
点击蓝字关注我们
MySQL8.0.19里面推出了一个新功能,InnoDB ReplicaSet,我暂且管它叫做叫做复制集。那么这个复制集是做什么用的呢?为何要推出这样一款产品呢?它将如何使用呢?这篇文章里我将会简单的介绍一下它。
InnoDB ReplicaSet由一个主节点和多个从节点组成,与传统主从复制的主从节点非常类似,所有的节点必须基于GTID,并且数据复制采用异步的方式。通过使用MySQL Shell的AdminAPI和ReplicaSet对象,用户可以像配置InnoDB Cluster那样非常简单地去搭建一主多从的复制架构。此外,使用复制集还可以接管既有的主从复制,但是需要注意,一旦被接管,只能通过AdminAPI对其进行管理。
为何要推出这样一款产品呢?首先,使用它可以非常容易的配置传统的主从复制,适用于一些对高可用性要求不高的场景,可用性要求高的情况下,还是推荐使用InnoDB Cluster。其次,该操作是集成在AdminAPI里面的,由MySQL Shell提供,如果大家看过我以前说过的InnoDB Cluster的发展路线图,会发现InnoDB Cluster的发展路线图里包括自动扩展数据读取,多个副本从集群中复制出来供应用程序使用,结合InnoDB Cluster的三个组件 MGR、MySQL Router和MySQL Shell来整体考虑,未来,复制集应该是自动读取扩展的一部分。从这一点来看,应该能够解释,为何要推出这样一款采用异步复制的HA较低的产品了。
如何使用呢?使用起来也非常简单,我按照手册上的例子执行了一遍,感兴趣的话,您也可以亲自试一试。
我的实验是在一台主机上做的,配置了两个实例,端口分别为3310和3320。另外需要安装最新的MySQL Shell 8.0.19
初始化两台实例之后,使用shell分别连接两台实例,进行简单的配置。
mysql-js> connect root@192.168.56.10:3310
连接后执行dba.configureReplicaSetInstance() 对其进行配置,在这里需要设置一个用于全部节点的账户(账户必须在全部节点上一致)
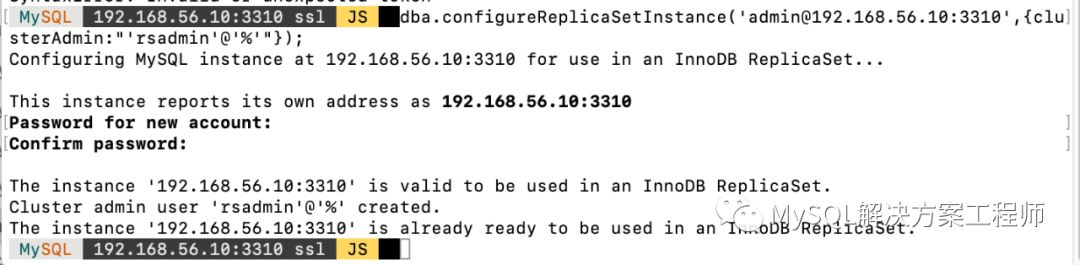
之后,使用dba.createReplicaSet() 创建复制集:
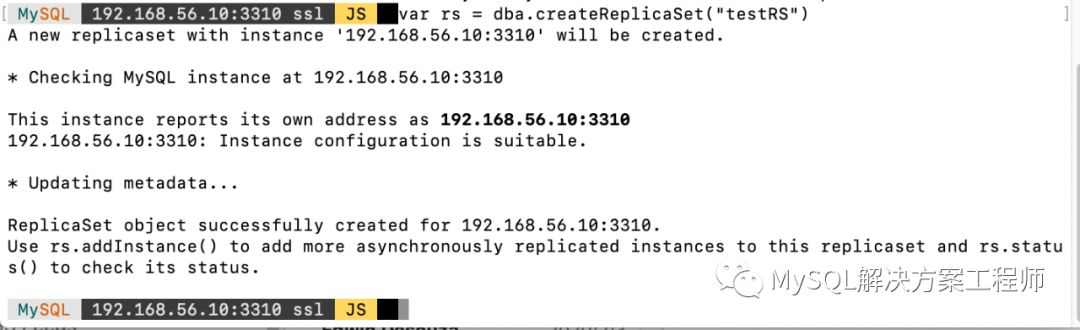
创建好了以后,可以通过ReplicaSet.status()查看复制集的状态:
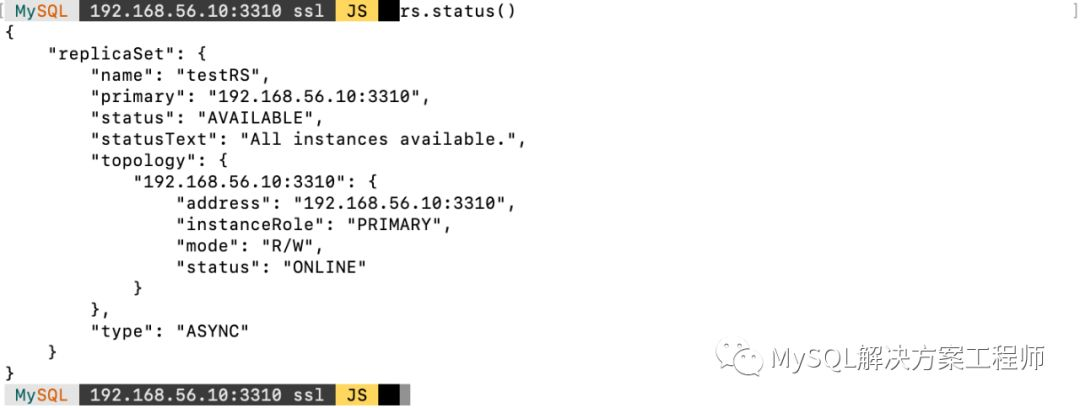
接下来,在第二个节点上同样执行配置操作,然后执行加入复制集操作。

