DOM接口和XML的关系模型
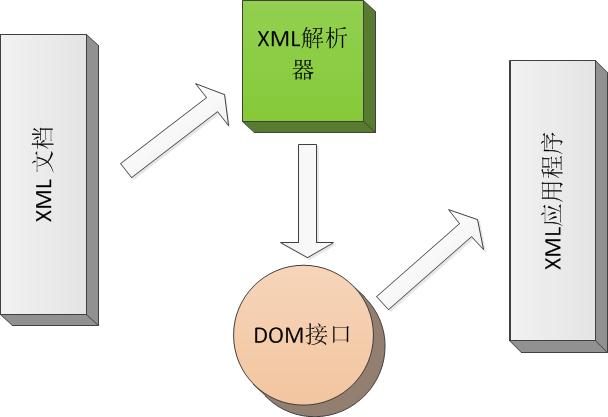
W3C制定了一套书写XML分析器的标准接口规范—DOM。下面我们来看看DOM在应用程序开发过程中和XML文档的关系模型示意图。从图中我们可以看出,应用程序不是直接对XML文档进行操作的,而是首先由XML分析器对XML文档进行分析,然后,应用程序通过对XML分析器所提供的DOM接口对分析结果进行操作,从而间接地实现对XML文档的访问。Java中DOM接口
在DOM接口规范中,有四个基本接口:Document,Node,NodeList以及NameNodeMap。在这四个接口中,Document接口是对文档进行操作的入口,它是从Node接口继续过来的。Node接口是其它接口的父类,像Document,Element,Attribute,Text ,comment 等接口都是从Node类接口继承过来的。NodeList 接口是一个节点的集合,它包含了某个节点中的子节点。NameNodeMap 接口也是一个节点的集合。通过该接口,可以建立节点和节点之间的一一映射关系,从而利用节点可以直接访问特定的节点。下面我们来具体了解一下,在Java DOM 解析一个XML文档时常用的类
解析器工厂类:DocumentBuilderFactory 创建一个解析器工厂对象:DocumentBuilderFactory dbf =
DocumentBuilderFactory.newInstance();解析器类:DocumentBuilder 通过解析器工厂类来获得 DocumentBuilder db = dbf.newDocumentBuilder();
XML 文档对象类:Document 通过xml文档 Document doc = db.parse(new File(“xml15.xml”));
注: Document对象代表了一个XML文档的模型树,所有的其他Node都以一定的顺序包含在Document对象之内,排列成一个树状结构,以后对XML文档的所有操作都与解析器无关,
节点类Node
Node对象是DOM中最基本的对象,代表了文档树中的抽象节点。但在实际使用中很少会直接使用Node对象,而是使用Node接口的实现类 Document,Element,Attribute,Text ,comment等。
Java中Dom解析XML的递归实现
package com.ywendeng.java.demo;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Attr;
import org.w3c.dom.Comment;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.Element;
//用递归的方式解析给定的任意一个XML文档 ,并将其输出到命令行上
public class Jaxp {
public static void main(String[] args) throws Exception {
DocumentBuilderFactory
dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder
db=dbf.newDocumentBuilder();
Document doc=db.parse(new File("xml15.xml"));
//获得根元素节点
Element
root=doc.getDocumentElement();
parseElement(root);
}
private
static void parseElement(Element element){
//元素的名字
String tagName=element.getNodeName();
//获取该元素的所有子元素构成的节点
NodeList childre=element.getChildNodes();
System.out.print("<"+tagName);
//element 元素的所有属性所构成的NameNodeMap 对象
NamedNodeMap
nMap=element.getAttributes();
//如果该元素存在属性
if(nMap!=null){
for(int i=0;i<nMap.getLength();i++){
//获得该元素的每一个属性
Attr
attr=(Attr)nMap.item(i);
String
attrName=attr.getName();
String
attrValue=attr.getValue();
System.out.print(" "+ attrName+"=""+attrValue+""");
}
}
System.out.print(">");
for(int i=0;i<childre.getLength();i++){
Node
node=childre.item(i);
//获得节点的类型
short nodeType=node.getNodeType();
if(nodeType==node.ELEMENT_NODE){
//是元素
继续递归
parseElement((Element)node);
}
else if(nodeType==node.TEXT_NODE){
//是递归的出口
System.out.print(node.getNodeValue());
}else if(nodeType==node.COMMENT_NODE){
System.out.print("<!--");
Comment
comment =(Comment)node;
//注释内容
String data=comment.getData();
System.out.println(data);
System.out.print("-->");
}
}
System.out.print("</"+tagName+">");
}
}
最后
以上就是壮观板凳最近收集整理的关于Java 中DOM解析XML的递归实现的全部内容,更多相关Java内容请搜索靠谱客的其他文章。








发表评论 取消回复