今天主要学tf2和动手实践;如果有时间,看下Transformer系列的细节!!加油!
一、环境配置
老师很贴心,带着装环境。
1、我建个github仓库~
2、设置了一个conda的默认清华镜像
参考链接:
https://blog.csdn.net/CV_YOU/article/details/83098414
3、环境配置
python3.7
二、chap1
装环境的时候看看课程
(一)、1.1三学派
1、三类
(1)行为主义
感知-动作控制系统???机器人单脚站立,感知方向,控制动作,保持平衡
(2)符号主义
公式
(3)连接主义
连接感知
2、步骤
准备数据;
搭建网络;
优化参数:训练,反向传播
应用网络:保存模型,进行前传预测

(二)1.2神经网络设计过程
1、鸢尾花种植者并不需要严格的if判断(逻辑判断),而是通过感知,也就是我们可以用神经网络模拟的东西。
2、基础概念
损失函数-SME均方误差
优化参数=梯度下降+反向传播
3、跑代码【c1-c13】
测试不同的学习率情况
过小:很慢
过大:摇摆,找不到最优值
(三)1.3张量生成
1、什么是张量?
0维数组-数字
1-向量
2-矩阵
±张量
2、数据类型
tf.int, tf.float,tf.bool,tf.string
3、如何用tf创建张量?
tf.cosntant(张量内容,dtype =数据类型)
例如:
a = tf.constant([1,5],tf.int64)
ps:
通过a.shape可以查看形状,有几个点,就是几维张量
4、如何将numpy转换为tf的数据类型?
tf.convert_to_numpy(数据名,dtype=)
例子:
c1p18
5、自己创建张量
tf.zeros(维度)
tf.ones(dim)
tf.fill(dim,value)
括号中:
一维:个数
二维:[行,列]
多维:[n,m,j,k…]
6、如何初始化参数呢?
正态分布随机数
tf.random.normal(dim,mean,stddev=标准差)
tf.random.truncated_normal(dim,mean,stddev=)
均匀分布随机数—左闭右开
tf.random.uniform(dim,minval=,maxval)
1.4TF2常用函数
1、axis如何理解呢?0代表什么?
0是指第一维度;
一般0是纵向;1是横向
2、如何标记带训练参数?
tf.Variable(初始值)
例如:
w = tf.Variable(tf.random.normal([2,2],mean=0.stddev=1))
3、加减乘除函数
tf.add( , )
tf.substract(,)
tf.multiply(,)对应相乘,不是矩阵乘法哦
tf.divide(,)
