一、 基础知识
1.1 数据仓库基本模型:星型模型(面向主题)、雪花模型
Hive数据仓库:是建立在Hadoop HDFS上的数据仓库基础框架,ELT,HQL
Hive的体系结构:hive将元数据存储在数据库中,用 HDFS存储数据,用MapReduce进行计算。
HQL执行过程:解析器、编译器、优化器
1.2 Hive架构与基本组成:
基本组成
•用户接口,包括 CLI,JDBC/ODBC,WebUI
•元数据存储,通常是存储在关系数据库如 mysql, derby 中
•解释器、编译器、优化器、执行器
•Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
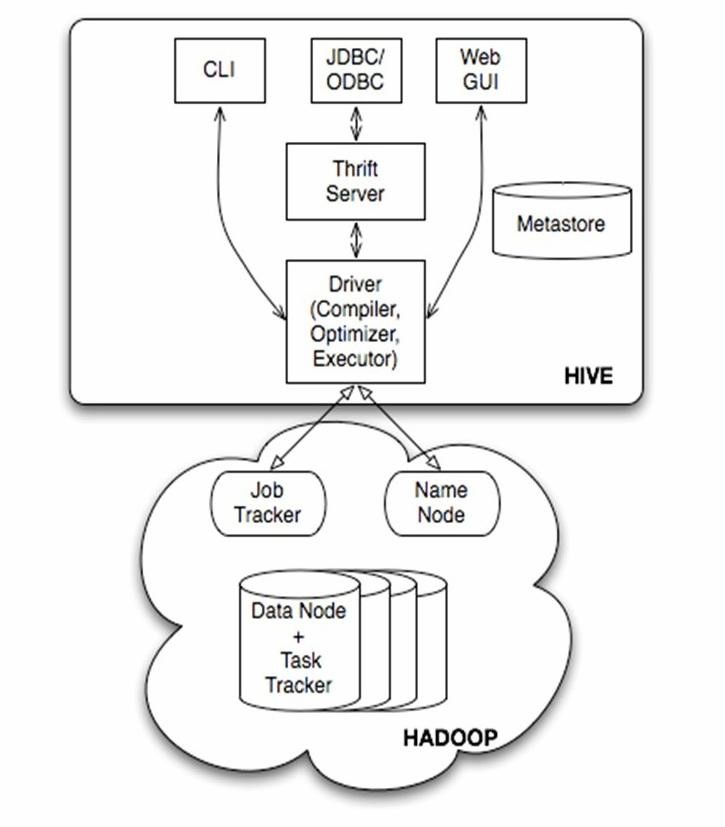
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor),这些组件我可以分为两大类:服务端组件和客户端组件。
首先讲讲服务端组件:
Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
Metastore组件:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据 库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性,这个方面的知识,我会在后面的metastore小节里做详细的讲解。
Thrift服务:thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
客户端组件:
CLI:command line interface,命令行接口。
Thrift客户端:上面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
WEBGUI:hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive webinterface),使用前要启动hwi服务。
1.3 HiveUI介绍
启动UI
•配置
•hive-site.xml 添加
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-0.8.1.war</value>
•启动Hive的UI sh $HIVE_HOME/bin/hive –service hwi
二、 HIVE的安装
下载路径:hive.apache.org
三、 常用的CLI命令
1、清屏:ctl+L或者!clear回车后加;
2、查看表的信息:show tables;
3、查看数据仓库中内置的函数:show functions;
4、查看表结构:desc表名;
5、删除表:drop table if exists 表名;
6、查看HDFS上的文件:dfs -ls 目录;
dfs -lsr 目录;(递归的方式查看)
7、执行操作系统的命令:!命令;
8、静默模式:hive –s;
9、操作系统中直接输:hive –e ‘show tables’;可直接执行
10、自动补全:如select,只要输入sel,然后按下tab键就可以自动补全命令。
11、查看当前工作目录:hive> ! pwd;
12、列举所有以字母h开头,以其他字符结尾的数据库名:hive>showdatabases like ‘h.*’;
13、将数据库设置为当前的工作数据库,和在文件系统中切换工作目录是一个概念:use 数据库名;
14、删除数据库并删除数据库中的表,要在删除命令最后加关键字cascade,这样可以使hive自行先删除数据库中的表:drop database if exists employee cascade;
15、查看表的详细表结构信息:describe extended employee;
16、查看表更多更详细的信息;describe formatted employee;
17、只看某一列:describe extended employee.name;
18、查看某个表信息:hive> ! cat employee.txt;
在Silent模式下将数据转储到指定的文件中并查询:
[hadoop@hadoop~]$ hive -S -e ‘show tables’ > a.txt
[hadoop@hadoop~]$ cat a.txt
19、查看所建数据表信息:hive> dfs -ls /user/hive/warehouse;
20、Linux下如何用命令查看当前目录下所有文件的大小,以行数和字节为单位:ls -l /ls -al或者像楼上说的直接 ll
21、linux下查找某个文件位置的方法:
[hadoop@master~]$ find -name user_infor.txt;
./user_infor.txt
或者是:[hadoop@master ~]$ locateuser_infor.txt;
/home/hadoop/user_infor.txt
四、 Hive基本命令整理
4.1 创建表:
1、创建表
hive> CREATE TABLE pokes (fooINT, bar STRING)
