- JSON入门教程
- JSON官方介绍
- cJSON源码下载
一、cJSON概述
cJSON 是一个非常轻量的C语言库,构建在ANSI C标准之上,用来解析JSON格式的数据。说其轻量是因为该库只包含了一个头文件和一个源文件,总的代码量不到一千行,源码可以在这里下载。本篇博客对cJSON库源码进行分析,旨在弄懂其实现原理和相关技术。我认为可以从以下三个问题入手:
1. 如何表示JSON数据
2. 如何生成JSON数据
3. 如何解析JSON数据
二、如何表示JSON数据
JSON主要的值类型null,false,true,number(数字),string(字符串),array(数组)以及object(对象),其中字符串用双引号" "表示,数组用[]表示,对象用{}表示,样例如下所示,值得注意的是数组或者对象是可以嵌套使用的。
{
// 结点1
"name": "Jack ("Bee") Nimble",
// 结点2
"format": {"type":"rect","width":1920,"height":1080,"interlace":false,"frame rate": 24}
}对于JSON数据,cJSON库用了树和双向链表这两种数据结构来构建,里面的基本元素(键值对)称作一个结点,将上面的样例数据用树形结构表示,如图1所示。
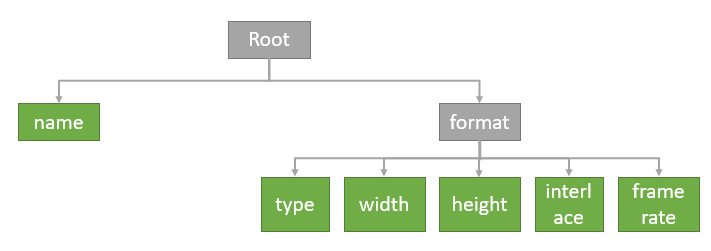
图1 JSON样例数据的树形结构
树中的每一个结点用结构体表示,对应cJSON库的源码如下,其中
字段next,prev用于构建双向链表查找同一层的结点(如linklist(name、format)或者linklist(type、width、height、interlace、frame rate)),即同一层的结点通常是双向链表的元素;
字段child是构建树层级结构的关键,用于查找下一层的结点,如Root的child是linklist(name、format),format结点的child是linklist(type、width、height、interlace、frame rate),注意只有对象和数组有child字段,该字段指向linklist的表头;
字段type记录这个结点的值类型(null,false,true,number,string,array,object中的一种);
字段valuestring、valueint、valuedouble分别记录所在结点的字符串值、整型值和双精度浮点型值;
字段string是该结点的名字。
typedef struct cJSON {
struct cJSON *next,*prev;
struct cJSON *child;
int type;
char *valuestring;
int valueint;
double valuedouble;
char *string;
} cJSON;
三、如何生成JSON数据
好了,到这里我们已经知道cJSON库是如何表示JSON格式的数据了,通过以下代码就可以生成先前的JSON样例数据,因此,我们只要弄懂了下列函数的原理,生成JSON数据的整个过程自然就懂了。
cJSON *root,*fmt;
root=cJSON_CreateObject();
cJSON_AddItemToObject(root, "name", cJSON_CreateString("Jack ("Bee") Nimble"));
cJSON_AddItemToObject(root, "format", fmt=cJSON_CreateObject());
cJSON_AddStringToObject(fmt,"type", "rect");
cJSON_AddNumberToObject(fmt,"width", 1920);
cJSON_AddNumberToObject(fmt,"height", 1080);
cJSON_AddFalseToObject (fmt,"interlace");
cJSON_AddNumberToObject(fmt,"frame rate", 24);首先看cJSON_CreateObject()函数内部的执行过程,该函数通过调用cJSON_New_Item ()分配内存,创建空白结点,如果创建成功则标识该结点的类型为对象类型,也就是说该函数的作用是创建一个对象结点。
