模块
一个py文件就是一个模块
模块一共三种:1.python标准库 2.第三方模块 3.应用程序自定义模块
import:1.执行对应文件 2.引入变量名
if__name__="__main__": #1.用于被调用文件测试 2.防止主程序被调用
time模块 常用命令
时间模块
1 importtime2 #时间戳:
3 print(time.tiem())4
5 #结构化时间(当地):
6 t =time.localtime(time.tiem())7 print(t)8
9 #结构化时间(世界标准):
10 t =time.gmtime(time.time())11 print(t)12
13 #需要把时间戳转换成结构化时间
14
15 #将结构化时间转换成时间戳:
16 print(time.mktime(time.localtime()))17
18 #将结构化时间转换成字符串时间:
19 print(time.strftime("%Y-%m-%d %X",time.localtime()))20 %Y年 %m月 %d日 %X时分秒21
22 #将字符串时间转换成结构化时间:
23 print(time.strptime("2018:8:26:19:58:43","%Y:%m:%d:%X"))24
25 #将一个时间戳转换成固定的字符串时间:
26 print(time.ctime())27
28 #将结构化时间转换成固定的字符串时间:
29 print(time.asctime())30
31 #推迟指定的时间运行,单位为秒:
32 time.sleep()33
34 #可以直观显示字符串时间:
35 importdatetime36 print(datetime.datetime.now())
random模块 常用命令
生成随机数
1 importrandom2
3 #用于生成一个0到1的随机浮点数
4 print(random.random())5
6 #用于生成一个指定范围内的整数:
7 random.randint(a,b)8 print(random.randint(1,3))9
10 #从指定范围内,按指定基数递增的集合中 获取一个随机数:
11 random.randrange([start], stop[, step])12 print(random.randrange(10,30,2))13 random.randrange(10, 30, 2),结果相当于从[10, 12, 14, 16, ... 26, 28]序列中获取一个随机数14
15 #从序列中获取一个随机元素,参数sequence表示一个有序类型,list, tuple, #字符串都属于sequence:
16 random.choice(sequence)17 print(random.choice([11,22,33]))18
19 #从指定序列中随机获取指定长度的片断并随机排列:
20 random.sample(sequence, k)21 print(random.samplc([11,22,33,44,55],2))22
23 #用于生成一个指定范围内的随机符点数:
24 random.uniform(a,b)25 print(random.uniform(1,4))26
27 #用于将一个列表中的元素打乱,即将列表内的元素随机排列:
28 ret =[1,2,3,4,5]29 random.shuffle(ret)30 print(ret)
os模块 常用命令
os模块就是对操作系统进行操作
1 importos2
3 #getcwd() 获取当前工作目录(当前工作目录默认都是当前文件所在的文件夹)
4 print(os.getcwd())5
6 #chdir()改变当前工作目录
7 os.chdir('/home/sy')8 print(os.getcwd())9
10 open('02.txt','w')11 #操作时如果书写完整的路径则不需要考虑默认工作目录的问题,按照实际书写路径操作
12 open('/home/sy/下载/02.txt','w')13
14 #listdir() 获取指定文件夹中所有内容的名称列表
15 result = os.listdir('/home/sy')16 print(result)17
18 #mkdir() 创建文件夹
19 os.mkdir('girls')20 os.mkdir('boys',0o777)21
22 #makedirs() 递归创建文件夹
23 os.makedirs('/home/sy/a/b/c/d')24
25 #rmdir() 删除空目录
26 os.rmdir('girls')27
28 #removedirs 递归删除文件夹 必须都是空目录
29 os.removedirs('/home/sy/a/b/c/d')30
31 #remove 删除一个文件
32 os.remove()33
34 #rename() 文件或文件夹重命名
35 os.rename('/home/sy/a','/home/sy/alibaba'
36 os.rename('02.txt','002.txt')37
38 #stat() 获取文件或者文件夹的信息
39 result = os.stat('/home/sy/PycharmProject/Python3/10.27/01.py)
40 print(result)41
42 #system() 执行系统命令(危险函数)
43 result = os.system('ls -al') #获取隐藏文件
44 print(result)45
46 #环境变量
47 """环境变量就是一些命令的集合48 操作系统的环境变量就是操作系统在执行系统命令时搜索命令的目录的集合"""
49
50 #getenv() 获取系统的环境变量
51 result = os.getenv('PATH')52 print(result.split(':'))53
54 #putenv() 将一个目录添加到环境变量中(临时增加仅对当前脚本有效)
55 #os.putenv('PATH','/home/sy/下载')
56 #os.system('syls')
57
58 #exit() 退出终端的命令
59
60 #os模块中的常用值
61 #curdir 表示当前文件夹 .表示当前文件夹 一般情况下可以省略
62 print(os.curdir)63
64 #pardir 表示上一层文件夹 ..表示上一层文件夹 不可省略!
65 print(os.pardir)66
67 #os.mkdir('../../../man')#相对路径 从当前目录开始查找
68 #os.mkdir('/home/sy/man1')#绝对路径 从根目录开始查找
69
70 #name 获取代表操作系统的名称字符串
71 print(os.name) #posix -> linux或者unix系统 nt -> window系统
72
73 #sep 获取系统路径间隔符号 window -> linux ->/
74 print(os.sep)75
76 #extsep 获取文件名称和后缀之间的间隔符号 window & linux -> .
77 print(os.extsep)78
79 #linesep 获取操作系统的换行符号 window -> rn linux/unix -> n
80 print(repr(os.linesep))81
82 #导入os模块
83 importos84 #以下内容都是os.path子模块中的内容
85
86 #abspath() 将相对路径转化为绝对路径
87 path = './boys'#相对
88 result =os.path.abspath(path)89 print(result)90
91 #dirname() 获取完整路径当中的目录部分 & basename()获取完整路径当中的主体部分
92 path = '/home/sy/boys'
93 result =os.path.dirname(path)94 print(result)95
96 result =os.path.basename(path)97 print(result)98
99 #split() 将一个完整的路径切割成目录部分和主体部分
100 path = '/home/sy/boys'
101 result =os.path.split(path)102 print(result)103
104 #join() 将2个路径合并成一个
105 var1 = '/home/sy'
106 var2 = '000.py'
107 result =os.path.join(var1,var2)108 print(result)109
110 #splitext() 将一个路径切割成文件后缀和其他两个部分,主要用于获取文件的后缀
111 path = '/home/sy/000.py'
112 result =os.path.splitext(path)113 print(result)114
115 #getsize() 获取文件的大小
116 #path = '/home/sy/000.py'
117 #result = os.path.getsize(path)
118 #print(result)
119
120 #isfile() 检测是否是文件
121 path = '/home/sy/000.py'
122 result =os.path.isfile(path)123 print(result)124
125 #isdir() 检测是否是文件夹
126 result =os.path.isdir(path)127 print(result)128
129 #islink() 检测是否是链接
130 path = '/initrd.img.old'
131 result =os.path.islink(path)132 print(result)133
134 #getctime() 获取文件的创建时间 get create time
135 #getmtime() 获取文件的修改时间 get modify time
136 #getatime() 获取文件的访问时间 get active time
137
138 importtime139
140 filepath = '/home/sy/下载/chls'
141
142 result =os.path.getctime(filepath)143 print(time.ctime(result))144
145 result =os.path.getmtime(filepath)146 print(time.ctime(result))147
148 result =os.path.getatime(filepath)149 print(time.ctime(result))150
151 #exists() 检测某个路径是否真实存在
152 filepath = '/home/sy/下载/chls'
153 result =os.path.exists(filepath)154 print(result)155
156 #isabs() 检测一个路径是否是绝对路径
157 path = '/boys'
158 result =os.path.isabs(path)159 print(result)160
161 #samefile() 检测2个路径是否是同一个文件
162 path1 = '/home/sy/下载/001'
163 path2 = '../../../下载/001'
164 result =os.path.samefile(path1,path2)165 print(result)166
167
168 #os.environ 用于获取和设置系统环境变量的内置值
169 #获取系统环境变量 getenv() 效果
170 print(os.environ['PATH'])171
172 #设置系统环境变量 putenv()
173 os.environ['PATH'] += ':/home/sy/下载'
174 os.system('chls')
sys模块 常用命令
1 importsys2
3 sys.argv: #实现从程序外部向程序传递参数。
4
5 sys.exit([arg]): #程序中间的退出,arg=0为正常退出。
6
7 sys.getdefaultencoding(): #获取系统当前编码,一般默认为ascii。
8
9 sys.setdefaultencoding(): """设置系统默认编码,执行dir(sys)时不会看到这个方法,在解释器中执行不通过,可以先执行reload(sys),在执行 setdefaultencoding('utf8'),此时将系统默认编码设置为utf8。(见设置系统默认编码 )"""
10
11 sys.getfilesystemencoding():"""获取文件系统使用编码方式,Windows下返回'mbcs',mac下返回'utf-8'."""