//Creates a table called pokeswith two columns, the first being an integer and the other a string
2、创建一个新表,结构与其他一样
hive> create table new_tablelike records;
3、创建分区表:
hive> create table logs(tsbigint,line string) partitioned by (dt String,country String);
4、加载分区表数据:
hive> load data local inpath’/home/hadoop/input/hive/partitions/file1’ into table logs partition(dt=’2001-01-01’,country=’GB’);
5、展示表中有多少分区:
hive> show partitions logs;
6、展示所有表:
hive> SHOW TABLES;
//lists all the tables
hive> SHOW TABLES ‘.*s’;
//lists all the table that endwith ‘s’. The pattern matching follows Java regular expressions.
7、显示表的结构信息
hive> DESCRIBE invites;
//shows the list of columns
8、更新表的名称:
hive> ALTER TABLE sourceRENAME TO target;
9、添加新一列:
hive> ALTER TABLE invites ADDCOLUMNS (new_col2 INT COMMENT ‘a comment’);
10、删除表:
hive> DROP TABLE records;
删除表中数据,但要保持表的结构定义
hive> dfs -rmr /user/hive/warehouse/records;
11、从本地文件加载数据:
hive> LOAD DATA LOCAL INPATH’/home/hadoop/input/ncdc/micro-tab/sample.txt’ OVERWRITE INTO TABLE records;
12、显示所有函数:
hive> show functions;
13、查看函数用法:
hive> describe function substr;
14、查看数组、map、结构
hive> selectcol1[0],col2[‘b’],col3.c from complex;
15、内连接:
hive> SELECT sales.,things. FROM sales JOIN things ON (sales.id = things.id);
16、查看hive为某个查询使用多少个MapReduce作业
hive> Explain SELECT sales.,things. FROM sales JOIN things ON (sales.id = things.id);
17、外连接:
hive> SELECT sales.,things. FROM sales LEFT OUTER JOIN things ON (sales.id = things.id);
hive> SELECT sales., things. FROM sales RIGHTOUTER JOIN things ON (sales.id = things.id);
hive> SELECT sales., things. FROM salesFULL OUTER JOIN things ON (sales.id = things.id);
in查询:Hive不支持,但可以使用LEFT SEMI JOIN
hive> SELECT * FROM thingsLEFT SEMI JOIN sales ON (sales.id = things.id);
18、创建视图:
hive> CREATE VIEWvalid_records AS SELECT * FROM records2 WHERE temperature !=9999;
19、查看视图详细信息:
hive> DESCRIBE EXTENDEDvalid_records;
五、 Hive中数据的导入
Hive的几种常见的数据导入方式
这里介绍四种:
- 从本地文件系统中导入数据到Hive表;
a) 从外部将数据导入到本地文件中,如:将employee.txt导入到/home/hadoop文件夹下。
b) 在hive中创建表。
hive> create table table_employee
> (namestring,id int,address string)
> rowformat delimited
>fields terminated by 't'
stored as textfile;
c) 将本地文件导入到表中
hive> load data local inpath ‘employee.txt’ into tabletable_employee;
若显示路径无效,则找到’employee.txt’的路径,方法:
[hadoop@master~]$ find -name employee.txt;
./user_infor.txt