只有维度相同才可以做四则运算,就是要一个对应一个
4、平方、次方、开方函数?
tf.square( 张量)
tf.pow(张量,n次方)
tf.sqrt(张量)
5、矩阵乘法函数?
tf.matmul(矩阵1,矩阵2)
都说明了是矩阵的乘法哦
ps:在用tf定义张量时,【】里面有几个数就是几维,数的大小对应该维度数的个数。
但是用shape查看形状时,逗号个数和维度是对应的;
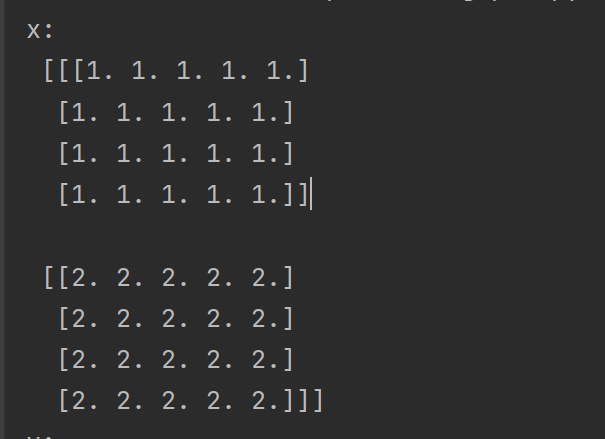
用print时,'[[[['个数和维度对应,比如像左边四个‘['代表四维。
------------现在时8:55,刚刚去了下校医院看膝盖,前两天跑步跑伤了,排号的时候,把chap1看完了,总结一下,可以开始看代码了。
把最后项目的代码,看着注释敲一下,然后最后要到没有注释自己心中有框架的地步。
1.5常用函数1
1、求导的函数?
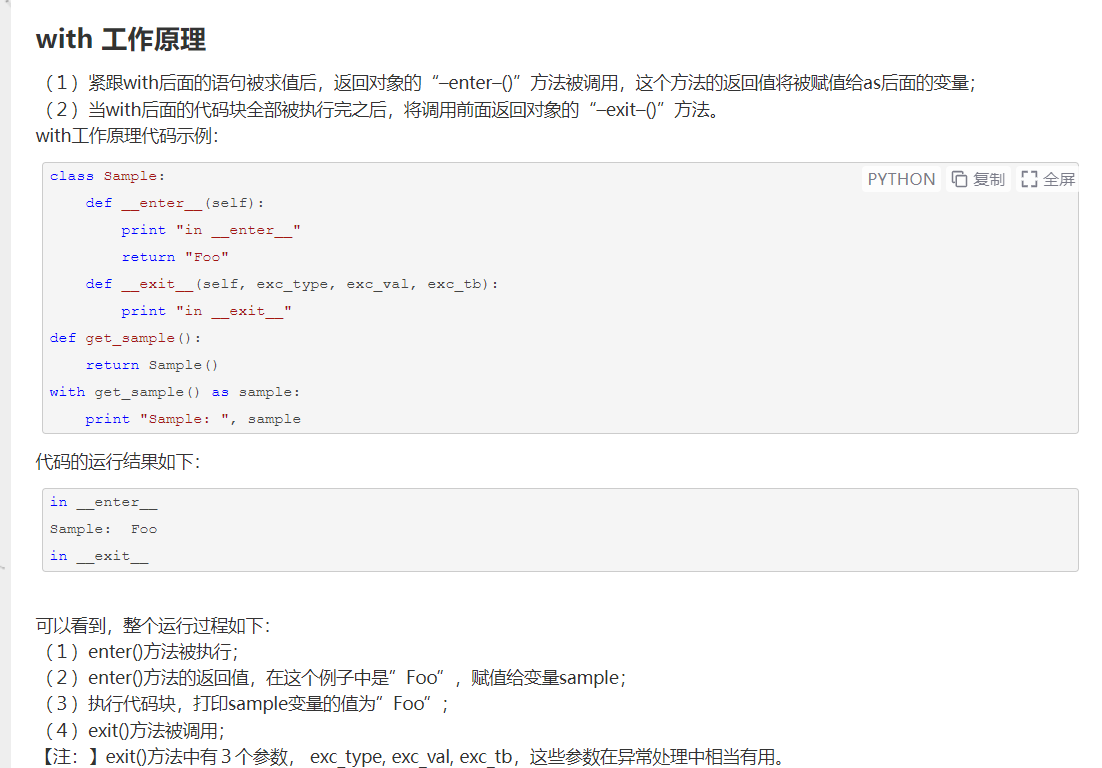
这里用了一个with结构,需要查一下用法
【查的时候突然想起来给师弟看gitee上代码问题,发现之前传错了,弄到了9:26】
with应该是避免异常的:
而使用with的话,能够减少冗长,还能自动处理上下文环境产生的异常。
https://www.cnblogs.com/sddai/p/14411906.html
比较清楚了
https://blog.csdn.net/youzhouliu/article/details/80976004?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.pc_relevant_default&utm_relevant_index=1
wtih tf.GradientType() as tape:
若干计算过程
grad = tape.gradient(函数,对谁求导)
2、如何枚举?
这其实是python内建函数 for i,ele in enumerate(…)
3、如何设置独热编码
tf.one_hot(带转换数据,depth=几分类)
4、softmax函数如何写?作用?
作用:使输出符合概率分布
tf.nn.softmax(x)
5、参数自更新函数作用?如何写?
求导后进行自更新;
assign_sub
6、argmax作用?
tf.argmax(张量名,axis=操作轴)
0纵向;1横向
自己跑前面的代码
1、normal是正太分布;uniform是均匀分布
2、在tf中定义数据类型的时候要加上tf
3、合并特征与标签
tf.data.Dataset.from_tensor_slices
4、定义常量要加.
现在11:07,把class1中除了最后的大作业都加了代码提问注释,并且“回答”。先去吃饭,吃完饭继续写大作业!!!

