Android实现手部检测和手势识别(可实时运行,含Android源码)
目录
Android实现手部检测和手势识别(可实时运行,含Android源码)
1. 前言
2. 手势识别的方法
(1)基于多目标检测的手势识别方法
(2)基于手部检测+手势分类识别方法
3. 手势识别数据集说明
(1)HaGRID手势识别数据集
(2)自定义数据集
4. 基于YOLOv5的手势识别训练
5.手势识别模型Android部署
(1) 将Pytorch模型转换ONNX模型
(2) 将ONNX模型转换为TNN模型
(3) Android端上部署手势识别模型
(4) 一些异常错误解决方法
6. 手势识别测试效果
7.项目源码下载
1. 前言
本篇博客是《基于YOLOv5的手势识别系统(含手势识别数据集+训练代码)》续作Android篇,主要分享将Python训练后的YOLOv5手势识别模型移植到Android平台。我们将开发一个简易的手势动作识别Android Demo。Demo支持one,two,ok等18种常见的通用手势动作识别,也可以根据业务需求自定义训练的手势识别的类别。

考虑到原始YOLOv5的模型计算量比较大,鄙人在YOLOv5s基础上,开发了一个非常轻量级的的手势识别模型yolov5s05。从效果来看,Android手势识别Demo性能还是顶呱呱的,平均精度平均值mAP_0.5=0.99421,mAP_0.5:0.95=0.82706。APP在普通Android手机上可以达到实时的手势识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
先展示一下Android Demo效果:
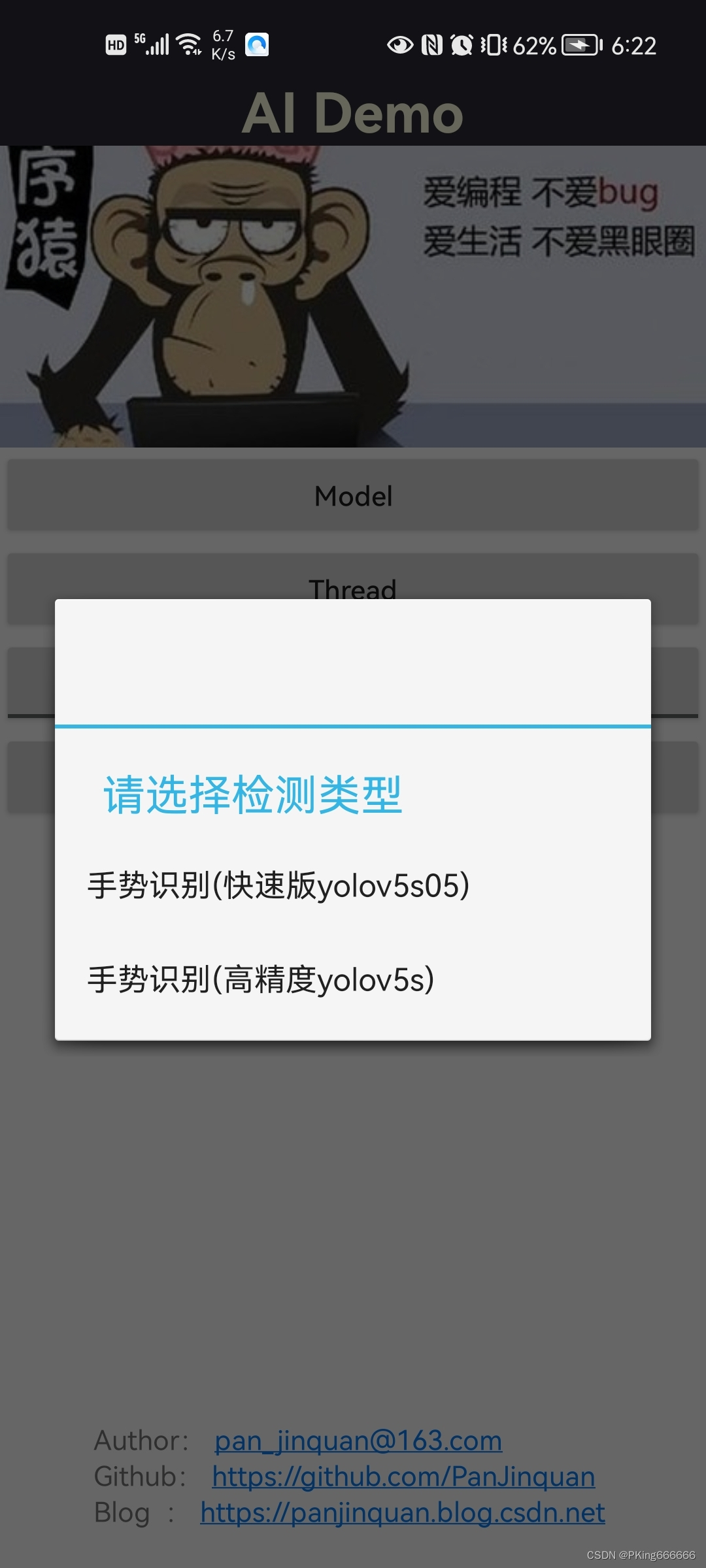 |  | |
【Android APP体验】https://download.csdn.net/download/guyuealian/86666991
【Android源码下载】 Android实现手部检测和手势识别
【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/126994546
2. 手势识别的方法
(1)基于多目标检测的手势识别方法
基于多目标检测的手势识别方法,一步到位,把手势类别直接当成多个目标检测的类别进行训练。
- 该方案采用one-stage的方法,直接端到端训练,任务简单,速度较快;
- 新增类别或者数据,需要人工拉框标注手势,成本较大
- 需要均衡采集的不同手势类别的样本数
- 部署简单
(2)基于手部检测+手势分类识别方法
该方法,先训练一个通用的手部检测模型(不区分手势,只检测手部框),然后裁剪手部区域,再训练一个手势分类器,完成对不同手势的分类识别。
- 该方案采用two-stage方法,可针对性分别提高检测模型和分类模型的性能
- 手部检测模型不区分手势,只检测手部框,检测精度较高,
- 手势分类模型可以做到很轻量
- 手势分类数据比较容易采集(你可以采集一个动手一个视频,这样经过手部检测裁剪下来的图片都是同一个类别的动作,减少人工拉框标注手势的成本)
