Java 集合学习笔记:LinkedList
- UML
- 简介
- 阅读源码
- 增
- boolean add(E e)
- void add(int index, E element)
- addAll(Collection<? extends E> c)
- boolean addAll(int index, Collection<? extends E> c)
- void addFirst(E e)
- void addLastTest()
- 删
- void clear()
- E remove()
- E remove(int index)
- boolean remove(Object o)
- E removeFirst()
- boolean removeFirstOccurrence(Object o)
- E removeLast()
- boolean removeLastOccurrence(Object o)
- E pop()
- E poll()
- E pollFirst()
- E pollLast()
- 改
- E set(int index, E element)
- 查
- int indexOf(Object o)
- int lastIndexOf(Object o)
- boolean contains(Object o)
- E getFirst()
- E element()
- E get(int index)
- E getLast()
- Object clone()
- E peek()
- E peekFirst()
- E peekLast()
- 迭代
- ListItr 实现了 ListIterator 又实现了 Iterator
- Iterator<E> descendingIterator():返回降序迭代器
- UML
- ListIterator<E> listIterator(int index):返回正序迭代器
- Object[] toArray()
- <T> T[] toArray(T[] a):将列表元素填充到给定数组
- 学习总结
- 参考资料
UML
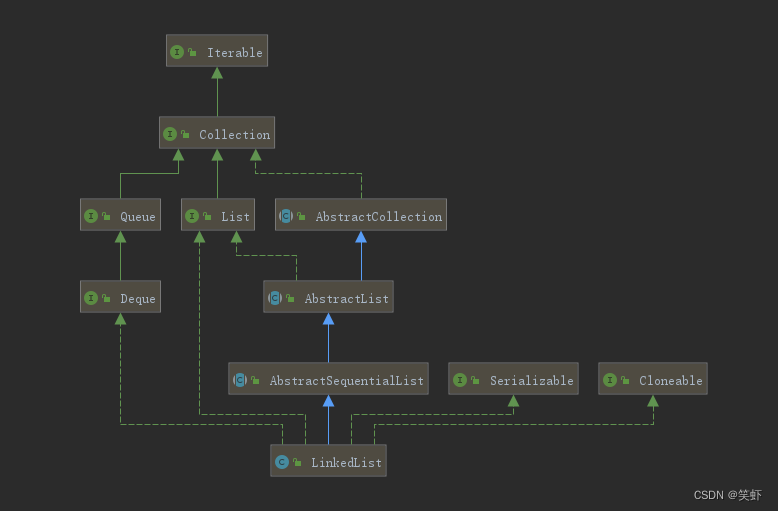
简介
List 接口的链接列表实现。实现所有可选的列表操作,并且允许所有元素(包括 null)。除了实现 List 接口外,LinkedList 类还为在列表的开头及结尾 get、remove 和 insert 元素提供了统一的命名方法。这些操作允许将链接列表用作堆栈、队列或双端队列。
此类实现 Deque 接口,为 add、poll 提供先进先出队列操作,以及其他堆栈和双端队列操作。
所有操作都是按照双重链接列表的需要执行的。在列表中编索引的操作将从开头或结尾遍历列表(从靠近指定索引的一端)。
注意,此实现不是同步的。如果多个线程同时访问一个链接列表,而其中至少一个线程从结构上修改了该列表,则它必须 保持外部同步。(结构修改指添加或删除一个或多个元素的任何操作;仅设置元素的值不是结构修改。)这一般通过对自然封装该列表的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedList 方法来“包装”该列表。最好在创建时完成这一操作,以防止对列表进行意外的不同步访问,如下所示:List list = Collections.synchronizedList(new LinkedList(...));此类的 iterator 和 listIterator 方法返回的迭代器是快速失败 的:在迭代器创建之后,如果从结构上对列表进行修改,除非通过迭代器自身的 remove 或 add 方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒将来不确定的时间任意发生不确定行为的风险。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在不同步的并发修改时,不可能作出任何硬性保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的方式是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。
阅读源码
增
| 访问修饰符&返回类型 | 方法 | 描述 |
|---|---|---|
| boolean | add(E e) | 将指定元素添加到此列表的结尾。 |
| void | add(int index, E element) | 在此列表中指定的位置插入指定的元素。 |
| boolean | addAll(Collection<? extends E> c) | 添加指定 collection 中的所有元素到此列表的结尾,顺序是指定 collection 的迭代器返回这些元素的顺序。 |
| boolean | addAll(int index, Collection<? extends E> c) | 将指定 collection 中的所有元素从指定位置开始插入此列表。 |
| void | addFirst(E e) | 将指定元素插入此列表的开头。 |
| void | addLast(E e) | 将指定元素添加到此列表的结尾。 |
| boolean | offer(E e) | 将指定元素添加到此列表的末尾(最后一个元素)。 直接调 add(E e)。 |
| boolean | offerFirst(E e) | 在此列表的开头插入指定的元素。 内部调 addFirst(e) 成功返回 true。 |
| boolean | offerLast(E e) | 在此列表末尾插入指定的元素。 内部调 addLast(e) 成功返回 true。 |
| void | push(E e) | 将元素推入此列表所表示的堆栈。 直接调 addFirst(e) 。 |
boolean add(E e)
- test
@Test
public void addTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.add("XYZ");
log.info(list.toString()); // [A, B, C, D, E, XYZ]
}
add(E e):将指定元素添加到此列表的结尾。
public boolean add(E e) {
linkLast(e);
return true;
}
linkLast(E e):链接e作为最后一个元素。
void linkLast(E e) {
// 临时缓存末尾节点
final Node<E> l = last;
// 创建新节点,亲节点插在末尾,所以它后面为 null
final Node<E> newNode = new Node<>(l, e, null);
// 更新末尾节点指针变量
last = newNode;
// 如原末尾节点就是 null 说明,列表是空的。头节点也指向新节点。
// 否则:原节点的上一个节点更新 next 指向新节点
if (l == null)
first = newNode;
else
l.next = newNode;
size++; // 插入节点成功,长度++
modCount++; // 插入节点成功,修改计数++
}
Node<E>:节点类,私有。
private static class Node<E> {
E item; // 节点中保存的元素
Node<E> next; // 后一节点指针
Node<E> prev; // 前一节点指针
// 构造节点对象(前节点,当前节点元素, 后节点)
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
void add(int index, E element)
- test
@Test
public void addIndexTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.add(2, "XYZ");
log.info(list.toString()); // [A, B, XYZ, C, D, E]
