1、前言
由前面的文章Spark基础06-Spark client和cluster提交流程我们已经知道了Spark client和cluster提交模式流程
- 启动Driver进程,并向集群管理器注册应用程序
- 集群资源管理器根据任务配置文件分配并启动Executor
- Executor启动之后反向到Driver注册,Driver已经获取足够资源可以运行
- Driver开始执行main函数,Spark查询为懒执行,当执行到action算子时开始反向推算,根据宽依赖进行stage的划分,随后每一个stage对应一个taskset,taskset中有多个task,根据本地化原则,task会被分发到指定的Executor去执行
- 【一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果】
- Executor在执行期间会不断向Driver进行通信,汇报任务运行情况
其中两种提交模式最大的区别就在于Driver的启动位置,client模式driver启动在本地机器,cluster模式driver启动在cluster集群上的节点
下面我们通过追踪源码来验证下这个提交流程
2、Submit shell提交
我们在提交spark任务是通过调用${SPARK_HOME}/bin/spark-submit.sh 脚本提交任务,下面我们给出一个样例
spark-submit
--master spark://127.0.0.1:7077
# 集群模式
--deploy-mode cluster
--driver-memory 1g
--executor-memory 1g
--executor-cores 1
# 启动类
--class org.apache.spark.examples.SparkPi
# jar包地址
${SPARK_HOME}/examples/jars/spark-examples.jar
再看下spark-submit.sh脚本,我们可以看到通过调用org.apache.spark.deploy.SparkSubmit,并将我们的参数传入该类
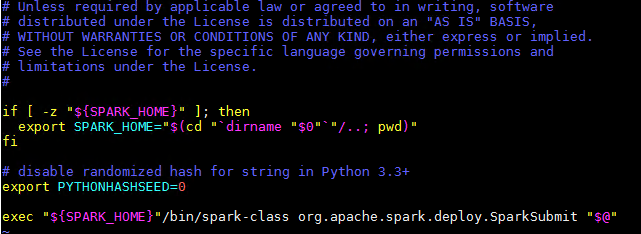
3、SparkSubmit提交流程01-SparkSubmit
本文使用spark源码版本为 2.3.4 ,进入SparkSubmit类,我们直奔主题,找到SparkSubmit.main()方法
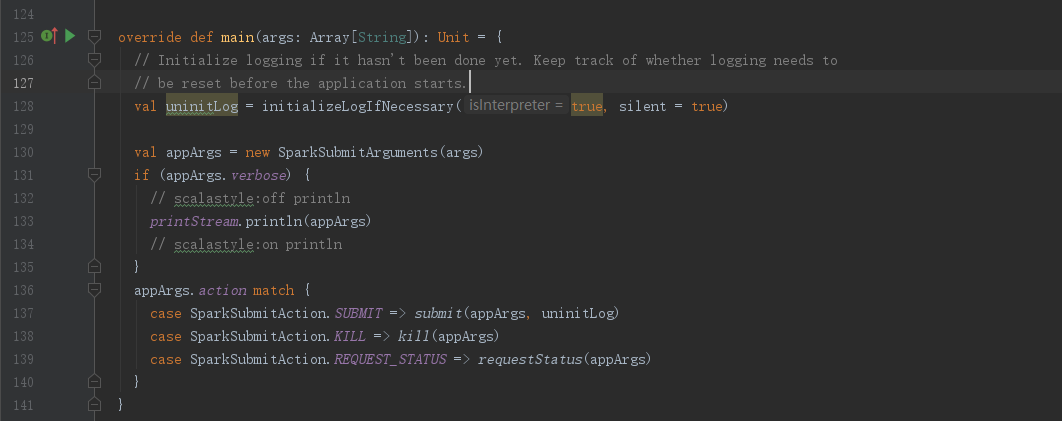
main()方法将入参进行封装为SparkSubmitArguments(),然后根据参数的类型执行相应的方法,这边我们主要跟踪提交流程