12
13 sys.path: """获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。"""
14
15 sys.platform: #获取当前系统平台。
16
17 sys.stdin,sys.stdout,sys.stderr: stdin , stdout , 以及stderr 变量包含与标准I/O 流对应的流对象. 如果需要更好地控制输出,而print 不能满足你的要求, 它们就是你所需要的. 你也可以替换它们, 这时候你就可以重定向输出和输入到其它设备( device ), 或者以非标准的方式处理它们
json模块,pickle模块,shelve模块 常用命令
基本的数据序列化
1 json字符串转为字典2 json.load /json.loads3 """两个方法功能类似,可选参数也相同,最大的区别在于,json.load方法接受的输入,即第一个参数,是包含json数据的文件对象,如open方法的返回对象,"""
4
5 json.loads"""接受的输入是json字符串,而非文件对象。从输入类型的区别也可以看出两者的使用场合。6 可选参数包括是否需要转换整型、浮点型等数值的参数,还有一些复杂的功能,暂时没有用到,以后有机会再了解。"""
7
8 字典转换为json9 json.dump /json.dumps10 """对应于load和loads,dump的第一个参数是对象字典,第二个参数是文件对象,可以直接将转换后的json数据写入文件,dumps的第一个参数是对象字典,其余都是可选参数。dump和dumps的可选参数相同,这些参数都相当实用,"""
11
12 pickle模块13 (需要使用"wb"的方法写入文件,写的是字节)14 pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。15 pickle模块只能在python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化,16 pickle序列化后的数据,可读性差,人一般无法识别。17
18 pickle.dump(obj,file,[protocol])19 """序列化对象,并将结果数据流写入到文件对象中。参数protocol是序列化模式,默认值为0,表示以文本的形式序列化。protocol的值还可以是1或2,表示以二进制的形式序列化。"""
20
21 pickle.load(file)22 """反序列化对象。将文件中的数据解析为一个Python对象。23 其中要注意的是,在load(file)的时候,要让python能够找到类的定义,否则会报错"""
24
25 shelve模块26 """shelve是一额简单的数据存储方案,他只有一个函数就是open(),这个函数接收一个参数就是文件名,并且文件名必须是.bat类型的。然后返回一个shelf对象,你可以用他来存储东西,就可以简单的把他当作一个字典,当你存储完毕的时候,就调用close函数来关闭,不过在shelve模块中,key必须为字符串,而值可以是python所支持的数据类型。"""
xml模块 常用命令
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
1 #查询:
2 #.tag 根标签名
3 #.attrib 标签属性
4 #.text 标签实际包裹的内容
5 #.iter #想取到每个属性中的year的text值就应该用iter方法这样取
6 #修改添加:
7 #.set 给这个标签增加一个属性
8 #.write直接把修改的写入到文件中
9 #删除:
10 #.findall 找多个标签
11 #.find 找单个标签
12 #.remove删除
13
14 importxml.etree.ElementTree as ET15
16 tree = ET.parse("xmltest.xml") """parse解析,用ET模块下的parse这个方法把xml文件解析开,解析开拿到一个tree,tree就是一个对象"""
17 root = tree.getroot()#这个对象可以调用方法,getroot就是根的意思
18 print(root.tag)19 #遍历xml文档,使用for循环
20 for child inroot:21 print(child.tag, child.attrib)22 for i inchild:23 print(i.tag,i.text)24
25 #只遍历year 节点
26 for node in root.iter('year'):27 print(node.tag,node.text)28
29 #修改和删除xml文档内容
30 importxml.etree.ElementTree as ET31
32 tree = ET.parse("xmltest.xml")33 root =tree.getroot()34
35 #修改
36 for node in root.iter('year'):37 new_year = int(node.text) + 1
38 node.text =str(new_year)39 node.set("updated","yes")40
41 tree.write("xmltest.xml")42
43 #删除node
44 for country in root.findall('country'):45 rank = int(country.find('rank').text)46 if rank > 50:47 root.remove(country)48
49 tree.write('output.xml')50
51 #自己创建xml文档
52
53 importxml.etree.ElementTree as ET54
55 new_xml = ET.Element("namelist")#创建了一个根节点
56 #相当于创建了
57 name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})58 #创建一个子标签name,然后增加一个属性
59 age = ET.SubElement(name,"age",attrib={"checked":"no"})60 sex = ET.SubElement(name,"sex")61 sex.text = '33'
62 name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})63 age = ET.SubElement(name2,"age")64 age.text = '19'
65
66 et = ET.ElementTree(new_xml) #生成文档对象
67 et.write("test.xml", encoding="utf-8",xml_declaration=True)68
69 ET.dump(new_xml) #打印生成的格式
re模块 常用命令
正则表达式本身是一种小型的、高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行。
1 .#通配符
2 """需要字符串里完全符合,匹配规则,就匹配,(规则里的.元字符)可以是任何一个字符,匹配任意除换行符"n"外的字符(在DOTALL模式中也能匹配换行符)"""
3 #!/usr/bin/env python
4 #-*- coding:utf-8 -*-
5 import re #第一步,要引入re模块
6 ret=re.findall("匹..则", "匹配规则这个字符串是否匹配") """需要字符串里完全符合,匹配规则,就匹配,(规则里的.元字符)可以是任何一个字符"""
7 print(ret)8 #打印出['匹配规则']
9
10 ^ #元字符
11 """字符串开始位置与匹配规则符合就匹配,否则不匹配,匹配字符串开头。在多行模式中匹配每一行的开头,^元字符如果写到[]字符集里就是反取"""
12 #!/usr/bin/env python
13 #-*- coding:utf-8 -*-
14 import re #第一步,要引入re模块
15 a = re.findall("^匹配规则", "匹配规则这个字符串是否匹配") """字符串开始位置与匹配规则符合就匹配,否则不匹配"""
16 print(a) #以列表形式返回匹配到的字符串
17 #打印出 ['匹配规则']
18
19 $ #元字符
20 """字符串结束位置与匹配规则符合就匹配,否则不匹配,匹配字符串末尾,在多行模式中匹配每一行的末尾"""
21 #!/usr/bin/env python
22 #-*- coding:utf-8 -*-
23 import re #第一步,要引入re模块
24 a = re.findall("匹配规则$", "这个字符串是否匹配规则") """字符串结束位置与匹配规则符合就匹配,否则不匹配"""
25 print(a) #以列表形式返回匹配到的字符串
26 #打印出 ['匹配规则']
27
28 * #元字符
29 """需要字符串里完全符合,匹配规则,就匹配,(规则里的*元字符)前面的一个字符可以是0个或多个原本字符,匹配前一个字符0或多次,贪婪匹配前导字符有多少个就匹配多少个很贪婪,如果规则里只有一个分组,尽量避免用*否则会有可能匹配出空字符串"""
30 #!/usr/bin/env python
31 #-*- coding:utf-8 -*-
32 import re #第一步,要引入re模块
33 a = re.findall("匹配规则*", "这个字符串是否匹配规则则则则则") """需要字符串里完全符合,匹配规则,就匹配,(规则里的*元字符)前面的一个字符可以是0或多个原本字符"""
34 print(a) #以列表形式返回匹配到的字符串
35 #打印出 ['匹配规则则则则则']
36
37 + #元字符
38 """需要字符串里完全符合,匹配规则,就匹配,(规则里的+元字符)前面的一个字符可以是1个或多个原本字符,匹配前一个字符1次或无限次,贪婪匹配前导字符有多少个就匹配多少个很贪婪"""
39 #!/usr/bin/env python
40 #-*- coding:gbk -*-
41 import re #第一步,要引入re模块
42 a = re.findall("匹配+", "匹配配配配配规则这个字符串是否匹配规则则则则则") """需要字符串里完全符合,匹配规则,就匹配,(规则里的+元字符)前面的一个字符可以是1个或多个原本字符"""
43 print(a) #以列表形式返回匹配到的字符串
44 #打印出 ['匹配配配配配', '匹配']
45
46 ? #元字符,和防止贪婪匹配