}
- 插入流程
- 找到
index对应的目标节点R。 - 将
R与它的前一节点L断开。 - 创建新节点
newNode。使newNode.prev指向L,newNode.next指向R。 - 更新
R节点指针:R.prev指向newNode。 - 更新
L节点指针:
5.1. 如果节点L为 null,表示我们插入在了头部,更新头节点指针first = newNode
5.2. 否则L.next指向newNode。
add(int index, E element)
在列表的index处插入element。
public void add(int index, E element) {
checkPositionIndex(index); // 检查 index 如果越界就抛锅
if (index == size) // 如果是末尾
linkLast(element); // 直接连接
else
// 否则 在非空 index 节点之前插入元素 element。
linkBefore(element, node(index));
}
checkPositionIndex(int index)
索引检测,如果越界就抛锅。
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
isPositionIndex(int index)
索引在正常范围内,返回true
private boolean isPositionIndex(int index) {
// index = 0 表示头节点。
// index = size 表示尾节点的 next。也就是末尾追加元素的位置。
return index >= 0 && index <= size;
}
- linkLast(E e):将元素
e作为最后一个节点,连接到链表。
node(int index)按索引获取节点。返回指定元素索引处的(非空)Node。
Node<E> node(int index) {
// size / 2 找出中间值,index 小于它说明靠左,从头开始找,否则从末尾开始找。
if (index < (size >> 1)) {
// 先拿到头节点
Node<E> x = first;
// 从前向后找,直到遇上 index 的前一个节点,取它的 next 返回。
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 先拿到尾节点
Node<E> x = last;
// 从后向前找,直到遇上 index 的后一个节点,取它的 prev 返回。
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
linkBefore(E e, Node<E> succ):在非空节点succ之前插入元素e。
void linkBefore(E e, Node<E> succ) {
// 断言 succ != null; add 开头有检测过 index 有效,肯定能找到一个节点。
// 获取【原节点 succ】的前一节点。
final Node<E> pred = succ.prev;
// 创建存放【元素e】的新节点,同时指定其【前、后】指针。
final Node<E> newNode = new Node<>(pred, e, succ);
// 更新【原节点 succ】的 prev 指针,指向新节点。
succ.prev = newNode;
// 如果【原节点 succ】的 prev 为 null 说明它当时就是头节点,
// 现在新节点插入在原节点前面,所以更新头节点指针,指向新插入的节点。
if (pred == null)
first = newNode;
// pred.next 本来指向【原节点 succ】,现在要更新为指向新插入节点。
else
pred.next = newNode;
// 插入成功,更新列表长度。
size++;
// 插入成功,更新修改计数。
modCount++;
}
addAll(Collection<? extends E> c)
- test
@Test
public void addAllTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.addAll(Arrays.asList("1","2","3"));
log.info(list.toString()); // [A, B, C, D, E, 1, 2, 3]
}
将集合 c 原样插入当前列表末尾。
public boolean addAll(Collection<? extends E> c) {
// 尾节点的索引是 size - 1。在它后面插入就是 size
return addAll(size, c);
}
boolean addAll(int index, Collection<? extends E> c)
- test
@Test
public void addAllIndexTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.addAll(2, Arrays.asList("1","2","3"));
log.info(list.toString()); // [A, B, 1, 2, 3, C, D, E]
}
addAll(int index, Collection<? extends E> c)
将指定集合 c 中的所有元素从指定位置 index 开始插入到此列表中。此列表中 index 及其后的所有元素,向后挪。
checkPositionIndex 索引检测,如果越界就抛锅。
// 向 ----- 索引2处插入 ===
// 断开为 -- 和 ---
// 插入 -- === ---
// 更新连接处各节点的 prev、next 指针
// 完成插入 --===---
// 插入的是集合 [===,+++,***] 就重复如上。
// --===---
// --===+++---
// --===+++***---
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index); // 索引检测,如果越界就抛锅。
Object[] a = c.toArray(); // 获取集合 c 所有元素的数组。
int numNew = a.length; // 获取将插入的元素个数
if (numNew == 0) // 如果插入元素个数为 0 直接返回 false
return false;
// 声明两个临时变量,在插入过程中,用来临时保存前后节点。
// pred=前节点(原本就在 index 节点前面,新节点来后,位置不变)
// succ=后节点(插入前 index 位置的节点,被新节点往后挤了)
Node<E> pred, succ;
// 如果 index == size 在尾节点后追加
if (index == size) {
succ = null; // 后节点自然还是 null
pred = last; // 原列表的尾节点。
// 否则在中间或头插入
} else {
succ = node(index); // index 所在节点,作为后节点。
pred = succ.prev; // index节点的 prev,作为前节点。
}
// 遍历数组 a 逐个插入
for (Object o : a) {
// 取出元素,强转类型,以符合当前列表。
@SuppressWarnings("unchecked") E e = (E) o;
// 创建存放元素的新节点:【前节点】上面已取得直接使,【后节点】留空,稍后处理。
Node<E> newNode = new Node<>(pred, e, null);
// 没人出头,我出头当大哥。
if (pred == null)
first = newNode;
// 有带头大哥,就让大哥带新节点。新节点在创建时 prev 已经指向 pred ,至此双向连接完成。
else
pred.next = newNode;
// 更新前节点变量。用这个的新节点作为后续节点的【前节点】
