B站视频讲解
EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计。EM算法的每次迭代由两步组成:E步,求期望(expectation);M步,求极大(maximization)。所以这一算法称为期望极大算法(expectation maximization),简称EM算法。概率模型有时既含有观测变量(observable variable),又含有隐变量或者潜在变量(latent variable)。EM算法就是含有隐变量的概率模型参数的极大似然估计法,或极大后验概率估计法。
算法引入
最大似然估计
一个例子:假如你去赌场,但是不知道能不能赚钱,你就在赌场门口等,出来一个人,就问这个人是赚了还是赔了,如果问了10个人都说赚了,那么你就会认为,赚钱的概率肯定是非常大的。那么我们就可以理解这样的问题:
-
已知:1.样本服从分布的模型,2.观测到的样本
-
求解:模型的参数
总的来说:极大似然估计就是用样本来估计模型参数的统计学方法。
上面介绍一个粗浅的例子,现在我们引入一个最大似然函数的数学问题:100名学生的身高问题
这个时候,我们可以认为这100个人的身高是满足高斯分布的(正太分布),那么就涉及到两个参数:均值( μ mu μ)和标准差( δ delta δ),或者方差( δ 2 delta ^2 δ2),为了便于表示,这里我们统一使用 θ theta θ表示,根据极大(最大)似然估计,我们就要找到两个参数的值,使得恰好抽到这100个学生的概率最大。那么数学化则有:
-
样本集 X = { x 1 , x 2 , ⋯   , x N } , N = 100 X={x_1,x_2,cdots,x_N},N=100 X={x1,x2,⋯,xN},N=100
-
概率密度: p ( x i ∣ θ ) p(x_i|theta) p(xi∣θ)抽到某个人i(的身高)的概率
-
θ theta θ是服从分布的参数
-
独立同分布:同时抽到这100个人的概率就是抽到他们各自概率的乘积。(也就是说,你抽到 x 1 x_1 x1,不会影响抽到 x 2 x_2 x2)
那么,我们就有了目标似然函数:
L
(
θ
)
=
∏
i
=
1
m
p
(
x
i
;
θ
)
L(theta)=prod_{i=1}^mp(x_i;theta)
L(θ)=i=1∏mp(xi;θ)
为了便于计算,我们将等式两边同时取对数有(学过数理统计的友友都应该知道的吧):
l
(
θ
)
=
∑
i
=
1
m
log
p
(
x
i
;
θ
)
l(theta)=sum_{i=1}^mlog p(x_i;theta)
l(θ)=i=1∑mlogp(xi;θ)
下一步,就是什么样的参数
θ
theta
θ能够使得出现当前这批样本(抽到这个100个人)的概率最大,那么就要对
θ
theta
θ进行估计了。如何做呢?这就是极大似然估计求解的最基本做法了(取对数,求偏导,令等式为0,求解),已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次实验,观察其结果,利用结果推出参数的大概值。
EM算法引入
问题升级:当然问题不是那么简单,
-
现在这100个人中,包含的有男生和女生(也就是两个类别,2套参数/2个高斯分布)
-
男生和女生的身高都服从高斯分布,但是参数不同(均值和方差)
-
用数学的语言描述:抽取得到的每个样本都不知道是从哪个(男生/女生)分布抽取的
-
求解目标:男生和女生对应的身高的高斯分布的参数是多少?