进入SparkSubmit.submit()方法,可以看到先定义了doRunMain()方法,然后进入判断,这边我们可以看到无论是走哪个分支最终还是调用了doRunMain()方法
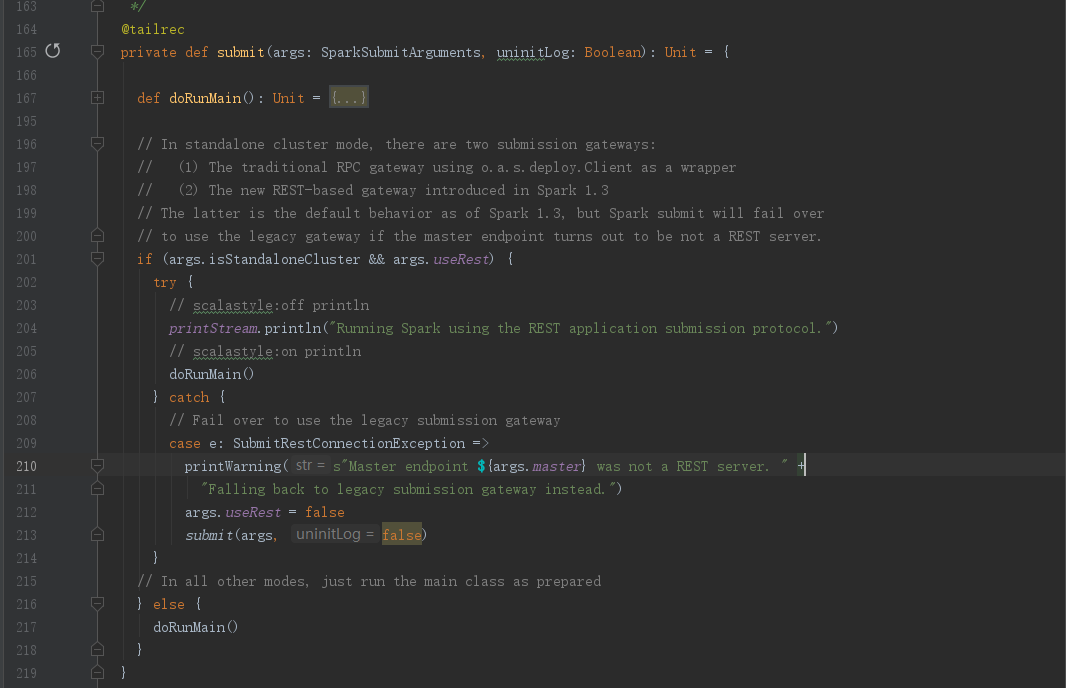
进入doRunMain()方法,可以看到有两个分支,一个是使用代理执行runMain()方法,一个是直接执行runMain()
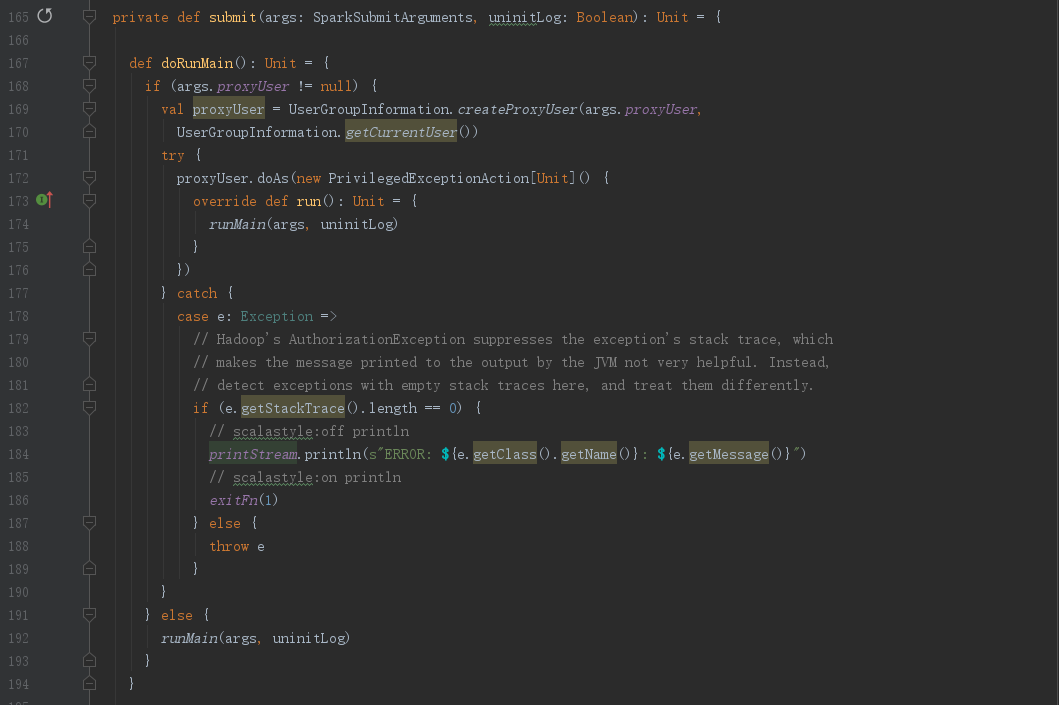
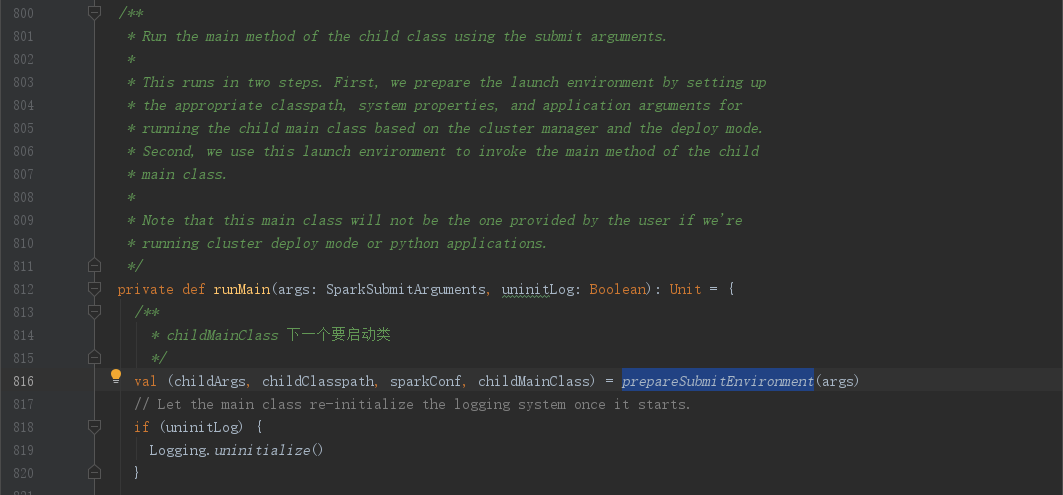
进入SparkSubmit.runMain(),这边我们要关注下注释,“使用submit参数运行子类的main法”,分为两个步骤
- 准备运行环境,设置适当的类路径,系统实行以及应用参数等为了运行 the child main class,基于集群管理器和部署模式
- 使用这个启动环境来调用 the main method of the child main class
从注释我们可以知道,runMain除了准备环境以外,我们需要关注的就是部署模式(deployMode)以及属性childMainClass
从源码我们可以看到prepareSubmitEnvironment(args)方法,返回一个tuple4,其中有我们需要关注的childMainClass属性
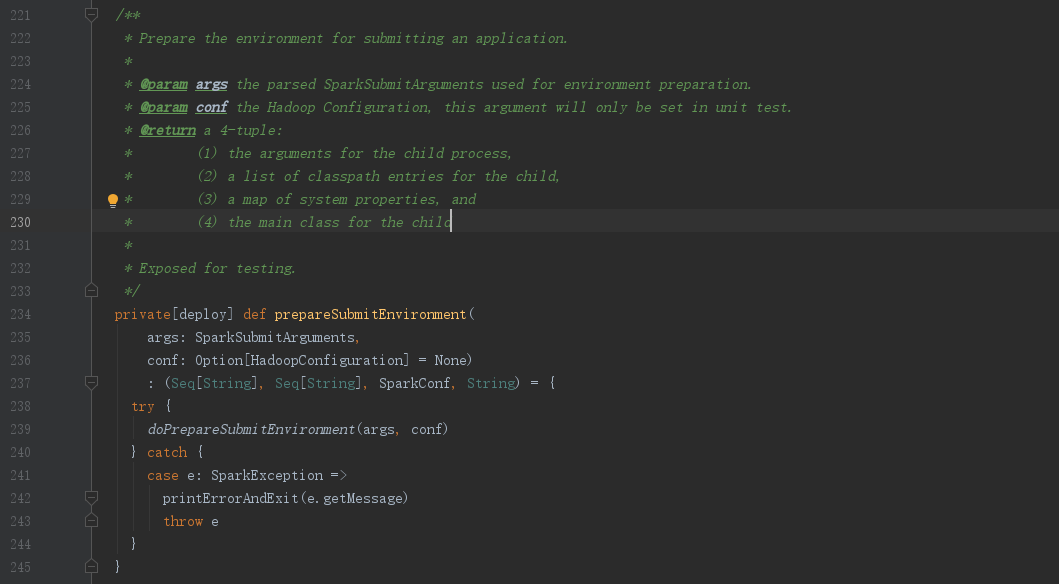
进入SparkSubmit.prepareSubmitEnvironment()方法,可以看到该方法只是一个过渡,实际是调用了doPrepareSubmitEnvironment()方法,这里注释也对了返回tuple4的说明,
//childArgs:the arguments for the child process
//childClasspath:a list of classpath entries for the child
//sparkConf:a map of system properties
//childMainClass:the main class for the child
进入SparkSubmit.doPrepareSubmitEnvironment(),我们先看下这个方法整整537行代码,这里我们就不一一分析方法的作用,我们只关注的核心点:deployMode以及childMainClass

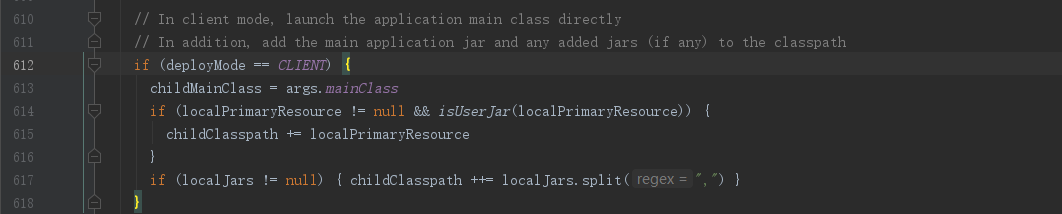
SparkSubmit.doPrepareSubmitEnvironment(),大概612行的位置,可以看到如果部署模式deployMode是client模式,则childMainClass赋值为 args.mainClass,