pred = newNode;
}
// 遍历插入完成后,处理尾节点。
// 在插入前,插入位置就没有【后节点】,那最后一个插入的节点作为【尾节点】
if (succ == null) {
last = pred;
// 否则:新插入的最后一个节点与 succ 连接。
} else {
pred.next = succ;
succ.prev = pred;
}
// 更新列表长度 +上新插入的个数
size += numNew;
// 更新修改计数。与批量插入了多少个元素无关,计为修改了 1 次。
modCount++;
// 插入成功返回 true
return true;
}
Object[] toArray()
将当前表中的元素,按顺序复制到一个新数组并返回。此数组与原列表无引用关系,可以随便编辑修改数组(元素是传值址的,与原列表共享,修改元素内容,两边都会变的)。
public Object[] toArray() {
Object[] result = new Object[size]; // 新建一个和当前列一样大的数组
int i = 0;
// 从头开始,遍历链表,逐个向数组复制元素。
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item; // 直接给的引用,而不是克隆一个副本
return result;
}
void addFirst(E e)
- test
@Test
public void addFirstTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.addFirst("X");
log.info(list.toString()); // [X, A, B, C, D, E]
}
void addFirst(E e)
public void addFirst(E e) {
linkFirst(e);
}
void linkFirst(E e)将元素e作为头节点,连接到链表。
private void linkFirst(E e) {
// 取出【头节点】,存入临时变量 f
final Node<E> f = first;
// 创建新节点,存放元素 e,并将其 next 指向 f (原来的头节点)
final Node<E> newNode = new Node<>(null, e, f);
// 更新当前链表的【头节点】指向【新节点】
first = newNode;
// 如果是空链表,更新当前链表的【尾节点】指向【新节点】
if (f == null)
last = newNode;
// 否则:【原来的头节点】的 prev 指向【新节点】
else
f.prev = newNode;
// 插入成功,更新列表长度。
size++;
// 插入成功,更新修改计数。
modCount++;
}
void addLastTest()
- test
@Test
public void addLastTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.addLast("X");
log.info(list.toString()); // [A, B, C, D, E, X]
}
void addLast(E e)
public void addLast(E e) {
linkLast(e);
}
- linkLast(E e):将元素
e作为最后一个节点,连接到链表。
删
| 访问修饰符&返回类型 | 方法 | 描述 |
|---|---|---|
| void | clear() | 从此列表中移除所有元素。 |
| E | remove() | 获取并移除此列表的头(第一个元素)。 底层调用 removeFirst() 并返回结果。 |
| E | remove(int index) | 移除此列表中指定位置处的元素。 |
| boolean | remove(Object o) | 从此列表中移除首次出现的指定元素(如果存在)。 |
| E | removeFirst() | 移除并返回此列表的第一个元素。 |
| boolean | removeFirstOccurrence(Object o) | 从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表时)。 直接调用 remove(Object o) 并返回结果。 |
| E | removeLast() | 移除并返回此列表的最后一个元素。 |
| boolean | removeLastOccurrence(Object o) | 从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表时)。 |
| E | pop() | 从此列表所表示的堆栈处弹出一个元素。 直接调用 removeFirst() 并返回结果。 |
| E | poll() | 获取并移除此列表的头(第一个元素)。 |
| E | pollFirst() | 获取并移除此列表的第一个元素;如果此列表为空,则返回 null。 代码与 pop() 完全一样。 |
| E | pollLast() | 获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。 |
void clear()
从此列表中移除所有元素。
- test
@Test
public void clearTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.clear();
log.info(list.toString()); // []
}
clear()
清除节点之间的所有链接“不是必须的”,但有利于垃圾回收。
public void clear() {
// 从【头节点】逐个遍历,把节点中的【元素、前节点、后节点】三个引用都置为 null
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
// 遍历完后,头尾节点两个指针也都置 null
first = last = null;
// 更新大小为 0
size = 0;
// 更新修改计数
modCount++;
}
E remove()
- test
@Test
public void removeTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.remove();
log.info(list.toString()); // [B, C, D, E]
}
remove()
public E remove() {
return removeFirst();
}
E removeFirst()
public E removeFirst() {
// 获取【头节点】,存到临时变量 f
final Node<E> f = first;
// 如果【头节点】为 null 直接抛锅。
if (f == null)
throw new NoSuchElementException();
// 否则断开【头节点】的连接,并将其返回。
return unlinkFirst(f);
}
E unlinkFirst(Node<E> f):将【头节点】f从链表中断开。并返回f中的元素。
private E unlinkFirst(Node<E> f) {
// 进来之前已经确认了 f 是【头节点】,且 f 不为 null;
// 取出【头节点】中保存的元素。(最后要返回的)
final E element = f.item;
// 临时缓存【头节点】的 next (也就是第二个节点)
final Node<E> next = f.next;
// 将 f 的 item 和 next 指向 null,有助于垃圾清理
f.item = null;
f.next = null;
// 更新【头节点】指向来的【二节点】
first = next;
// 如果【二节点】为空,则更新【尾节点】为空。
if (next == null)
last = null;
// 否则更新【二节点】的 prev 指向 null