cJSON * cJSON_CreateObject (void)
{
cJSON * item = cJSON_New_Item ();
if (item)
item->type = cJSON_Object;
return item;
}
/* Internal constructor. */
static cJSON * cJSON_New_Item (void)
{
cJSON * node = (cJSON *)cJSON_malloc (sizeof (cJSON));
if (node)
memset (node, 0, sizeof (cJSON));
return node;
}接着看cJSON_AddItemToObject函数,这里涉及的代码有点多,不过大家不要怕,我们一起来解读这段代码:该函数有3个形参,分别是对象父节点、子结点名字以及子结点,该函数要求子结点已经分配内存,如果子结点的名字已被赋值,则会被释放再重新赋予指定的名字,在这一过程中,由于名字是通过指针传入的,为了不影响原先这块内存的值,所以子结点的名字值实际指向的是传入值在内存中的一份副本;到这里也仅仅是修改了子结点的名字,最关键的一步是将对象父节点和子结点建立联系,该过程封装在cJSON_AddItemToArray (object,item)函数中,其通过父节点的child字段完成绑定,并将子结点插入链表的表尾。
void cJSON_AddItemToObject (cJSON * object, const char * string, cJSON * item)
{
if (!item)
return;
if (item->string)
cJSON_free (item->string);
item->string = cJSON_strdup (string);
cJSON_AddItemToArray (object, item);
}
static char * cJSON_strdup (const char * str)
{
size_t len;
char * copy;
len = strlen (str) + 1;
if (! (copy = (char *) cJSON_malloc (len)))
return 0;
memcpy (copy, str, len);
return copy;
}
/* Add item to array/object. */
void cJSON_AddItemToArray (cJSON * array, cJSON * item)
{
cJSON * c = array->child;
if (!item)
return;
if (!c)
{
array->child = item;
}
else
{
while (c && c->next)
c = c->next;
suffix_object (c, item);
}
}
/* Utility for array list handling. */
static void suffix_object (cJSON * prev, cJSON * item)
{
prev->next = item;
item->prev = prev;
}通过下面的源码得知,其余各类型数据实际都是调用函数cJSON_AddItemToObject添加的,因此只要根据样例数据的内容,分别调用对应的函数将子结点添加到对象父节点即可。
/* Macros for creating things quickly. */
#define cJSON_AddNullToObject(object,name) cJSON_AddItemToObject(object, name, cJSON_CreateNull())
#define cJSON_AddTrueToObject(object,name) cJSON_AddItemToObject(object, name, cJSON_CreateTrue())
#define cJSON_AddFalseToObject(object,name) cJSON_AddItemToObject(object, name, cJSON_CreateFalse())