#这里的agrs.mainClass就是我们 submit提交的--class 参数
spark-submit
--class org.apache.spark.examples.SparkPi
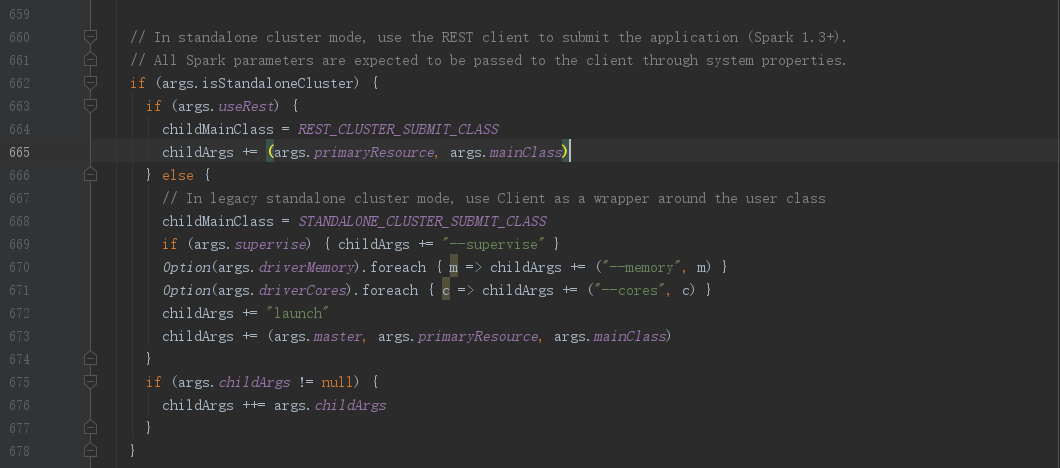
下面我们到662行的位置,本篇文章采用的提交方式是spark-cluster方式,既:StandaloneCluster,下面我们简化下代码逻辑
// 是否使用rest方式
if (args.useRest) {
// 不符合本次逻辑忽略
......
} else {
// childMainClass 赋值
childMainClass = STANDALONE_CLUSTER_SUBMIT_CLASS
// childArgs 赋值
childArgs += (args.master, args.primaryResource, args.mainClass)
}
if (args.childArgs != null) {
childArgs ++= args.childArgs
}
从代码逻辑可以看到,最终childMainClass被赋值为STANDALONE_CLUSTER_SUBMIT_CLASS,此外,childArgs也被赋值了一些数值
下面我们看下STANDALONE_CLUSTER_SUBMIT_CLASS的赋值,将ClientApp的全类名赋值给STANDALONE_CLUSTER_SUBMIT_CLASS变量

下面我们看下ClientApp,是SparkApplication的子类
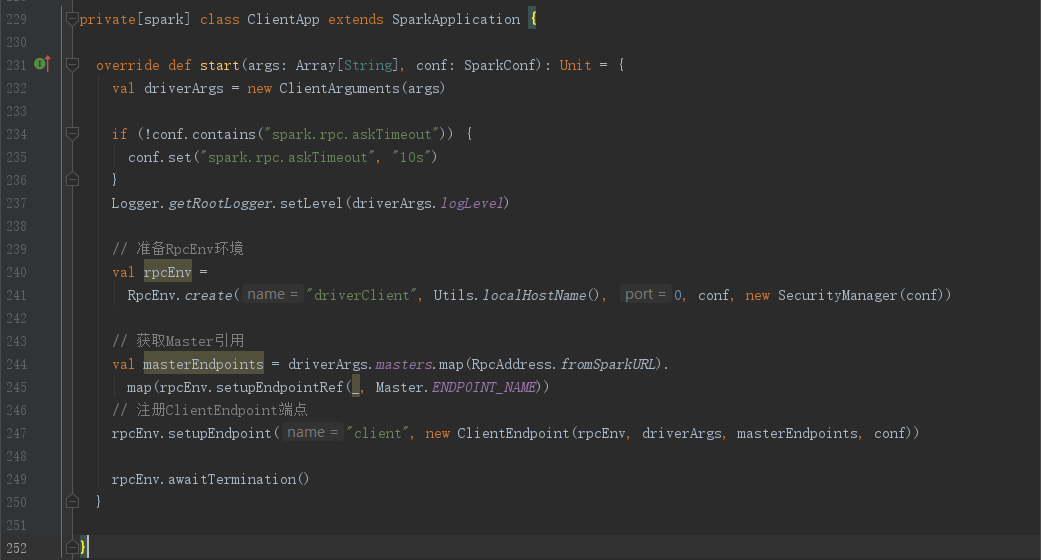
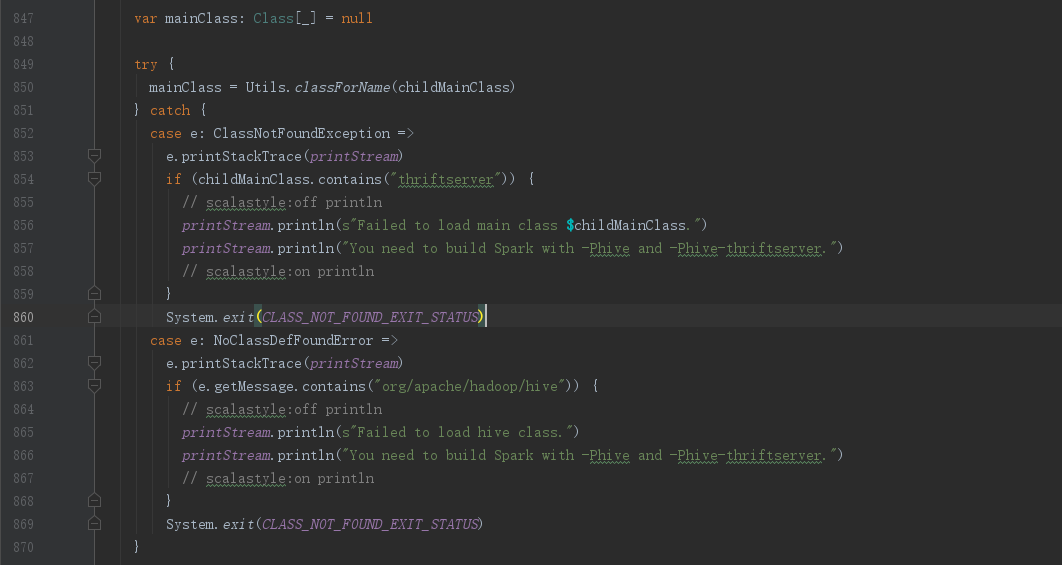
我们继续回到doRunMain()方法,第850行左右的位置,我们可以看到将childMainClass通过反射的方式创建了mainClass
下面我们继续跟着mainClass,来到第877左右的位置,下面我们简化下代码逻辑
// 判断mainClass是否为SparkApplication类型
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
// 如果是SparkApplication类型,则创建实例
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
// 非SparkApplication类型
// 既Client模式提交的就会走该分支,mainClass 则是 --class 带的全类名