- 由于采用two-stage方法进行检测-识别,因此速度相对较慢
考虑到HaGRID手势识别数据集,所有图片已经标注了手势类别和检测框,因此采用“基于多目标检测的手势识别方法”更为简单。本篇博客就是基于多目标检测的手势识别方法,多目标检测的的方法较多,比如Faster-RCNN,YOLO系列,SSD等均可以采用,本博客将采用YOLOv5进行多目标检测的手势识别训练。
如果你的数据集仅有部分检测框,但手势分类图片的数据集比较容易采集,建议使用“基于手部检测+手势分类识别方法”,毕竟这方案标注成本比较低。若你需要这个方案,可以微信公众号联系我。
3. 手势识别数据集说明
(1)HaGRID手势识别数据集
原始的HaGRID数据集非常大,图片都是高分辨率(1920 × 1080)200W像素,完整下载HaGRID数据集,至少需要716GB的硬盘空间。另外,由于是外网链接,下载可能经常掉线。
考虑到这些问题,本人对HaGRID数据集进行精简和缩小分辨率,目前整个数据集已经压缩到18GB左右,可以满足手势识别分类和检测的任务需求,为了有别于原始数据集,该数据集称为Light-HaGRID数据集,即一个比较轻量的手势识别数据集。
- 提供手势动作识别数据集,共18个手势类别,每个类别约含有7000张图片,总共123731张图片(12W+)
- 提供所有图片的json标注格式文件,即原始HaGRID数据集的标注格式
- 提供所有图片的XML标注格式文件,即转换为VOC数据集的格式
- 提供所有手势区域的图片,每个标注框的手部区域都裁剪下来,并保存在Classification文件夹下
- 可用于手势目标检测模型训练
- 可用于手势分类识别模型训练
关于《HaGRID手势识别数据集使用说明和下载》,请参考鄙人另一篇博客,
HaGRID手势识别数据集使用说明和下载_PKing666666的博客-CSDN博客
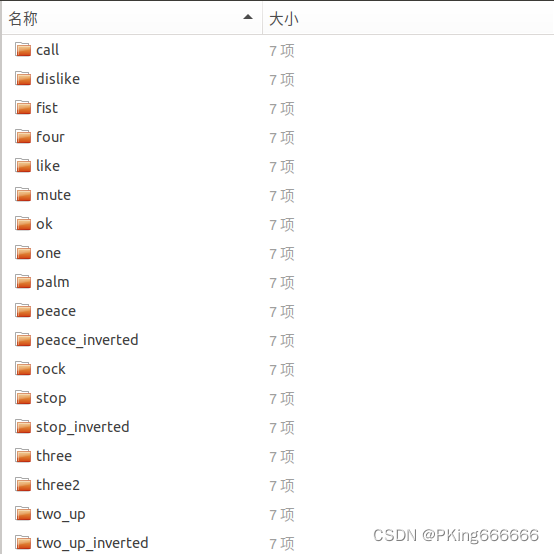
(2)自定义数据集
如果需要增/删类别数据进行训练,或者需要自定数据集进行训练,可参考如下步骤:
- 采集手势图片,建议不少于200张图片
- 使用Labelme等标注工具,对手势拉框标注:labelme工具:GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
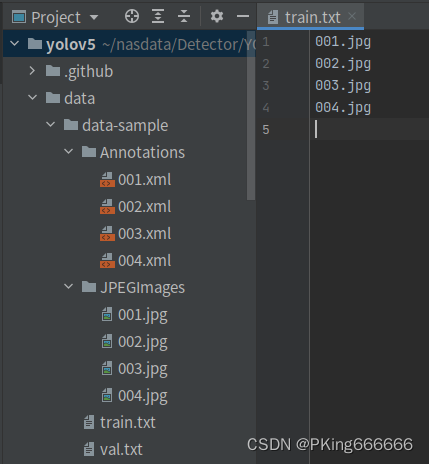
- 将标注格式转换为VOC数据格式,参考工具:labelme/labelme2voc.py at main · wkentaro/labelme · GitHub
- 生成训练集train.txt和验证集val.txt文件列表
- 修改engine/configs/voc_local.yaml的train和val的数据路径
- 重新开始训练
4. 基于YOLOv5的手势识别训练
