字节存储顺序主要分为大端序(Big-endian)和小端序(Little-endian),区别如下:
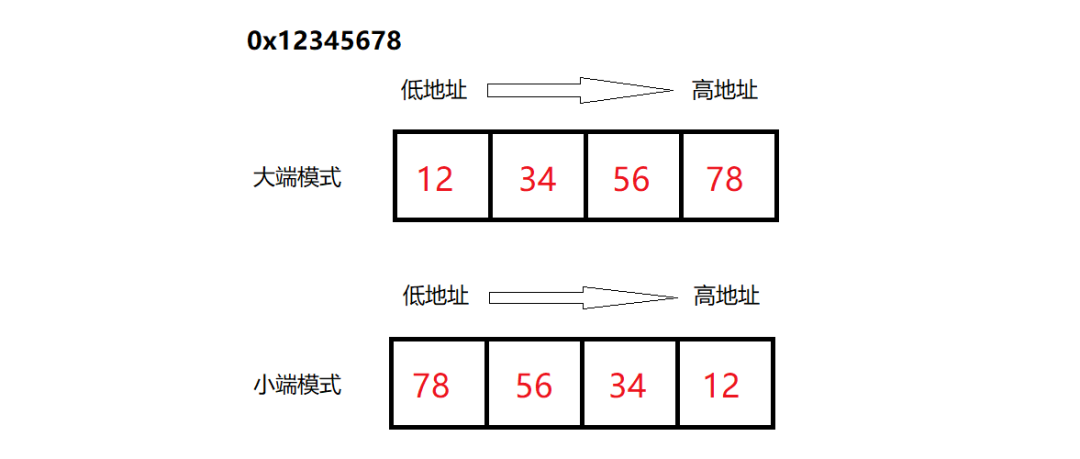
Big-endian:高位字节存入低地址,低位字节存入高地址;Little-endian:低位字节存入低地址,高位字节存入高地址;
例如,将12345678h写入内存中,以大端序和小端序模式存放结果如下:
一般来说,x86系列CPU都是Little-endian字节序,PowerPC通常是Big-endian字节序,大小端主要由CPU决定,与编译器、操作系统这些没有直接关系。
大小端主要有用于存储的顺序,与存储器(硬件)关系比较大,编译器和操作系统仅仅是配合CPU编译好相应的代码,而不是决定大小端的因素。
ARM处理器默认是小端模式,但它是支持大端模式。
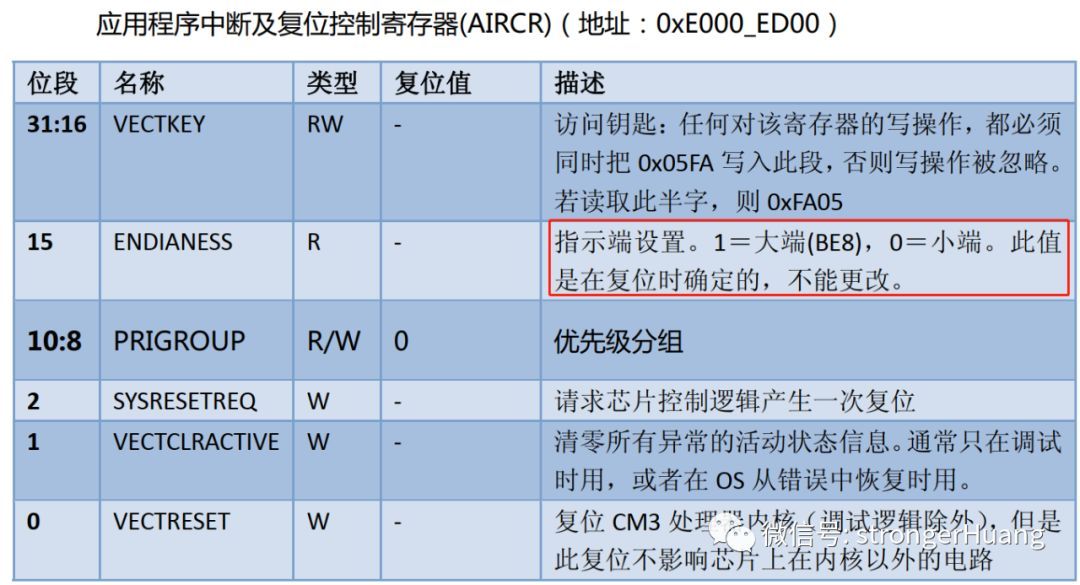
我们在Cortex-M3手册中有这么一些描述: 在 Cortex-M3中, 存储器系统支持 both 小端配置和大端配置。
Cortex-M3 支持 both 小端模式和大端模式。但是,单片机其它部分的设计,包括总线的连接,内存控制器以及外设的性质等, 一定要先在单片机的数据手册上查清楚可以使用的端。在绝大多数情况下,基于 CM3 的单片机都使用小端模式。为了避免不必要的麻烦,基本清一色地使用小端模式。
因为网络协议也都是采用Big-endian方式传输数据的,所以有时也把Big-endian方式称为网络字节序。
示例
#include "windows.h"
BYTE b = 0x12;
WORD w = 0x1234;
DWORD dw = 0x12345678;
char str[] = "abcde";
int main(int argc, char* argv[])