else
next.prev = null;
// 移除【头节点】成功,更新列表大小。
size--;
// 更新列表的修改计数
modCount++;
// 返回被移除的【头节点】中所保存的元素
return element;
}
E remove(int index)
- test
@Test
public void removeIndexTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.remove(2);
log.info(list.toString()); // [A, B, D, E]
}
E remove(int index)
移除此列表中指定位置处的元素。
public E remove(int index) {
// 检测索引如果越界,直接抛锅。
checkElementIndex(index);
// 将 index 所在节点,从链表中断开
return unlink(node(index));
}
- unlink(Node x):从链表中断开非空节点
x - node(int index) 按索引获取节点。
void checkElementIndex(int index):如果index越界,则抛锅。
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
boolean isElementIndex(int index)
检测索引index没有越界,则返回true
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
E unlink(Node<E> x):从链表中断开非空节点x
E unlink(Node<E> x) {
// 进来之前已经确认 x 非 null;
// 先取出节点中保持的元素,最后要返回的。
final E element = x.item;
// 用临时变量,分别取 x 的前后节点
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// 如果 x 前面没有节点(同时 x 自己又要被移除)则【头节点】变量指向 x 后面的节点。
// 否则:x 前面的节点与 x 后面的节点直接相连。并将 x 的【前指针】置空。
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
// 如果 x 后面没有节点(同时 x 自己又要被移除)则【尾节点】变量指向 x 前面的节点。
// 否则:x 后面的节点与 x 前面的节点直接相连。并将 x 的【后指针】置空。
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
// 将 x 节点元素变量置 null
x.item = null;
// 更新列表大小
size--;
// 更新修改计数
modCount++;
// 返回 x 中的元素
return element;
}
boolean remove(Object o)
- test
@Test
public void removeObjectTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E", "B"));
list.remove("B");
log.info(list.toString()); // [A, C, D, E, B]
}
boolean remove(Object o)
从此列表中移除首次出现的指定元素(如果存在)。如果列表不包含该元素,则不作更改。
更确切地讲,移除具有满足 (o==null ? get(i)==null : o.equals(get(i))) 的最低索引 i 的元素(如果存在这样的元素)。
如果此列表已包含指定元素(或者此列表由于调用而发生更改),则返回 true。
public boolean remove(Object o) {
// null 或非 null 分开处理。null 用 ==,非null 用 equals
if (o == null) {
// 从【头节点】开始遍历链表,直到找到 null 则调用 unlink(x)
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
// 从【头节点】开始遍历链表,直到o.equals(x.item) 为 true 调用 unlink(x)
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
// 没找到,最后返回 false
return false;
}
- E unlink(Node x):从链表中断开非空节点
x
E removeFirst()
- test
@Test
public void removeFirsttTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.removeFirst();
log.info(list.toString()); // [B, C, D, E]
}
E removeFirst():移除并返回此列表的第一个元素。
public E removeFirst() {
// 取【头节点】
final Node<E> f = first;
// 如果为 null 抛锅
if (f == null)
throw new NoSuchElementException();
// 将【头节点】f 从链表中断开。并返回 f 中的元素。
return unlinkFirst(f);
}
- E unlinkFirst(Node f):将【头节点】
f从链表中断开。并返回f中的元素。
boolean removeFirstOccurrence(Object o)
直接调用 remove(Object o) 并返回结果。
public boolean removeFirstOccurrence(Object o) {
return remove(o);
}
E removeLast()
- test
@Test
public void removeLastTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
list.removeLast();
log.info(list.toString()); // [A, B, C, D]
}
E removeLast()
public E removeLast() {
// 取【尾节点】
final Node<E> l = last;
// 如果为 null 抛锅
if (l == null)
throw new NoSuchElementException();
// 将【尾节点】l 从链表中断开。并返回 l 中的元素。
return unlinkLast(l);
}
E unlinkLast(Node<E> l):断开末尾节点。并返回其保存的元素值。
private E unlinkLast(Node<E> l) {
// 进来之前已经确认了 l 是【尾节点】,且 l 不为 null;
// 取出【尾节点】中保存的元素。(最后要返回的)
final E element = l.item;
// 临时缓存【尾节点】的前一个
final Node<E> prev = l.prev;
// 将 l 的 item 和 prev 指向 null,有助于垃圾清理
l.item = null;
l.prev = null; // help GC
// 更新【尾节点】指向 l 前面的节点【倒数二节点】
last = prev;
// l 的【前指针】为空。说明链表中只有 l 一个节点。删除后【首节点】变量为 null
// 否则:更新【倒数二节点】的 next 指向 null。(原倒数老二现在成末尾了)
if (prev == null)
first = null;
else
prev.next = null;
// 移除成功,更新列表大小。
size--;
// 更新列表的修改计数
modCount++;
// 返回被移除的【头节点】中所保存的元素
return element;
}