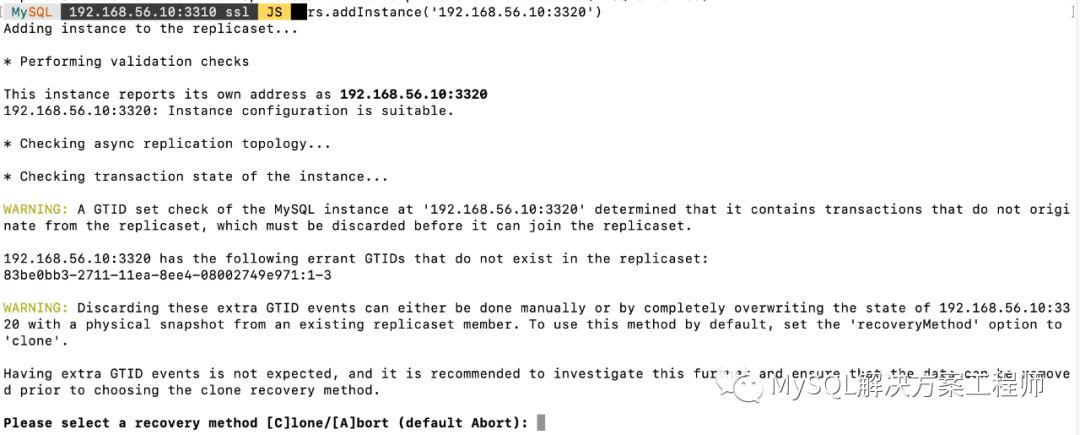
执行加入复制集操作后,会提示使用哪种方式进行数据恢复(克隆或增量),由于我的两台节点数据不一致,我选用的克隆方式,此方式会将从节点上的数据完全删除。
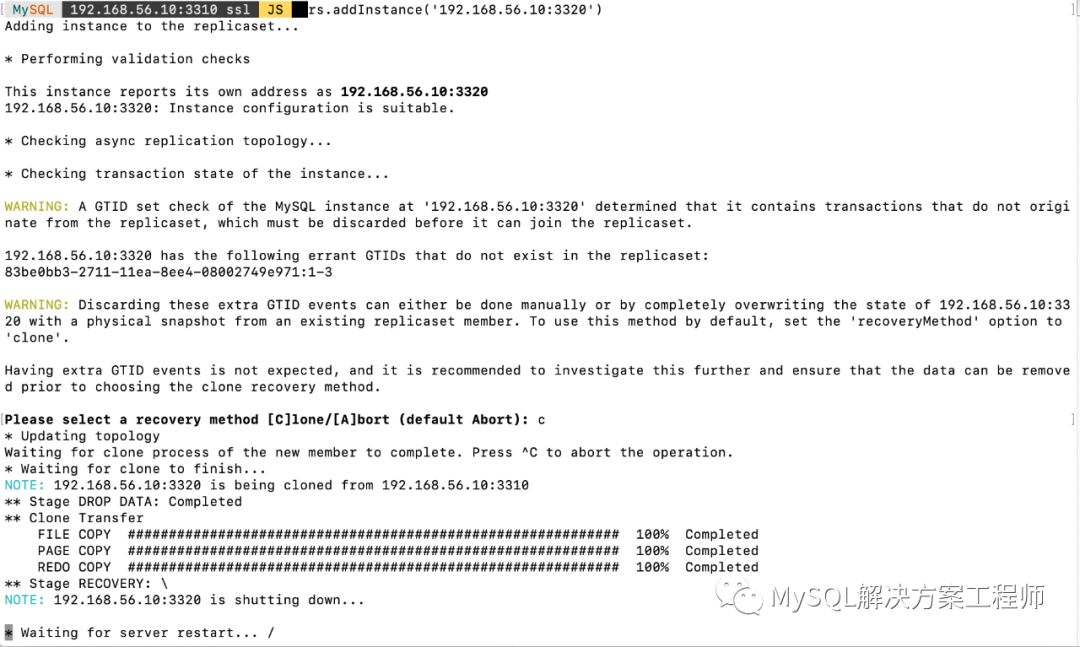
克隆完毕,重启之后,再次查看复制集状态:
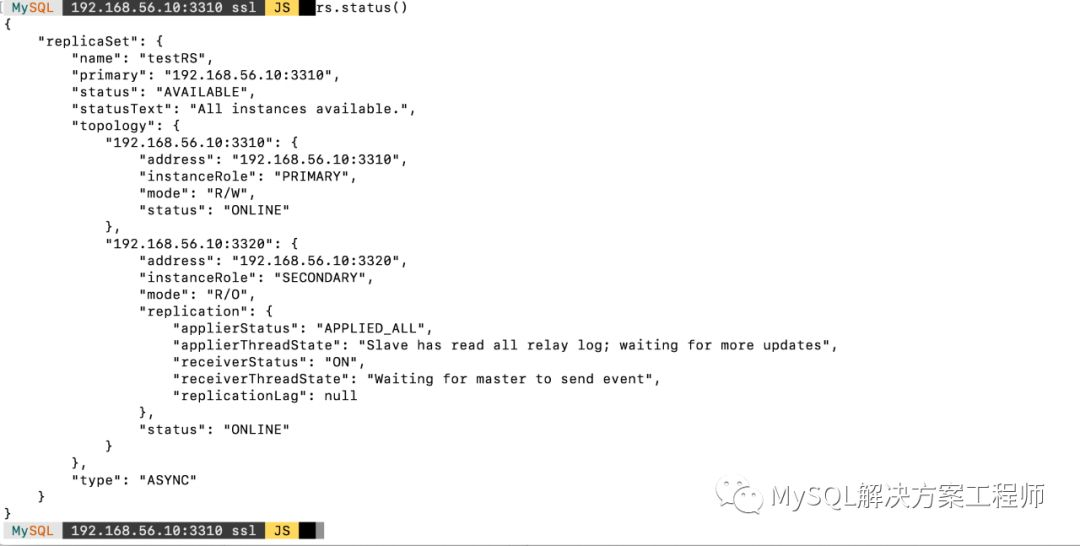
复制集已经搭建好了,接下来就可以按照平时的操作对MySQL进行操作了,数据会从主节点异步复制到从节点上。
关于复制集的介绍就到这里,更为详尽的内容请访问“https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-replicasets.html”
欢迎大家试用并提出反馈!
叶老师新课程《MySQL性能优化》已经在腾讯课堂发布,本课程讲解读几个MySQL性能优化的核心要素:合理利用索引,降低锁影响,提高事务并发度。下面是报名小程序码,厚着脸皮请求大家推荐给需要的小伙伴们。

下面是本课程内容目录
扫码加入MySQL技术Q群
(群号:650149401)

点“在看”给我一朵小黄花![]()

最后
以上就是迷人缘分最近收集整理的关于MySQL8.0.19的InnoDB ReplicaSet的全部内容,更多相关MySQL8.0.19的InnoDB内容请搜索靠谱客的其他文章。








发表评论 取消回复