47 """需要字符串里完全符合,匹配规则,就匹配,(规则里的?元字符)前面的一个字符可以是0个或1个原本字符,匹配一个字符0次或1次,还有一个功能是可以防止贪婪匹配,详情见防贪婪匹配"""
48 #!/usr/bin/env python
49 #-*- coding:utf-8 -*-
50 import re #第一步,要引入re模块
51 a = re.findall("匹配规则?", "匹配规这个字符串是否匹配规则则则则则") """需要字符串里完全符合,匹配规则,就匹配,(规则里的?元字符)前面的一个字符可以是0个或1个原本字符"""
52 print(a) #以列表形式返回匹配到的字符串
53 #打印出 ['匹配规', '匹配规则']
54
55 {} #元字符,范围
56 """需要字符串里完全符合,匹配规则,就匹配,(规则里的 {} 元字符)前面的一个字符,是自定义字符数,位数的原本字符57 {m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次58 {0,}匹配前一个字符0或多次,等同于*元字符59 {+,}匹配前一个字符1次或无限次,等同于+元字符60 {0,1}匹配前一个字符0次或1次,等同于?元字符"""
61 #!/usr/bin/env python
62 #-*- coding:utf-8 -*-
63 import re #第一步,要引入re模块
64 a = re.findall("匹配规则{3}", "匹配规这个字符串是否匹配规则则则则则") """{m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次"""
65 print(a) #以列表形式返回匹配到的字符串
66 #打印出 ['匹配规则则则']
67
68 [] #元字符,字符集
69 """. % * + ? () {} 出现在中括号中仅表示字符本身。^字符在中括号中表示取反。70 需要字符串里完全符合,匹配规则,就匹配,(规则里的 [] 元字符)对应位置是[]里的任意一个字符就匹配71 字符集。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。[^abc]表示取反,即非abc。72 所有特殊字符在字符集中都失去其原有的特殊含义。用反斜杠转义恢复特殊字符的特殊含义。"""
73 #!/usr/bin/env python
74 #-*- coding:utf-8 -*-
75 import re #第一步,要引入re模块
76 a = re.findall("匹配[a,b,c]规则", "匹配a规则这个字符串是否匹配b规则则则则则") """需要字符串里完全符合,匹配规则,就匹配,(规则里的 [] 元字符)对应位置是[]里的任意一个字符就匹配"""
77 print(a) #以列表形式返回匹配到的字符串
78
79 [^] #非,反取,匹配出除[^]里面的字符,^元字符如果写到字符集里就是反取
80 #!/usr/bin/env python
81 #-*- coding:utf-8 -*-
82 import re #第一步,要引入re模块
83 a = re.findall("[^a-z]", "匹配s规则这s个字符串是否s匹配f规则则re则则则") #反取,匹配出除字母外的字符
84 print(a) #以列表形式返回匹配到的字符串
85 #打印出 ['匹', '配', '规', '则', '这', '个', '字', '符', '串', '是', '否', '匹', '配', '规', '则', '则', '则', '则', '则']
86
87 () #元字符,分组
88 """也就是分组匹配,()里面的为一个组也可以理解成一个整体89 如果()后面跟的是特殊元字符如 (adc)* 那么*控制的前导字符就是()里的整体内容,不再是前导一个字符"""
90 #列1
91 #!/usr/bin/env python
92 #-*- coding:utf8 -*-
93 import re #第一步,要引入re模块
94 #也就是分组匹配,()里面的为一个组也可以理解成一个整体
95 a = re.search("(a4)+", "a4a4a4a4a4dg4g654gb") #匹配一个或多个a4
96 b =a.group()97 print(b)98 #打印出 a4a4a4a4a4
99 #列2
100 #!/usr/bin/env python
101 #-*- coding:utf8 -*-
102 import re #第一步,要引入re模块
103 #也就是分组匹配,()里面的为一个组也可以理解成一个整体
104 a = re.search("a(d+)", "a466666664a4a4a4dg4g654gb") #匹配 (a) (d0-9的数字) (+可以是1个到多个0-9的数字)
105 b =a.group()106 print(b)107 #打印出 a466666664
108
109 | #元字符,或
110 #或就是前后其中一个符合就匹配
111 #!/usr/bin/env python
112 #-*- coding:utf8 -*-
113 import re #第一步,要引入re模块
114 a = re.findall(r"你|好", "a4a4a你4aabc4a4dgg好dg4g654g") #|或,或就是前后其中一个符合就匹配
115 print(a)116 #打印出 ['你', '好']
117
118 r #原生字符
119 """将在python里有特殊意义的字符如b,转换成原生字符(就是去除它在python的特殊意义),不然会给正则表达式有冲突,为了避免这种冲突可以在规则前加原始字符r"""
120
121 """贪婪和非贪婪122 正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。123 贪婪模式下字符串查找会直接走到字符串结尾去匹配,如果不相等就向前寻找,这一过程称为回溯。"""
124 importre125 str1='
贪婪'126 str2=re.findall(r'<.*>',str1)127 print(str2)128 >>>['
']129130 #非贪婪模式下会自左向右查找,一个一个匹配不会出现回溯的情况。
131 importre132 str1='
贪婪'133 str2=re.findall(r'<.*?>',str1)134 print(str2)135 >>>['
']136137 #正则转义符
138 #在使用时需在字符串外加上 r 来取消转义
139
140 d #数字
141 importre142 str1='iii amiiii 123er45vg44'
143 str2=re.findall(r'd',str1)144 print(str2)145 >>>['1', '2', '3', '4', '5', '4', '4']146
147 D #匹配数字以外的字符
148 importre149 str1='i love python12456'
150 str2=re.findall(r'D',str1)151 print(str2)152 >>>['i', ' ', 'l', 'o', 'v', 'e', ' ', 'p', 'y', 't', 'h', 'o', 'n']153
154 w #字母、数字、汉字和下划线
155 importre156 str1='iii am_你好iiii 123er45vg44'
157 str2=re.findall(r'w',str1)158 print(str2)159 >>>['i', 'i', 'i', 'a', 'm', '_', '你', '好', 'i', 'i', 'i', 'i', '1', '2', '3', 'e', 'r', '4', '5', 'v', 'g', '4', '4']160
161 W #非w匹配的字符
162 importre163 str1='i love ¥%*python12456nt'
164 str2=re.findall(r'W',str1)165 print(str2)166 >>>[' ', ' ', '¥', '%', '*', 'n', 't']167
168 s #匹配空白符号(n,t和空格)
169 importre170 str1='iii am_你好iiii 123nert45vg44'
171 str2=re.findall(r's',str1)172 print(str2)173 >>>[' ', ' ', 'n', 't', ' ']174
175 S #匹配除了空白字符之外的
176 importre177 str1='i love python12456nt'
178 str2=re.findall(r'S',str1)179 print(str2)180 >>>['i', 'l', 'o', 'v', 'e', 'p', 'y', 't', 'h', 'o', 'n', '1', '2', '4', '5', '6']181
182 b #单词边界
183 """字符的位置是非常重要的。如果它位于要匹配的字符串的开始,它在单词的开始处查找匹配项。如果它位于字符串的结尾,它在单词的结尾处查找匹配项。"""
184 importre185 str1='i love python'
186 str2=re.findall(r'bon',str1)187 str3=re.findall(r'onb',str1)188 print(str2)189 print(str3)190 >>>[]191 ['on']192
193 B #匹配非单词边界
194 """对于 B 非字边界运算符,位置并不重要,因为匹配不关心究竟是单词的开头还是结尾。"""
195 importre196 str1='i love python12456'
197 str2=re.findall(r'ovB',str1)198 print(str2)199 >>>['ov']200
201 #re模块下的常用方法
202 findall()203 #re.findall 遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
204 #格式:
205 re.findall(pattern, string, flags=0)206 p = re.compile(r'd+')207 print(p.findall('o1n2m3k4'))208 执行结果如下:209 ['1', '2', '3', '4']210
211 importre212 tt = "Tina is a good girl, she is cool, clever, and so on..."