new JavaMainApplication(mainClass)
}
// 调用实例的start()方法并传入参数
app.start(childArgs.toArray, sparkConf)
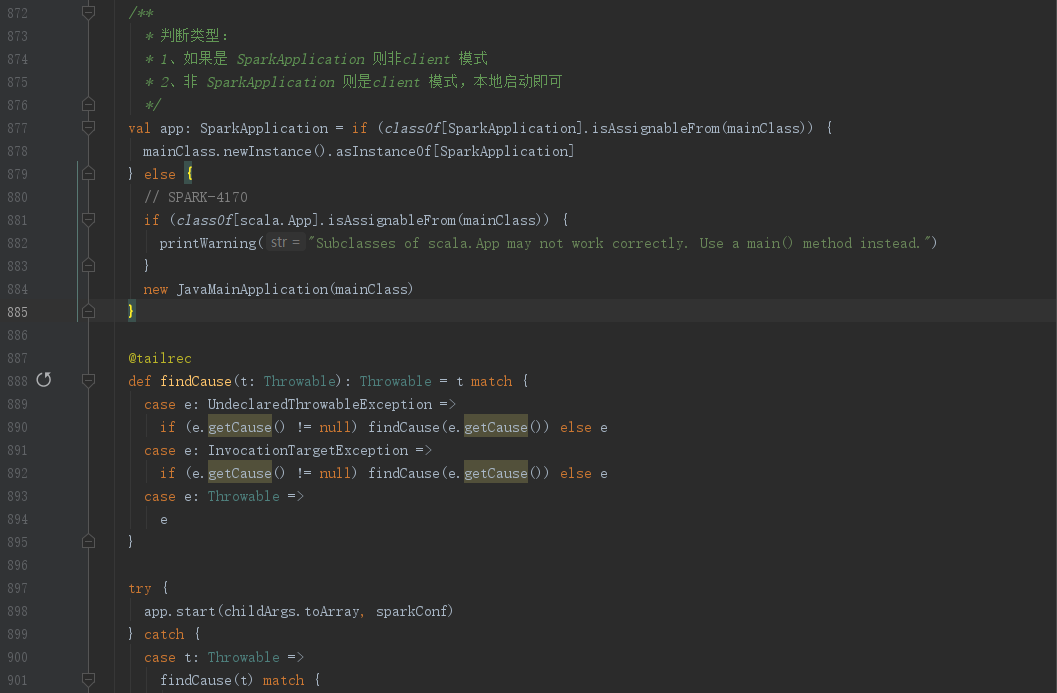
从上面代码逻辑可以知道,如果是Client模式提交的,则是将我们提交的 --class 类通过JavaMainApplication包装一下然后直接本地调用start()启动服务,既:client提交模式,Driver启动在client本地机器上
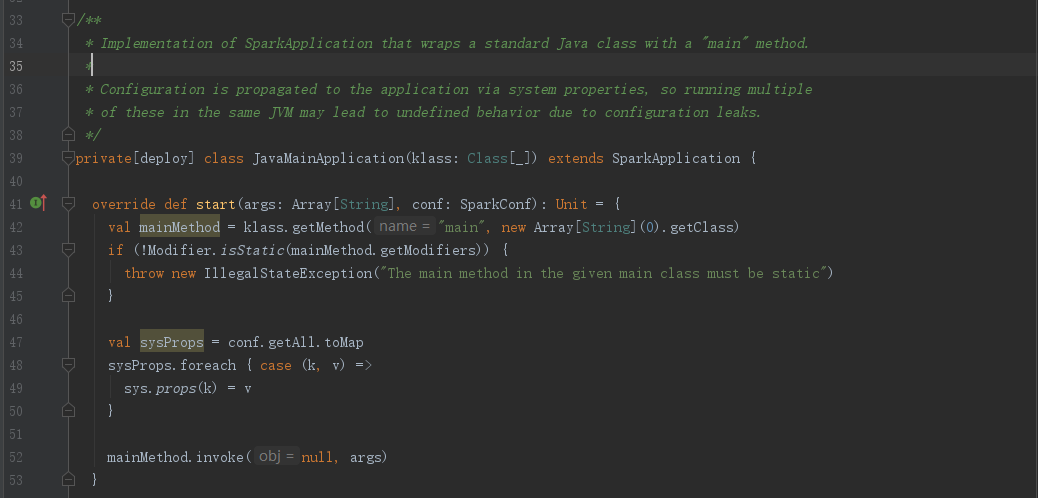
小结:
- Spark提交是通过脚本调用SparkSubmit类,将我们参数进行封装以及校验,判断我们是基于那种提交模式(deployMode)来决定我们–main-class提交的类代码执行的位置
- client模式,执行mainClass则是在本地机器
- cluster模式,则是将mainClass封装成参数,传给ClientAPP进行下一步操作
下面我们把调用流程用图表示下

4、SparkSubmit提交流程02-ClientApp
由于本篇文章采用的是spark-cluster模式,mainClass是ClientApp,接下来我们看下,ClientApp.start()方法
由前面的文章Spark基础06-Spark client和cluster提交流程我们知道,Client需要与Master进行通信申请启动Driver,既我们可以猜测,Client需要有RpcEnv环境,同时要与Master进行通信,还需要获取Master的引用,下面我们从源码看下是否与我们猜测相符
代码逻辑如下,与我们猜测的一致,RpcEnv环境,Master引用,在源码里可以看到,另外我们关注下将driverArgs参数以及Master引用传入到ClientEndpoint端点类,并且通过rpcEnv.setupEndpoint()方法进行端点注册,读过之前文章Spark源码解析01-Master启动流程,肯定知道,在注册端点的时候会伴随这调用端点的onStart()方法,将服务启动,接下来我们需要关注点就是ClientEndpoint类的onStart()方法
// 参数转化为Driver参数
val driverArgs = new ClientArguments(args)
// 准备RpcEnv
val rpcEnv =
RpcEnv.create("driverClient", Utils.localHostName(), 0, conf, new SecurityManager(conf))