----------现在是12:47,刚才吃饭+走路+饭后站着消食的时候把class2看完了,感慨万分!老师甚至把深度学习的一些基础知识讲的太好了!!!比如说,激活函数、损失函数、优化器(如何利用导数进行反向传播优化)、指数衰减学习率之类的,下午具体说。此外,老师讲代码的思路也很清晰!感谢知识开源!!!爱了!听这种课就是享受!
我现在桌子上趴一会,然后起来自己实现class1最后一个代码和class2的所有代码。
------13:17趴了一会,做了一个已经忘了的梦!!!趴一会真的很清醒!!!现在来敲代码!!!!!!!!先敲chap1最后一个,再回顾chap2,再敲chap2
chap1终极boss代码
1、错误1


 这里原来打错了,打成x_data,导致维度不匹配。x_test是150;y_test是30
这里原来打错了,打成x_data,导致维度不匹配。x_test是150;y_test是30

2、错误2
在计算正确率的时候,并未将correct reduce_sum,导致总是在第一轮训练的时候报错提前结束。
3、通过写底层的代码:
(1)对batch有更深入的理解
batch=32,也就意味着每次32个y一起算loss。batch不同,还是有影响的。
每epoch的每个batch都是直接投32个数据。
(2)plt中的legend就是图注,最好不要写中文的标题。。显示不出来
4、这里之所以写axis=1

是因为行数据是这样的,我想要每行,也就是横向数据中最大的索引
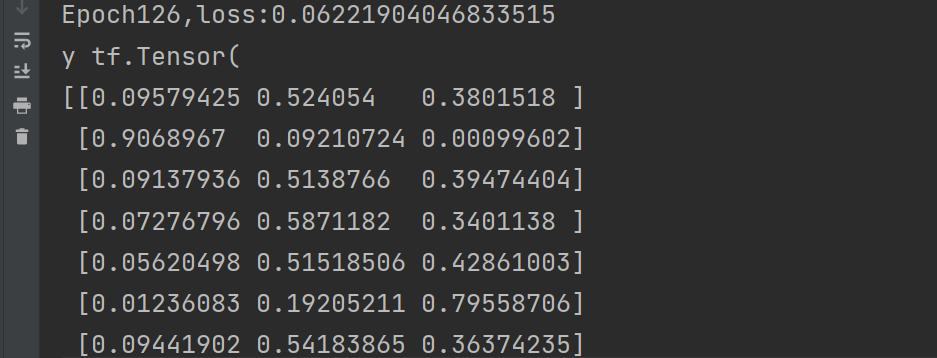
5、最后可视化是每一epoch都可视化
画的是train的loss和test的acc
-----现在14:33了,自己敲完一遍,感觉收获很多,但是还是没有完全掌握,先commit一下。接下来看下class3,然后敲class2的代码
chap2
1、预备知识(后续会用到)
(1)tf.where(条件语句,A,B)

(2)返回[0,1)之间的随机数
np.random.RandomState.rand(维度)
可以通过
rdm = np.random.RandomState(seed=1)实例化一个钟字为1的rdm
然后用a = rdm.rand()生成一个随机标量,未传参数就代表是标量
b = rdm.ran(2,3)2*3随机矩阵,数值大小在[0,1)
(3)如何将两个数组按照竖直方向叠加
np.vstack()
叠加完,一维变成二维

