嵌套饼图
我们可以用嵌套饼图更直观地展示某些的类型数据, 下面是用一个例子详细介绍如何用python绘制嵌套饼图.
这里要绘制的是一个最内圈 6 个类别, 每个类别再细分为几个方向, 各个方向上再进行细分.
大致的效果如下:
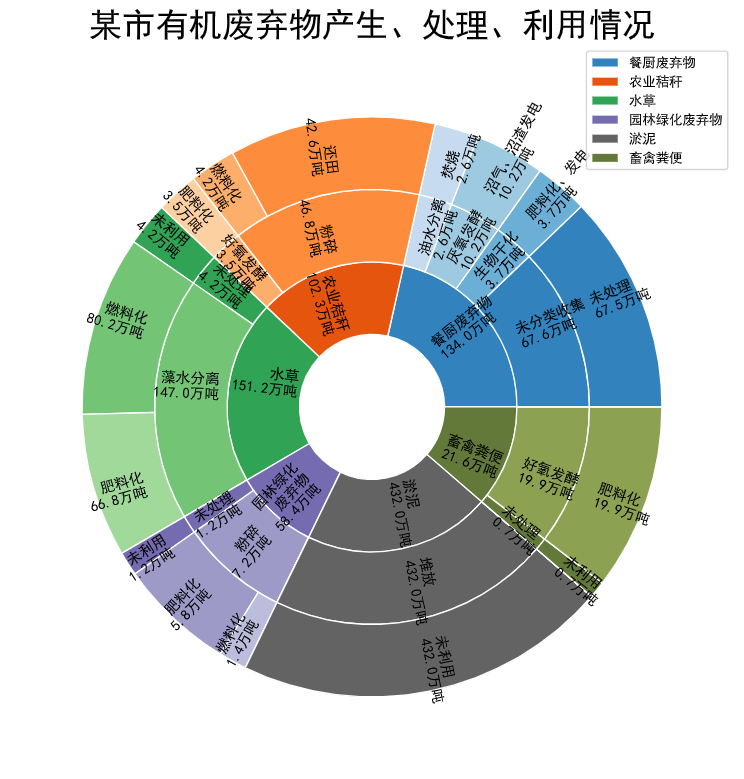
下面我们来一步一步实现这个嵌套饼图.
绘制饼图
ax.pie( vals_first, radius=1-size-size,
colors=inner_colors, labels=labels_first,
labeldistance=0.5, rotatelabels=True,
textprops={'fontsize': 11}, wedgeprops=dict(width=size, edgecolor='w'))
ax.pie( vals_second.flatten(), radius=1-size,
colors=outer_colors, labels=labels_seocnd,
labeldistance=0.7, rotatelabels=True,
textprops={'fontsize': 11}, wedgeprops=dict(width=size, edgecolor='w'))
ax.pie( vals_third.flatten(), radius=1,
colors=outer_colors, labels=labels_third,
labeldistance=0.8, rotatelabels=True,
textprops={'fontsize': 11}, wedgeprops=dict(width=size, edgecolor='w'))
这里是使用matplotlib绘制饼图的代码, 绘制了三层饼图, 对每一层饼图的半径和宽度进行了设置, 使得三层饼图可以一层一层套在一起.
这些参数中, 第一个参数为绘制饼图的数值, radius为饼图的半径, textprop为标签的属性, 设置rotatelabels为True, 使得标签自动旋转. wedgeprops中可以设置饼图的各项数据, 这里我们设置了饼图的宽度和边颜色, 使得饼图显示成嵌套饼图的样子.
这边数据, 颜色, 标签的设置会在后面慢慢细说.
数据设置
数据方面, 由于这次的数据差别太大, 若按照比例来绘制的话, 必然有一些数据显示不出来, 所以我选择将所有数据添加一个固定的数值, 再按照比例来绘制. 但是还有一个问题, 部分数据过大或过小, 会非常影响图形的观感, 这里我只能在绘制图形时手动设置该部分所占的大小.
# 第二圈的数据
vals_b = np.array([
[47.5,11.7,15.2,9.6],
[0,44.8,7.5,0],
[9.2, 68.5 , 0, 0],
[1.2, 7.2, 0, 0],
[80,0, 0, 0],
[1.7, 18.9, 0, 0]
])
# 第三圈的数据
vals_c = np.array([
[47.5,11.7,15.2,9.6],
[0,36.6,8.2,7.5],
[9.2,38.1,30.4, 0],
[1.2, 5.8, 1.4, 0],
[80,0, 0, 0],
[1.7, 18.9, 0, 0]
])
# 第一圈的数据
vals_inner = vals_middle.sum(axis=1)
# 绘图时最内圈使用的数值为内圈各类数据加上base
vals_first = vals_inner + base
’‘’
绘图时第二圈使用的数值, 因为最内圈每个类别都加上了base, 所以为了确保第二圈的数值和内圈相匹配, 第二圈的各类别要按照各自所占的比例分配各类的总数值.