那么也就是说,我们加入一个隐变量(是男生,还是女生)。这个时候,传统的极大似然估计就不好解决了,于是就使用EM算法来计算,换句话说,EM算法就是能够计算含有隐变量的极大似然估计算法。让我们继续来看:
我们用Z表示这个隐变量,Z=1或Z=2标记样本来自哪个分布。那么使用之前的最大似然估计函数则有:
l
(
θ
)
=
∑
i
=
1
m
log
p
(
x
i
;
θ
)
=
∑
i
=
1
m
log
∑
Z
p
(
x
i
,
z
;
θ
)
l(theta)=sum_{i=1}^mlog p(x_i;theta)=sum_{i=1}^mlog sum_Z p(x_i,z;theta)
l(θ)=i=1∑mlogp(xi;θ)=i=1∑mlogZ∑p(xi,z;θ)
上式中,第二个求和符号就是要考虑的隐变量的情况。这个时候使用极大似然估计(求偏导)就不方便计算了。现在先不从数学公式的角度来说EM算法,我们看一个计算案例:
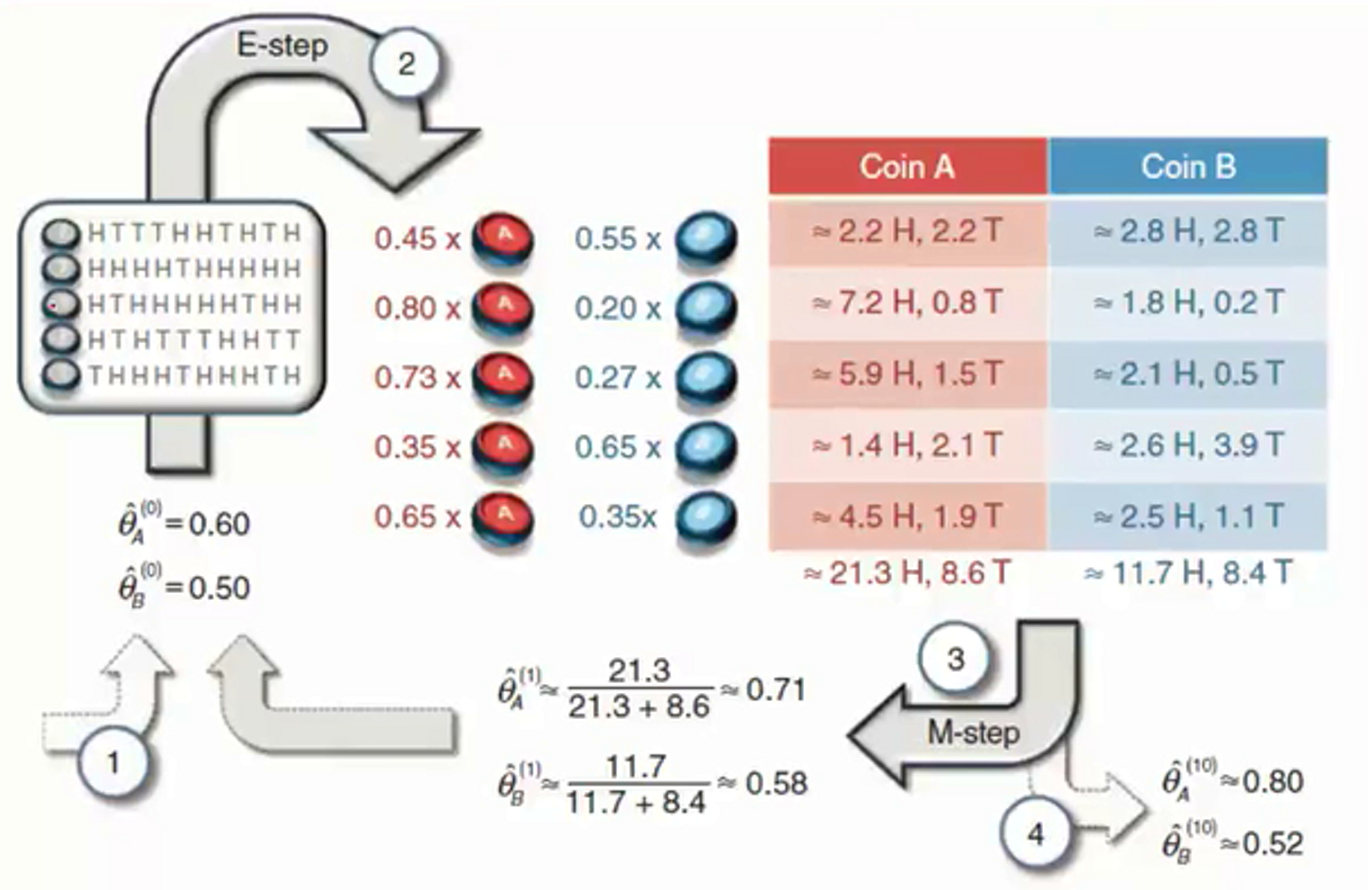
假设有赌场中的两个硬币A,B。我们现在想计算出这两个硬币正面朝上的概率分别是多少?现在有n组(上图中有五组)数据(HT的序列,表示硬币的正反面,并且我们不知道是哪个硬币掷出来的)
我们现在先假设两个硬币的分布(二项分布),初始化时数据最好是比较接近实际情况的,否则可能迭代次数比较多(也和你选择的停迭代止阈值有关),有:A:0.6几率正面,记为 θ A theta_A θA,B:0.5几率正面,记为 θ B theta_B θB
现在我们来看第一组数据(HTTTHHTHTH),其中:H有5个,T有5个。那么隐变量Z=A和Z=B.那么就有:
p A = C 10 5 0. 6 5 0. 4 10 − 5 p_A=C_{10}^50.6^50.4^{10-5} pA=C1050.650.410−5, p B = C 10 5 0. 5 5 0. 5 10 − 5 p_B=C_{10}^50.5^50.5^{10-5} pB=C1050.550.510−5
接着我们选择硬币A,B的概率分别是: p a = p A p A + p B = 0.45 p_a=frac{p_A}{p_A+p_B}=0.45 pa=pA+pBpA=0.45, p b = 1 − p a = 0.55 p_b=1-p_a=0.55 pb=1−pa=0.55
现在我们进行E步(求期望):
对硬币A有: 0.45 × 5 T = 2.2 T , 0.45 × 5 H = 2.2 H 0.45times 5T=2.2T,0.45times 5H=2.2H 0.45×5T=2.2T,0.45×5H=2.2H