(4)下面的三个理解不深入,用到的时候再说
关于np.mgrid()用法的小实验
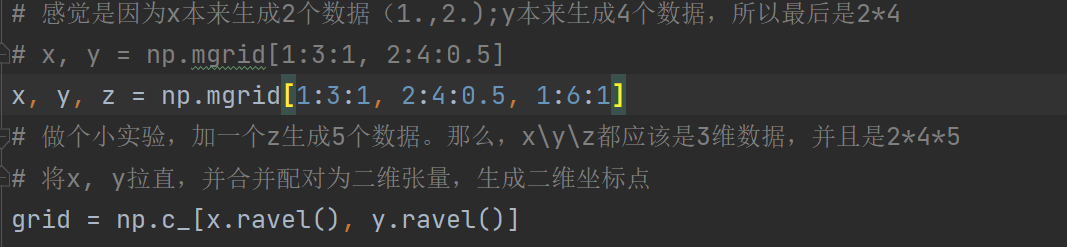
所以,np.mgrid[]里面有几组,就会生成几位数据。
(5).x.ravel()
(6)np._c[]返回间隔数值点之间的配对
2、神经网络复杂度(掠过)
略
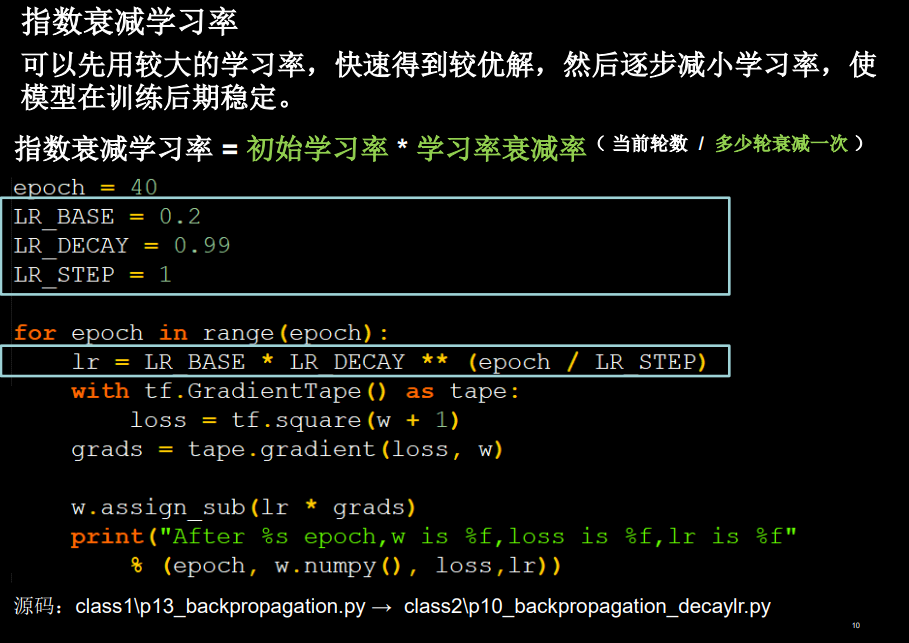
3、指数衰减学习率(讲的很好)
lr过大容易造成忽悠忽悠的,老是错过最好的值;
过小会导致太慢;
so,先大一点,找到很好的区域,然后再精调
这个就是指数衰减学习率
超参数为
(1)初始学习率
(2)学习率衰减率
(3)多少轮衰减一次
变量为轮数
也就是说,我们可以设置一个最初的速度,然后设置一个减慢一次的速度,然后设置一下多久根据这个减慢的速度见一次。当然,由于是指数形式,所以随着轮数增大,衰减速度也就也来越小,那么学习率减小的速度也会越来越小,实现精细地调试/
这里的多少论跳一次也不是多少论衰减一次,其实每一轮都在衰减,随着轮数的增大;只不过“多少论衰减一次”这个参数可以近似看作是这个效果罢了。
4、激活函数(特点清晰)
(1)优秀的激活函数
a、非线性:多层后,可逼近所有函数【哭了,好清晰,刚学的时候,完全不理解】
b、可微性:梯度下降
c、单调性:保证单层网络的损失函数是凸函数(凸函数我记得就是有最大值那种吧,好优化)
参考
:https://www.zhihu.com/question/22125449
d、近似恒等性
第一次听说,这个意思就是f(x)=x,比如Relu,这样的好处是,初始化为随机小值时,神经网络稳定。

关于激活函数输出值的范围这点,不太理解
有限值,就像sigmoid,tanh;
无限,就像Relu?为啥要调校学习率呢?