‘’‘
vals_second = np.zeros((6, 4))
for i in range(6):
s_a = vals_first[i]
s_b = vals_a[i].sum()
# 如果第二圈某类总数值为0, 则分配base.
if s_b == 0.0:
vals_second[i][1] = base
continue
for j in range(4):
vals_second[i][j] = (vals_mid[i][j] / s_b) * s_a
# 第三圈使用的数值, 和上方同理
vals_third = np.zeros((6, 4))
for i in range(6):
s_a = vals_first[i]
s_b = vals_outer[i].sum()
if s_b == 0.0:
vals_third[i][1] = base
continue
for j in range(4):
vals_third[i][j] = (vals_outer[i][j] / s_b) * s_a
颜色设置
官方自带的 Colormaps, 这里我需要的是6×4共24种颜色, 于是我选择了colormap tab20c的全部色彩和 tab20b 中 5至8 颜色, 一共24种, 当然你也可以通过 rgba 自己定义颜色而不是选择colormap.

具体代码如下:
# 获取colormap tab20c和tab20b的颜色
cmap_c = plt.get_cmap("tab20c")
cmap_b = plt.get_cmap("tab20b")
# 使用tab20c的全部颜色和tab20b中的 5至8 颜色
cmap_1 = cmap_c(np.arange(20))
cmap_2 = cmap_b(np.array([4, 5, 6, 7]))
# 内圈的颜色是每4个颜色中色彩最深的那个. vstack是将两类颜色叠加在一起
inner_colors = np.vstack((cmap_1[::4], cmap_2[0]))
# 外圈的颜色是全部24种颜色
outer_colors = np.vstack((cmap_1, cmap_2))
标签设置
标签总共是三圈的标签, 内圈, 中圈和外圈, 这里内圈我为了更美观得显示数据, 更改了某些类别的占比, 所以不能直接从输入数据中获取到值, 只能手动输入数值.
中圈和外圈也是同理, 因为绘制的量不大, 中圈和外圈我全部采取了手动输入的方法, 事实上效率确实是大大下降了, 但是毕竟是为了图案美观, 不得已而为之. 如果数据允许的话, 这三种标签中的数据都可以采用输入的数据, 而非手动填写.
labels_first=["餐厨废弃物n{}万吨".format(vals_first[0]),
"农业秸秆n{}万吨".format(vals_first[1]),
"水草n151.2万吨",
"园林绿化n废弃物n{}万吨".format(vals_first[3]),
"淤泥n432.0万吨",
"畜禽粪便n21.6万吨"
]
labels_seocnd=[
"未分类收集n67.6万吨",
"生物干化n3.7万吨",
"厌氧发酵n10.2万吨",
"油水分离n2.6万吨",
"",
"粉碎n46.8万吨",
"好氧发酵n3.5万吨",
"",
"未处理n4.2万吨",
"藻水分离n147.0万吨",
"",
"",
"未处理n1.2万吨",
"粉碎n7.2万吨",
"",
"",
"堆放n432.0万吨",
"",
"",
"",
"未处理n0.7万吨",
"好氧发酵n19.9万吨",
"",
"",
]
labels_third=[
"未处理n67.5万吨",
"肥料化、发电n3.7万吨",
"沼气、沼渣发电n10.2万吨",
"焚烧n2.6万吨",
"",
"还田n42.6万吨",
"燃料化n4.2万吨",
"肥料化n3.5万吨",
"未利用n4.2万吨",
"燃料化n80.2万吨",
"肥料化n66.8万吨",
"",
"未利用n1.2万吨",
"肥料化n5.8万吨",
"燃料化n1.4万吨",
"",
"未利用n432.0万吨",
"",
"",
"",
"未利用n0.7万吨",
"肥料化n19.9万吨",
"",
"",
]
图例
这里因为只需要内圈的图例, 所以我把内圈的handels单独拿了出来
handles, labels = ax.pie(vals_first, radius=1-size-size,
labels=labels_first,
labeldistance=0.5, rotatelabels=True, textprops={'fontsize': 11},
colors=inner_colors, wedgeprops=dict(width=size, edgecolor='w'))
再绘制图例时不再简单使用plt.legend()而是使用:
plt.legend(handles=handles, labels=[
"餐厨废弃物",
"农业秸秆",
"水草",
"园林绿化废弃物",
"淤泥",
"畜禽粪便"],
loc = 1
)
这样出来的图中就只会显示最内层的图例了.
