Kafka是一种高吞吐量的分布式发布订阅的消息队列系统,Kafka对消息进行保存时是通过tipic进行分组的。今天我们仅实现Kafka集群的配置。理论的抽空在聊前言
- 最近研究kafka,发现网上很多关于kafka的介绍都是基于Linux操作系统的。虽然这些服务最后都是配置Linux上的。但是我们平时使用的大多都是Windows系统。所以研究很是吃力。经过借鉴不同的网络文章终于在Windows上实现了kafka的配置。在这里现在的配置是基于Zookeeper 3.4.6 版本的。如果读者在操作希望能和我的版本保持一致。
zookeeper
了解kafka的都知道。kafka是通过Zookeeper实现分布操作的。不管是broker,consumer,还是provide信息都是存储在Zookeeper中的。当broker挂掉都是Zookeeper来进行重新分配选择的。所以实现kafka集群前我们得先实现Zookeeper的集群配置。
首先我们从官网上下载Zookeeper到本地。我这里下载的是Zookeeper-3.4.6.tar.gz版本的。读者可以根据自己情况下载。下载好之后进行文件解压。然后找到conf文件中的zoo_sample.cfg文件。该文件是Zookeeper官网给我们提供的一套样板。我们赋值该文件到同级下并改名为zoo.cfg.如下图
修改配置文件
然后我们来看看这个配置文件里面都有些啥
tickTime=2000- 服务器之间或客户端与服务端之间维持心跳的时间。就是每隔tickTime就会发送一次心跳。单位毫秒
initLimit=10- 这个是配置Zookeeper接收客户端初始化连接最长能忍受initLimit心跳时间间隔。
syncLimit=5- Leader与follow之间发送消息和应答的时间 总时间=syncLimit*tickTime
dataDir- zookeeper数据保持路径 默认将log日志也保存在dataDir
dataLogDir- zookeeper log日志保存地址 不设置默认是dataDir
clientPort=2181- 客户端连接的端口
server.1=192.168.1.130:28881:38881
server.2=192.168.1.130:28882:38882
server.3=192.168.1.130:28883:38883- 因为我的集群都是在同一台电脑上配置的,所以这里端口不能一样
知道配置文件里的意思应该就知道如何修改了吧
- 对于新手我们只需要该以下地方呢。
dataDir+dataLogDir+clientPort- 但是下面的server是Zookeeper配置里需要重点讲解的部分