213 rr = re.compile(r'w*oow*')214 print(rr.findall(tt))215 print(re.findall(r'(w)*oo(w)',tt))#()表示子表达式
216 执行结果如下:217 ['good', 'cool']218 [('g', 'd'), ('c', 'l')]219
220 search()221 #格式:
222 re.search(pattern, string, flags=0)223 #re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
224
225 print(re.search('dcom','www.4comrunoob.5com').group())226 #执行结果如下:
227 4com228 """注:match和search一旦匹配成功,就是一个match object对象,而match object对象有以下方法:229 group() 返回被 RE 匹配的字符串230 start() 返回匹配开始的位置231 end() 返回匹配结束的位置232 span() 返回一个元组包含匹配 (开始,结束) 的位置233 group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串234 group()返回re整体匹配的字符串,235 group (n,m) 返回组号为n,m所匹配的字符串,如果组号不存在,则返回indexError异常236 groups()groups() 方法返回一个包含正则表达式中所有小组字符串的元组,从 1 到所含的小组号,通常groups()不需要参数,返回一个元组,元组中的元就是正则表达式中定义的组。"""
237
238 importre239 a = "123abc456"
240 print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) #123abc456,返回整体
241 print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) #123
242 print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) #abc
243 print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) #456
244 """group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。"""
245
246 match()247 """决定RE是否在字符串刚开始的位置匹配。//注:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'"""
248 #格式:
249 re.match(pattern, string, flags=0)250
251 print(re.match('com','comwww.runcomoob').group())252 print(re.match('com','Comwww.runcomoob',re.I).group())253 #执行结果如下:
254 com255 com256
257 split()258 """按照能够匹配的子串将string分割后返回列表。259 可以使用re.split来分割字符串,如:re.split(r's+', text);将字符串按空格分割成一个单词列表。"""
260 #格式:
261 re.split(pattern, string[, maxsplit])262 #maxsplit用于指定最大分割次数,不指定将全部分割。
263
264 print(re.split('d+','one1two2three3four4five5'))265 #执行结果如下:
266 ['one', 'two', 'three', 'four', 'five', '']267
268 sub()269 #使用re替换string中每一个匹配的子串后返回替换后的字符串。
270 #格式:
271 re.sub(pattern, repl, string, count)272
273 importre274 text = "JGood is a handsome boy, he is cool, clever, and so on..."
275 print(re.sub(r's+', '-', text))276 #执行结果如下:
277 JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on...278 """其中第二个函数是替换后的字符串;本例中为'-'第四个参数指替换个数。默认为0,表示每个匹配项都替换。"""
279 #re.sub还允许使用函数对匹配项的替换进行复杂的处理。
280 """如:re.sub(r's', lambda m: '[' + m.group(0) + ']', text, 0);将字符串中的空格' '替换为'[ ]'。"""
281 importre282 text = "JGood is a handsome boy, he is cool, clever, and so on..."
283 print(re.sub(r's+', lambda m:'['+m.group(0)+']', text,0))284 #执行结果如下:
285 JGood[ ]is[ ]a[ ]handsome[ ]boy,[ ]he[ ]is[ ]cool,[ ]clever,[ ]and[ ]so[ ]on...286
287 subn()288 #返回替换次数
289 #格式:
290 subn(pattern, repl, string, count=0, flags=0)291
292 print(re.subn('[1-2]','A','123456abcdef'))293 print(re.sub("g.t","have",'I get A, I got B ,I gut C'))294 print(re.subn("g.t","have",'I get A, I got B ,I gut C'))295 #执行结果如下:
296 ('AA3456abcdef', 2)297 I have A, I have B ,I have C298 ('I have A, I have B ,I have C', 3)299
300 compile()301 """编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。)"""
302 #格式:
303 re.compile(pattern,flags=0)304 #pattern: 编译时用的表达式字符串。
305 """flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:"""
306 re.S(DOTALL)307 #使.匹配包括换行在内的所有字符
308 re.I(IGNORECASE)309 #使匹配对大小写不敏感
310 re.L(LOCALE)311 #做本地化识别(locale-aware)匹配,法语等
312 re.M(MULTILINE)313 #多行匹配,影响^和$
314 re.X(VERBOSE)315 #该标志通过给予更灵活的格式以便将正则表达式写得更易于理解
316 re.U317 #根据Unicode字符集解析字符,这个标志影响w,W,b,B
318 importre319 tt = "Tina is a good girl, she is cool, clever, and so on..."