对硬币B有: 0.55 × 5 T = 0.275 T , 0.55 × 5 H = 2.275 H 0.55times5T=0.275T,0.55times5H=2.275H 0.55×5T=0.275T,0.55×5H=2.275H。
现在我们对这五组数据分别进行这样的计算,有如上图所示的结果。现在我们使用M步对初始的分布参数进行更新,其中的更新方式一看公式就明白了,就是将硬币A中计算出的所有H,T分别加在一起,然后计算各自得占比,如下:
θ ^ A ( 1 ) = 21.3 21.3 + 8.6 ≈ 0.71 , θ ^ B ( 1 ) = 11.7 11.7 + 8.4 ≈ 0.58 hat{theta}_A^{(1)}=frac{21.3}{21.3+8.6}approx0.71,hat{theta}_B^{(1)}=frac{11.7}{11.7+8.4}approx0.58 θ^A(1)=21.3+8.621.3≈0.71,θ^B(1)=11.7+8.411.7≈0.58
这就是对这五组数据进行了一次迭代计算,之后就是多次迭代计算,最后输出结果。这样一看EM算法其实就很简单了,但是我们凭什么这么做呢?下面我们就带着问题看看EM算法的推导。
EM算法推导
问题:样本
{
x
(
1
)
,
⋯
 
,
x
(
m
)
}
{x(1),cdots,x(m)}
{x(1),⋯,x(m)},包含m个独立的样本,其中每个样本i对应的类别z(i)是未知的,所以很难用最大似然估计。
l
(
θ
)
=
∑
i
=
1
m
log
p
(
x
i
;
θ
)
=
∑
i
=
1
m
log
∑
Z
p
(
x
i
,
z
;
θ
)
l(theta)=sum_{i=1}^mlog p(x_i;theta)=sum_{i=1}^mlog sum_Z p(x_i,z;theta)
l(θ)=i=1∑mlogp(xi;θ)=i=1∑mlogZ∑p(xi,z;θ)
刚才已经说过,使用最大似然估计比较难求解,本来正常求偏导就可以了,但是现在log后面还有求和,那么就麻烦了。于是我们就是使用EM算法进行求解,下面就是对其进行推导。
EM算法推导
我们现在上式中一部分
l
o
g
∑
Z
p
(
x
i
,
z
;
θ
)
log sum_Z p(x_i,z;theta)
log∑Zp(xi,z;θ),对其分子分母同时乘
Q
(
z
)
Q(z)
Q(z)有:
log
∑
Z
p
(
x
i
,
z
;
θ
)
=
l
o
g
∑
Z
Q
(
z
)
p
(
x
i
,
z
;
θ
)
Q
(
z
)
logsum_Zp(x_i,z;theta)=logsum_ZQ(z)frac{p(x_i,z;theta)}{Q(z)}
logZ∑p(xi,z;θ)=logZ∑Q(z)Q(z)p(xi,z;θ)
