 |
| G | 6 | 5 | 4 | 4 | 3 | 3 | 3 | 3 | 3 | 4 | 5 | 6 |
| A | 7 | 6 | 5 | 4 | 4 | 4 | 4 | 3 | 4 | 4 | 5 | 5 |
依照上面的回溯法则,回溯到矩阵的左上角
第三步:根据回溯路径,写出匹配字串
若回溯到左上角单元格,将ai添加到匹配字串A,将bj添加到匹配字串B
若回溯到上边单元格,将ai添加到匹配字串A,将_添加到匹配字串B
若回溯到左边单元格,将_添加到匹配字串A,将bj添加到匹配字串B
搜索晚整个匹配路径,匹配字串也就完成了
从上面可以看出,LD算法在不需要计算出匹配字串的话,时间复杂度为O(MN),空间复杂度经优化后为O(M)
不过,如果要计算匹配字符串的话,时间复杂度为O(MN),空间复杂度由于需要利用LD矩阵计算匹配路径,故空间复杂度仍然为O(MN)。这个在两个字符串都比较短小的情况下,能获得不错的性能。不过,如果字符串比较长的情况下,就需要极大的空间存放矩阵。例如:两个字符串都是20000字符,则LD矩阵的大小为20000*20000*2=800000000Byte=800MB。呵呵,这是什么概念?
参考
戴正华《串匹配算法》
http://www.cnitblog.com/ictfly/archive/2005/12/27/5828.aspx
http://www.cnblogs.com/grenet/category/287355.html
最后
以上就是呆萌西牛最近收集整理的关于字符串相似度算法 -- levenshtein distance 编辑距离算法 的全部内容,更多相关字符串相似度算法内容请搜索靠谱客的其他文章。








发表评论 取消回复