找到路径后再重新导入:hive> load data local inpath ‘./employee.txt’into table table_employee;
d) 在表的目录下查看
hadoopdfs –ls;
e) 进行检验,如表的查询
select *from table_employee;
从HDFS上导入数据到Hive表;
从别的表中查询出相应的数据并导入到Hive表中;
在创建表的时候通从别的表中查询出相应的记录并插入到所创建的表中。
六、 分区分桶
hive引入partition和bucket的概念,这两个概念都是把数据划分成块,分区是粗粒度的划分桶是细粒度的划分,这样做为了可以让查询发生在小范围的数据上以提高效率。
如表:
lyw 1 shanghai
ls 2 wuhan
hj 3 hangzhou
yj 4 wuhan
jg 5 nignbo
wyy 6 shenzhen
- 分区
a) hive中创建分区表没有什么复杂的分区类型(范围分区、列表分区、hash分区、混合分区等)。分区列也不是表中的一个实际的字段,而是一个或者多个伪列。意思是说在表的数据文件中实际上并不保存分区列的信息与数据。下面的语句创建了一个简单的分区表:
hive> create table table_friends
> (namestring,id int)partitioned by(year int)
> row formatdelimited
> fieldsterminated by ' '
(字段分隔符)
> stored astextfile;
(作为文本存储)
b) 描述分区表(describeextended )
describe extended table_friends;
c) 导入分区和数据
将数据导入,先创建好分区才能导入数据。这个例子中创建了year作为分区列,通常情况下需要先预先创建好分区,然后才能使用该分区。
hive> load datainpath
into table table_friends
partition(year=2015);
对于小数据量导入,可采取下面的语句来实现
insert intovalues()等价实现insert into table select …from limit 1;
- 分桶
分桶的目的:第一,获得更高的查询处理效率,桶为表加上了额外的结构,第二,取样更高效。
桶是更为细粒度的数据范围划分,它能使一些特定的查询效率更高,比如对于具有相同的桶划分并且jion的列刚好就是在桶里的连接查询,还有就是示例数据,对于一个庞大的数据集我们经常需要拿出来一小部分作为样例,然后在样例上验证我们的查询,优化我们的程序。
物理上,每个桶就是表目录里的一个文件。
创建带桶的表:
hive> create table bucket_employee(
> name string,
> id int,
> address string,
> date int) clusteredby (address) into 4 buckets;
导入数据到桶中:
hive> set hive.enforce.bucketing=true; //指令让Inceptor自动根据表的分桶填入数据,写入时,Inceptor会尽量均匀地将数据哈希进各个桶中。
hive> insert overwrite table bucket_employee
> select * fromemployee;
下面来看看利用bucket来对示例数据进行查询
—带桶的表
select * from bucketed_users
tablesample(bucket 1 out of 4 on id);
—不带桶的表
select * from users
tablesample(bucket 1 out of 4 on rand());
tablesample的作用就是让查询发生在一部分桶上而不是整个数据集上,上面就是查询4个桶里面第一个桶的数据,相对与不带桶的表这无疑是效率很高的,因为同样都是需要一小部分数据,但是不带桶的表需要使用rand()函数,需要在整个数据集上检索。
存储格式查询
describe formatted bucket_employee;
七、 Hive的元数据存储
存储方式与模式
Hive 将元数据存储在数据库中
连接到数据库模式有三种
单用户模式
多用户模式
远程服务器模式
八、 遇到的问题及解决方法
(一) 10.1.30.2上的mysql是mysql -u root -p123456
[hadoop@master ~]$ mysql -u root -p123456
回滚出错修改方法。
若要showtables;
先要showdatabases;
选择数据库 use 数据库名;
(二) 进入sqoop
(三)自己建的文件:
[root@transwarp1 ~]# su hdfs
bash-4.1$ hdfs dfs –ls
bash-4.1$ hdfs dfs -ls /
bash-4.1$ hdfs dfs -ls /user
hdfs dfs -ls /user/outputHive
(四)进入环境10.1.65.10
最后
以上就是踏实冥王星最近收集整理的关于hive的全部内容,更多相关hive内容请搜索靠谱客的其他文章。








发表评论 取消回复