要想深入学习Hadoop分布式文件系统,首先需要搭建Hadoop的实验环境,Hadoop有两种安装模式,即单节点集群模式安装(也称为伪分布式)和完全分布式模式安装,本节只介绍单节点模式的安装,参考官方文档:
http://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-common/SingleCluster.html
由于Hadoop是运行在Linux/Unix平台,如果读者使用的是Windows操作系统,需要在虚拟机中搭建Linux运行环境,目前主流的虚拟机产品有vmware和vitualBox,Linux的发行版可以根据个人喜好自行选择,笔者使用的是vmware和ubuntu系统。
搭建Hadoop单节点安装环境需要以下几个步骤:
一.安装JDK,对于Ubuntu系统可以使用apt-get工具进行安装:
sudo apt-get install openjdk-7-jdk二.获取Hadoop软件包,下载地址:http://hadoop.apache.org/releases.html
笔者选择的版本为2.7.1,下载完后解压到任意目录下。hadoop的目录结构也比较简单,如下图所示:
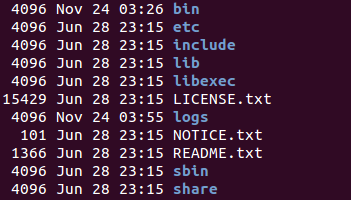
bin目录下存放最基本的管理脚本和使用脚本,用户可以使用这些脚本管理和使用Hadoop
etc目录下存放hadoop所有的配置文件,包括我们接下来会关注的core-site.xml、hdfs-site.xml等
include提供对为编程的c++的头文件,用于c++程序访问HDFS或编写MR程序等
lib为对外提供的静态库和动态库文件,与include目录下的头文件结合使用
libexec为各个服务所对应的shell配置文件所在目录,可用于配置日志输出目录、启动参数(比如JVM参数)等基本信息
sbin为hadoop管理脚本所在目录,主要包括HDFS和YARN中各类服务的启动/关闭脚本
share为各个模块编译后的jar包所在目录
三.修改Hadoop配置
1.修改hadoop解压目录下的 etc/hadoop/hadoop-env.sh文件
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration><configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>1.格式化文件系统:
bin/hdfs namenode -formatsbin/start-dfs.shps -ef|grep hadoop3.在web浏览器中访问NameNode的web接口,默认地址为:http://localhost:50070/
如果出现上图所示界面说明hadoop启动成功。
4.创建HDFS目录用于执行MapReduce任务:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>
$ bin/hdfs dfs -put etc/hadoop input$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output 'dfs[a-z.]+'$ sbin/stop-dfs.sh转载于:https://www.cnblogs.com/lanzhi/p/6468464.html
最后
以上就是美满黑猫最近收集整理的关于Hadoop学习笔记(一)Hadoop的单节点安装的全部内容,更多相关Hadoop学习笔记(一)Hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复