上面的格式我们可以简单的总结为 server.num=B:C:D。
num:是正整数代表的服务的唯一标识。这个要和后面说道的myid文件保持一致。
B: 标识Zookeeper集群中某一个服务的ip或者域名 192.168.1.130
C:表示server.num这个服务于集群中leader进行信息交流的端口。在kafka中我们leader和follower需要进行数据备份。具体服务就是通过这个地方制定的端口进行通信的。
D:表示万一leader宕机了,我们就通过这个端口来进行再follower中选举新的leader。
大坑预防
网上的很多教程也就介绍到这里。稍微好点就提了一下创建myid文件的事,我当时就纠结在这里。因为我根本不知道穿件的myid的类型。我就随便创建txt文件。结果是错的。这里我们创建myid我有两种方式。还有myid里面的内容就是我们对应的配置文件中server.num中的num。
第一种就是我们通过cmd窗口到我们要创建myid的文件夹下
执行如下命令
echo 1 > myid
第二种是我们先创建TXT文件将对应的内容写入。然后txt后缀删掉就可以了。
顺便提一下myid应该放在我们conf/zoo.cfg文件中指定的dataDir 的对应的文件路径下。
服务开启
所谓的集群就是讲上面的Zookeeper复制成多个,将上面提到的几个重要的属性更改掉就行了。
如果你到这一步说明你离成功已经不远了。下面我们只需要开启服务就行了。开启服务在我们解压的bin目录下。
- 这里我们得有些常识,已sh结尾的是Linux 系统的shell文件。在windows上没有装插件是无法使用的。我们windows认识的就是bat文件。就是上面的cmd结尾才是我们可以用的功能。但是我们还需要进行一下修改。其实这里已经可以了。我们到cmd窗口中通过该命令去执行我们zoo.cfg文件。但是为了方便我们这里讲zoo.cfg配置进我们的zkServer.cmd文件中
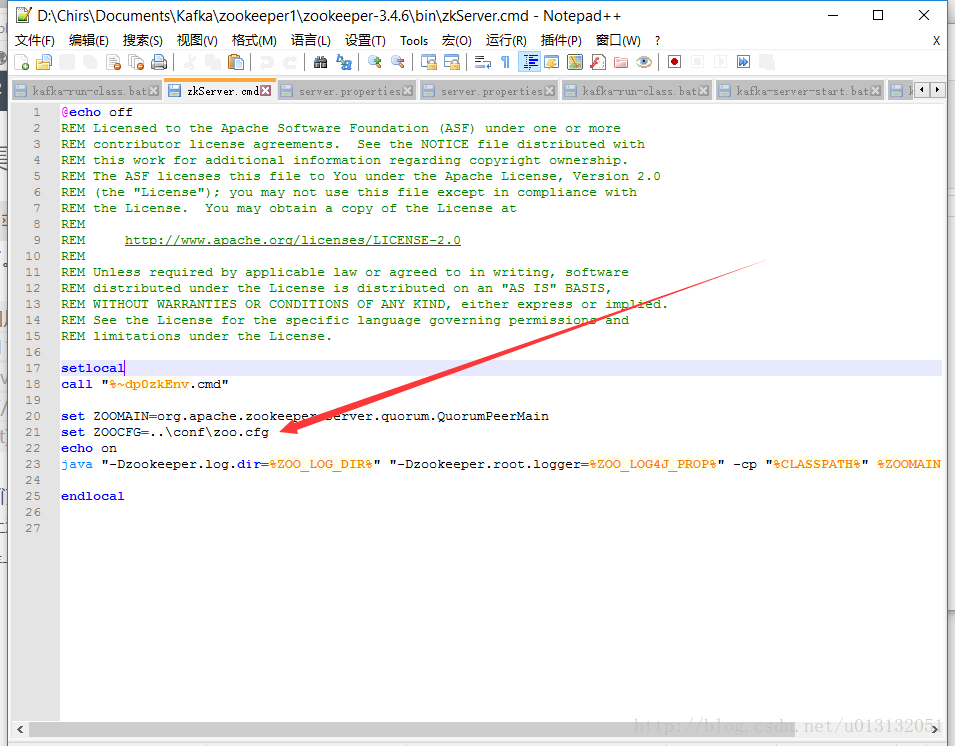
- 好了。配置完成。我们只需要每次点击zkServer.cmd就开启了Zookeeper中的服务了。
友情提醒
上面我们配置的Zookeeper在开启第一个时候回报错。为什么呢。原因就是我们开启了一个服务,。但是我们的配置文件配置的是集群的信息。这个时候就回去寻找其他服务。但是这个时候其他的服务还没有开启呢。所以这个错误是正常。等我们集群中的所有的服务都开启了就不会报错。这里大家不要被吓到。
除此之外,还有一点就是Zookeeper的安装目录(解压目录)是绝对不能包含汉字的。我上面的截图有汉字那是我计算机上设置的。实际的路径是没有汉字的。不要被上面的图片诱导。