boolean removeLastOccurrence(Object o)
- test
@Test
public void removeLastOccurrenceTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("X", "A", "B", "C", "D", "E", "X"));
list.removeLastOccurrence("X");
log.info(list.toString()); // [X, A, B, C, D, E]
}
boolean removeLastOccurrence(Object o)null或not null分开处理。null用==,not null用equals判断。- 从【尾节点】开始向前遍历链表,找到目标就调用
unlink(x)移除它。 - 成功执行移除操作,返回
true
public boolean removeLastOccurrence(Object o) {
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
- E unlink(Node x):从链表中断开非空节点
x
E pop()
- test
@Test
public void popTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
String pop = list.pop();
log.info(pop); // A
log.info(list.toString()); // [B, C, D, E]
}
E pop()
public E pop() {
return removeFirst();
}
- E removeFirst():移除并返回此列表的第一个元素。
E poll()
- test
@Test
public void pollTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
String poll = list.poll();
log.info(poll); // A
log.info(list.toString()); // [B, C, D, E]
list = new LinkedList<>();
poll = list.poll();
log.info(poll); // null
}
E poll():获取并移除此列表的头(第一个元素)
public E poll() {
// 获取【头节点】
final Node<E> f = first;
// 如果【头节点】为 null,直接返回,否则调用 unlinkFirst(f) 移除【头节点】。
return (f == null) ? null : unlinkFirst(f);
}
- E unlinkFirst(Node f):将【头节点】
f从链表中断开。并返回f中的元素。
E pollFirst()
- test
@Test
public void pollFirstTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
String pollFirst = list.pollFirst();
log.info(pollFirst); // A
log.info(list.toString()); // [B, C, D, E]
list = new LinkedList<>();
pollFirst = list.pollFirst();
log.info(pollFirst); // null
}
E pollFirst()=== E poll():获取并移除此列表的头(第一个元素)
public E pollFirst() {
// 获取【头节点】
final Node<E> f = first;
// 如果【头节点】为 null,直接返回,否则调用 unlinkFirst(f) 移除【头节点】。
return (f == null) ? null : unlinkFirst(f);
}
- E unlinkFirst(Node f):将【头节点】
f从链表中断开。并返回f中的元素。
E pollLast()
- test
@Test
public void pollLastTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
String pollLast = list.pollLast();
log.info(pollLast); // E
log.info(list.toString()); // [A, B, C, D]
list = new LinkedList<>();
pollLast = list.pollFirst();
log.info(pollLast); // null
}
E pollLast()
public E pollLast() {
// 获取【尾节点】
final Node<E> l = last;
// 如果【尾节点】为 null,直接返回,否则调用 unlinkLast(l) 移除【尾节点】。
return (l == null) ? null : unlinkLast(l);
}
- E unlinkLast(Node l):断开末尾节点。并返回其保存的元素值。
改
| 访问修饰符&返回类型 | 方法 | 描述 |
|---|---|---|
| E | set(int index, E element) | 将此列表中指定位置的元素替换为指定的元素。 |
E set(int index, E element)
- test
@Test
public void settTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
String pollLast = list.set(2, "笨笨");
log.info(pollLast); // C
log.info(list.toString()); // [A, B, 笨笨, D, E]
}
E set(int index, E element)
public E set(int index, E element) {
checkElementIndex(index); // 检查索引,越界就抛锅。
Node<E> x = node(index); // 按索引获取要修改的节点
E oldVal = x.item; // 取出节点中的原值
x.item = element; // 修改节点值
return oldVal; // 返回原值
}
- checkElementIndex(int index):如果
index越界,则抛锅。 - node(int index):按索引获取节点。返回指定元素索引处的(非空)Node。
查
| 访问修饰符&返回类型 | 方法 | 描述 |
|---|---|---|
| int | indexOf(Object o) | 返回此列表中首次出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。 |
| int | lastIndexOf(Object o) | 返回此列表中最后出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。 |
| boolean | contains(Object o) | 如果此列表包含指定元素,则返回 true。 |
| E | getFirst() | 返回此列表的第一个元素。 |
| E | element() | 获取但不移除此列表的头(第一个元素)。 直接调用 getFirst() 并返回其值。 |
| E | get(int index) | 返回此列表中指定位置处的元素。 |
| E | getLast() | 返回此列表的最后一个元素。 |
| Object | clone() | 返回此 LinkedList 的浅表副本。 |
| E | peek() | 获取但不移除此列表的头(第一个元素)。 |
| E | peekFirst() | 获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。 代码 peek() 完全一样 |