// 得到Master引用
val masterEndpoints = driverArgs.masters.map(RpcAddress.fromSparkURL).
map(rpcEnv.setupEndpointRef(_, Master.ENDPOINT_NAME))
// 注册ClientEndpoint端点
rpcEnv.setupEndpoint("client", new ClientEndpoint(rpcEnv, driverArgs, masterEndpoints, conf))
进入ClientEndpoint.onStart()方法,我们可以看到一个重要的参数mainClass = “org.apache.spark.deploy.worker.DriverWrapper”这个参数看起来与我们要启动Driver很相似,下面我们简化代码逻辑
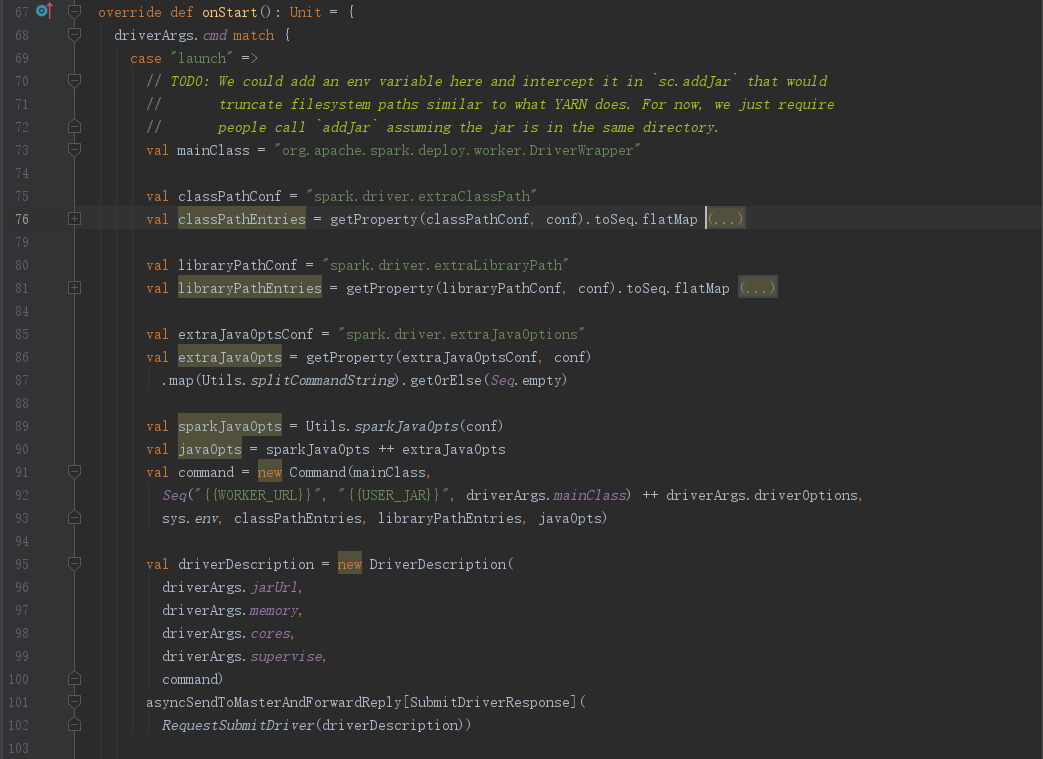
mainClass以及driverArgs最后被封装到DriverDescription对象中,然后调用asyncSendToMasterAndForwardReply()想Master发送RequestSubmitDriver消息
// 定义mainClass
val mainClass = "org.apache.spark.deploy.worker.DriverWrapper"
val command = new Command(mainClass,
Seq("{{WORKER_URL}}", "{{USER_JAR}}", driverArgs.mainClass) ++ driverArgs.driverOptions,
sys.env, classPathEntries, libraryPathEntries, javaOpts)
// 将mainClass封装到DriverDescription()中
val driverDescription = new DriverDescription(
driverArgs.jarUrl,
driverArgs.memory,
driverArgs.cores,
driverArgs.supervise,
command)
// 异步向Master发送RequestSubmitDriver消息
asyncSendToMasterAndForwardReply[SubmitDriverResponse](
RequestSubmitDriver(driverDescription))
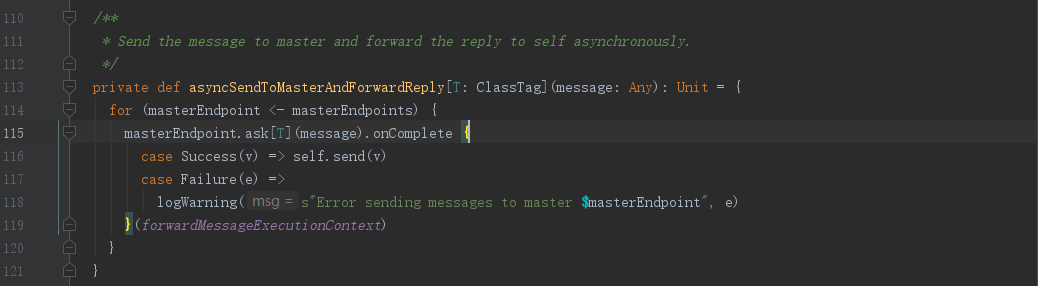