考虑到手机端CPU/GPU性能比较弱鸡,直接部署yolov5s运行速度十分慢,所以这里Android部署仅仅考虑yolov5s05模型,yolov5s05即是在yolov5s的基础上做了模型轻量化处理,其channels通道数全部都减少一半,并且模型输入由原来的640×640降低到320×320。从性能来看,yolov5s05比yolov5s快5多倍,而mAP下降了5%(0.87605→0.82706),对于手机端,这精度还是可以接受。
官方YOLOv5: https://github.com/ultralytics/yolov5
下面是yolov5s05和yolov5s的参数量和计算量对比:
| 模型 | input-size | params(M) | GFLOPs | 手势识别mAP(0.5:0.95) |
| yolov5s | 640×640 | 7.2 | 16.5 | 0.87605 |
| yolov5s05 | 320×320 | 1.7 | 1.1 | 0.82706 |
yolov5s05和yolov5s训练过程完全一直,仅仅是配置文件不一样而已;碍于篇幅,本篇博客不在赘述,详细训练过程请参考:《基于YOLOv5的手势识别系统(含手势识别数据集+训练代码)》
5.手势识别模型Android部署
(1) 将Pytorch模型转换ONNX模型
训练好yolov5s05或者yolov5s模型后,你需要将模型转换为ONNX模型,并使用onnx-simplifier简化网络结构
# 转换yolov5s05模型
python export.py --weights "runs/yolov5s05_320/weights/best.pt" --img-size 320 320
# 转换yolov5s模型
python export.py --weights "runs/yolov5s_640/weights/best.pt" --img-size 640 640GitHub: https://github.com/daquexian/onnx-simplifier
Install: pip3 install onnx-simplifier
(2) 将ONNX模型转换为TNN模型
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署:
TNN转换工具:
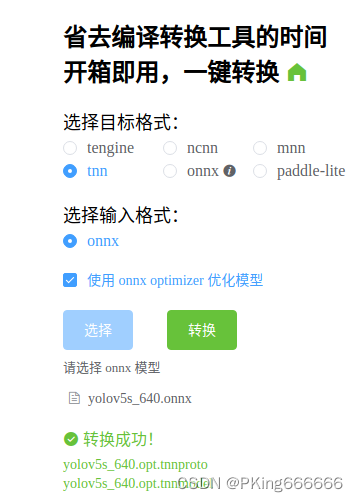
- (1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master · Tencent/TNN · GitHub
- (2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine (可能存在版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换,2022年9约25日测试可用)
(3) Android端上部署手势识别模型
项目实现了Android版本的手势动作识别Demo,部署框架采用TNN,支持多线程CPU和GPU加速推理,在普通手机上可以实时处理。Android源码核心算法均采用C++实现,上层通过JNI接口调用.
