标题
- 1.需求分析
- 2.数据准备
- 3.代码思路
- 4.代码
1.需求分析
在互联网中,我们经常会见到城市热点图这样的报表数据,例如在百度统计中,会统计今年的热门旅游城市、热门报考学校等,会将这样的信息显示在热点图中。我们根据每个用户的IP地址,与我们的IP地址段进行比较,确认每个IP落在哪一个IP端内,获取经纬度,然后绘制热力图
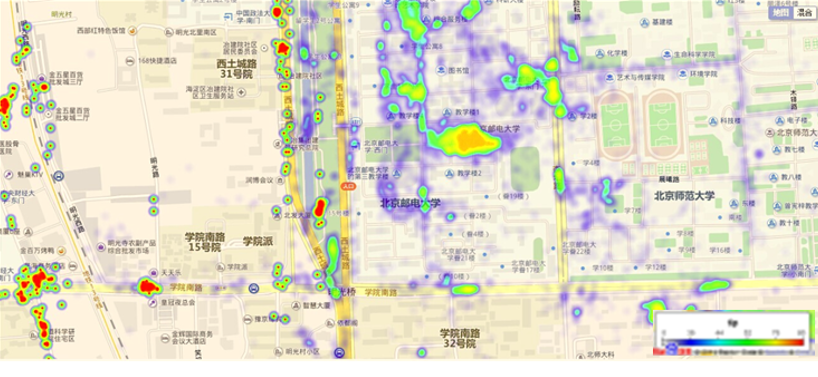
我们需要通过日志信息(运行商或者网站自己生成)和城市ip段信息来判断用户的ip段,统计热点经纬度。
2.数据准备
ip日志信息:
在ip日志信息中,只需要关心ip这一个维度就可以了

城市ip段信息:
第一第二字段分别为:ip地址的起始与结束
第三第四字段分别对应:ip始末解析为数字后的结果
最后两个字段分别对应经度,纬度
此次我们需要关心的是3,4,和最后两个字段

