在12月初,我诞生了这个想法。现在的拍摄效果的转换都是人和机器通过物理接触完成,包括开始拍摄,各种拍摄效果等,几乎都是通过手指来完成。人类具有丰富的表达自我的能力,手势是表达自我的手段之一。无论是哪个地域的文化,一些手势都有其含义。在深度学习时代,我们完全可以用手势代替手指,告诉机器我们想做什么样的事情,想调换什么拍摄模式,因此HandAI诞生了。固然手指在更多的场合还是很方便,但我做这个事情,不想去探讨手势控制的价值以及实用性,我只是单纯想做这个事情。
效果展示视频
友情提示:后半段视频声音略大,请调小音量。
项目地址 随手赏个star吧((╹▽╹))。
项目功能
HandAI能识别出8种手势。这八种手势是亚洲地区常用的手势,其意义都是积极或中性的,没有贬义手势。
Note: 如果gif图像没法显示(有些图像较大),可以去github上下载项目,在pictures文件夹中查看。
- one:背景虚化,实现景深效果,前景人物不虚化

- two:背景变化

- three:背景调成黑白模式,前景人物依然有色彩。

- four:人脸贴纸

- five:画面横向复制扩展

- good:视频背景转换模式,当右上角出现红点之后,使用yeah手势(two),即可把背景换成视频数据,而不是单纯的图像。

- eight:华丽防挡弹幕模式。

- ok:结束录制

项目设计思路
项目包括三个深度学习模型,分别是手部关键点检测以及识别(算统一的一个模型), 人像精细分割模型,人脸即五个关键点检测。
- 手部关键点检测以及识别:对每一帧都要运行该模型,用来判断手势的含义(8个类别之一)。
- 人像分割模型:也是每一帧都要运行,获得前景人物的掩码。用于做背景变化,背景虚化,背景黑白,防挡弹幕。
- 人脸及五个关键点检测:用于做人脸贴纸。
下面具体讲解,首先看整个项目的结构图,非常简单。
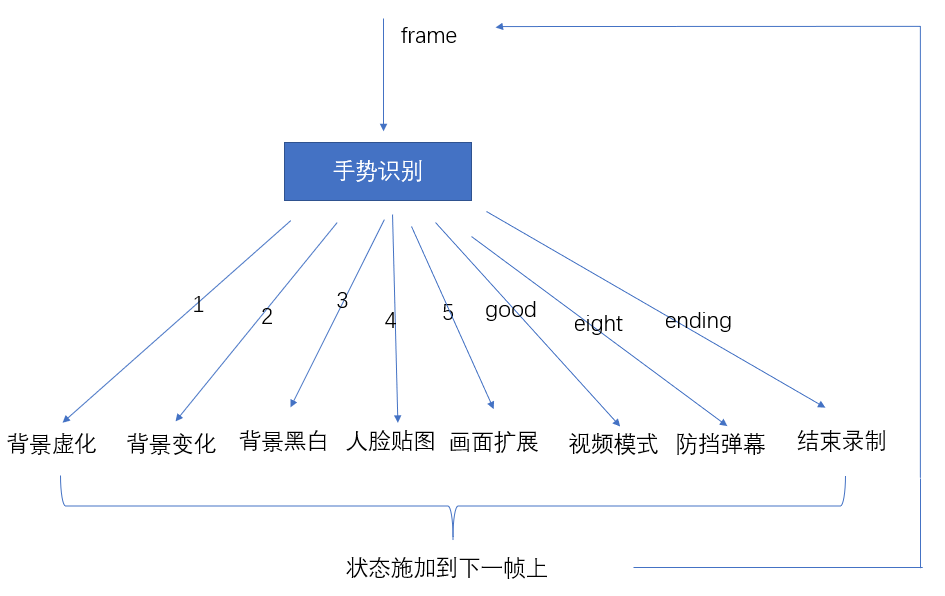
我使用了一个flags.py文件设置各种手势的当前状态。这些状态会保留并施加到下一帧上,所以每个手势都不是独立作用的。正如视频中描述,这些手势对应的效果能一起作用在同一帧上。
手势识别
在2019年8月,谷歌发布了一个能检测手部关键点的开源apk,当时很多公众号对其进行了报道。在他们开放的视频中,该开源模型可以检测手部21个关键点并且识别手势。但是遗憾的是,在开源的代码中,并没有识别手势的部分,仅仅有关键点检测。但是在谷歌发布的博客中,提到了他们识别手势的方法是,判断手部关节点的弯曲程度以及关系。在HandAI中,我使用了他们开源的网络检测手部关键点,根据他们的描述,复现了8种手势的识别。
- 如果判断手部弯曲程度: 计算指关节到指尖的向量,计算指关节到手掌底部的向量,再计算两个向量的余弦距离。根据余弦距离判断手指的弯曲程度。再把每个手指的状态(弯曲,伸直)映射到一组预定义的手势上即可。不需要在训练一个分类网络。
背景的虚化,变化,黑白效果
关于背景的虚化,变化,以及黑白效果。本质上就是得到了人像的mask,然后把mask迁移到另一张图像上罢了。不多介绍。
人脸贴纸的实现思路:
首先贴纸肯定要往脸上贴,所以需要一个人脸检测网络。还需要确保贴纸能贴到脸上的合理区域,比如猫耳朵不能把人眼睛覆盖了是吧。所以需要关键点检测。越是需要贴的准,贴的多样,就越需要检测多个关键点,一般98个关键点是很合适的,因为关键点还覆盖了头部,可以贴帽子。当然68个点也可以,只是需要根据面部比例算出头部的位置。
在我的项目中,我简化了操作。首先我在网上找到了这样的素材

