算法的背景:
卷积神经网络:卷积神经网络是神经网络中十分重要的一种网络,如今几乎所有的深度学习的经典模型中都能找到卷积神经网络的身影,他成功解决了参数过多的问题,并且达到了全连接神经网络实现不了的效果,就比如说我在我的上一篇博客中用到的对手势进行分类的全连接神经网络一共用到了(4900*7+7)=34307个参数,这还仅仅是一层的全连接神经网络,再加几层参数还会疯狂的增长,而卷积神经网络只需要很少的参数。算法的运算过程:
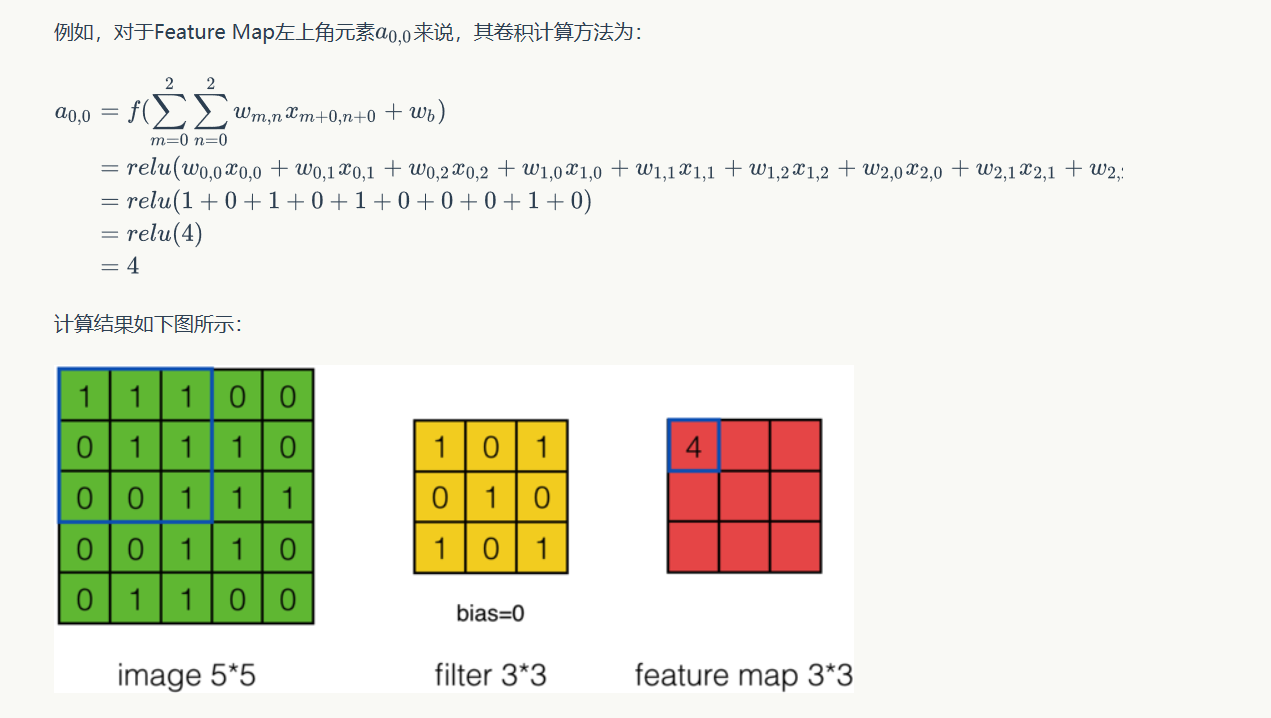 依次类推就能算出feature map。
依次类推就能算出feature map。
Sobel算子:Sobel算子就是一种特殊的filter。
python代码实现
1.图片轮廓提取
# * coding:utf-8 *
# 作者:Little Bear
# 创建时间:2020/2/5 16:56
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from skimage import io, transform
image = io.imread("image/bear.jpg")
print(image)
image = np.reshape(image, [1, 320, 320, 3])
# plt.imshow(image)
# plt.axis("off")
# plt.show()
input = tf.Variable(tf.constant(1.0, shape=[1, 320, 320, 3]))
#定义filter也就是sobel算子
filter= tf.Variable(tf.constant([[-1.0, -1.0, -1.0], [0, 0, 0], [1.0, 1.0, 1.0],
[-2.0, -2.0, -2.0], [0, 0, 0], [2.0, 2.0, 2.0],
[-1.0, -1.0, -1.0], [0, 0, 0], [1.0, 1.0, 1.0]], shape=[3, 3, 3, 1]))
#定义卷积操作
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
#归一化操作
o = tf.cast(((op - tf.reduce_min(op)) / (tf.reduce_max(op) - tf.reduce_min(op))) * 255, tf.uint8)
print(image.shape)
with tf.Session() as sess:
#初始化
sess.run(tf.global_variables_initializer())
#运行静态模型
t, f = sess.run([o, filter], feed_dict={input: image})
t = np.reshape(t, [320, 320])
plt.imshow(t, cmap='Greys_r') # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
