
这是简易数据分析系列的第 11 篇文章。
今天我们讲讲如何抓取网页表格里的数据。首先我们分析一下,网页里的经典表格是怎么构成的。
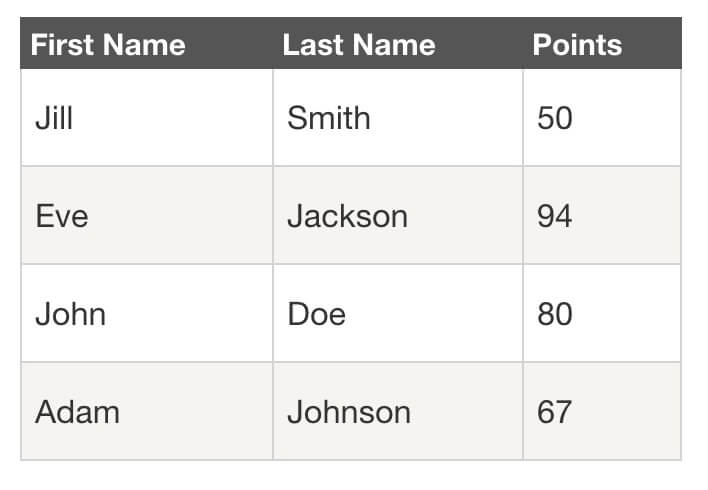
First Name所在的行比较特殊,是一个表格的表头,表示信息分类- 2-5 行是表格的主体,展示分类内容
经典表格就这些知识点,没了。下面我们写个简单的表格 Web Scraper 爬虫。
1.制作 Sitemap
我们今天的练手网站是
http://www.huochepiao.com/search/chaxun/result.asp?txtChuFa=%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们先创建一个包含整个表格的 container,Type 类型选为 Table,表示我们要抓取表格。

具体的参数如上图所示,因为比较简单,就不多说了。
在这个面板下向下翻,会发现多了一个不一样的面板。观察一下你就会发现,这些数据其实就是表格数据类型的分类,在这个案例里,他把车次、出发站、开车时间等分类都列了出来。

在 Table columns 这个分类里,每一行的内容旁边的选择按钮默认都是打勾的,也就是说默认都会抓取这些列的内容。如果你不想抓取某类内容,去掉对应的勾选就可以了。
在你点击 Save selector 的按钮时,会发现 Result key 的一些选项报错,说什么 invalid format 格式无效:

解决这个报错很简单,一般来说是 Result key 名字的长度不够,你给加个空格加个标点符号就行。如果还报错,就试试换成英文名字:

解决报错保存成功后,我们就可以按照 Web Scraper 的爬取套路抓取数据了。
2.为什么我不建议你用 Web Scraper 的 Table Selector?
如果你按照刚刚的教程做下里,就会感觉很顺利,但是查看数据时就会傻眼了。
刚开始抓取时,我们先用 Data preview 预览一下数据,会发现数据很完美:
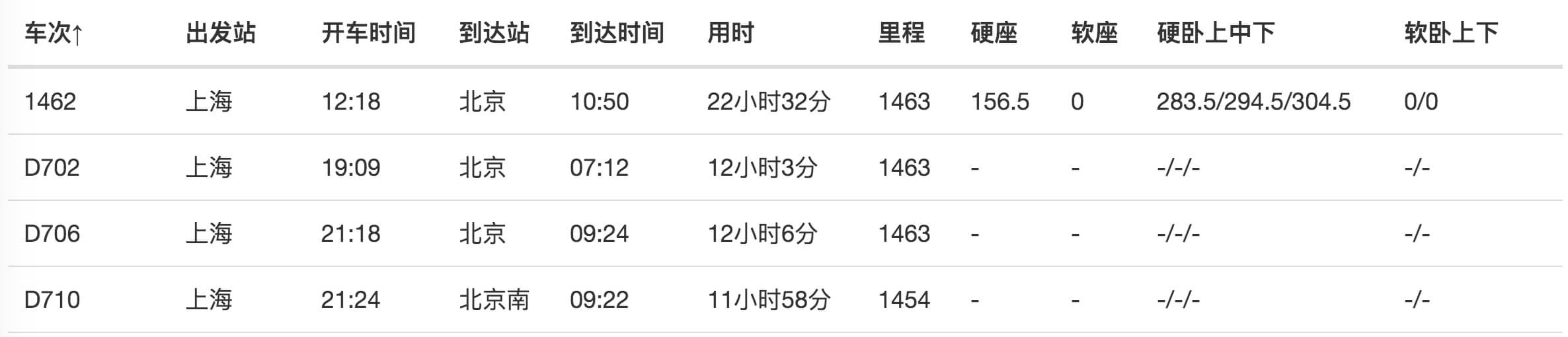
抓取数据后,在浏览器的预览面板预览,会发现车次这一列数据为 null,意味着没有抓取到相关内容:
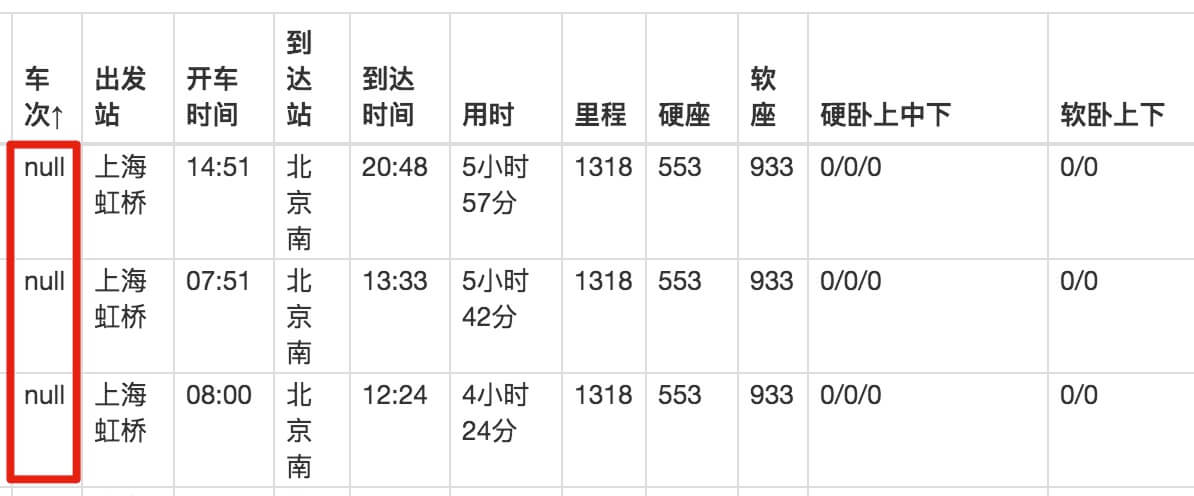
我们下载抓取的 CSV 文件后,在预览器里打开,会发现车次的数据出现了,但出发站的数据又为 null 了!

这不是坑爹呢!
关于这个问题我调查了半天,应该是 Web Scraper 对中文关键字索引的支持不太友好,所以会抛出一些诡异的 bug,因此我并不建议大家用它的 Table 功能。
如果真的想抓取表格数据,我们可以用之前的方案,先创建一个类型为 Element 的 container,然后在 container 里再手动创建子选择器,这样就可以规避这个问题。
上面只是一个原因,还有一个原因是,在现代网站,很少有人用 HTML 原始表格了。
HTML 提供了表格的基础标签,比如说 <table>、 <thead>、 <tbody> 等标签,这些标签上提供了默认的样式。好处是在互联网刚刚发展起来时,可以提供开箱即用的表格;缺点是样式太单一,不太好定制,后来很多网站用其它标签模拟表格,就像 PPT里用各种大小方块组合出一个表格一样,方便定制:

出于这个原因,当你在用 Table Selector 匹配一个表格时,可能会死活匹配不上,因为从 Web Scraper 的角度考虑,你看到的那个表格就是个高仿,根本不是原装正品,自然是不认的。
3.总结
我们并不建议直接使用 Web Scraper 的 Table Selector,因为对中文支持不太友好,也不太好匹配现代网页。如果有抓取表格的需求,可以用之前的创建父子选择器的方法来做。
4.推荐阅读
简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页

转载于:https://www.cnblogs.com/web-scraper/p/web_scraper_table.html
最后
以上就是专注水壶最近收集整理的关于简易数据分析 11 | Web Scraper 抓取表格数据的全部内容,更多相关简易数据分析内容请搜索靠谱客的其他文章。








发表评论 取消回复