当所有的服务都开启了,我们如何查看我们的服务是否开启成功呢。这很简单。我们重新打开一个新的cmd窗口。直接执行jps就可以看到我们的服务了。QuorumPeerMain就是我们的服务主类

Kafka集群配置
- 上面我们就完成了Zookeeper的集群的配置。实际上Kafka中就自带有Zookeeper的服务。但是为了数据的高可用性。我们最好选择自己搭建Zookeeper集群。这也是官网上的建议。
这里我的Kafka版本选择的是0.8.1.1。建议单价不要选择太高的版本。刚出的版本可能有未知的bug。
同样这里的集群就是讲Kafka复制多个。这里我选择其中一个进行讲解。其他的都是一样的主要就是讲端口改掉就行了。
将官网下载的Kafka解压改名为kafka1(其他的改名数字递增就行。或者自定义别的名字)。找到config/server.properties文件。
server.properties修改
同样的先来了解里面的参数含义吧
broker.id=1- 在kafka这个集群中的唯一标识,且只能是正整数
port=9091- 该服务监听的端口
host.name=192.168.1.130- broker 绑定的主机名称(IP) 如果不设置将绑定所有的接口。
advertised.host.name=192.168.1.130- broker服务将通知消费者和生产者 换言之,就是消费者和生产者就是通过这个主机(IP)来进行通信的。如果没有设置就默认采用host.name。
num.network.threads=2- broker处理消息的最大线程数,一般情况是CPU的核数
num.io.threads=8- broker处理IO的线程数 一般是num.network.threads的两倍
socket.send.buffer.bytes=1048576- socket发送的缓冲区。socket调优参数SO_SNDBUFF
socket.receive.buffer.bytes=1048576- socket接收的缓冲区 socket的调优参数SO_RCVBUF
socket.request.max.bytes=104857600- socket请求的最大数量,防止serverOOM。
log.dirs=logs- kafka数据的存放地址,多个地址的话用逗号隔开。多个目录分布在不同的磁盘上可以提高读写性能
num.partitions=2- 每个tipic的默认分区个数,在创建topic时可以重新制定
log.retention.hours=168- 数据文件的保留时间 log.retention.minutes也是一个道理。
log.segment.bytes=536870912- topic中的最大文件的大小 -1表示没有文件大小限制 log.segment.bytes 和log.retention.minutes 任意一个