如果你想在这个Android Demo部署你自己训练的模型,你可将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把TNN模型代替你模型即可。
package com.cv.tnn.model;
import android.graphics.Bitmap;
public class Detector {
static {
System.loadLibrary("tnn_wrapper");
}
/***
* 初始化模型
* @param model: TNN *.tnnmodel文件文件名(含后缀名)
* @param root:模型文件的根目录,放在assets文件夹下
* @param model_type:模型类型
* @param num_thread:开启线程数
* @param useGPU:关键点的置信度,小于值的坐标会置-1
*/
public static native void init(String model, String root, int model_type, int num_thread, boolean useGPU);
/***
* 检测
* @param bitmap 图像(bitmap),ARGB_8888格式
* @param score_thresh:置信度阈值
* @param iou_thresh: IOU阈值
* @return
*/
public static native FrameInfo[] detect(Bitmap bitmap, float score_thresh, float iou_thresh);
}
(4) 一些异常错误解决方法
-
TNN推理时出现:Permute param got wrong size
官方YOLOv5: https://github.com/ultralytics/yolov5
如果你是直接使用官方YOLOv5代码转换TNN模型,部署TNN时会出现这个错误Permute param got wrong size,这是因为TNN最多支持4个维度计算,而YOLOv5在输出时采用了5个维度。你需要修改model/yolo.py文件
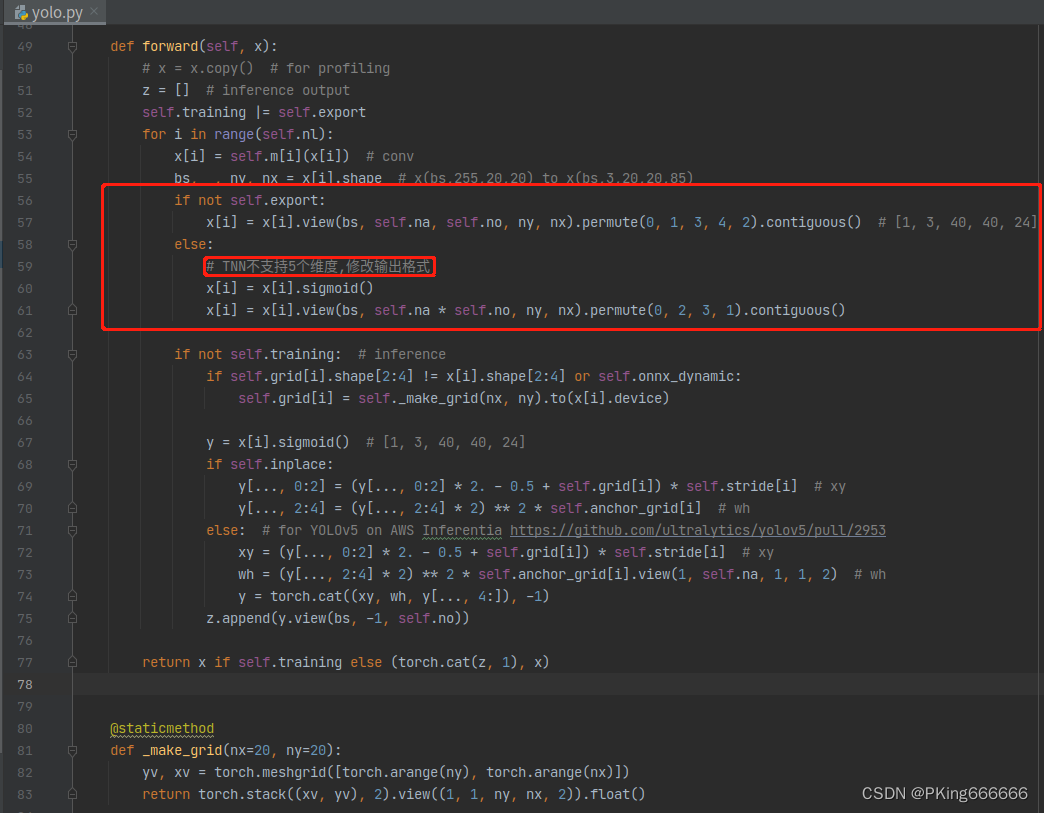
export.py文件设置model.model[-1].export = True:
"""Export a YOLOv5 *.pt model to TorchScript, ONNX, CoreML formats
Usage:
$ python path/to/export.py --weights yolov5s.pt --img 640 --batch 1
"""
import argparse
import sys
import time
from pathlib import Path
import torch
import torch.nn as nn
from torch.utils.mobile_optimizer import optimize_for_mobile
FILE = Path(__file__).absolute()
sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to path
from models.common import Conv
from models.yolo import Detect
from models.experimental import attempt_load
from utils.activations import Hardswish, SiLU
from utils.general import colorstr, check_img_size, check_requirements, file_size, set_logging
from utils.torch_utils import select_device
def export_torchscript(model, img, file, optimize):
# TorchScript model export
prefix = colorstr('TorchScript:')
try:
print(f'n{prefix} starting export with torch {torch.__version__}...')
f = str(file.with_suffix('.torchscript.pt'))
ts = torch.jit.trace(model, img, strict=False)
(optimize_for_mobile(ts) if optimize else ts).save(f)
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return ts
except Exception as e:
print(f'{prefix} export failure: {e}')
def export_onnx(model, img, file, opset, train, dynamic, simplify):
# ONNX model export
prefix = colorstr('ONNX:')
try:
check_requirements(('onnx', 'onnx-simplifier'))
import onnx
print(f'n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