320 rr = re.compile(r'w*oow*')321 print(rr.findall(tt)) #查找所有包含'oo'的单词
322 #执行结果如下:
323 ['good', 'cool']324
325 finditer()326 """搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。找到 RE 匹配的所有子串,并把它们作为一个迭代器返回。"""
327 #格式:
328 re.finditer(pattern, string, flags=0)329
330 iter = re.finditer(r'd+','12 drumm44ers drumming, 11 ... 10 ...')331 for i initer:332 print(i)333 print(i.group())334 print(i.span())335 #执行结果如下:
336 <_sre.SRE_Match object; span=(0, 2), match='12'>
337 12
338 (0, 2)339 <_sre.SRE_Match object; span=(8, 10), match='44'>
340 44
341 (8, 10)342 <_sre.SRE_Match object; span=(24, 26), match='11'>
343 11
344 (24, 26)345 <_sre.SRE_Match object; span=(31, 33), match='10'>
346 10
347 (31, 33)348
349 """浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中,未匹配成功返回空列表350 注意:一旦匹配成,再次匹配,是从前一次匹配成功的,后面一位开始的,也可以理解为匹配成功的字符串,不在参与下次匹配"""
351 #!/usr/bin/env python
352 #-*- coding:utf8 -*-
353 importre354 #无分组
355 r = re.findall("d+wd+", "a2b3c4d5") """浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中"""
356 print(r)357 #输出结果
358 #['2b3', '4d5']
359 """注意:匹配成功的字符串,不在参与下次匹配,所以3c4也符合规则但是没匹配到,注意:如果没写匹配规则,也就是空规则,返回的是一个比原始字符串多一位的,空字符串列表"""
360 #!/usr/bin/env python
361 #-*- coding:utf8 -*-
362 importre363 #无分组
364 r = re.findall("", "a2b3c4d5") """浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中"""
365 print(r)366 #输出结果
367 #['', '', '', '', '', '', '', '', '']
368 """注意:如果没写匹配规则,也就是空规则,返回的是一个比原始字符串多一位的,空字符串列表"""
369
370 """注意:正则匹配到空字符的情况,如果规则里只有一个组,而组后面是*就表示组里的内容可以是0个或者多过,这样组里就有了两个意思,一个意思是匹配组里的内容,二个意思是匹配组里0内容(即是空白)所以尽量避免用*否则会有可能匹配出空字符串371 注意:正则只拿组里最后一位,如果规则里只有一个组,匹配到的字符串里在拿组内容是,拿的是匹配到的内容最后一位"""
372 #!/usr/bin/env python
373 #-*- coding:utf8 -*-
374 importre375 origin = "hello alex bcd alex lge alex acd 19"
376 r = re.findall("(a)*", origin)377 print(r)378 #输出结果
379 ['', '', '', '', '', '', 'a', '', '', '', '', '', '', '', '', 'a', '', '', '', '', '', '', '', '', 'a', '', '', '', '', 'a', '', '', '', '', '', '']380
381 #有分组:只将匹配到的字符串里,组的部分放到列表里返回,相当于groups()方法
382 #!/usr/bin/env python
383 #-*- coding:utf8 -*-
384 importre385 origin = "hello alex bcd alex lge alex acd 19"
386 r = re.findall("a(w+)", origin) #有分组:只将匹配到的字符串里,组的部分放到列表里返回
387 print(r)388 #输出结果
389 #['lex', 'lex', 'lex', 'cd']
390
391 """多个分组:只将匹配到的字符串里,组的部分放到一个元组中,最后将所有元组放到一个列表里返392 相当于在group()结果里再将组的部分,分别,拿出来放入一个元组,最后将所有元组放入一个列表返回"""
393
394 #!/usr/bin/env python
395 #-*- coding:utf8 -*-
396 importre397 origin = "hello alex bcd alex lge alex acd 19"
398 r = re.findall("(a)(w+)", origin) """多个分组:只将匹配到的字符串里,组的部分放到一个元组中,最后将所有元组放到一个列表里返回"""
399 print(r)400 #输出结果
401 #[('a', 'lex'), ('a', 'lex'), ('a', 'lex'), ('a', 'cd')]
402
403 """分组中有分组:只将匹配到的字符串里,组的部分放到一个元组中,先将包含有组的组,看作一个整体也就是一个组,把这个整体组放入一个元组里,然后在把组里的组放入一个元组,最后将所有组放入一个列表返回"""
404
405 #!/usr/bin/env python
406 #-*- coding:utf8 -*-
407 importre408 origin = "hello alex bcd alex lge alex acd 19"
409 r = re.findall("(a)(w+(e))", origin) """分组中有分组:只将匹配到的字符串里,组的部分放到一个元组中,先将包含有组的组,看作一个整体也就是一个组,把这个整体组放入一个元组里,然后在把组里的组放入一个元组,最后将所有组放入一个列表返回"""
410 print(r)411 #输出结果
412 [('a', 'le', 'e'), ('a', 'le', 'e'), ('a', 'le', 'e')]413
414 ?: """在有分组的情况下findall()函数,不只拿分组里的字符串,拿所有匹配到的字符串,注意?:只用于不是返回正则对象的函数如findall()"""
415
416 #!/usr/bin/env python
417 #-*- coding:utf8 -*-
418 importre419 origin = "hello alex bcd alex lge alex acd 19"
420 b = re.findall("a(?:w+)",origin) """?:在有分组的情况下,不只拿分组里的字符串,拿所有匹配到的字符串,注意?:只用于不是返回正则对象的函数如findall()"""
421 print(b)422 #输出
423 ['alex', 'alex', 'alex', 'acd']424
425 #特殊分组用法表:只对正则函数返回对象的有用
426 (?P)427 """?P<>定义组里匹配内容的key(键),<>里面写key名称,值就是匹配到的内容,在用groupdict()方法打印字符串"""
428 (?Pabc){2}429
430 (?P=name)431 #引用别名为的分组匹配到字符串
432 (?Pd)abc(?P=id)433
434
435 #引用编号为的分组匹配到字符串
436 (d)abc1
configparser模块 常用命令
来看一个好多软件的常见文档格式如下:
1 [DEFAULT]2 ServerAliveInterval = 45
3 Compression =yes4 CompressionLevel = 9
5 ForwardX11 =yes6
7 [bitbucket.org]8 User =hg9
10 [topsecret.server.com]11 Port = 50022
12 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
1 importconfigparser2
3 config =configparser.ConfigParser()4 config["DEFAULT"] = {'ServerAliveInterval': '45',5 'Compression': 'yes',6 'CompressionLevel': '9'}7
8 config['bitbucket.org'] ={}9 config['bitbucket.org']['User'] = 'hg'
10 config['topsecret.server.com'] ={}11 topsecret = config['topsecret.server.com']12 topsecret['Host Port'] = '50022' #mutates the parser
13 topsecret['ForwardX11'] = 'no' #same here
14 config['DEFAULT']['ForwardX11'] = 'yes'
15 with open('example.ini', 'w') as configfile:16 config.write(configfile)
增删改查操作
1 importconfigparser2
3 config =configparser.ConfigParser()4
5 #---------------------------------------------查
6 print(config.sections()) #[]
7
8 config.read('example.ini')9
10 print(config.sections()) #['bitbucket.org', 'topsecret.server.com']
11
12 print('bytebong.com' in config)#False
13
14 print(config['bitbucket.org']['User']) #hg
15
16 print(config['DEFAULT']['Compression']) #yes
17