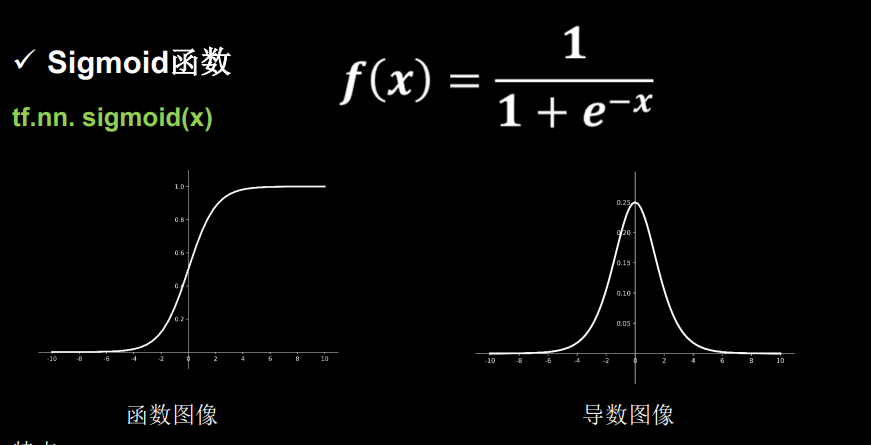
(2)sigmoid
a导数在0-0.25,多层网络,容易梯度消失
b输出均值非0均值,全为整的哦,0-1;但为啥会收敛慢呢
c函数有幂运算,比较复杂,训练时间长
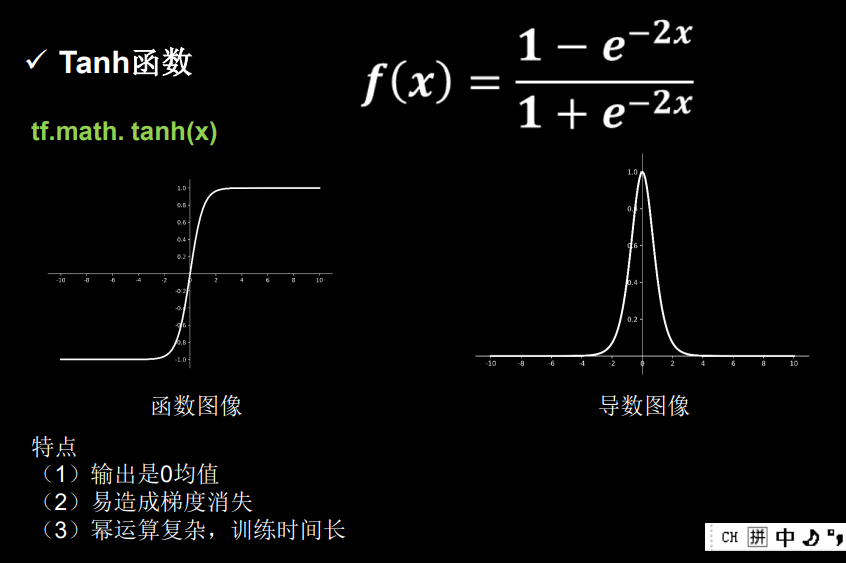
(3)Tanh
a输出是0均值,解决了sigmoid收敛慢的问题
b导数是0-1,仍旧有梯度消失的问题
c还有幂运算,训练时间长
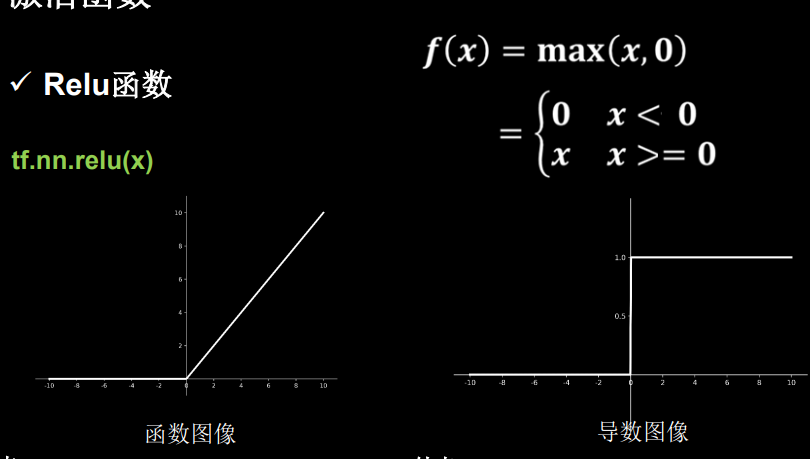
(4)Relu
pros:
a正区间内,解决梯度消失
b函数只需判断是否大于0,没有幂运算,快
c收敛速度快,为啥快呀?
cons:
a输出为非0均值,收敛慢
bDead ReLu问题(应该是负数部分求导为0吧)
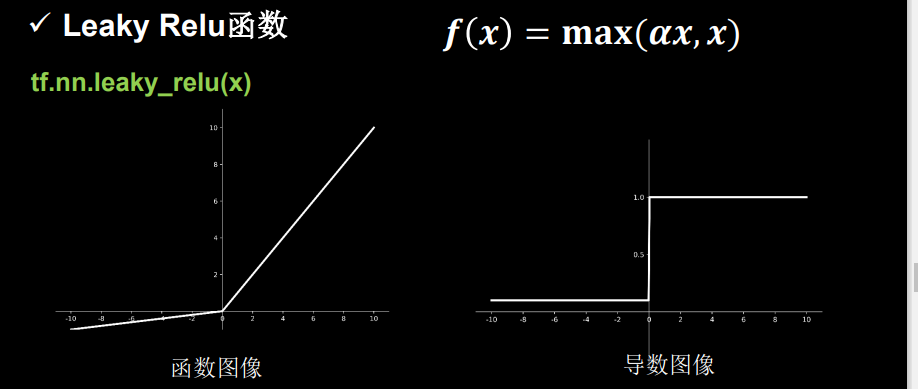
(5)Leaky Relu
xswl继承了Relu的优点,解决了Dead ReLu的问题。
但