torch.onnx.export(model, img, f, verbose=False, opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# print(onnx.helper.printable_graph(model_onnx.graph)) # print
# Simplify
if simplify:
try:
import onnxsim
print(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(
model_onnx,
dynamic_input_shape=dynamic,
input_shapes={'images': list(img.shape)} if dynamic else None)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
except Exception as e:
print(f'{prefix} simplifier failure: {e}')
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
print(f"{prefix} run --dynamic ONNX model inference with detect.py: 'python detect.py --weights {f}'")
except Exception as e:
print(f'{prefix} export failure: {e}')
def export_coreml(model, img, file):
# CoreML model export
prefix = colorstr('CoreML:')
try:
import coremltools as ct
print(f'n{prefix} starting export with coremltools {ct.__version__}...')
f = file.with_suffix('.mlmodel')
model.train() # CoreML exports should be placed in model.train() mode
ts = torch.jit.trace(model, img, strict=False) # TorchScript model
model = ct.convert(ts, inputs=[ct.ImageType('image', shape=img.shape, scale=1 / 255.0, bias=[0, 0, 0])])
model.save(f)
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'n{prefix} export failure: {e}')
def run(weights='./yolov5s.pt', # weights path
img_size=(640, 640), # image (height, width)
batch_size=1, # batch size
device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
include=('torchscript', 'onnx', 'coreml'), # include formats
half=False, # FP16 half-precision export
inplace=True, # set YOLOv5 Detect() inplace=True
train=False, # model.train() mode
optimize=False, # TorchScript: optimize for mobile
dynamic=False, # ONNX: dynamic axes
simplify=True, # ONNX: simplify model
opset=12, # ONNX: opset version
):
t = time.time()
include = [x.lower() for x in include]
img_size *= 2 if len(img_size) == 1 else 1 # expand
file = Path(weights)
# Load PyTorch model
device = select_device(device)
assert not (device.type == 'cpu' and half), '--half only compatible with GPU export, i.e. use --device 0'
model = attempt_load(weights, map_location=device) # load FP32 model
names = model.names
# Input
gs = int(max(model.stride)) # grid size (max stride)
img_size = [check_img_size(x, gs) for x in img_size] # verify img_size are gs-multiples
img = torch.zeros(batch_size, 3, *img_size).to(device) # image size(1,3,320,192) iDetection
# Update model
if half:
img, model = img.half(), model.half() # to FP16
model.train() if train else model.eval() # training mode = no Detect() layer grid construction
for k, m in model.named_modules():
if isinstance(m, Conv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
elif isinstance(m, Detect):
m.inplace = inplace
m.onnx_dynamic = dynamic
# m.forward = m.forward_export # assign forward (optional)
# for _ in range(2):
# y = model(img) # dry runs
print(f"n{colorstr('PyTorch:')} starting from {weights} ({file_size(weights):.1f} MB)")
# Exports
if 'torchscript' in include:
model.model[-1].export = True # TNN不支持5个维度,修改输出格式
export_torchscript(model, img, file, optimize)
if 'onnx' in include:
model.model[-1].export = True # TNN不支持5个维度,修改输出格式
export_onnx(model, img, file, opset, train, dynamic, simplify=simplify)
if 'coreml' in include:
export_coreml(model, img, file)
# Finish
print(f'nExport complete ({time.time() - t:.2f}s)'
f"nResults saved to {colorstr('bold', file.parent.resolve())}"
f'nVisualize with https://netron.app')
def parse_opt():
"""
python export.py --weights "runs/yolov5s05_320/weights/best.pt" --img-size 320 320
python export.py --weights "runs/yolov5s_640/weights/best.pt" --img-size 640 640
"""
weights = "runs/yolov5s_640/weights/best.pt" # 模型文件yolov5s_640
input_size = [640, 640]
# weights = "runs/yolov5s05_320/weights/best.pt" # 模型文件yolov5s05_320
# input_size = [320, 320]
# default = ['torchscript', 'onnx', 'coreml']
default = ['onnx']
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=weights, help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=input_size, help='image (height, width)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--include', nargs='+', default=default, help='include formats')
# parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
# parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
# parser.add_argument('--train', action='store_true', help='model.train() mode')
# parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
# parser.add_argument('--dynamic', action='store_true', help='ONNX: dynamic axes')
# parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')
opt = parser.parse_args()
return opt
def main(opt):
set_logging()
print(colorstr('export: ') + ', '.join(f'{k}={v}' for k, v in vars(opt).items()))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
- TNN推理时效果很差,检测框一团麻

这个问题,大部分是模型参数设置错误,需要根据自己的模型,修改C++推理代码YOLOv5Param模型参数。
struct YOLOv5Param {