达到要求 都会删除该文件 在创建topic时可以重新制定。若没有.则选取该默认值
log.retention.check.interval.ms=60000- 文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略
log.cleaner.enable=false- 是否开启日志清理
zookeeper.connect=192.168.1.130:num1,192.168.1.130:num2,192.168.1.130:num3- 上面我们的Zookeeper集群
zookeeper.connection.timeout.ms=1000000- 进群链接时间超时
- 同样的我们每次赋值kafka服务我们只需该配置文件里的下面两个属性就行了。
broker.id + port服务启动前的命令准备
同样的我们观察bin目录中我们会发现Kafka针对Linux和windows提供了不同的组件。windows的组件放在了windows的文件夹下了。但是我在实际操作中无法使用里面的命令。报一些错误。这里我的解决办法是将windows里的bat全部复制到外面。就是复制到bin目录下。
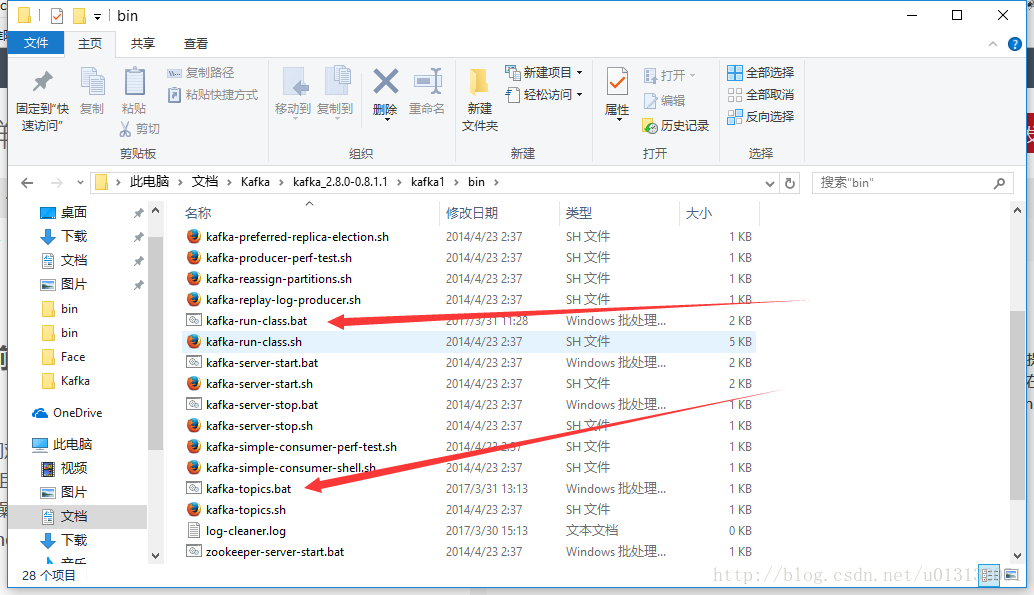
上图中指出来的bat原本是在windows文件中。拷贝到bin目录之后我们需要修改一下kafka-run-class.bat文件。因为里面写的相对路径和引入的jar会导致出错。所以我们将里面的这段代码
set ivyPath=%USERPROFILE%.ivy2cache
set snappy=%ivyPath%/org.xerial.snappy/snappy-java/bundles/snappy-java-1.0.5.jar
call :concat %snappy%
set library=%ivyPath%/org.scala-lang/scala-library/jars/scala-library-2.8.0.jar
call :concat %library%
set compiler=%ivyPath%/org.scala-lang/scala-compiler/jars/scala-compiler-2.8.0.jar
call :concat %compiler%
set log4j=%ivyPath%/log4j/log4j/jars/log4j-1.2.15.jar
call :concat %log4j%
set slf=%ivyPath%/org.slf4j/slf4j-api/jars/slf4j-api-1.6.4.jar
