在本文中,Zookeeper节点个数(奇数)为3个。Zookeeper默认对外提供服务的端口号2181。Zookeeper集群内部3个节点之间通信默认使用2888:3888。
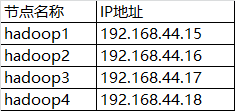
1. Hadoop集群环境
2. 下载Zookeeper安装包
下载地址:http://mirrors.shu.edu.cn/apache/zookeeper/
根据需要选择合适的版本,本文为zookeeper-3.4.14.tar.gz.
3. 上传、解压Zookeeper包
进入/opt目录,使用rz命令上传到hadoop1服务器并解压,命令如下:
#cd /opt #rz #tar -zxvf zookeeper-3.4.14.tar.gz
#生成软链接
#ln -s /opt/zookeeper-3.4.14 /opt/zookeeper
4. 配置环境变量(每个节点都需要配置)
# vim /etc/profile # zookeeper export ZK_HOME=/opt/zookeeper # zookeeper解压安装目录 export PATH=$PATH:$ZK_HOME/bin #配置后,使之生效 # source /etc/profile
依次在hadoop1、hadoop2、hadoop3、hadoop4节点上执行上述操作。
5. 配置Zookeeper参数文件(每个节点都需要配置)
(1)配置/opt/zookeeper/conf/zoo.cfg文件
首先,复制zoo_sample.cfg文件,命名为zoo.cfg。
[root@hadoop1 conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@hadoop1 conf]# cp zoo_sample.cfg zoo.cfg
[root@hadoop1 conf]# ls
configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg
其次,编辑zoo.cfg配置文件(每个节点配置相同)
#保持默认值
tickTime=2000 initLimit=10 syncLimit=5
#修改存储快照文件snapshot的目录 dataDir=/opt/zookeeper/data clientPort=2181
#这里server.x中的x是一个数字,与myid文件中的id一致 server.1=hadoop1:2888:3888 server.2=hadoop2:2888:3888 server.3=hadoop3:2888:3888
(2)配置/opt/zookeeper/data/myid文件(三个节点均需配置)
创建data文件夹,新建myid文件,路径为zoo.cfg文件中dataDir指定的路径,本文为/opt/zookeeper/data。
hadoop1节点:
# cd /opt/zookeeper # mkdir data # cd data # echo 1 > myid
6. 分发安装包
将配置好的/opt/zookeeper文件夹拷贝到hadoop2、hadoop3节点。
# scp -r /opt/zookeeper hadoop2:/opt/ # scp -r /opt/zookeeper hadoop3:/opt/ # scp -r /opt/zookeeper hadoop4:/opt/
# scp -r /opt/zookeeper-3.4.14 hadoop2:/opt/ # scp -r /opt/zookeeper-3.4.14 hadoop3:/opt/ # scp -r /opt/zookeeper-3.4.14 hadoop4:/opt/
注意:修改hadoop2、hadoop3服务器对应/opt/zookeeper/data/myid文件内容。
hadoop2节点:
# echo 2 > /opt/zookeeper/data/myid
hadoop3节点:
# echo 3 > /opt/zookeeper/data/myid
7. 启动Zookeeper集群(分别在每台服务器启动Zookeeper)
[root@hadoop1 ~]# /opt/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@hadoop2 ~]# /opt/zookeeper/bin/zkServer.sh start
[root@hadoop3 ~]# /opt/zookeeper/bin/zkServer.sh start
使用zkServer.sh status命令查看状态
[root@hadoop1 conf]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Mode: follower
==============================以下是Zookeeper集群启动自动化脚本========================
zk集群脚本编写
将脚本放到/usr/local/bin目录下,方便调用。
# vim /usr/local/bin/xzk-cluster.sh #修改脚本执行权限 # chmod 755 /usr/local/bin/xzk-cluster.sh
脚本内容如下:
#!/bin/bash cmd=$1 servers="hadoop1 hadoop2 hadoop3" for s in $servers ; do tput setaf 3 echo ========== $s ========== tput setaf 7 ssh $s "source /etc/profile ; zkServer.sh $cmd" done
使用范例:
[root@hadoop1 conf]# xzk-cluster.sh status ========== hadoop1 ========== ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Mode: follower ========== hadoop2 ========== ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Mode: leader ========== hadoop3 ========== ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Mode: follower
[root@hadoop1 conf]# xzk-cluster.sh stop ========== hadoop1========== ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Stopping zookeeper ... STOPPED ========== hadoop2 ========== ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Stopping zookeeper ... STOPPED ========== hadoop3 ========== ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Stopping zookeeper ... STOPPED
转载于:https://www.cnblogs.com/shireenlee4testing/p/10730536.html
最后
以上就是帅气柠檬最近收集整理的关于Zookeeper集群安装与配置的全部内容,更多相关Zookeeper集群安装与配置内容请搜索靠谱客的其他文章。








发表评论 取消回复