附全部代码
from matplotlib import pyplot as plt
import numpy as np
size = 0.25
base = 50
plt.rcParams['font.family'] = 'SimHei'
fig, ax = plt.subplots(figsize = (10, 10))
vals_middle = np.array([
[47.5,11.7,15.2,9.6],
[0,44.8,7.5,0],
[9.2, 68.5 , 0, 0],
[1.2, 7.2, 0, 0],
[80,0, 0, 0],
[1.7, 18.9, 0, 0]
])
vals_outer = np.array([
[47.5,11.7,15.2,9.6],
[0,36.6,8.2,7.5],
[9.2,38.1,30.4, 0],
[1.2, 5.8, 1.4, 0],
[80,0, 0, 0],
[1.7, 18.9, 0, 0]
])
vals_inner = vals_middle.sum(axis=1)
# 最内圈使用的数值为内圈各类数据加上base
vals_first = vals_inner + base
'''
第二圈使用的数值, 因为最内圈每个类别都加上了base, 所以为了确保第二圈的数值和内圈相匹配, 第二圈的各类别要按照各自所占的比例分配各类的总数值.
'''
vals_second = np.zeros((6, 4))
for i in range(6):
s_a = vals_first[i]
s_b = vals_middle[i].sum()
# 如果第二圈某类总数值为0, 则分配base.
if s_b == 0.0:
vals_second[i][1] = base
continue
for j in range(4):
vals_second[i][j] = (vals_middle[i][j] / s_b) * s_a
# 第三圈使用的数值, 和上方同理
vals_third = np.zeros((6, 4))
for i in range(6):
s_a = vals_first[i]
s_b = vals_outer[i].sum()
if s_b == 0.0:
vals_third[i][1] = base
continue
for j in range(4):
vals_third[i][j] = (vals_outer[i][j] / s_b) * s_a
# 获取colormap tab20c和tab20b的颜色
cmap_c = plt.get_cmap("tab20c")
cmap_b = plt.get_cmap("tab20b")
# 使用tab20c的全部颜色和tab20b中的 5至8 颜色
cmap_1 = cmap_c(np.arange(20))
cmap_2 = cmap_b(np.array([4, 5, 6, 7]))
# 内圈的颜色是每4个颜色中色彩最深的那个. vstack是将两类颜色叠加在一起
inner_colors = np.vstack((cmap_1[::4], cmap_2[0]))
# 外圈的颜色是全部24种颜色
outer_colors = np.vstack((cmap_1, cmap_2))
labels_first=["餐厨废弃物n{}万吨".format(vals_inner[0]),
"农业秸秆n{}万吨".format(vals_inner[1]),
"水草n151.2万吨",
"园林绿化n废弃物n{}万吨".format(vals_inner[3]),
"淤泥n432.0万吨",
"畜禽粪便n21.6万吨"
]
labels_seocnd=[
"未分类收集n67.6万吨",
"生物干化n3.7万吨",
"厌氧发酵n10.2万吨",
"油水分离n2.6万吨",
"",
"粉碎n46.8万吨",
"好氧发酵n3.5万吨",
"",
"未处理n4.2万吨",
"藻水分离n147.0万吨",
"",
"",
"未处理n1.2万吨",
"粉碎n7.2万吨",
"",
"",
"堆放n432.0万吨",
"",
"",
"",
"未处理n0.7万吨",
"好氧发酵n19.9万吨",
"",
"",
]
labels_third=[
"未处理n67.5万吨",
"肥料化、发电n3.7万吨",
"沼气、沼渣发电n10.2万吨",
"焚烧n2.6万吨",
"",
"还田n42.6万吨",
"燃料化n4.2万吨",
"肥料化n3.5万吨",
"未利用n4.2万吨",
"燃料化n80.2万吨",
"肥料化n66.8万吨",
"",
"未利用n1.2万吨",
"肥料化n5.8万吨",
"燃料化n1.4万吨",
"",
"未利用n432.0万吨",
"",
"",
"",
"未利用n0.7万吨",
"肥料化n19.9万吨",
"",
"",
]
handles, labels = ax.pie(vals_first, radius=1-size-size,
labels=labels_first,
labeldistance=0.5, rotatelabels=True, textprops={'fontsize': 11},
colors=inner_colors, wedgeprops=dict(width=size, edgecolor='w'))
ax.pie(vals_second.flatten(), radius=1-size, colors=outer_colors,
labels=labels_seocnd,
labeldistance=0.7, rotatelabels=True, textprops={'fontsize': 11},
wedgeprops=dict(width=size, edgecolor='w'))
ax.pie(vals_third.flatten(), radius=1, colors=outer_colors,
labels=labels_third,
labeldistance=0.8, rotatelabels=True, textprops={'fontsize': 11},
wedgeprops=dict(width=size, edgecolor='w'))
plt.title('某市有机废弃物产生、处理、利用情况', fontsize=25)
plt.legend(handles=handles, labels=[
"餐厨废弃物",
"农业秸秆",
"水草",
"园林绿化废弃物",
"淤泥",
"畜禽粪便"],
loc = 1
)
plt.show()
查看原文
最后
以上就是哭泣小伙最近收集整理的关于使用Matplotlib绘制多层嵌套饼图的全部内容,更多相关使用Matplotlib绘制多层嵌套饼图内容请搜索靠谱客的其他文章。








发表评论 取消回复