文章目录
- 前言
- 从集合读取数据
- 从文件读取数据
- 从socket读取数据
- 从kafka读取数据
- 自定义Source
- sink到kafka
- sink到redis
- sink到Elasticsearch
- jdbc自定义
前言
flink中提供了很多种数据源,有基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
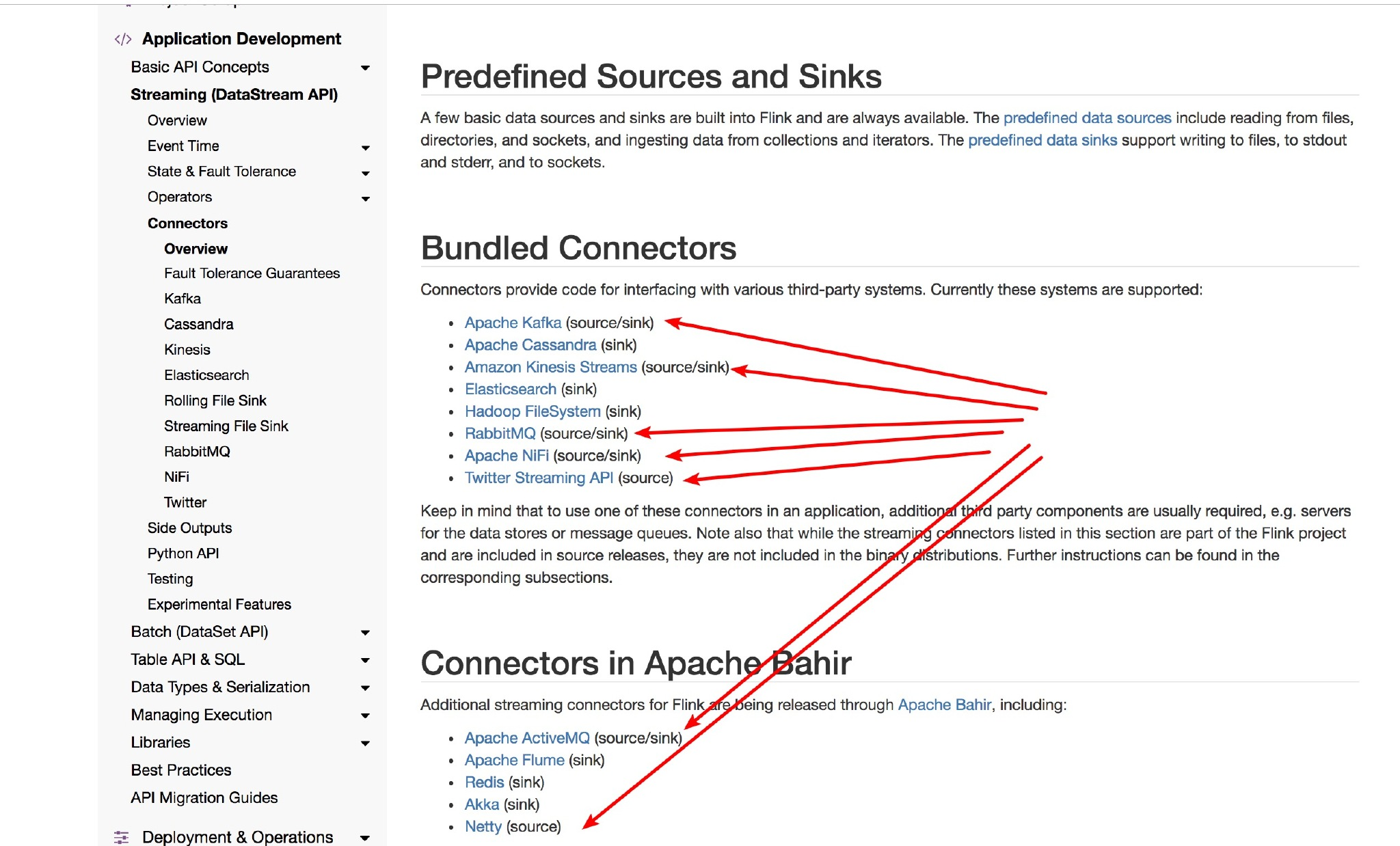
Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 Sink。
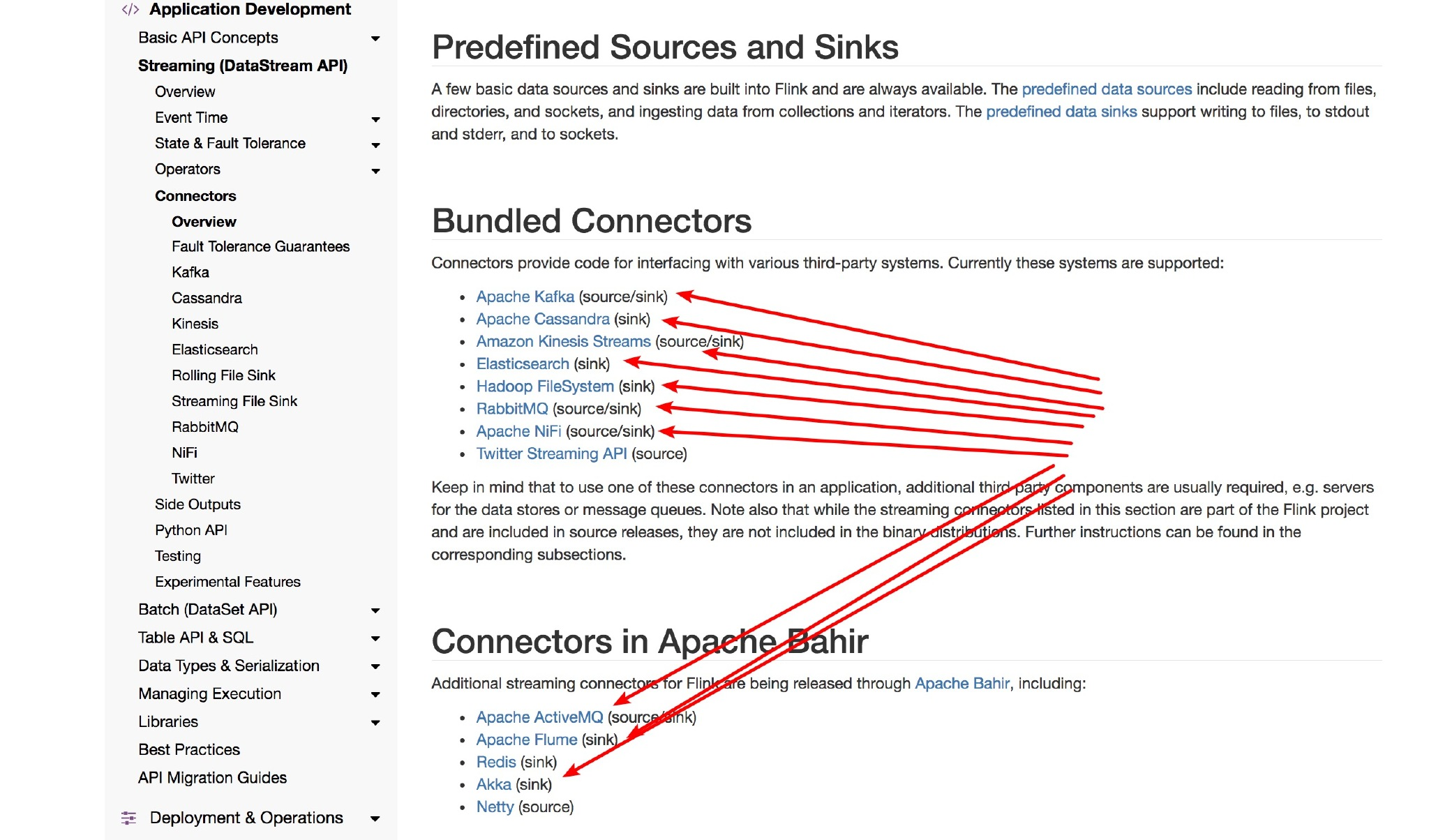
自定义sink需要继承RichSinkFunction 类,主要实现open、invoke、close三个方法。open主要是一些连接,invoke主要是插入逻辑,close是关闭。比如sink to mysql,open建立连接,invoke具体写执行逻辑,close关闭连接。
从集合读取数据
- fromCollection(Collection) - 从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
- fromCollection(Iterator, Class) - 从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
- fromElements(T …) - 从给定的对象序列中创建数据流。所有对象类型必须相同。
- fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
- fromSequence(from, to) - 创建一个生成指定区间范围内的数字序列的并行数据流。
package source; import bean.SensorReading; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Arrays; /** * Created with IntelliJ IDEA. * * @Author: yingtian * @Date: 2021/05/10/16:36 * @Description: 从集合中读取数据 */ public class SourceTest1_Collection { public static void main(String[] args) throws Exception{ //创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // Source: 从集合Collection中获取数据 DataStream<SensorReading> dataStream = env.fromCollection( Arrays.asList( new SensorReading("sensor_1", 1547718199L, 35.8), new