(6)初学者选择建议
首选relu
学习率设小点
特征要标准函,0均值,1为标准差,正态分布(为啥)
莫大大的文章的意思是把数据的归一化,避免单位不同造成的偏差
https://zhuanlan.zhihu.com/p/24839177
这篇更加“复杂”一点,但更详细客观,有时间看把
https://www.cnblogs.com/shine-lee/p/11779514.html
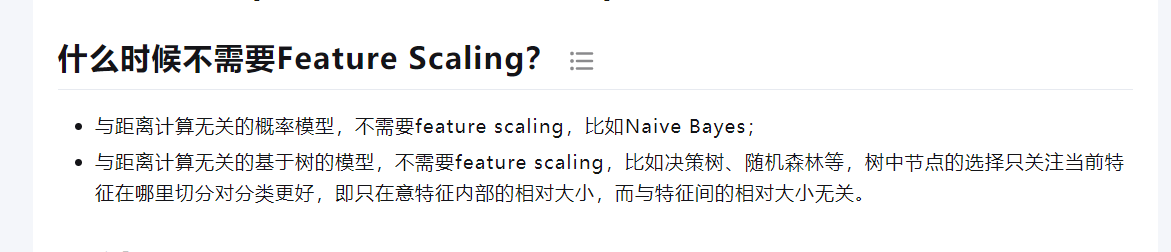
获取无关性

不需要scaling的模型
与距离计算无关----朴素贝叶斯;树模型
初始参数中心化
5、损失函数(非常清晰!尤其是MSE和交叉熵的对比)
**NN优化目标:loss最小!!!**虽然大家应该都知道,但我觉得很重要,标出来!
(1)mse
字面理解好吧
(2)自定义
更加灵活。看一种自定义的方式,用到了前面提到的预备知识,所以这个讲义很妙!成本和利润的损失系数不同,通过比较大小,来确定是成本还是利用。所以这个where和greater结合,可以很好地表达分段函数。

(3)ce
表征两个概率分布之间的距离,越小越近
这句话经典了!!!!!
鹅鹅鹅tf里还有softmax和交叉熵结合的一键到家服务

6、欠拟合和过拟合(可以随便看看,写了解决方式)
不理解为什么过拟合可以通过数据清洗解决?
粗略搜索,没找到答案。。。。直接问下同学吧
看到底下关于正则化缓解过拟合的解释里提到噪声,我猜想是不是,噪声过多会导致拟合的过于复杂,所以清理数据有用;底层原理和正则化,给w加权值(减小其作用),弱化数据作用,减少噪声影响的一样