创建数据库:
用于对结果进行存储
CREATE DATABASE `spark`;
USE `spark`;
DROP TABLE IF EXISTS `iplocation`;
CREATE TABLE `iplocation` (
`longitude` varchar(32) DEFAULT NULL,
`latitude` varchar(32) DEFAULT NULL,
`total_count` varchar(32) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.代码思路
1、加载城市ip段信息,获取ip起始数字和结束数字,经度,维度
2、 加载日志数据,获取ip信息,然后转换为数字,和ip段比较
3、 比较的时候采用二分法查找,找到对应的经度和维度
4、 然后对经度和维度做单词计数
4.代码
package cn.itcast.rdd
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
//todo:利用spark实现ip地址查询
object Iplocation {
//将ip地址转换为Long类型 192.168.200.100
def ip2Long(ip: String): Long = {
val ips: Array[String] = ip.split("\.")
var ipNum:Long=0L
//遍历数组
for(i <- ips){
ipNum=i.toLong | ipNum << 8L
}
ipNum
}
//利用二分查询,找到long类型数字在数组中的下标 ip开始数字 ip结束数字 经度 维度
def binarySearch(ipNum: Long, broadcastValue: Array[(String, String, String, String)]): Int ={
var start=0
var end=broadcastValue.length-1
while(start <=end){
val middle=(start+end)/2
if(ipNum >=broadcastValue(middle)._1.toLong && ipNum <=broadcastValue(middle)._2.toLong){
return middle
}
if(ipNum < broadcastValue(middle)._1.toLong){
end=middle-1
}
if(ipNum > broadcastValue(middle)._2.toLong){
start=middle+1
}
}
-1
}
//将数据写入到mysql表中
val data2Mysql=(iter:Iterator[((String, String), Int)]) =>{
//创建数据库连接
var conn:Connection=null
//创建PreparedStatement
var ps:PreparedStatement=null
//sql语句 ?表示占位符
val sql="insert into iplocation(longitude,latitude,total_count) values(?,?,?)"
try {
//构建连接
conn = DriverManager.getConnection("jdbc:mysql:///spark?serverTimezone=GMT%2B8&useSSL=false","root","123456")
ps = conn.prepareStatement(sql)
//遍历迭代器
iter.foreach(line => {
//给?赋值
ps.setString(1, line._1._1)
ps.setString(2, line._1._2)
ps.setLong(3, line._2)
//执行sql语句
ps.execute()
})
}catch {
case e:Exception =>println(e)
}finally {
//关闭数据库连接
if(ps!=null){
ps.close()
}
if(conn!=null){
conn.close()
}
}
}
def main(args: Array[String]): Unit = {
//1、创建SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("Iplocation").setMaster("local[2]")
//2、创建SparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//3、读取城市ip信息日志数据,获取(ip开始数字、结束数字、经度、维度)
val city_ips: RDD[(String, String, String, String)] = sc.textFile("H:\大数据实时资料\3、Spark\2、spark第二天教案文档\资料\服务器访问日志根据ip地址查找区域\用户ip上网记录以及ip字典\ip.txt").map(x=>x.split("\|")).map(x=>(x(2),x(3),x(x.length-2),x(x.length-1)))
//把城市ip信息数据通过广播变量下发到每一个worker节点
val broadcastIps: Broadcast[Array[(String, String, String, String)]] = sc.broadcast(city_ips.collect())
//4、读取运营商日志数据,获取所有的ip地址
val ips: RDD[String] = sc.textFile("H:\大数据实时资料\3、Spark\2、spark第二天教案文档\资料\服务器访问日志根据ip地址查找区域\用户ip上网记录以及ip字典\20090121000132.394251.http.format").map(x=>x.split("\|")(1))
//5、遍历运营商日志数据,获取每一个ip地址,然后去广播变量中去匹配,获取当前ip地址对应经纬度
val result: RDD[((String, String), Int)] = ips.mapPartitions(iter => {
// 获取广播变量中的值
val broadcastValue: Array[(String, String, String, String)] = broadcastIps.value
//遍历迭代器,获取每一个ip地址
iter.map(ip => {
//把ip地址转换成long类型数字
val ipNum: Long = ip2Long(ip)
//拿到long类型的数字去广播变量值中去匹配,获取对应下标 用到二分查询
val index: Int = binarySearch(ipNum, broadcastValue)
//返回结果数据 ((经度,维度),1)
((broadcastValue(index)._3, broadcastValue(index)._4), 1)
})
})
//6、统计相同经度和维度出现总次数
val finalResult: RDD[((String, String), Int)] = result.reduceByKey(_+_)
//7、打印输出
finalResult.foreach(println)
// 把结果数据写入到mysql表中
finalResult.foreachPartition(data2Mysql)
//8、关闭sc
sc.stop()
}
}
运行结果:
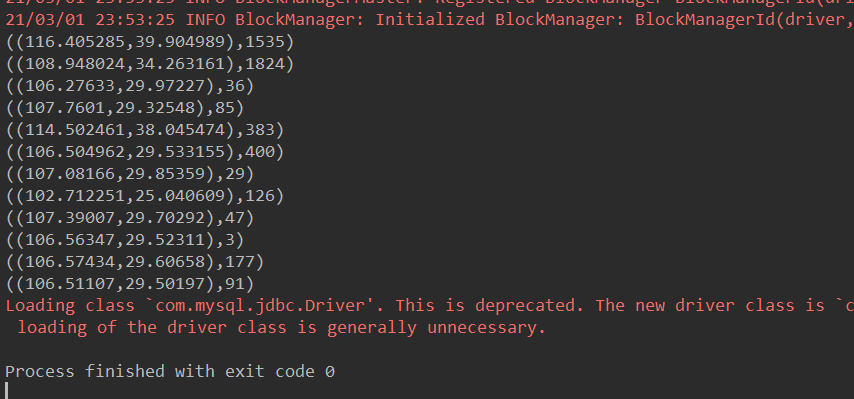
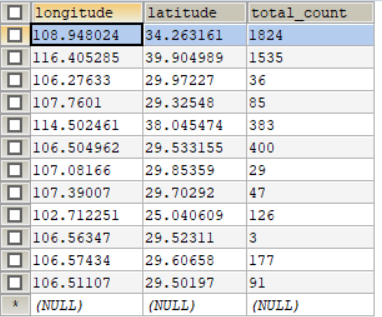
数据库:
最后
以上就是积极小蝴蝶最近收集整理的关于Spark_通过Spark实现ip地址查询的全部内容,更多相关Spark_通过Spark实现ip地址查询内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。






![[看图说话] 基于Spark UI性能优化与调试——初级篇](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)

发表评论 取消回复