这个猫脸贴纸图包含了足够多的部分,所以我没有必要定位每个需要贴纸的位置,贴上合适的贴纸。我只要找到人脸鼻子的位置,和猫鼻子对应。然后计算合适的比例,对猫脸素材缩放,然后把素材的mask找到,算出相对坐标,直接覆盖在人脸上就ok了。
详细说下计算比例的问题。我使用centerFace检测人脸。centerFace还能输出人脸的眼部中心,鼻子,两个嘴角这五个位置的关键点。通过计算人脸鼻子到嘴角(左或者右)的距离,和猫脸素材的鼻子中心到嘴角(估计一下大概位置)的距离,这两个距离的比值,就是猫脸素材应该缩放的尺度。
然后在猫脸素材上求得所有像素点相对于鼻子中心的相对坐标,加上人脸鼻子的坐标,就是猫脸素材应该在人脸图像坐标上的具体位置。
f
1
(
x
,
y
)
=
(
x
n
o
s
e
,
y
n
o
s
e
)
+
f
r
e
l
a
t
i
v
e
(
x
,
y
)
f_1(x,y) = (x_{nose}, y_{nose}) + f_{relative}(x,y)
f1(x,y)=(xnose,ynose)+frelative(x,y)
f
r
e
l
a
t
i
v
e
(
x
,
y
)
=
(
x
,
y
)
−
(
x
c
a
t
_
n
o
s
e
,
y
c
a
t
_
n
o
s
e
)
f_{relative} (x,y)= (x,y) - (x_{cat_nose}, y_{cat_nose})
frelative(x,y)=(x,y)−(xcat_nose,ycat_nose)
其中,
x
,
y
x,y
x,y是猫脸素材在猫脸图像坐标系下的坐标。通过函数
f
1
f_1
f1,将坐标变换到人脸坐标系下。
画面扩展
如果检测到了5这个手势,flags将会设置对应的状态。首先会记录手掌中心的位置 p o s pos pos。然后后续帧在移动5的过程中,计算当前帧手掌中心和 p o s pos pos在x轴的距离,按照合理的比例求出当前画面有多宽的位置应该被扩展。包括画面的扩展,以及收回扩展画面,都是这样做的。
防挡弹幕
防挡弹幕,其中防挡的效果自然是用人像精细分割得到的mask来实现的,不多说。至于这个弹幕效果如何生成。哈哈。将每一条弹幕视作一个对象,加入到队列中。首先没有一个弹幕被发出,所有的弹幕都在一个队列中。每一帧都有弹幕发出,发出的弹幕出列,并进入另一个队列中。所以有两个队列,其中一个队列用来保存没有发出的弹幕,另一个队列用来保存发出的队列。对每一帧,都遍历保存发出的队列,弹幕这个对象中保存了弹幕应该出现的位置,然后draw出来,再把位置更新一下,就是x轴减去一个合理的数值,数值是和fps有关的。
项目例子
推荐先运行webCamera_demo.py看看效果。需要pytorch-GPU, tensorflow2.0等库。在我的电脑,cpu是intel i5-8300, GPU GTX1060(6GB)上,处理速度是5fps。
同时我还提供了每个模型使用的例子,可以去example文件夹查看。
致谢
本项目受很多开源项目支撑。其中有谷歌的mediapipe,centerFace,PortraitNet。
mediapipe
centerFace
PortraitNet
谷歌手势识别
hand tracking
感谢这些开源项目,今后我也将会秉持开源精神,促进知识传播,共享技术,共同进步。
最后
以上就是激昂雪糕最近收集整理的关于HandAI开源项目,拉近人和摄影的距离:基于手势识别完成不同的拍摄行为项目功能项目设计思路项目例子致谢的全部内容,更多相关HandAI开源项目,拉近人和摄影内容请搜索靠谱客的其他文章。








发表评论 取消回复