| E | peekLast() | 获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。 |
| int | size() | 返回此列表的元素数。 |
int indexOf(Object o)
- test
@Test
public void indexOfTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("列表中存在“C”的索引:{}", list.indexOf("C")); // 列表中存在“C”的索引:2
log.info("列表中存在“笨笨”的索引:{}", list.indexOf("笨笨")); // 列表中存在“笨笨”的索引:-1
}
int indexOf(Object o):返回此列表中首次出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。null或not null分开处理。null用==,not null用equals判断。- 从【头节点】开始向前遍历链表
- 初
index为0。每走一次 +1,直到找到目标,返回index的值。 - 遍历结束也没找到,返回
-1
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
int lastIndexOf(Object o)
- test
@Test
public void lastIndexOfTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "X", "C", "X", "D", "E"));
log.info("从后向前找“C”索引:{}", list.lastIndexOf("C")); // 从后向前找“C”索引:3
log.info("从后向前找“笨笨”索引:{}", list.lastIndexOf("笨笨")); // 从后向前找“笨笨”索引:-1
}
int lastIndexOf(Object o)
- 取出列表大小。(索引从 0 开始,所以最后一个索就是 size - 1)
null或not null分开处理。null用==,not null用equals判断。- 从最后一个节点
last开始向前遍历,直到获取的节点为null结束。 - 如果找到目标元素
o就返回对应的索引index
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
boolean contains(Object o)
- test
@Test
public void containsTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("列表中存在“C”:{}", list.contains("C")); // 列表中存在“C”:true
log.info("列表中存在“笨笨”:{}", list.contains("笨笨")); // 列表中存在“笨笨”:false
}
boolean contains(Object o)
public boolean contains(Object o) {
return indexOf(o) != -1;
}
E getFirst()
- test
@Test
public void getFirstTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("获取列表头:{}", list.getFirst()); // A
log.info("列表内容不变:{}", list); // [A, B, C, D, E]
}
E getFirst():返回此列表的第一个节点的元素。
- 直接获取【头节点】变量。
- 如果为空抛锅,否则返回它的元素值。
- 为啥不直接用
first而是搞个临时变量f,感觉没啥必要啊。
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
E element()
- test
@Test
public void elementTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("获取但不移除此列表的头:{}", list.element()); // 列表中存在“C”:true
log.info("列表内容不变:{}", list); // 列表中存在“C”:true
}
E element()
public E element() {
return getFirst();
}
- E getFirst():返回此列表的第一个元素。
E get(int index)
- test
@Test
public void getTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("{}", list.get(2)); // C
}
E get(int index)
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
- checkElementIndex(int index):如果
index越界,则抛锅。 - node(int index) 按索引获取节点。
E getLast()
- test
@Test
public void getLastTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("{}", list.getLast()); // E
}
E getLast():返回此列表的最后一个节点的元素。
- 直接获取【尾节点】变量。
- 如果为空抛锅,否则返回它的元素值。
- 为啥不直接用
last而是搞个临时变量l,感觉没啥必要啊。
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
Object clone()
- test
@Test
public void cloneTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
Object clone = list.clone();
log.info("{}", clone ); // [A, B, C, D, E]
log.info("{}", clone == list ); // false
}
Object clone()
- 调用父类的克隆方法 ,创建一个空列表。
- 初始化
clone对象 - 遍历当前列表,填充
clone然后返回。
public Object clone() {
LinkedList<E> clone = superClone();
// 初始化 clone 对象
clone.first = clone.last = null; // 头尾节点初始为 null
clone.size = 0; // 大小初始为 0
clone.modCount = 0; // 修改计数初始为 0
// 遍历当前列表,填充 clone
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
// 返回克隆出来的列表
return clone;
}
- LinkedList superClone()
调用父类的克隆方法,如果异常了就抛InternalError
private LinkedList<E> superClone() {
try {
return (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
E peek()
- test
@Test
public void peekTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("{}", list.peek() ); // A
}
E peek()
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