#define cJSON_AddBoolToObject(object,name,b) cJSON_AddItemToObject(object, name, cJSON_CreateBool(b))
#define cJSON_AddNumberToObject(object,name,n) cJSON_AddItemToObject(object, name, cJSON_CreateNumber(n))
#define cJSON_AddStringToObject(object,name,s) cJSON_AddItemToObject(object, name, cJSON_CreateString(s))
四、如何解析JSON数据
经过前两步,我们已经知道了如何表示JSON数据以及生成JSON数据,接下来看看cJSON库是如何解析JSON数据的。代码如下所示,通过调用cJSON_parse函数返回JSON树的根节点,其执行流程如图2所示,原始的输入JSON_text是存在字符数组(char *)中的,在解析的时候利用指针逐字符判断当前数据的类型,根据该类型进入相应的分支解析数据;接着只要调用cJSON_GetObjectItem就可以获取指定名字的结点。
cJSON *root_parse = cJSON_Parse(JSON_data);
cJSON *format = cJSON_GetObjectItem(root_parse,"format");
char *name = cJSON_GetObjectItem(root_parse, "name")->valuestring;
char *type = cJSON_GetObjectItem(format, "type")->valuestring;
int width = cJSON_GetObjectItem(format, "width")->valueint;
int height = cJSON_GetObjectItem(format, "height")->valueint;
int interlace = cJSON_GetObjectItem(format, "interlace")->valueint;
int framerate = cJSON_GetObjectItem(format,"frame rate")->valueint;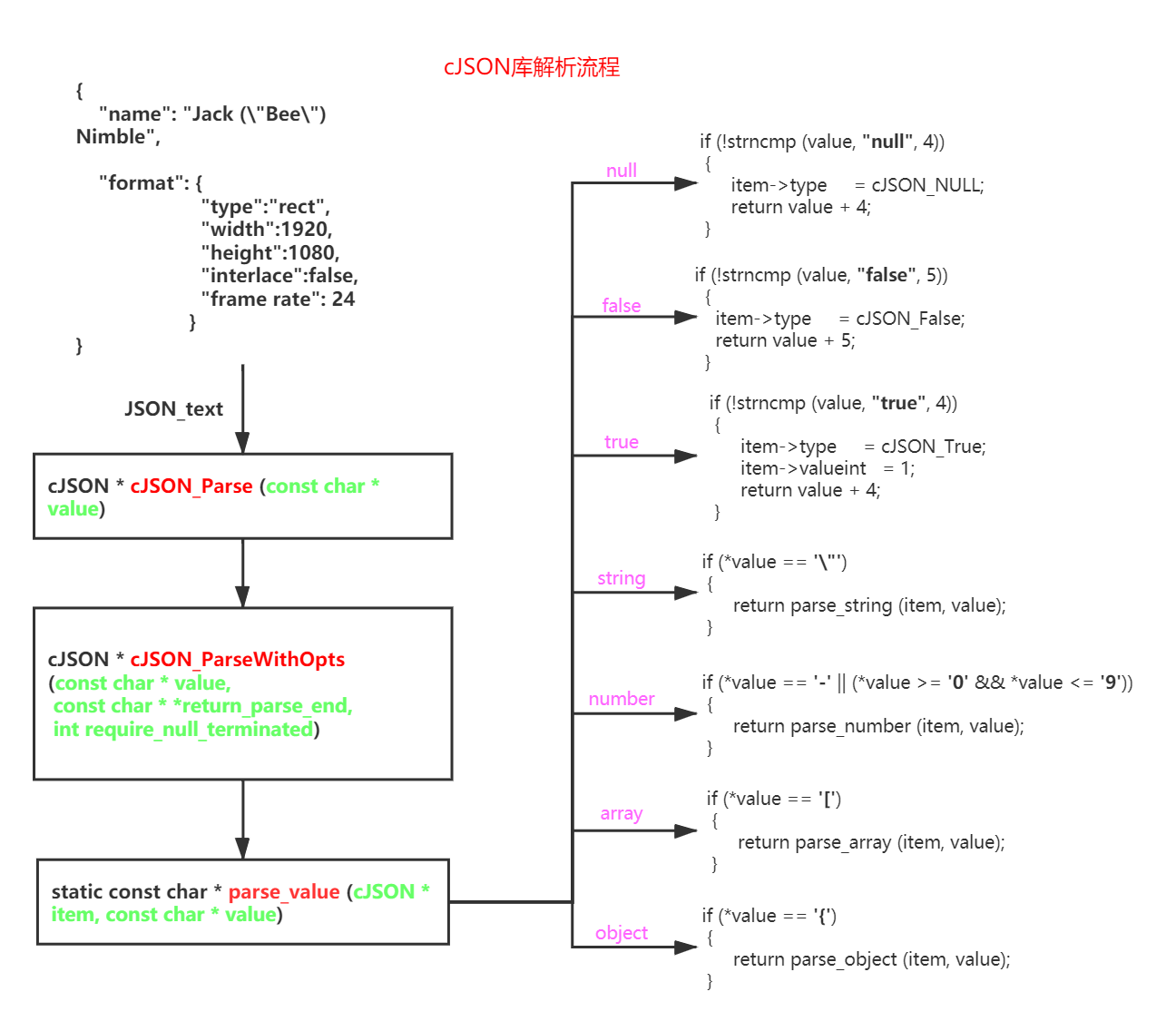
图2 cJSON_parse 函数执行流程
由于null,false,true类型的数据解析简单,这里主要介绍string、number、array、object的解析,源码就不贴了,可以在源文件中找到对应函数来看。
parse_string:初始化两个指针,一个指向源字符数组,另一个指向存放解析后字符的目标数组,基本原理是遍历源字符数组,如果是合法字符则拷贝到目标数组,否则做相应处理。其复杂性在于要处理各种转义字符,特别是编码的转换;
parse_number:基本原理是将ASCII值转十进制,同时考虑浮点数和科学计数法的情况;
parse_array:将同一层结点解析成双向链表,该函数主要是递归调用了parse_value这个函数;
parse_object:该函数也是主要递归调用了parse_value这个函数,以此解析对象数据。
至此,cJSON库的核心功能差不多这些了,其他的细节以及值得学习借鉴的技术有待日后琢磨总结,最后看一下cJSON库生成和解析JSON数据的效果。
generate JSON data:
{
"name": "Jack ("Bee") Nimble",
"format": {
"type": "rect",
"width": 1920,
"height": 1080,
"interlace": false,
"frame rate": 24
}
}
JSON parse result:
name: Jack ("Bee") Nimble
type: rect
width: 1920
height: 1080
interlace: 0
framerate: 24
最后
以上就是漂亮哑铃最近收集整理的关于cJSON 源码分析的全部内容,更多相关cJSON内容请搜索靠谱客的其他文章。








发表评论 取消回复