接下来我们看下asyncSendToMasterAndForwardReply()方法,通过Master端点引用,向Master发送RequestSubmitDriver消息,注意:此处用的是ask()方法,所以我们要去对应的Master.receiveAndReply()方法中寻找相应消息处理逻辑
小结:
- org.apache.spark.deploy.worker.DriverWrapper可能是要启动的Driver类
- ClientAPP类的作用就为了与Master通信做准备,如:启动的Driver全类名,以及Driver所需要的参数,同时ClientAPP也准备好了RpcEnv通信环境,并将所需的参数封装到DriverDescription对象中,最后异步向所持有的所有Master引用发送消息RequestSubmitDriver
下面我们将调用流程图补充下

5、SparkSubmit提交流程03-Master
前面我们已经知道了,ClientAPP向Master发送RequestSubmitDriver消息,并且将必须参数分装到DriverDescription中,下面我们回到Master类的receiveAndReply(),知道RequestSubmitDriver消息的处理逻辑,可以看到通过调用createDriver(description)并返回一个driver
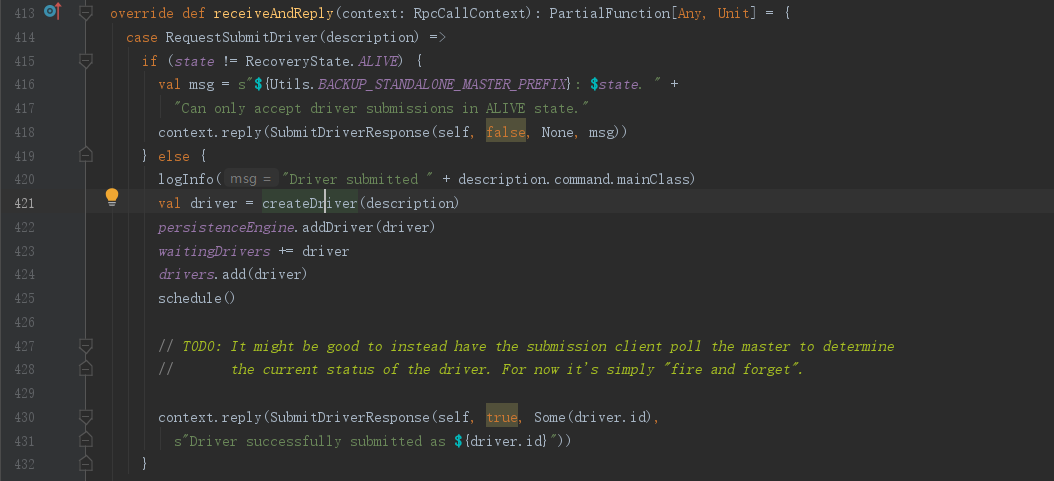
进入Master.createDriver()方法,看到这里只是将参数desc进行了封装,转换成DriverInfo对象并返回

我们回到receiveAndReply()方法,从代码逻辑来看,将driver参数封装成DriverInfo后,就全部存储到Master的driver信息集合中,然后调用schedule()方法,最后就是返回消息给Client;
这边我们可以看到没有任何关于Driver启动的操作,也就剩下schedule()方法来启动Driver
// 将driver参数进一步封装为 DriverInfo
val driver = createDriver(description)
// 加入集合
persistenceEngine.addDriver(driver)
waitingDrivers += driver
drivers.add(driver)
// 调度
schedule()
// 返回信息
context.reply(SubmitDriverResponse(self, true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}"))
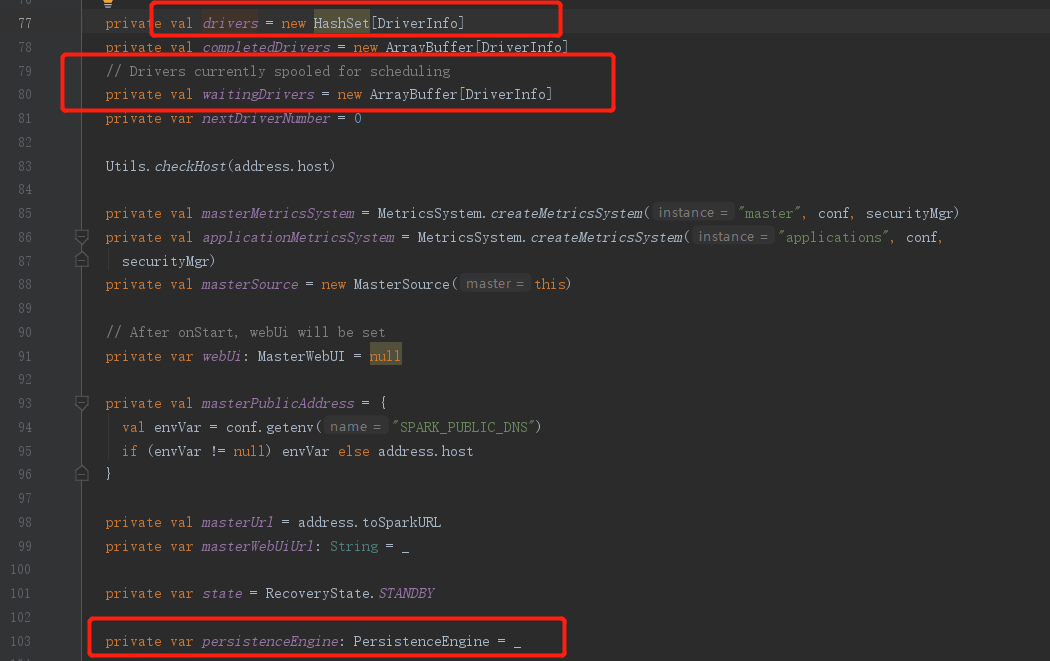