显示效果(我的小熊):

2.调用摄像头当前场景轮库提取
# * coding:utf-8 *
# 作者:Little Bear
# 创建时间:2020/2/5 16:56
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from skimage import io, transform
import pylab
import cv2
import imageio
import skimage
input = tf.Variable(tf.constant(1.0, shape=[1, 500, 700, 3]))
filter= tf.Variable(tf.constant([[-1.0, -1.0, -1.0], [0, 0, 0], [1.0, 1.0, 1.0],
[-2.0, -2.0, -2.0], [0, 0, 0], [2.0, 2.0, 2.0],
[-1.0, -1.0, -1.0], [0, 0, 0], [1.0, 1.0, 1.0]], shape=[3, 3, 3, 1]))
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
o = tf.cast(((op - tf.reduce_min(op)) / (tf.reduce_max(op) - tf.reduce_min(op))) * 255, tf.uint8)
cap = cv2.VideoCapture(0)
success, frame = cap.read()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
while success and cv2.waitKey(1) == -1:
success, frame = cap.read()
frame=transform.resize(frame,[500,700])
frame = np.reshape(frame, [1, 500, 700, 3])
t, f = sess.run([o, filter], feed_dict={input: frame})
t = np.reshape(t, [500, 700])
cv2.imshow("Main Window", t)
cap.release()
cv2.destroyAllWindows()
这段代码可以调用电脑的前置摄像头获取当前场景转化为轮廓图并显示:
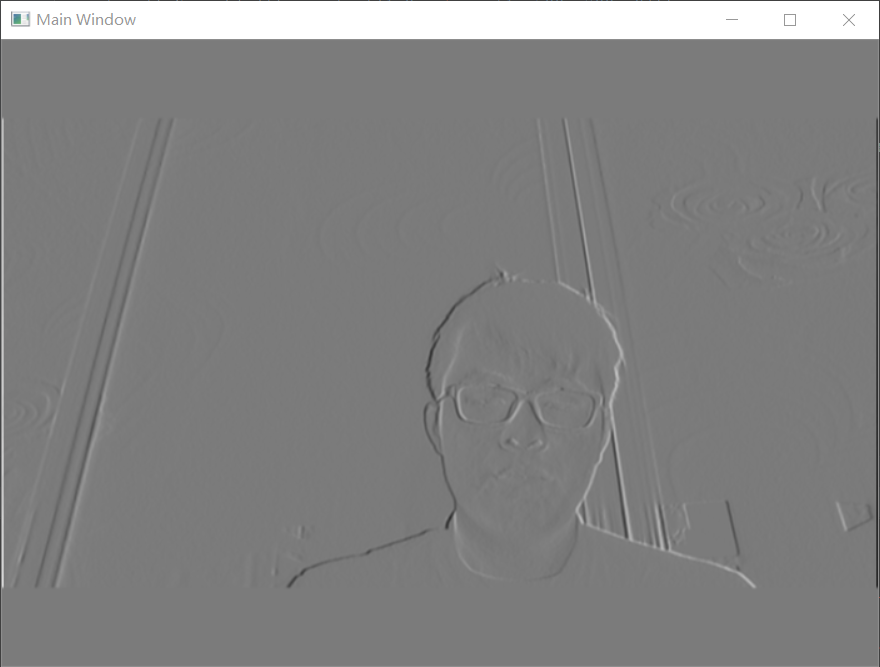
ps(我发现这个小程序可以有效的检查你的牙齐不齐,真的,不信你呲牙试试。。。)
最后
以上就是多情芹菜最近收集整理的关于卷积神经网络实战——使用sobel因子提取图片和视频轮廓(调用前置摄像头)的全部内容,更多相关卷积神经网络实战——使用sobel因子提取图片和视频轮廓(调用前置摄像头)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复