SensorReading("sensor_6", 1547718201L, 15.4), new SensorReading("sensor_7", 1547718202L, 6.7), new SensorReading("sensor_10", 1547718205L, 38.1) ) ); //元素类型必须相同 DataStream<Integer> intStream = env.fromElements(1,2,3,4,5,6,7,8,9); //生成区间 输出10、11、12、13、14、15 DataStreamSource<Long> longStream = env.fromSequence(10, 15); //打印 dataStream.print("sensorReading"); intStream.print("int"); longStream.print("long"); //执行程序 env.execute(); } }
从文件读取数据
-
readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。
-
readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。
-
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)
这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
实现:
在具体实现上,Flink 把文件读取过程分为两个子任务,即目录监控和数据读取。每个子任务都由单独的实体实现。目录监控由单个非并行(并行度为1)的任务执行,而数据读取由并行运行的多个任务执行。后者的并行性等于作业的并行性。单个目录监控任务的作用是扫描目录(根据 watchType 定期扫描或仅扫描一次),查找要处理的文件并把文件分割成切分片(splits),然后将这些切分片分配给下游 reader。reader 负责读取数据。每个切分片只能由一个 reader 读取,但一个 reader 可以逐个读取多个切分片。
重要注意:
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,则当文件被修改时,其内容将被重新处理。这会打破“exactly-once”语义,因为在文件末尾附加数据将导致其所有内容被重新处理。
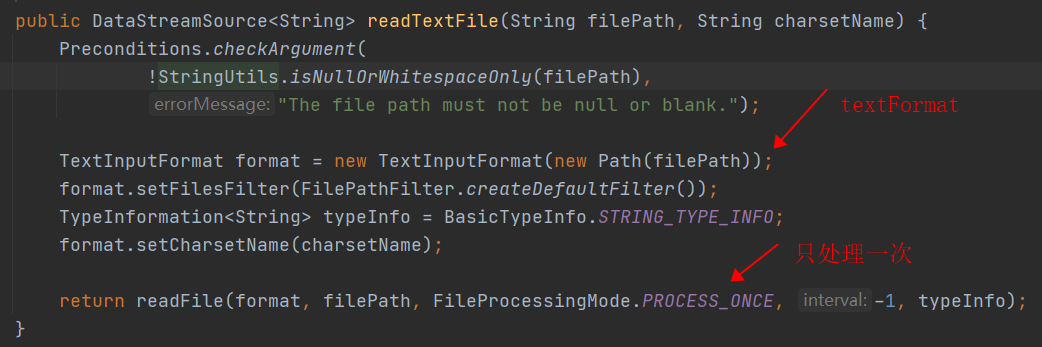
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,则 source 仅扫描路径一次然后退出,而不等待 reader 完成文件内容的读取。当然 reader 会继续阅读,直到读取所有的文件内容。关闭 source 后就不会再有检查点。这可能导致节点故障后的恢复速度较慢,因为该作业将从最后一个检查点恢复读取。