这是简易数据分析系列的第 16 篇文章。
这期课程我们讲一个用的较少的 Web Scraper 功能——抓取属性信息。
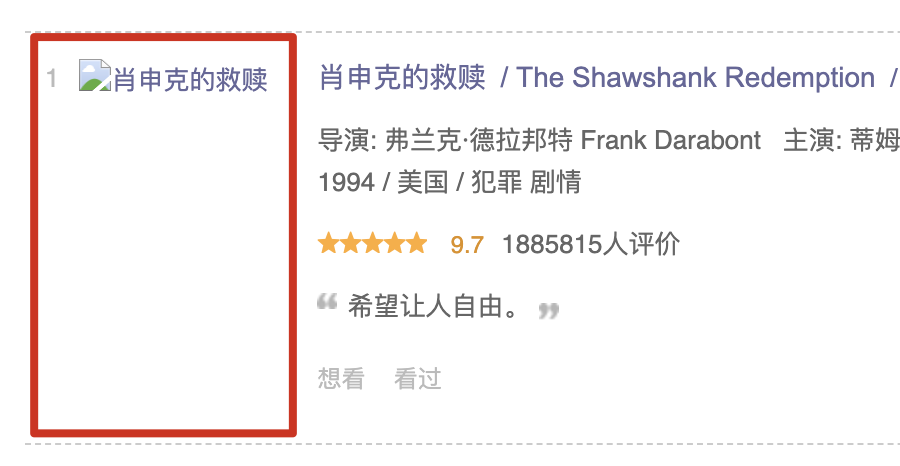
网页在展示信息的时候,除了我们看到的内容,其实还有很多隐藏的信息。我们拿豆瓣电影250举个例子:
电影图片正常显示的时候是这个样子:

如果网络异常,图片加载失败,就会显示图片的默认文案,这个文案其实就是这个图片的属性信息:
我们查看一下这个结构的 HTML(查看方法可见 CSS 选择器的使用的第一节内容),就会发现图片的默认文案其实就是这个 <img/> 标签的 alt 属性:

我们可以看一下 HTML 文档里对 alt 属性的描述:
alt 属性是一个必需的属性,它规定在图像无法显示时的替代文本
在 web scraper 里,我们可以利用 Element attribute 属性来抓取这种属性信息。
因为这次的内容比较简单,新建 sitemap 这一步我就先省略了,我们直接上来使用 Element attribute 抓取数据。
我们把 Type 选为 Element attribute,然后用 Selector 选中图片这个元素:
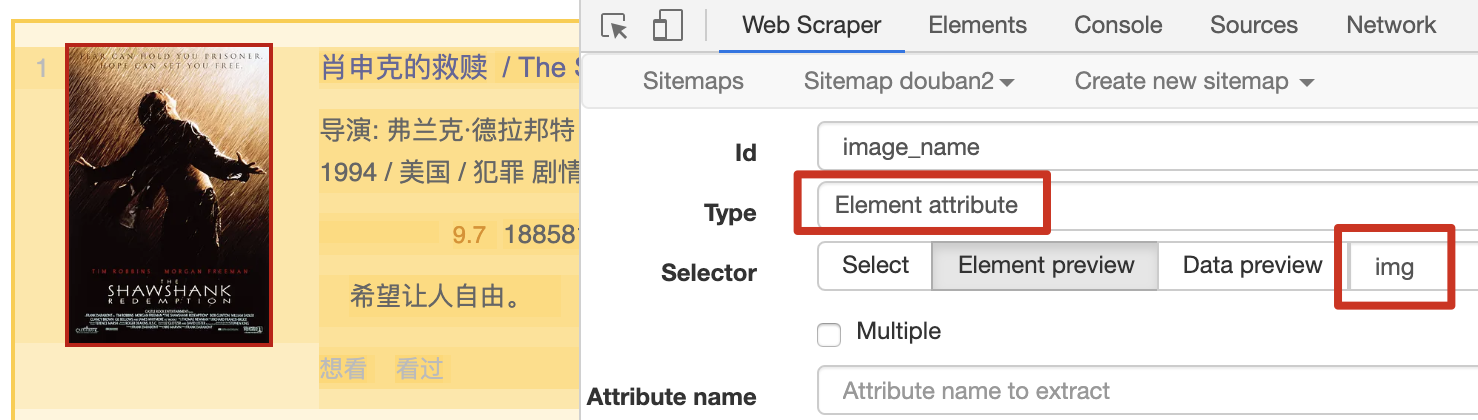