相信看过之前的文章Spark源码解析02-Worker启动流程以及与Master心跳通信的人,对schedule()方法并不陌生,因为在注册Worker的时候也调用了schedule()方法,但是并未研究该方法的用途,现在我们来研究下schedule()
进入schedule()方法,首先要关注的就是注释:“为等待的应用程序调度当前可用资源,每当有新的应用程序加入或资源可用性发生变化时,就会调用此方法”,我们可以简单理解,所有涉及到资源调度的都会调用该方法,既:Driver、Worker等申请资源操作
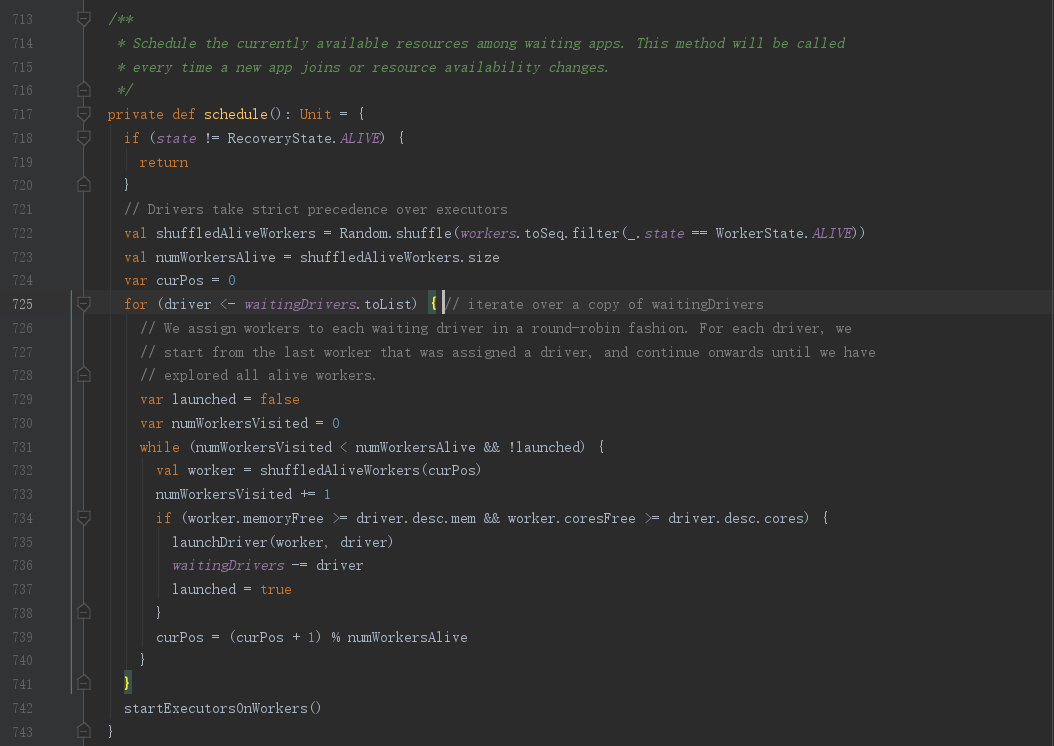
从前面我们知道,Master将Driver的参数信息存入到遇Driver相关的集合中,例:waitingDrivers、drivers、persistenceEngine,下面我们简化下代码逻辑,
- Driver相关
- 遍历等待启动的Driver信息集合
- 寻找符合要求的Worker
- 调用launchDriver()方法来启动Driver
private def schedule(): Unit = {
// 寻找还活着的Worker
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
/*
* 1、Driver相关调度
*/
// 1.1、遍历等待集合中的Driver
for (driver <- waitingDrivers.toList) {
var launched = false
var numWorkersVisited = 0
// 1.2、寻找合适的Worker
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
// 1.3、启动Driver
launchDriver(worker, driver)
waitingDrivers -= driver
launched = true
}
curPos = (curPos + 1) % numWorkersAlive
}
}
/*
* Worker相关调度
*/
startExecutorsOnWorkers()
}
下面我们看下launchDriver()启动Driver方法,将Driver信息记录在Worker中,然后拿着worker的引用,向Worker发送LaunchDriver消息,并将driver信息传递过去

小结:
- Master所需要做的就是通过获取Driver信息,在自己管理的Worker集合中寻找符合要求启动的Worker,然后向Worker发送LaunchDriver方法来启动Driver
6、SparkSubmit提交流程04-Worker