package source; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import wc.WordCountSet; /** * Created with IntelliJ IDEA. * * @Author: yingtian * @Date: 2021/05/10/16:54 * @Description: 从文件中获取数据 */ public class SourceTest2_File { public static void main(String[] args) throws Exception{ //创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //从文件中读取数据 String inputPath = WordCountSet.class.getClassLoader().getResource("sensor.txt").getFile(); DataStreamSource<String> textStream = env.readTextFile(inputPath); textStream.print(); //执行程序 env.execute(); } }readTextFile方法内部调用:
从socket读取数据
-
socketTextStream(host,port):从指定ip和端口获取数据
底层调用socketTextStream(hostname, port, delimiter, 0)方法package wc; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * Created with IntelliJ IDEA. * * @Author: yingtian * @Date: 2021/04/29/15:09 * @Description: 监听socket数据,测试流 */ public class WordCountSocketStream { public static void main(String[] args) throws Exception { //创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //读取配置 ParameterTool config = ParameterTool.fromArgs(args); String host = config.get("host"); int port = Integer.parseInt(config.get("port")); //创建socket流 DataStreamSource<String> socketStream = env.socketTextStream(host, port); // 对数据集进行处理,按空格分词展开,转换成(word, 1)二元组进行统计 SingleOutputStreamOperator<Tuple2<String, Integer>> resultStream = socketStream.flatMap(new MyFlatMapper()).setParallelism(2) .keyBy(item -> item.f0) // 按照第一个位置的word分组 .sum(1);// 按照第二个位置上的数据求和 //打印输出 resultStream.print("socket"); env.execute(); } public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String,Integer>> { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] arr = line.split(" "); for(String str : arr){ collector.collect(new Tuple2<>(str,1)); } } } }
从kafka读取数据
pom文件中添加flink-kafka的jar包
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
package source;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
/**
* Created with IntelliJ IDEA.
*
* @Author: yingtian
* @Date: 2021/05/10/17:35
* @Description: 从kafka获取数据
*/
public class SourceTest3_Kafka {
public static void main(String[] args) throws Exception{
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度1
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//获取kafka的consumer 默认从当前位置消费
FlinkKafkaConsumer<String> sensor = new FlinkKafkaConsumer<>("sensor", new SimpleStringSchema(), properties);
//从头开始消费
// sensor.setStartFromEarliest();
//从最新位置开始消费
// sensor.setStartFromLatest();
// flink添加外部数据源
DataStream<String> dataStream = env.addSource(sensor);
// 打印输出
dataStream.print();
env.execute();
}
}
自定义Source
flink支持自定义source,只需要实现SourceFunction接口。
package source;
import bean.SensorReading;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.HashMap;
import java.util.Random;
/**
* Created with IntelliJ IDEA.