E peekFirst()
- test
@Test
public void peekFirstTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("{}", list.peekFirst() ); // A
}
E peekFirst()
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
E peekLast()
- test
@Test
public void peekLastTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
log.info("{}", list.peekLast() ); // E
}
E peekLast()
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
迭代
| 访问修饰符&返回类型 | 方法 | 描述 |
|---|---|---|
| Iterator | descendingIterator() | 返回以逆向顺序在此双端队列的元素上进行迭代的迭代器。 |
| ListIterator | listIterator(int index) | 返回此列表中的元素的列表迭代器(按适当顺序),从列表中指定位置开始。 |
| Object[] | toArray() | 返回以适当顺序(从第一个元素到最后一个元素)包含此列表中所有元素的数组。 |
| <T> T[] | toArray(T[] a) | 返回以适当顺序(从第一个元素到最后一个元素)包含此列表中所有元素的数组;返回数组的运行时类型为指定数组的类型。 |
ListItr 实现了 ListIterator 又实现了 Iterator
LinkedList 定义的内部类 ListItr 在接下来的 返回降序迭代器 中就是它。
private class ListItr implements ListIterator<E> {
// 指向上一次返回的节点,可以理解为【当前节点】
// 每次调用 next、previous 后会给它复制,每次调用 remove 后会清空它。
private Node<E> lastReturned;
// 下一个节点(指向下一次调 next 将要返回的节点,如果调 previous 会返回 next.prev)
private Node<E> next;
// 下一指针(与 next 对应的索引)
private int nextIndex;
// 同步修改计数,用于判断并发冲突
private int expectedModCount = modCount;
// 初始化 ListItr
ListItr(int index) {
// 传 index 进来之前,已经确保了 index 在有效范围内
// 用 index 及对应的节点初始化 next、nextIndex
// 这个 node(index) 是外层的方法
next = (index == size) ? null : node(index);
nextIndex = index;
}
// 是否存在下一个节点。如果【下一指针】小于列表大小,则返回 true
public boolean hasNext() {
return nextIndex < size;
}
// 返回下一个节点
public E next() {
// 检测并发冲突
checkForComodification();
// 下一个都没了,怎么返回。直接抛锅。
if (!hasNext())
throw new NoSuchElementException();
// 更新【当前节点】(为上次留下的【next】。它也就是这一次将要返回的节点)
lastReturned = next;
// 更新【下一个节点】(为原【下一个节点】的【下一个节点】)
next = next.next;
// 更新【下一指针】
nextIndex++;
// 返回【最近一次返回的节点】中包含的元素
return lastReturned.item;
}
// 是否存上一个节点。如果【下一指针】大于 0 返回 true
//
public boolean hasPrevious() {
return nextIndex > 0;
}
// 返回上一个节点
public E previous() {
// 检测并发冲突
checkForComodification();
// 如果没有上一个了,就抛锅。
if (!hasPrevious())
throw new NoSuchElementException();
// 更新【最近一次返回的节点】及【下一个节点】
// 如果 next 指向 null 返回 【最后一个】 否则返回 【上一个节点】
lastReturned = next = (next == null) ? last : next.prev;
// 更新下一索引
nextIndex--;
return lastReturned.item;
}
// 返回下一指针
public int nextIndex() {
return nextIndex;
}
// 返回上一指针
public int previousIndex() {
return nextIndex - 1;
}
// 移除最近一次返回的元素(也就是当前节点)
public void remove() {
// 检测并发冲突
checkForComodification();
// 如果【最近一次返回的节点】为 null 抛锅。remove 与要获取操作对应,不能单独调用。
if (lastReturned == null)
throw new IllegalStateException();
// 下一步要删除当前节点了,先把【下一节点】取出来缓存到 lastNext
Node<E> lastNext = lastReturned.next;
// 断开【当前节点】(也就是移除); unlink 这里有 modCount++;
unlink(lastReturned);
// 如果是从后向前迭代时就会出现 next == lastReturned
// 【尾节点】被删除后,倒数第二个节点的【next】要指向原来【尾节点】的 next (正常情况就是 null)
// 但有可能当前列表是一个 subList,这时如果没有更新这个 next。那原列表就断球了。
if (next == lastReturned)
next = lastNext;
else
// 从前向后遍历时删除成功,只需要索引-1,表示后续所有节点都整体向前移一位即可。
nextIndex--;
// 【当前节点】已经被删除,置为 null。下一次调 next、previous 时将再次给它赋值
lastReturned = null;
// 更新修改计数(父列表的修改计数在 unlink 已经++ 了)
expectedModCount++;
}
// 更新【当前节点】的元素
public void set(E e) {
// 如果【当前节点】为 null 抛锅
if (lastReturned == null)
throw new IllegalStateException();
// 检测并发冲突
checkForComodification();
// 更新元素
lastReturned.item = e;
}
// 添加元素到列表末尾
public void add(E e) {
checkForComodification(); // 检测并发冲突
lastReturned = null; // 添加了新元素,【当前节点】置 null
// 如果是空列表,
if (next == null)
linkLast(e); // 插后面
else
linkBefore(e, next); // 插前面
// 更新【下一个索引】因为插入成功,后面的索引要向后推了
nextIndex++;
// 更新修改计数。父列表的计数在 linkLast、linkBefore 中已经修改了
expectedModCount++;
}
// 遍历消费剩余节点