Element attribute 会多一个选项——Attribute name,我们在这个输入框里输入我们要抓取的属性名字。
观察一下这个 img 标签的属性,有 alt(替换文本)、width(图片宽度)和 src(图片链接)3 种:

这里我先输入 alt,表示抓取图片的替代文本:
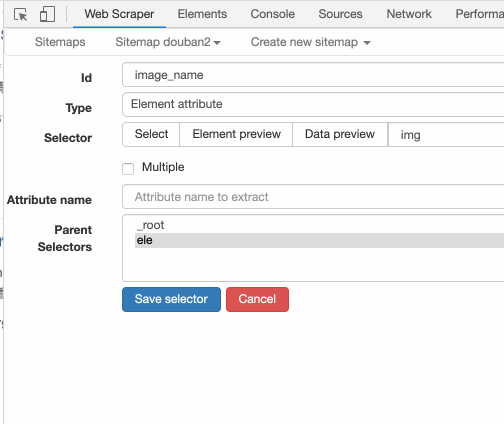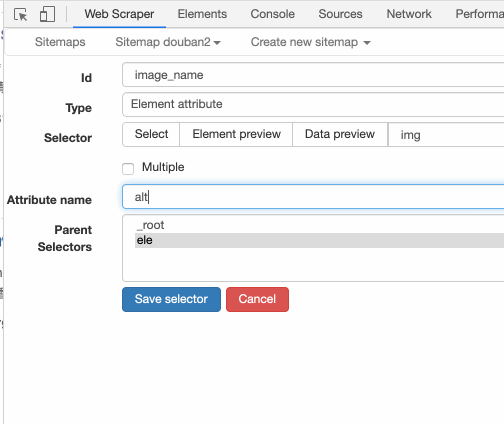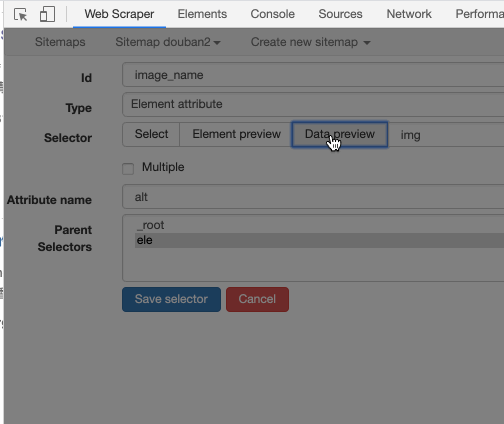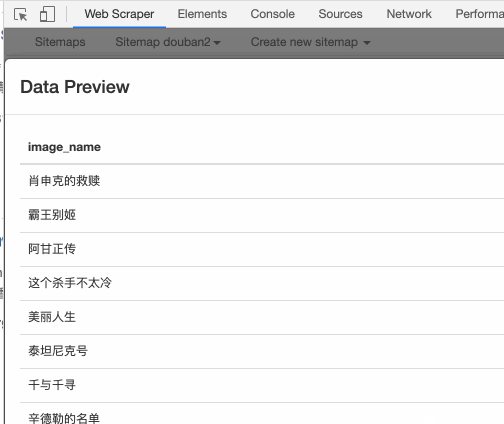
还可以输入 src,表示抓取图片的链接:
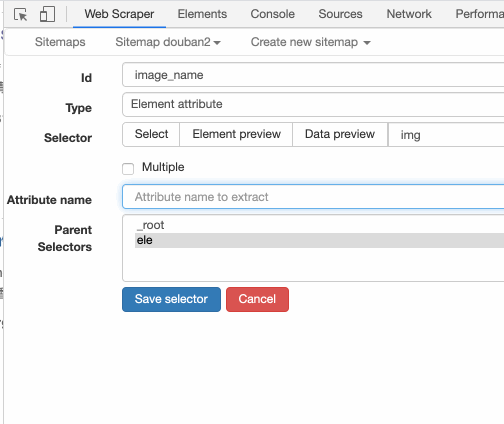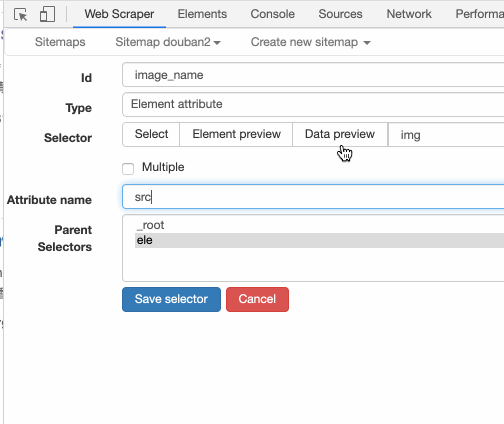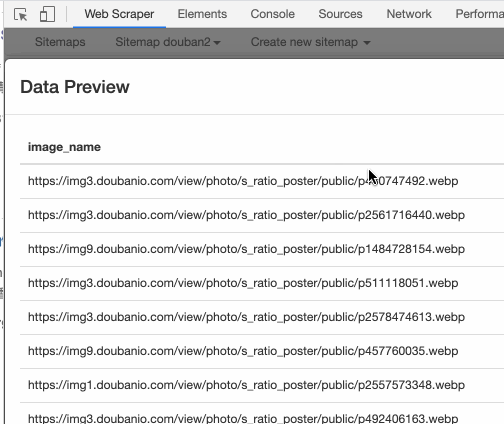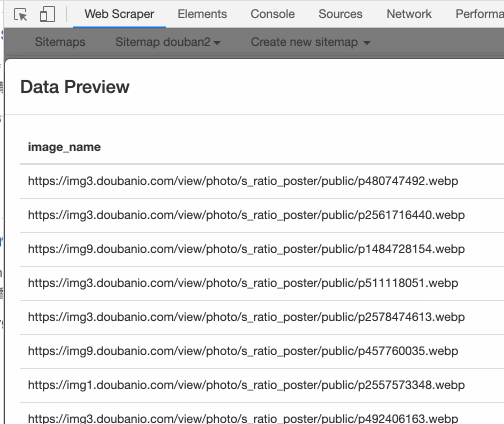
也可以输入 width,抓取图片宽度:
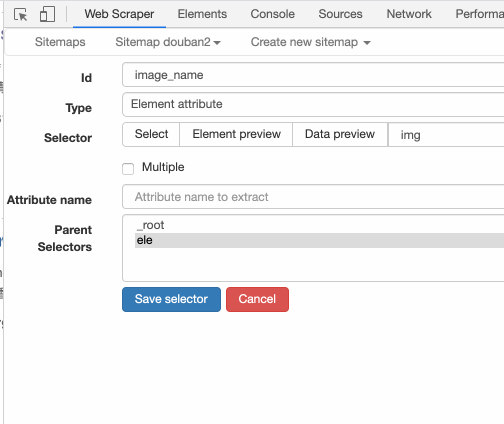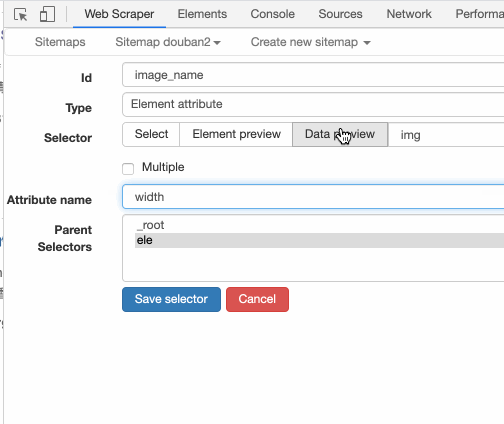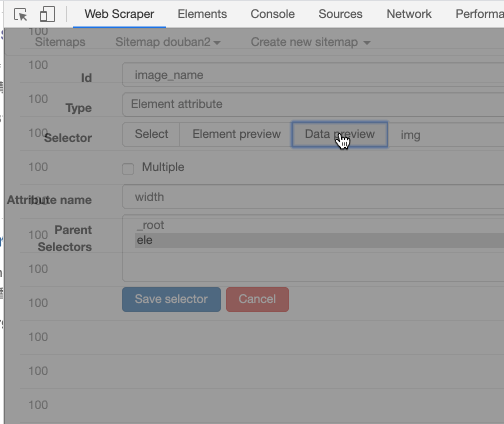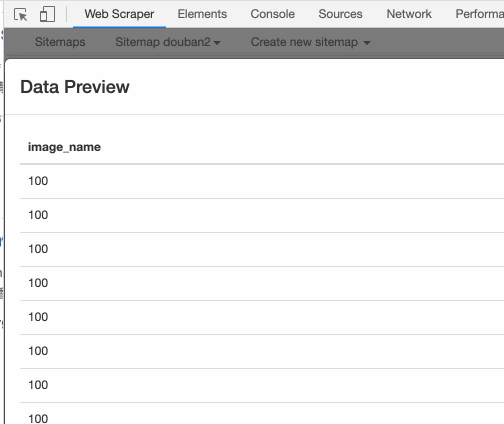
通过 Element attribute 这个选择器,我们就可以抓取一些网页没有直接展示出来的数据信息,非常的方便。
sitemap 分享
{"_id":"douban2","startUrl":["https://movie.douban.com/top250?start=0&filter="],"selectors":[{"id":"ele","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"image_name","type":"SelectorElementAttribute","parentSelectors":["ele"],"selector":"img","multiple":false,"extractAttribute":"alt","delay":0}]}
最后
以上就是平淡墨镜最近收集整理的关于Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16的全部内容,更多相关Web内容请搜索靠谱客的其他文章。








发表评论 取消回复