18 print(config['topsecret.server.com']['ForwardX11']) #no
19
20
21 for key in config['bitbucket.org']:22 print(key)23
24
25 #user
26 #serveraliveinterval
27 #compression
28 #compressionlevel
29 #forwardx11
30
31
32 print(config.options('bitbucket.org'))#['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11']
33 print(config.items('bitbucket.org')) #[('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')]
34
35 print(config.get('bitbucket.org','compression'))#yes
36
37
38 #---------------------------------------------删,改,增(config.write(open('i.cfg', "w")))
39
40
41 config.add_section('yuan')42
43 config.remove_section('topsecret.server.com')44 config.remove_option('bitbucket.org','user')45
46 config.set('bitbucket.org','k1','11111')47
48 config.write(open('i.cfg', "w"))
hashlib模块 常用命令
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
1 importhashlib2
3 m=hashlib.md5()#m=hashlib.sha256()
4
5 m.update('hello'.encode('utf8'))6 print(m.hexdigest()) #5d41402abc4b2a76b9719d911017c592
7
8 m.update('alvin'.encode('utf8'))9
10 print(m.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af
11
12 m2=hashlib.md5()13 m2.update('helloalvin'.encode('utf8'))14 print(m2.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
1 importhashlib2
3 ######### 256 ########
4
5 hash = hashlib.sha256('898oaFs09f'.encode('utf8'))6 hash.update('alvin'.encode('utf8'))7 print (hash.hexdigest())#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密:
1 importhmac2 h = hmac.new('alvin'.encode('utf8'))3 h.update('hello'.encode('utf8'))4 print (h.hexdigest())#320df9832eab4c038b6c1d7ed73a5940
subprocess模块 常用命令
当我们需要调用系统的命令的时候,最先考虑的os模块。用os.system()和os.popen()来进行操作。但是这两个命令过于简单,不能完成一些复杂的操作,如给运行的命令提供输入或者读取命令的输出,判断该命令的运行状态,管理多个命令的并行等等。这时subprocess中的Popen命令就能有效的完成我们需要的操作。
subprocess模块允许一个进程创建一个新的子进程,通过管道连接到子进程的stdin/stdout/stderr,获取子进程的返回值等操作。
1 #Popen它的构造函数如下:
2
3 subprocess.Popen(args, bufsize=0, executable=None, stdin=None, stdout=None,stderr=None, preexec_fn=None, close_fds=False, shell=False,
cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0)4
5 #参数args可以是字符串或者序列类型(如:list,元组),用于指定进程的可执行文件及其参数。
6 #如果是序列类型,第一个元素通常是可执行文件的路径。我们也可以显式的使用executeable参
7 #数来指定可执行文件的路径。在windows操作系统上,Popen通过调用CreateProcess()来创
8 #建子进程,CreateProcess接收一个字符串参数,如果args是序列类型,系统将会通过
9 #list2cmdline()函数将序列类型转换为字符串。
10 #
11 #
12 #参数bufsize:指定缓冲。我到现在还不清楚这个参数的具体含义,望各个大牛指点。
13 #
14 #参数executable用于指定可执行程序。一般情况下我们通过args参数来设置所要运行的程序。如
15 #果将参数shell设为True,executable将指定程序使用的shell。在windows平台下,默认的
16 #shell由COMSPEC环境变量来指定。
17 #
18 #参数stdin, stdout, stderr分别表示程序的标准输入、输出、错误句柄。他们可以是PIPE,
19 #文件描述符或文件对象,也可以设置为None,表示从父进程继承。
20 #
21 #参数preexec_fn只在Unix平台下有效,用于指定一个可执行对象(callable object),它将
22 #在子进程运行之前被调用。
23 #
24 #参数Close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会
25 #继承父进程的输入、输出、错误管道。我们不能将close_fds设置为True同时重定向子进程的标准
26 #输入、输出与错误(stdin, stdout, stderr)。
27 #
28 #如果参数shell设为true,程序将通过shell来执行。
29 #
30 #参数cwd用于设置子进程的当前目录。
31 #
32 #参数env是字典类型,用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父
33 #进程中继承。
34 #
35 #参数Universal_newlines:不同操作系统下,文本的换行符是不一样的。如:windows下
36 #用’/r/n’表示换,而Linux下用’/n’。如果将此参数设置为True,Python统一把这些换行符当
37 #作’/n’来处理。
38 #
39 #参数startupinfo与createionflags只在windows下用效,它们将被传递给底层的
40 #CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等。
简单命令:
1 importsubprocess2
3 a=subprocess.Popen('ls')#创建一个新的进程,与主进程不同步
4
5 print('>>>>>>>',a)#a是Popen的一个实例对象
6
7 '''
8 >>>>>>> 9 __init__.py10 __pycache__11 log.py12 main.py13
14 '''
15
16 #subprocess.Popen('ls -l',shell=True)
17
18 #subprocess.Popen(['ls','-l'])
subprocess.PIPE
在创建Popen对象时,subprocess.PIPE可以初始化stdin, stdout或stderr参数。表示与子进程通信的标准流
1 importsubprocess2
3 #subprocess.Popen('ls')
4 p=subprocess.Popen('ls',stdout=subprocess.PIPE)#结果跑哪去啦?
5
6 print(p.stdout.read())#这这呢:b'__pycache__nhello.pynok.pynwebn'
这是因为subprocess创建了子进程,结果本在子进程中,if 想要执行结果转到主进程中,就得需要一个管道,即 : stdout=subprocess.PIPE
subprocess.STDOUT
创建Popen对象时,用于初始化stderr参数,表示将错误通过标准输出流输出。
Popen的方法
1 Popen.poll()2 用于检查子进程是否已经结束。设置并返回returncode属性。3
4 Popen.wait()5 等待子进程结束。设置并返回returncode属性。6
7 Popen.communicate(input=None)8 与子进程进行交互。向stdin发送数据,或从stdout和stderr中读取数据。可选参数input指定发送到子进程的参数。 Communicate()返回一个元组:(stdoutdata, stderrdata)。注意:如果希望通过进程的stdin向其发送数据,在创建Popen对象的时候,参数stdin必须被设置为PIPE。同样,如 果希望从stdout和stderr获取数据,必须将stdout和stderr设置为PIPE。9
10 Popen.send_signal(signal)11 向子进程发送信号。12
13 Popen.terminate()14 停止(stop)子进程。在windows平台下,该方法将调用Windows API TerminateProcess()来结束子进程。15
16 Popen.kill()17 杀死子进程。18
19 Popen.stdin20 如果在创建Popen对象是,参数stdin被设置为PIPE,Popen.stdin将返回一个文件对象用于策子进程发送指令。否则返回None。21
22 Popen.stdout23 如果在创建Popen对象是,参数stdout被设置为PIPE,Popen.stdout将返回一个文件对象用于策子进程发送指令。否则返回 None。24
25 Popen.stderr26 如果在创建Popen对象是,参数stdout被设置为PIPE,Popen.stdout将返回一个文件对象用于策子进程发送指令。否则返回 None。27
28 Popen.pid29 获取子进程的进程ID。30
31 Popen.returncode32 获取进程的返回值。如果进程还没有结束,返回None。
supprocess模块的工具函数
1 supprocess模块提供了一些函数,方便我们用于创建进程来实现一些简单的功能。2