call :concat %slf%
set zookeeper=%ivyPath%/org.apache.zookeeper/zookeeper/jars/zookeeper-3.3.4.jar
call :concat %zookeeper%
set jopt=%ivyPath%/net.sf.jopt-simple/jopt-simple/jars/jopt-simple-3.2.jar
call :concat %jopt%
for %%i in (%BASE_DIR%coretargetscala-2.8.0*.jar) do (
call :concat %%i
)
for %%i in (%BASE_DIR%corelib*.jar) do (
call :concat %%i
)
for %%i in (%BASE_DIR%perftargetscala-2.8.0/kafka*.jar) do (
call :concat %%i
) - 替换成
for %%i in (%BASE_DIR%libs*.jar) do (
call :concat %%i
) - 我们仔细观察原来的配置大概意思是引入一些jar包啥的。但是会出现有的时候我们的文件根本没有那个jar。但是又引入了。会经常报错。所以我们改成引入libs下的所有jar.有啥就引入啥。这样就不会报错的。
大坑预防
- 到这里我原本天真的认为就已经完事了。但是谁知我按照网上的教程继续的时候就出现如下错误
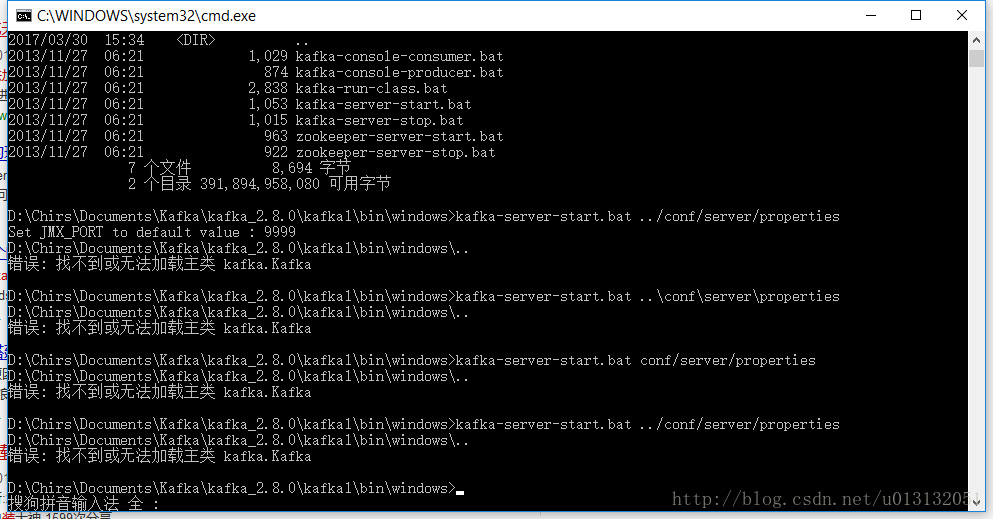
首先第一行提示 set JMX_PORT to default value 9999 这个错误是因为我没有设置这个值。这倒是小事。但是后面报说找不到或无法加载主类kafka.Kafka这就让我费解。在这里我也是卡了一天了。后来在网上找到了一个方法。我不知道这是不是Kafka的bug。反正用这个方法我是解决了这个错误了。
- 解决办法就是将kafka-run-class.bat文件中
set COMMAND= %JAVA% %KAFKA_OPTS% %KAFKA_JMX_OPTS% -cp %CLASSPATH% %*- 修改为
set COMMAND= %JAVA% %KAFKA_OPTS% %KAFKA_JMX_OPTS% -cp "%CLASSPATH%" %*- 对比我们发现就是将classpath加上双引号。搞了半天就是系统变量路径没有找到的原因。不过这个问题值得引起我们的注意。我们的kafka寄去你的搭建实在Java 的jdk基础是搭建的。所以前提我们得将jdk等这些配置到环境变量中去。这里的配置网上搜去吧很多。