ModelType model_type; // 模型类型,MODEL_TYPE_TNN,MODEL_TYPE_NCNN等
int input_width; // 模型输入宽度,单位:像素
int input_height; // 模型输入高度,单位:像素
bool use_rgb; // 是否使用RGB作为模型输入(PS:接口固定输入BGR,use_rgb=ture时,预处理将BGR转换为RGB)
bool padding;
int num_landmarks; // 关键点个数
NetNodes InputNodes; // 输入节点名称
NetNodes OutputNodes; // 输出节点名称
vector<YOLOAnchor> anchors;
vector<string> class_names; // 类别集合
};
input_width和input_height是模型的输入大小;vector<YOLOAnchor> anchors需要对应上,注意Python版本的yolov5s的原始anchor是
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
而yolov5s05由于input size由原来640变成320,anchor也需要做对应调整,所以我训练前对手势数据的anchor进行重新聚类,得到输入320×320的anchor为:
anchors:
- [ 12,19, 17,28, 22,34 ]
- [ 25,47, 33,41, 34,59 ]
- [ 49,54, 46,79, 70,92 ]因此C++版本的yolov5s和yolov5s05的模型参数YOLOv5Param如下设置
//YOLOv5s模型参数
static YOLOv5Param YOLOv5s_GESTURE_640 = {MODEL_TYPE_TNN,
640,
640,
true,
true,
0,
{{{"images", nullptr}}}, //InputNodes
{{{"boxes", nullptr}, //OutputNodes
{"scores", nullptr}}},
{
{"434", 32,
{{116, 90}, {156, 198}, {373, 326}}},
{"415", 16, {{30, 61}, {62, 45}, {59, 119}}},
{"output", 8,
{{10, 13}, {16, 30}, {33, 23}}}, //
},
GESTURE_NAME};
//YOLOv5s05模型参数
static YOLOv5Param YOLOv5s05_GESTURE_ANCHOR_320 = {MODEL_TYPE_TNN,
320,
320,
true,
true,
0,
{{{"images", nullptr}}}, //InputNodes
{{{"boxes", nullptr}, //OutputNodes
{"scores", nullptr}}},
{
{"434", 32,
{{49, 54}, {46, 79}, {70, 92}}},
{"415", 16,
{{25, 47}, {33, 41}, {34, 59}}},
{"output", 8,
{{12, 19}, {17, 28}, {22, 34}}}, //
},
GESTURE_NAME};
- 运行APP闪退:dlopen failed: library "libomp.so" not found
参考解决方法:解决dlopen failed: library “libomp.so“ not found_PKing666666的博客-CSDN博客_dlopen failed
6. 手势识别测试效果
Android APP体验 https://download.csdn.net/download/guyuealian/86666991
APP在普通Android手机上可以达到实时的手势识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
| | |
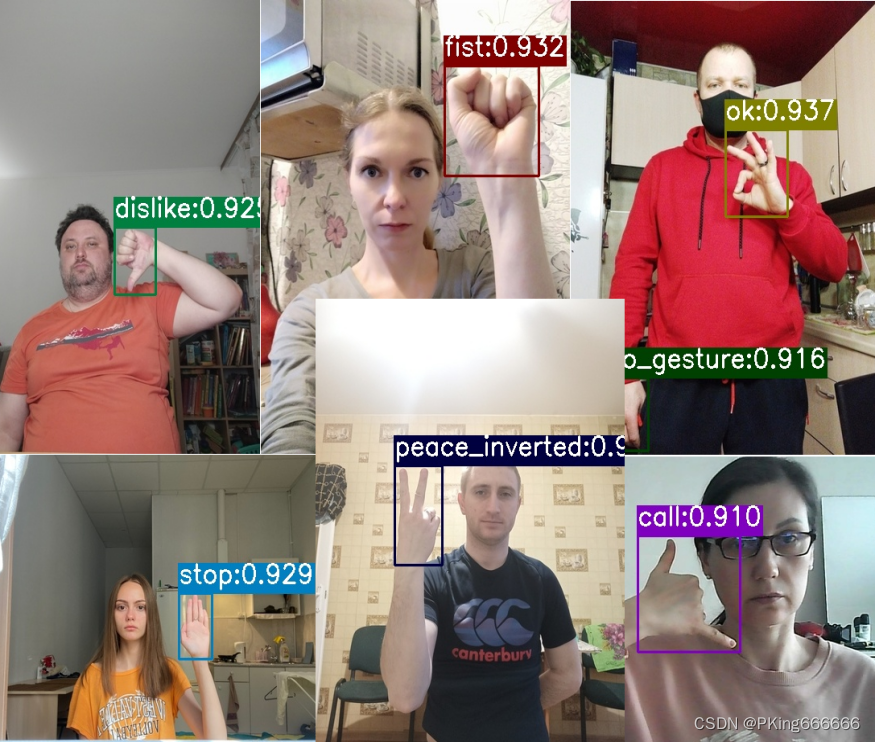
7.项目源码下载
【Android APP体验】https://download.csdn.net/download/guyuealian/86666991
整套Android手势识别项目源码内容下载: Android实现手部检测和手势识别
- 提供快速版yolov5s05手势识别,在普通手机可实时检测识别,CPU(4线程)约30ms左右,GPU约25ms左右
- 提供高精度版本yolov5s手势识别,CPU(4线程)约250ms左右,GPU约100ms左右
整套Android手势识别项目源码
Android Demo支持图片,视频,摄像头测试
所有依赖库都已经配置好,可直接build运行,若运行出现闪退,请参考dlopen failed: library “libomp.so“ not found 解决。
- 如果你需要配套的手势识别数据集:HaGRID手势识别数据集使用说明和下载
- 如果你需要配套的手势识别训练代码:基于YOLOv5的手势识别系统(含手势识别数据集+训练代码)
![]()
最后
以上就是典雅舞蹈最近收集整理的关于Android实现手部检测和手势识别(可实时运行,含Android源码)Android实现手部检测和手势识别(可实时运行,含Android源码)的全部内容,更多相关Android实现手部检测和手势识别(可实时运行内容请搜索靠谱客的其他文章。








发表评论 取消回复