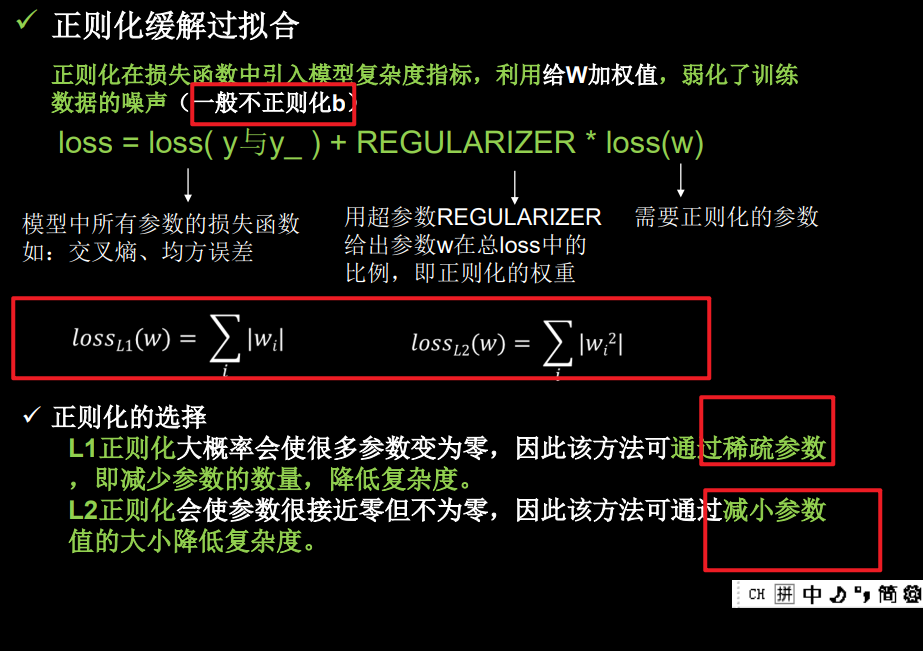
7、正则化减少过拟合(讲清了L1和L2的区别)
我猜,不正则化b是因为b不影响噪声吧
l1和l2的公式在底下,特点也列出来了:
l1会减少参数,因为很多参数会为0;
l2会减小参数。
但是我不能通过他们的数学表达式,联想到为什么。
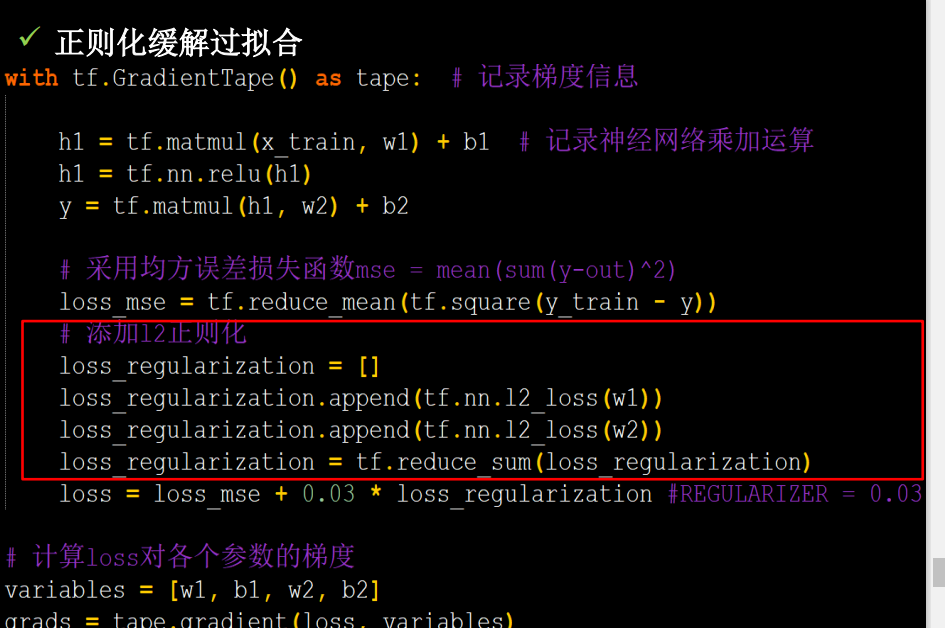
甚至还有代码,就随便看看吧
因为后面六步法肯恶搞不太需要,而且底下的优化器更精彩!
这里他主要是用代码写了一下如何写正则化,其实就一条命令tf.nn.l2_loss(w1)的事情,把需要正则化的 参数传进去
8、优化器更新网络参数(加强了我对优化器的理解,很有用强推!!!但是特点方面感觉没有吴恩达讲的好,吴恩达讲了啥我也忘了。。。)
简而言之,我对于优化器的理解:
反向传播+梯度下降理论确实可以对目标函数进行优化。但是梯度具体如何下降,就由优化器来解决了~~
优化器有点像教书的老师,水平特点也不太一样,所以对于同一个孩子,往同一个方向教书(比如高考向),但是效果可能不一样。具体还是取决于孩子和老师是不是投缘啊。
所谓动量,我的理解就是,之前的力量,也就是借助之前的信息。一阶动量就是一次方的之前信息,二阶就是二次方。SGF没有用动量;SGDM用来一阶动量(指数平滑);Adagrad用的二阶动量(直接求之前的平方和,用的时候再开方);RMSProp也用二阶动量(用的是平方指数平滑);Adam结合了SGDM和RMSProp,用了一阶动量和二阶动量的指数平滑,并且做了修正。不过为什么要写成m/根号v,我还不太理解
(1)SGD
简单常用
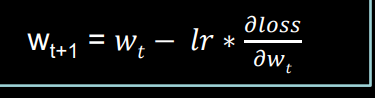
(2)SGDM
在sgd基础上加入momentum一阶动量
mt就是gt的指数平均,也就是之前梯度的平均值。
二阶动量Vt为1,也就是不设置
β为学习率,越大越偏向之前的,一般偏向1?
(记得听了一耳朵,经验值好像是0.9?)