{
byte lb = b;
WORD lw = w;
DWORD ldw = dw;
char* lstr = str;
return 0;
}
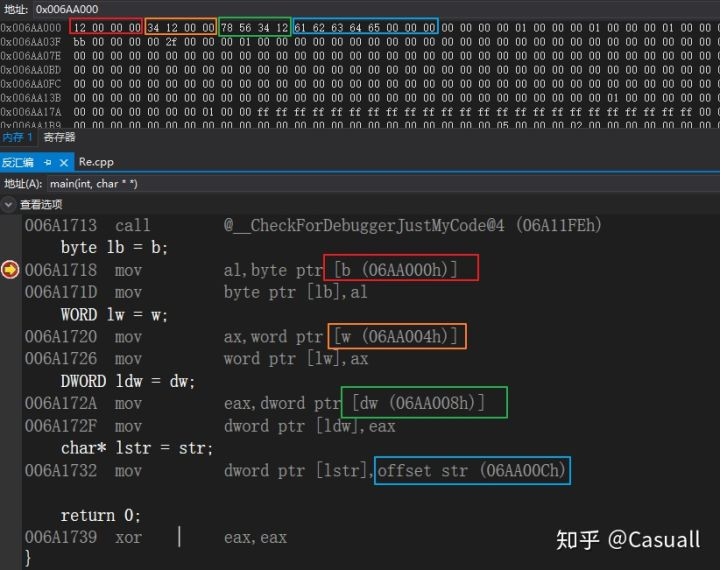
通过visual studio调试一下,转到反汇编查看反汇编代码
可以看到全局变量b、w、dw、str的地址分别为06AA000h、06AA004h、06AA008h、06AA00Ch。我们在内存窗口查看相应的地址,可以看到对应的数据,上面不同颜色的方框对应不同变量。
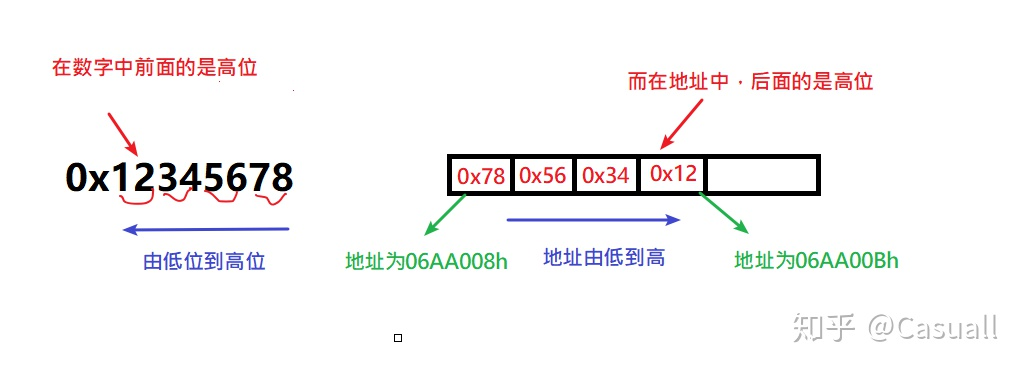
拿dw这个变量来说,他的地址是06AA008h,可以看到他的数据是0x78 0x56 0x34 0x12,注意小端序是地址高位存储数据的高位,地址低位存储数据的低位。
而字符串“abcde”被保存在一个字符(char)数组str中,字符数组在内存中是连续的,此时向字符数组存放数据,无论是采用大端序还是小端序,存储顺序都相同。
还有另个知识点,就是注意到反汇编代码中的ptr了吗,逆向分析的时候是不是经常看见这个符号,知道他是干什么的吗?
PTR运算符可以重写操作数默认的大小类型,ptr的前面会有类型的声明,比如byte ptr [b(06AA000h)],他的意思从这个地址取一个byte大小的数据。比如byte ptr [dw(06AA008h)] 得到的就是0x78, word ptr [dw(06AA008h)] 得到的就是0x5678,以此类推。
参考文章
- ARM大小端格式,编译器决定还是CPU决定
- 大端序和小端序
最后
以上就是勤恳胡萝卜最近收集整理的关于字节序大小端的区别的全部内容,更多相关字节序大小端内容请搜索靠谱客的其他文章。








发表评论 取消回复