3 subprocess.call(*popenargs, **kwargs)4 运行命令。该函数将一直等待到子进程运行结束,并返回进程的returncode。如果子进程不需要进行交 互,就可以使用该函数来创建。5
6 subprocess.check_call(*popenargs, **kwargs)7 与subprocess.call(*popenargs, **kwargs)功能一样,只是如果子进程返回的returncode不为0的话,将触发CalledProcessError异常。在异常对象中,包 括进程的returncode信息。8
9 check_output(*popenargs, **kwargs)10 与call()方法类似,以byte string的方式返回子进程的输出,如果子进程的返回值不是0,它抛出CalledProcessError异常,这个异常中的returncode包含返回码,output属性包含已有的输出。11
12 getstatusoutput(cmd)/getoutput(cmd)13 这两个函数仅仅在Unix下可用,它们在shell中执行指定的命令cmd,前者返回(status, output),后者返回output。其中,这里的output包括子进程的stdout和stderr。
1 importsubprocess2
3 #1
4 #subprocess.call('ls',shell=True)
5 '''
6 hello.py7 ok.py8 web9 '''
10 #data=subprocess.call('ls',shell=True)
11 #print(data)
12 '''
13 hello.py14 ok.py15 web16 '''
17
18 #2
19 #subprocess.check_call('ls',shell=True)
20
21 '''
22 hello.py23 ok.py24 web25 '''
26 #data=subprocess.check_call('ls',shell=True)
27 #print(data)
28 '''
29 hello.py30 ok.py31 web32 '''
33 #两个函数区别:只是如果子进程返回的returncode不为0的话,将触发CalledProcessError异常
34
35
36
37 #3
38 #subprocess.check_output('ls')#无结果
39
40 #data=subprocess.check_output('ls')
41 #print(data) #b'hello.pynok.pynwebn'
logging模块 常用命令
一 (简单应用)
1 importlogging2 logging.debug('debug message')3 logging.info('info message')4 logging.warning('warning message')5 logging.error('error message')6 logging.critical('critical message')
输出:
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
可见,默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),默认的日志格式为日志级别:Logger名称:用户输出消息。
二 灵活配置日志级别,日志格式,输出位置
1 importlogging2 logging.basicConfig(level=logging.DEBUG,3 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',4 datefmt='%a, %d %b %Y %H:%M:%S',5 filename='/tmp/test.log',6 filemode='w')7
8 logging.debug('debug message')9 logging.info('info message')10 logging.warning('warning message')11 logging.error('error message')12 logging.critical('critical message')
查看输出:
cat /tmp/test.log
Mon, 05 May 2014 16:29:53 test_logging.py[line:9] DEBUG debug message
Mon, 05 May 2014 16:29:53 test_logging.py[line:10] INFO info message
Mon, 05 May 2014 16:29:53 test_logging.py[line:11] WARNING warning message
Mon, 05 May 2014 16:29:53 test_logging.py[line:12] ERROR error message
Mon, 05 May 2014 16:29:53 test_logging.py[line:13] CRITICAL critical message
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
三 logger对象
上述几个例子中我们了解到了logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical()(分别用以记录不同级别的日志信息),logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数,另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
先看一个最简单的过程:
1 importlogging2
3 logger =logging.getLogger()4 #创建一个handler,用于写入日志文件
5 fh = logging.FileHandler('test.log')6
7 #再创建一个handler,用于输出到控制台
8 ch =logging.StreamHandler()9
10 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')11
12 fh.setFormatter(formatter)13 ch.setFormatter(formatter)14
15 logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
16 logger.addHandler(ch)17
18 logger.debug('logger debug message')19 logger.info('logger info message')20 logger.warning('logger warning message')21 logger.error('logger error message')22 logger.critical('logger critical message')
先简单介绍一下,logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
(1) Logger是一个树形层级结构,输出信息之前都要获得一个Logger(如果没有显示的获取则自动创建并使用root Logger,如第一个例子所示)。logger = logging.getLogger()返回一个默认的Logger也即root Logger,并应用默认的日志级别、Handler和Formatter设置。当然也可以通过Logger.setLevel(lel)指定最低的日志级别,可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出。
1 logger.debug('logger debug message')2 logger.info('logger info message')3 logger.warning('logger warning message')4 logger.error('logger error message')5 logger.critical('logger critical message')
只输出了
2014-05-06 12:54:43,222 - root - WARNING - logger warning message
2014-05-06 12:54:43,223 - root - ERROR - logger error message
2014-05-06 12:54:43,224 - root - CRITICAL - logger critical message
从这个输出可以看出logger = logging.getLogger()返回的Logger名为root。这里没有用logger.setLevel(logging.Debug)显示的为logger设置日志级别,所以使用默认的日志级别WARNIING,故结果只输出了大于等于WARNIING级别的信息。
(2) 如果我们再创建两个logger对象:
1 ##################################################
2 logger1 = logging.getLogger('mylogger')3 logger1.setLevel(logging.DEBUG)4
5 logger2 = logging.getLogger('mylogger')6 logger2.setLevel(logging.INFO)7
8 logger1.addHandler(fh)9 logger1.addHandler(ch)10
11 logger2.addHandler(fh)12 logger2.addHandler(ch)13
14 logger1.debug('logger1 debug message')15 logger1.info('logger1 info message')16 logger1.warning('logger1 warning message')17 logger1.error('logger1 error message')18 logger1.critical('logger1 critical message')19
20 logger2.debug('logger2 debug message')21 logger2.info('logger2 info message')22 logger2.warning('logger2 warning message')23 logger2.error('logger2 error message')24 logger2.critical('logger2 critical message')
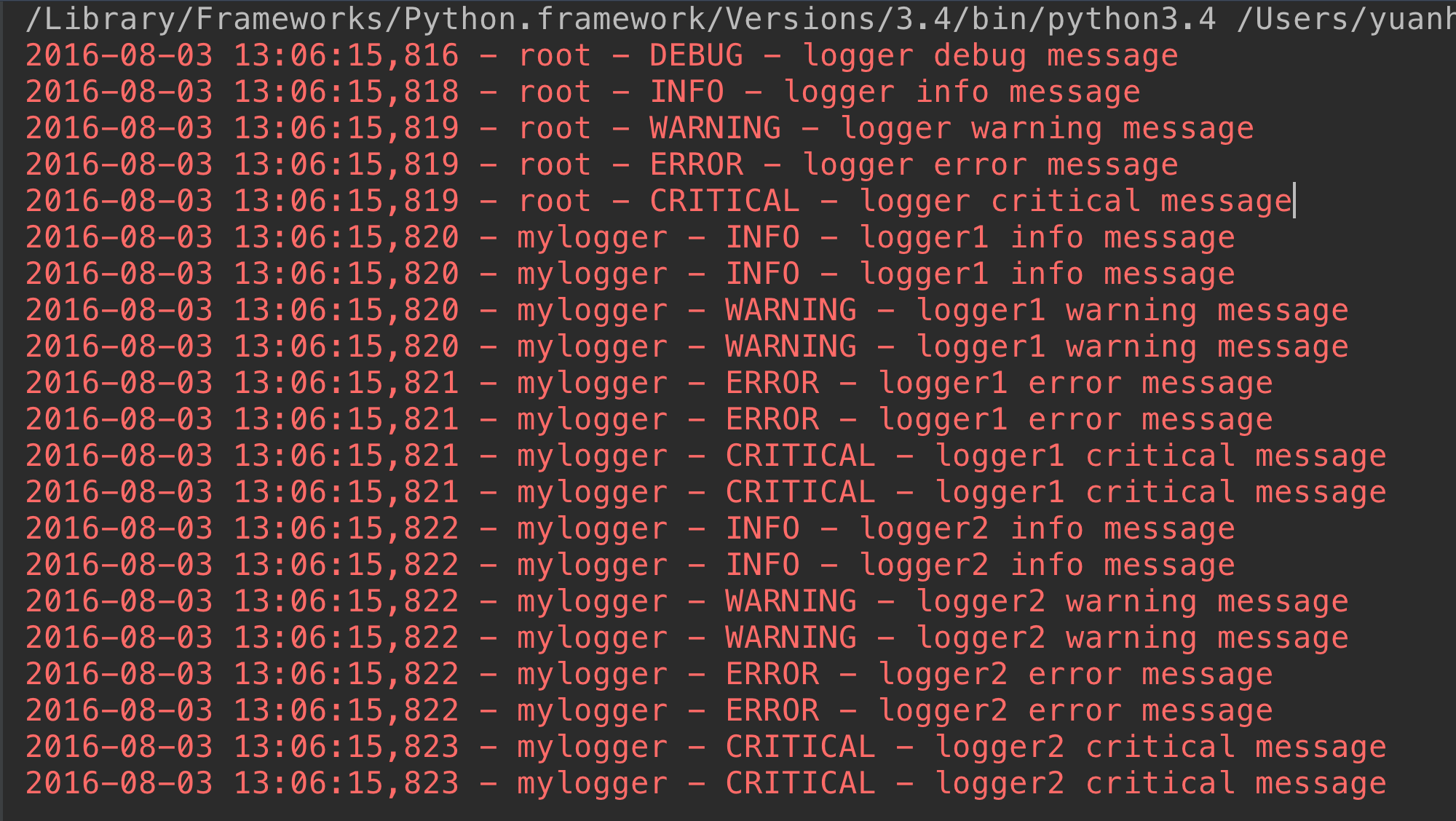
这里有两个个问题:
<1>我们明明通过logger1.setLevel(logging.DEBUG)将logger1的日志级别设置为了DEBUG,为何显示的时候没有显示出DEBUG级别的日志信息,而是从INFO级别的日志开始显示呢?