服务开启
到这一步我们离kafka的成功又不远了。我们新开cmd窗口cd到kafka的bin目录中。
但是在执行开启之前我们需要先执行
Set JMX_PORT=19091(每个服务数字不能一样)- 然后在执行
kafka-server-start.bat ..configserver.properties创建Topic批处理
- 官网上是没有提供windows版本的topic处理程序的。我们需要自己新建一个bat文件。这个bat文件的内容填写如下
kafka-run-class.bat kafka.admin.TopicCommand %* 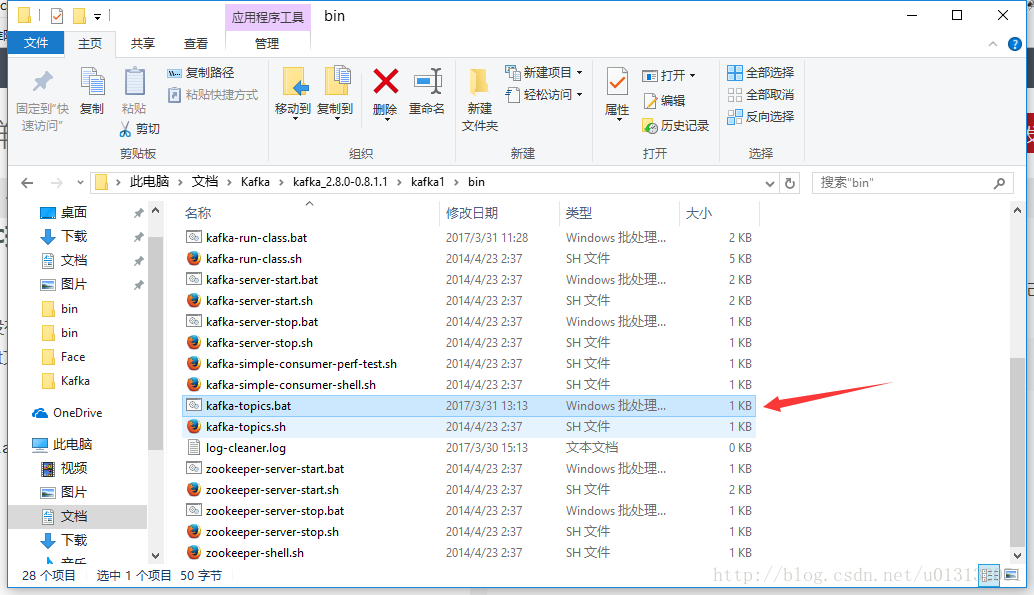
消息处理
- 有了这个批处理我们就可以通过它实现topic的创建。生产者发送消息和消费者的接收消息
创建Topic
- replication-factor:表示该topic需要在不同的broker中保存
- partitions : 对该top的分区数量
- topic : 该top的名称。建议指定。否则采用默认
kafka-topics.bat --create --zookeeper 192.168.1.130:2181 --replication-factor 2 --partitions 3 --topic my-replicated-topic 查看Topic
kafka-topics.bat --describe --zookeeper 192.168.1.130:2181 --topic my-replicated-topic生产topic消息
kafka-console-producer.bat --broker-list 192.168.1.130:9093 --topic my-replicated-topic消费topic消息
kafka-console-consumer.bat --zookeeper 192.168.1.130:2181 --from-beginning --topic my-replicated-topic- 最后在接收发送消息是我们需要重新创建新的cmd窗口。下面看看效果图。最终实现实时接收消息
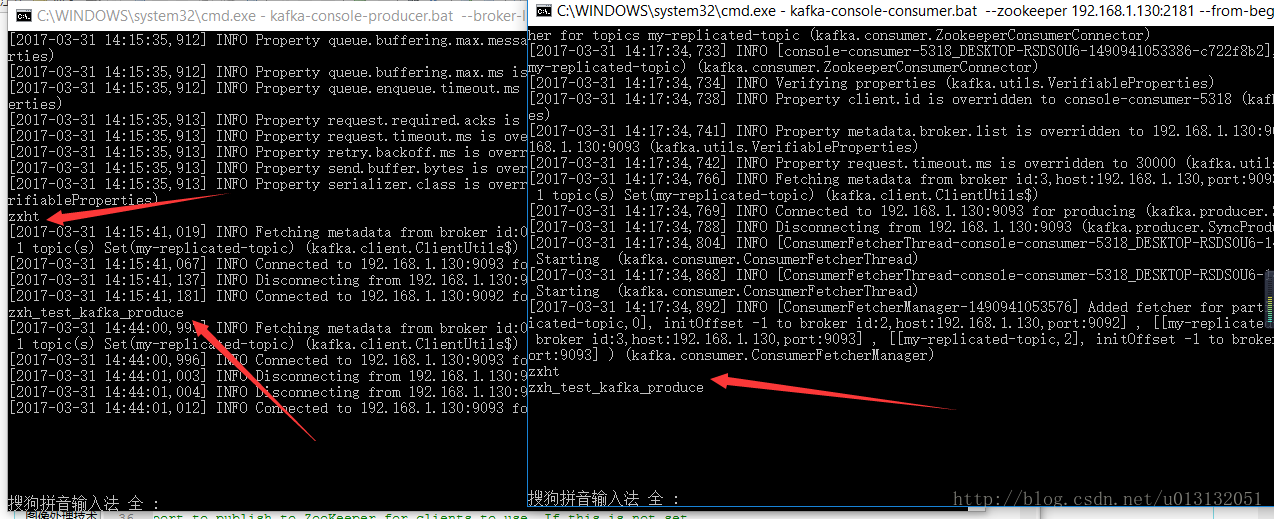
资源由于大小限制暂时无法上传!后续再上传
最后
以上就是凶狠水壶最近收集整理的关于Kafka集群配置---Windows版zookeeper服务开启友情提醒Kafka集群配置的全部内容,更多相关Kafka集群配置---Windows版zookeeper服务开启友情提醒Kafka集群配置内容请搜索靠谱客的其他文章。








发表评论 取消回复