*
* @Author: yingtian
* @Date: 2021/05/10/18:19
* @Description: 自定义source
*/
public class SourceTest4_UDF {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<SensorReading> dataStream = env.addSource(new MySensorSource());
//打印输出
dataStream.print();
env.execute();
}
// 实现自定义的SourceFunction
public static class MySensorSource implements SourceFunction<SensorReading> {
// 标示位,控制数据产生
private volatile boolean running = true;
@Override
public void run(SourceContext<SensorReading> ctx) throws Exception {
//定义一个随机数发生器
Random random = new Random();
// 设置10个传感器的初始温度
HashMap<String, Double> sensorTempMap = new HashMap<>();
for (int i = 0; i < 10; ++i) {
sensorTempMap.put("sensor_" + (i + 1), 60 + random.nextGaussian() * 20);
}
while (running) {
for (String sensorId : sensorTempMap.keySet()) {
// 在当前温度基础上随机波动
Double newTemp = sensorTempMap.get(sensorId) + random.nextGaussian();
sensorTempMap.put(sensorId, newTemp);
ctx.collect(new SensorReading(sensorId,System.currentTimeMillis(),newTemp));
}
// 控制输出评率
Thread.sleep(2000L);
}
}
@Override
public void cancel() {
this.running = false;
}
}
}
sink到kafka
// 将数据写入Kafka
dataStream.addSink( new FlinkKafkaProducer<String>("localhost:9092", "sinktest", new SimpleStringSchema()));
sink到redis
pom.xml
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
// 定义jedis连接配置(我这里连接的是docker的redis)
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("localhost")
.setPort(6379)
.setPassword("123456")
.setDatabase(0)
.build();
dataStream.addSink(new RedisSink<>(config, new MyRedisMapper()));
自定义RedisMapper
public static class MyRedisMapper implements RedisMapper<SensorReading> {
// 定义保存数据到redis的命令,存成Hash表,hset sensor_temp id temperature
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "sensor_temp");
}
@Override
public String getKeyFromData(SensorReading data) {
return data.getId();
}
@Override
public String getValueFromData(SensorReading data) {
return data.getTemperature().toString();
}
}
sink到Elasticsearch
pom.xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_2.12</artifactId>
<version>1.12.1</version>
</dependency>
// 定义es的连接配置
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("localhost", 9200));
dataStream.addSink( new ElasticsearchSink.Builder<SensorReading>(httpHosts, new MyEsSinkFunction()).build());
实现自定义的ES写入操作
public static class MyEsSinkFunction implements ElasticsearchSinkFunction<SensorReading> {
@Override
public void process(SensorReading element, RuntimeContext ctx, RequestIndexer indexer) {
// 定义写入的数据source
HashMap<String, String> dataSource = new HashMap<>();
dataSource.put("id", element.getId());
dataSource.put("temp", element.getTemperature().toString());
dataSource.put("ts", element.getTimestamp().toString());
// 创建请求,作为向es发起的写入命令(ES7统一type就是_doc,不再允许指定type)
IndexRequest indexRequest = Requests.indexRequest()
.index("sensor")
.source(dataSource);
// 用index发送请求
indexer.add(indexRequest);
}
}
jdbc自定义
pom.xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
// 实现自定义的SinkFunction
public static class MyJdbcSink extends RichSinkFunction<SensorReading> {
// 声明连接和预编译语句
Connection connection = null;
PreparedStatement insertStmt = null;
PreparedStatement updateStmt = null;
@Override
public void open(Configuration parameters) throws Exception {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/flink_test?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&useSSL=false", "root", "example");
insertStmt = connection.prepareStatement("insert into sensor_temp (id, temp) values (?, ?)");
updateStmt = connection.prepareStatement("update sensor_temp set temp = ? where id = ?");
}
// 每来一条数据,调用连接,执行sql
@Override
public void invoke(SensorReading value, Context context) throws Exception {
// 直接执行更新语句,如果没有更新那么就插入
updateStmt.setDouble(1, value.getTemperature());
updateStmt.setString(2, value.getId());
updateStmt.execute();
if (updateStmt.getUpdateCount() == 0) {
insertStmt.setString(1, value.getId());
insertStmt.setDouble(2, value.getTemperature());
insertStmt.execute();
}
}
@Override
public void close() throws Exception {
insertStmt.close();
updateStmt.close();
connection.close();
}
}
ps:以上内容整理于SGG教程。
最后
以上就是还单身世界最近收集整理的关于Flink学习笔记(4)——source and sink前言从集合读取数据从文件读取数据从socket读取数据从kafka读取数据自定义Sourcesink到kafkasink到redissink到Elasticsearchjdbc自定义的全部内容,更多相关Flink学习笔记(4)——source内容请搜索靠谱客的其他文章。


![#C语言[Basic I/O] Converting feet into meters](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)





发表评论 取消回复