原来logger1和logger2对应的是同一个Logger实例,只要logging.getLogger(name)中名称参数name相同则返回的Logger实例就是同一个,且仅有一个,也即name与Logger实例一一对应。在logger2实例中通过logger2.setLevel(logging.INFO)设置mylogger的日志级别为logging.INFO,所以最后logger1的输出遵从了后来设置的日志级别。
<2>为什么logger1、logger2对应的每个输出分别显示两次?
这是因为我们通过logger = logging.getLogger()显示的创建了root Logger,而logger1 = logging.getLogger('mylogger')创建了root Logger的孩子(root.)mylogger,logger2同样。而孩子,孙子,重孙……既会将消息分发给他的handler进行处理也会传递给所有的祖先Logger处理。
ok,那么现在我们把
# logger.addHandler(fh)
# logger.addHandler(ch) 注释掉,我们再来看效果:

因为我们注释了logger对象显示的位置,所以才用了默认方式,即标准输出方式。因为它的父级没有设置文件显示方式,所以在这里只打印了一次。
孩子,孙子,重孙……可逐层继承来自祖先的日志级别、Handler、Filter设置,也可以通过Logger.setLevel(lel)、Logger.addHandler(hdlr)、Logger.removeHandler(hdlr)、Logger.addFilter(filt)、Logger.removeFilter(filt)。设置自己特别的日志级别、Handler、Filter。若不设置则使用继承来的值。
<3>Filter
限制只有满足过滤规则的日志才会输出。
比如我们定义了filter = logging.Filter('a.b.c'),并将这个Filter添加到了一个Handler上,则使用该Handler的Logger中只有名字带 a.b.c前缀的Logger才能输出其日志。
filter = logging.Filter('mylogger')
logger.addFilter(filter)
这是只对logger这个对象进行筛选
如果想对所有的对象进行筛选,则:
filter = logging.Filter('mylogger')
fh.addFilter(filter)
ch.addFilter(filter)
这样,所有添加fh或者ch的logger对象都会进行筛选。
完整代码1:
1 importlogging2
3 logger =logging.getLogger()4 #创建一个handler,用于写入日志文件
5 fh = logging.FileHandler('test.log')6
7 #再创建一个handler,用于输出到控制台
8 ch =logging.StreamHandler()9
10 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')11
12 fh.setFormatter(formatter)13 ch.setFormatter(formatter)14
15 #定义一个filter
16 filter = logging.Filter('mylogger')17 fh.addFilter(filter)18 ch.addFilter(filter)19
20 #logger.addFilter(filter)
21 logger.addHandler(fh)22 logger.addHandler(ch)23
24
25
26
27 logger.setLevel(logging.DEBUG)28
29 logger.debug('logger debug message')30 logger.info('logger info message')31 logger.warning('logger warning message')32 logger.error('logger error message')33 logger.critical('logger critical message')34
35 ##################################################
36 logger1 = logging.getLogger('mylogger')37 logger1.setLevel(logging.DEBUG)38
39 logger2 = logging.getLogger('mylogger')40 logger2.setLevel(logging.INFO)41
42 logger1.addHandler(fh)43 logger1.addHandler(ch)44
45 logger2.addHandler(fh)46 logger2.addHandler(ch)47
48 logger1.debug('logger1 debug message')49 logger1.info('logger1 info message')50 logger1.warning('logger1 warning message')51 logger1.error('logger1 error message')52 logger1.critical('logger1 critical message')53
54 logger2.debug('logger2 debug message')55 logger2.info('logger2 info message')56 logger2.warning('logger2 warning message')57 logger2.error('logger2 error message')58 logger2.critical('logger2 critical message')
完整代码2:
1 #coding:utf-8
2 importlogging3
4 #创建一个logger
5 logger =logging.getLogger()6
7 logger1 = logging.getLogger('mylogger')8 logger1.setLevel(logging.DEBUG)9
10 logger2 = logging.getLogger('mylogger')11 logger2.setLevel(logging.INFO)12
13 logger3 = logging.getLogger('mylogger.child1')14 logger3.setLevel(logging.WARNING)15
16 logger4 = logging.getLogger('mylogger.child1.child2')17 logger4.setLevel(logging.DEBUG)18
19 logger5 = logging.getLogger('mylogger.child1.child2.child3')20 logger5.setLevel(logging.DEBUG)21
22 #创建一个handler,用于写入日志文件
23 fh = logging.FileHandler('/tmp/test.log')24
25 #再创建一个handler,用于输出到控制台
26 ch =logging.StreamHandler()27
28 #定义handler的输出格式formatter
29 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')30 fh.setFormatter(formatter)31 ch.setFormatter(formatter)32
33 #定义一个filter
34 #filter = logging.Filter('mylogger.child1.child2')
35 #fh.addFilter(filter)
36
37 #给logger添加handler
38 #logger.addFilter(filter)
39 logger.addHandler(fh)40 logger.addHandler(ch)41
42 #logger1.addFilter(filter)
43 logger1.addHandler(fh)44 logger1.addHandler(ch)45
46 logger2.addHandler(fh)47 logger2.addHandler(ch)48
49 #logger3.addFilter(filter)
50 logger3.addHandler(fh)51 logger3.addHandler(ch)52
53 #logger4.addFilter(filter)
54 logger4.addHandler(fh)55 logger4.addHandler(ch)56
57 logger5.addHandler(fh)58 logger5.addHandler(ch)59
60 #记录一条日志
61 logger.debug('logger debug message')62 logger.info('logger info message')63 logger.warning('logger warning message')64 logger.error('logger error message')65 logger.critical('logger critical message')66
67 logger1.debug('logger1 debug message')68 logger1.info('logger1 info message')69 logger1.warning('logger1 warning message')70 logger1.error('logger1 error message')71 logger1.critical('logger1 critical message')72
73 logger2.debug('logger2 debug message')74 logger2.info('logger2 info message')75 logger2.warning('logger2 warning message')76 logger2.error('logger2 error message')77 logger2.critical('logger2 critical message')78
79 logger3.debug('logger3 debug message')80 logger3.info('logger3 info message')81 logger3.warning('logger3 warning message')82 logger3.error('logger3 error message')83 logger3.critical('logger3 critical message')84
85 logger4.debug('logger4 debug message')86 logger4.info('logger4 info message')87 logger4.warning('logger4 warning message')88 logger4.error('logger4 error message')89 logger4.critical('logger4 critical message')90
91 logger5.debug('logger5 debug message')92 logger5.info('logger5 info message')93 logger5.warning('logger5 warning message')94 logger5.error('logger5 error message')95 logger5.critical('logger5 critical message')
应用:
1 importos2 importtime3 importlogging4 from config importsettings5
6
7 defget_logger(card_num, struct_time):8
9 if struct_time.tm_mday < 23:10 file_name = "%s_%s_%d" %(struct_time.tm_year, struct_time.tm_mon, 22)11 else:12 file_name = "%s_%s_%d" %(struct_time.tm_year, struct_time.tm_mon+1, 22)13
14 file_handler =logging.FileHandler(15 os.path.join(settings.USER_DIR_FOLDER, card_num, 'record', file_name),16 encoding='utf-8'
17 )18 fmt = logging.Formatter(fmt="%(asctime)s : %(message)s")19 file_handler.setFormatter(fmt)20
21 logger1 = logging.Logger('user_logger', level=logging.INFO)22 logger1.addHandler(file_handler)23 return logger1
最后
以上就是优秀唇彩最近收集整理的关于python第七章_python 第七章 模块的全部内容,更多相关python第七章_python内容请搜索靠谱客的其他文章。








发表评论 取消回复