public void forEachRemaining(Consumer<? super E> action) {
// 传进来的 lambda 为空就抛锅
Objects.requireNonNull(action);
// 如果修改计数里外一至并且【下一个索引】小于 size
while (modCount == expectedModCount && nextIndex < size) {
// 消费【下一节点】的元素
action.accept(next.item);
// 取【下一节点】继续遍历
lastReturned = next; // 更【当前节点】
next = next.next; // 更新【下一节点】()
nextIndex++; // 更新【下一索引】
}
// 检测并发冲突
checkForComodification();
}
// 检测并发冲突
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
- E unlink(Node x):从链表中断开非空节点
x - linkLast(E e):将元素
e作为最后一个节点,连接到链表。 - linkBefore(E e, Node succ):在非空节点
succ之前插入元素e。
Iterator descendingIterator():返回降序迭代器
- test
public void descendingIteratorTest(){
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
Iterator<String> stringIterator = list.descendingIterator();
while (stringIterator.hasNext()) {
String next = stringIterator.next();
log.info("{}", next);
stringIterator.remove();
}
log.info("{}", list); // 5
}
// 信息: E
// 信息: D
// 信息: C
// 信息: B
// 信息: A
// 信息: []
UML
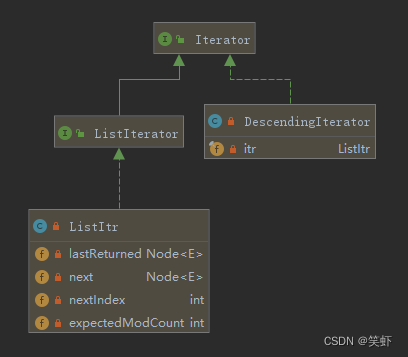
Iterator<E> descendingIterator()
public Iterator<E> descendingIterator() {
return new DescendingIterator();
}
classDescendingIterator implements Iterator
实现 Iterator
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
// 有上一个
public boolean hasNext() {
return itr.hasPrevious();
}
// 有下一个
public E next() {
return itr.previous();
}
// 移除上次返回的节点
public void remove() {
itr.remove();
}
}
ListIterator listIterator(int index):返回正序迭代器
- test
@Test
public void listIteratorTest() {
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
Iterator<String> iterator = list.listIterator();
while (iterator.hasNext()) {
log.info("{}", iterator.next());
}
}
ListIterator<E> listIterator(int index):从列表中指定位置开始,返回此列表中的元素的列表迭代器(按适当顺序)。
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
- private class ListItr implements ListIterator:ListItr 实现了 ListIterator 又实现了
Object[] toArray()
- test
@Test
public void toArrayTest() {
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "D", "E"));
Object[] objects = list.toArray();
log.info("{}", Arrays.toString(objects));
}
Object[] toArray()
public Object[] toArray() {
// 创建一个与当前列表大小相同的数组
Object[] result = new Object[size];
int i = 0;
// 从【头节点】开始逐个遍历,将元素填充进数组。
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
// 返回结果数组
return result;
}
<T> T[] toArray(T[] a):将列表元素填充到给定数组
- test
@Test
public void toArrayClassTest() {
LinkedList<Integer> list = new LinkedList<>(Arrays.asList(1, 2, 3, 4, 5));
Integer[] integers1 = list.toArray(new Integer[5]);
log.info("{}", Arrays.toString(integers1)); // [1, 2, 3, 4, 5]
Integer[] integers2 = list.toArray(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9 ,10});
log.info("{}", Arrays.toString(integers2)); // [1, 2, 3, 4, 5, null, 7, 8, 9, 10]
}
<T> T[] toArray(T[] a)
public <T> T[] toArray(T[] a) {
// 如果给定数组小于当前列表,就需要 new 一个新的数组来用。
// a.getClass().getComponentType() 拿到数组中元素的类型。
// java.lang.reflect.Array.newInstance(类型, 大小) 用反射创建指定类型的数组。
if (a.length < size)
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size
);
// 从【头节点】开始遍历节点,逐个放进数组。
// 这里使用了一个临时变量 result
int i = 0;
Object[] result = a;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
// 如果数组比列表长,则将数组的 size 设置为 null (再往后的位置就不管了)
if (a.length > size)
a[size] = null;
return a;
}
学习总结
- 底层数组结构是
链表 LinkedList底层不是数组,为了实现List针对于索引的操作。它是通过遍历列表,然后累加一个index来模拟索引的。
2.1. 因此频繁的使用索引是低效的。- 链表的优势在于,明确拿到一个节点时,删除节点或在其前后插入节点比较高效。因为本质上只需要更新相关节点的
next、prev指针。而不需要像数组那样挪数据。
参考资料
LinkedList
可视化数据结果 链表
最后
以上就是糊涂舞蹈最近收集整理的关于Java 集合学习笔记:LinkedListUML简介阅读源码学习总结参考资料的全部内容,更多相关Java内容请搜索靠谱客的其他文章。








发表评论 取消回复