(3)Adagrad
在SGD上加入二阶动量,也就是对于之前的一阶动量平方求和,用的时候开方

(4)RMSProp
sgd加入二阶动量;
这个和Adagrad一样也是二阶动量,只不过用的是之前一阶动量平方的指数平均。
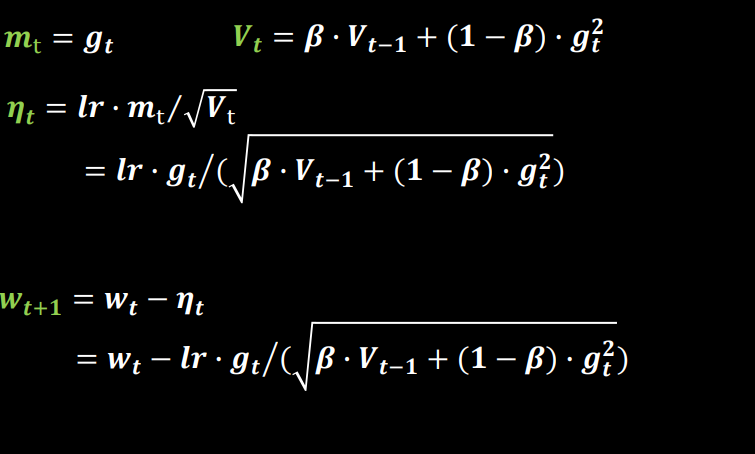
(5)Adam
Adam结合了SGDM和RMSProp,用了一阶动量和二阶动量的指数平滑,并且做了修正。阿蛋好强。!
chap3
听了3.1开始庆幸chap1.-1只写了一次,chap2还没敲。八股六步太爽了吧!
1、import
2、train,test
(引入数据集,划分数据集(也可以不划分,到下面的fit中设置。),打乱顺序,,,;总之,就是做数据的预处理,为训练做准备)
3、model = tf.keras.models.Sequential
(定义模型结构)
(还有一种class写法,好像更灵活一点)

4、model.compile(定义优化器、损失函数,metrics,主要是优化时候的事情)
优化器Adadelta前面没提过,先不查了,用的时候再说。

loss选交叉熵的话,from_logits=False说明用的不是原本神经元的输出数据,而是通过softmax归一化的数据。要和前面softmax的使用对应。

Metrcs主要说的是优化指标。
这里只提了acc,其实也可以有其他指标叭。
需要注意,不同种类的acc选择是依据y_和y的格式:都是数值,就选acc;两个one_hot选categorical_acc;y_为数值,y是one_hot选sparse_categoraical_acc

5、model.fit(进行训练,设置batch_size,epochs,测试集相关信息。主要是训练时候的设置)

6、model.summary()
打印网络结构、参数个数
7、用class定义结构
把原来第三步换一下

这个class呀,有点面向对象编程的意思。鹅鹅鹅,我还不熟悉,不过没关系啦~
大体格式:
1、继承Model
2、__init__函数里写super()…
然后在定义各种“积木”——你的网络结构块
3、call函数里拼接调用init里的积木,实现前向传播,返回y
4、最后实例化你的modle就ok

-------------------15:01,看完chap3拉~打算休息一下,回来总结chap2,总结、跟敲chap3前面的代码,最后自己做fashion数据集的作业!!!!!开心啊!感觉自己要上天了!
------------------------15:06开始写chap2重要基础理论的总结
--------------------------17:01chap2写完已经这个点了omg,不过收获颇丰。休息一下直接写chap3的八股六步。
------------17:08我要写个代码,然后去吃饭拿快递了!!!最近膝盖伤了,不能锻炼哎。
------------17:28写完chap3的总结,还有24行的sequential模型没敲;10行的model定义没敲;还有一个mnist;和自己挑战一下fashion数据集;吃完饭、拿完快递再来叭,估计今天又学不了CATTI了。
------------20:12吃完饭好累,去拿了快递,背了单词顺便把chap4也看完了,老师讲的太好了!!!想直接先把课看完~
--------20:30为了买护膝,去量了个腿围,凑了个单!!!终于可以看课了!!
---------22:25还没看完,但是看到chap6了,rnn讲的也很清楚!不过要多看几遍!先去刷牙洗脸,然后去床上看,明天复现!
最后
以上就是勤奋小懒猪最近收集整理的关于NLP学习D2-TF2基础学习-北大教程的全部内容,更多相关NLP学习D2-TF2基础学习-北大教程内容请搜索靠谱客的其他文章。







![tf2报错解决 assertion failed: [predictions must be >= 0] [Condition x >= y did not hold element-wise:]](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)
发表评论 取消回复