回到Worker.receive()方法,我们找到对应的LaunchDriver消息处理流程,可以看到将Driver信息封装到DriverRunner类中,然后调用start()方法,启动Driver,更新Worker使用信息
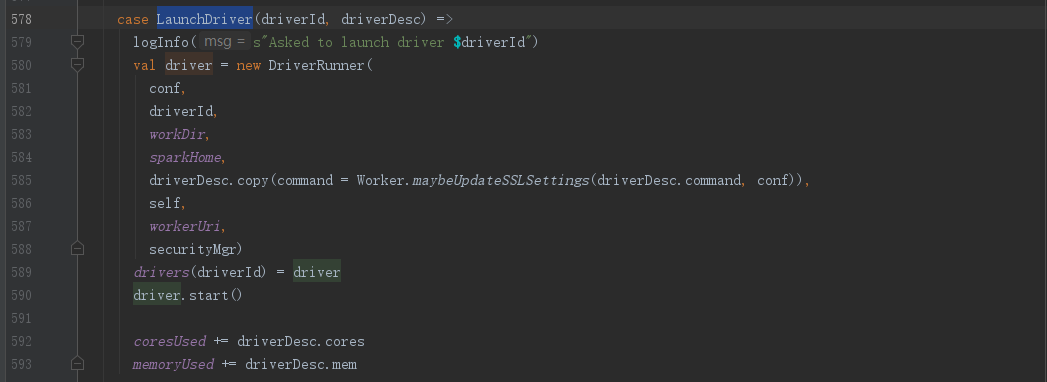
这边我们进入DriverRunner.start()方法,这边我们不必太过关注Driver启动的细节,因为java启动进程的实现在Window和Linux平台的实现是不一样的,我们只需知道启动的Driver正是前面我们所熟知的org.apache.spark.deploy.worker.DriverWrapper类
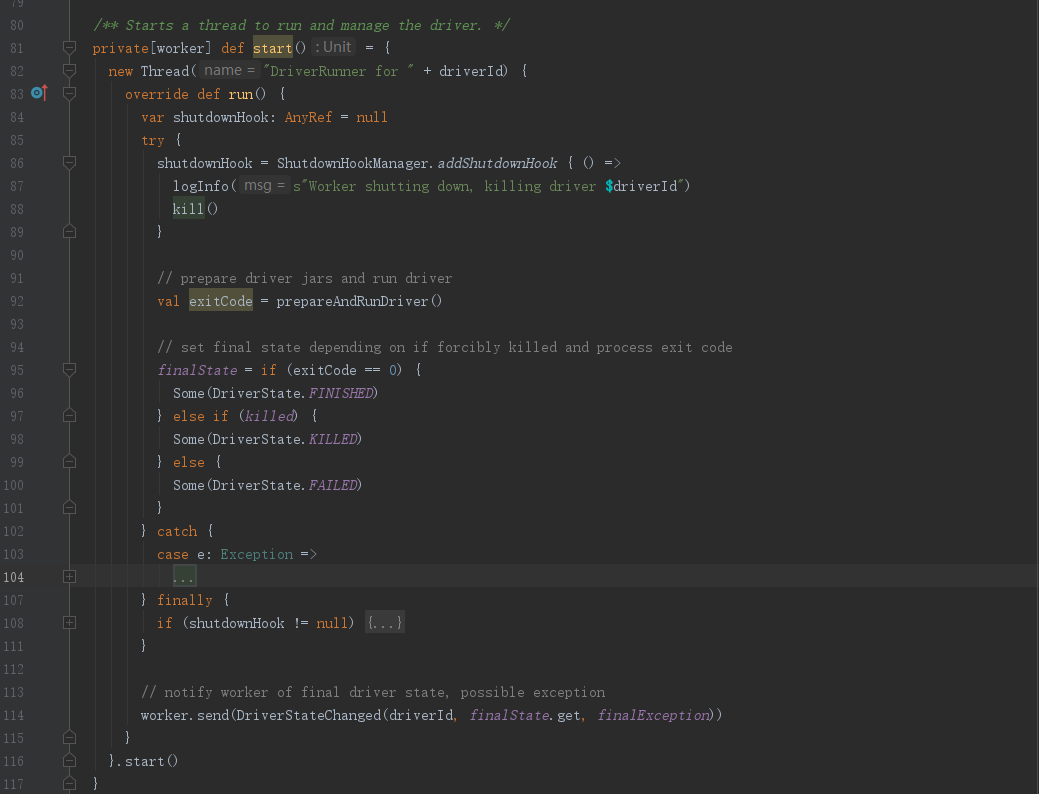
回到DriverWrapper类,我们可以看到这里又有一个mainClass,这个mainClass就是我们通过–class提交的那个全类名,从代码逻辑我们看到,mainClass在DriverWrapper中会被反射创建,并最后调用invoke()方法,执行其main方法,可见,DriverWrapper运行了我们提交的代码,也就是DriverWrapper正是Driver的实例
至此,我们关于Driver的启动流程已经全部跟踪完毕
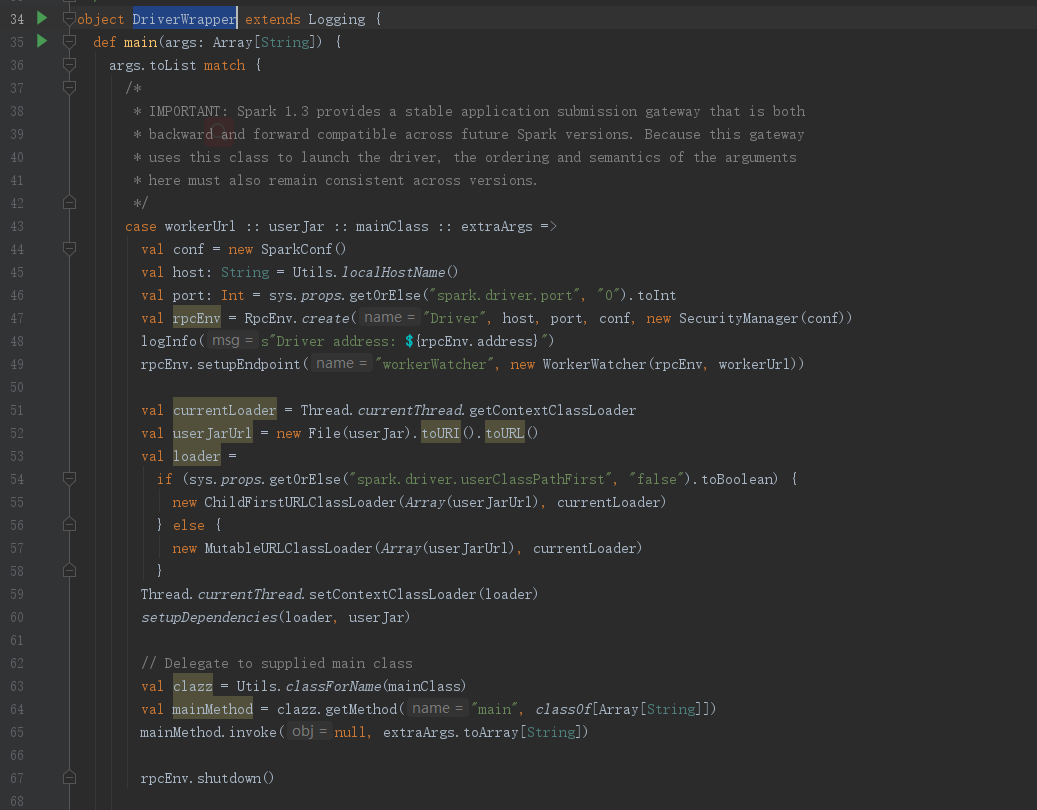
小结:
- Worker则是通过接收到的Driver信息,在自己的机器上启动Driver,也就是启动参数传递中的mainClass org.apache.spark.deploy.worker.DriverWrapper类
- 从源码可以证实org.apache.spark.deploy.worker.DriverWrapper就是我们所熟知的Driver实例
- 至此,Driver启动流程基本完成
7、总结
- Spark的提交流程中涉及角色分别是:
- (SparkSubmit -->) Client --> Master --> Worker --> Executor --> Driver
- (对于spark-cluster而言)Client的实例是ClientApp,Driver的实例则是DriverWrapper
- 结合前面的文章我们已经跟踪完,Spark的资源层、以及计算层的开端源码,下面将是Spark源码解析的重头戏,SparkContext源码的解析
最后
以上就是野性河马最近收集整理的关于Spark源码解析03-Submit提交流程及Driver启动流程的全部内容,更多相关Spark源码解析03-Submit提交流程及Driver启动流程内容请搜索靠谱客的其他文章。








发表评论 取消回复