为什么这么做呢?其实就是为了配凑Jensen不等式(Q(z)是z的分布函数)。这个估计大家都不是很了解,让我们来看看,jensen不等式吧:(需要申明的是,国内与国外定义凹凸函数是不同的,这个大家可以百度一下,不要纠结下面的问题。)
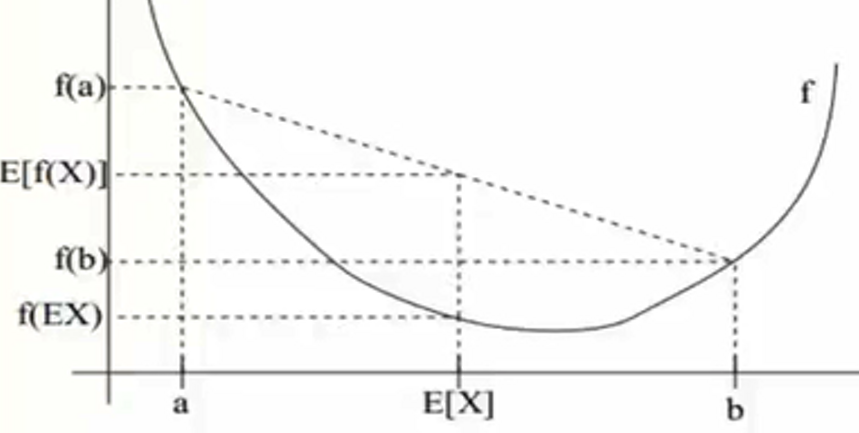
设f是定义为实数的函数,如果对于定义域内的所有实数x,有f(x)的二次导数大于等于0,那么f就是凸函数(你会说,这明明就是凹函数嘛,不要纠结);如果f是凸函数,X是随机变量,那么: E ( f ( X ) ) > = f ( E ( X ) ) E(f(X))>=f(E(X)) E(f(X))>=f(E(X)),我们来解释一下这个属性,上图的实线f是凸函数,X有0.5的概率选择a,也有0.5的概率选择b(这里是假设选值),那么随机变量X的期望值(均值)就为a和b的中值(0.5a+0.5b)即,E[X]=0.5(a+b)。而E[f(X)]=0.5E[f(a)]+0.5E[f(b)](a和b各有50%的概率取到)。那么从图中可以看出,E[f(X)]>=f(E(X))。,那么对于凹函数,那么就会有: E [ f ( X ) ] < = f ( E [ X ] ) E[f(X)]<=f(E[X]) E[f(X)]<=f(E[X])。现在Jensen的介绍就告一段落。我们再回到EM算法中涉及的算式:
∑
Z
Q
(
z
)
p
(
x
i
,
z
;
θ
)
Q
(
z
)
sum_ZQ(z)frac{p(x_i,z;theta)}{Q(z)}
∑ZQ(z)Q(z)p(xi,z;θ)可以看成
p
(
x
i
,
z
;
θ
)
Q
(
z
)
frac{p(x_i,z;theta)}{Q(z)}
Q(z)p(xi,z;θ)的期望,这又该如何理解呢?我们知道在连续变量的概率密度中计算期望的公式
∫
x
f
(
x
)
int xf(x)
∫xf(x),看到这个就不难理解上面的那句话了。下面我们可以设
Y
=
p
(
x
i
,
z
;
θ
)
Q
(
z
)
Y=frac{p(x_i,z;theta)}{Q(z)}
Y=Q(z)p(xi,z;θ),进而化简有:
log
∑
Z
Q
(
z
)
p
(
x
i
,
z
;
θ
)
Q
(
z
)
=
log
∑
Y
P
(
Y
)
Y
=
log
E
(
Y
)
logsum_ZQ(z)frac{p(x_i,z;theta)}{Q(z)} =logsum_YP(Y)Y=log E(Y)
logZ∑Q(z)Q(z)p(xi,z;θ)=logY∑P(Y)Y=logE(Y)
这个时候我们就可以利用Jensen不等式了,log函数是凹函数,则有:
log
E
(
Y
)
≥
E
(
log
Y
)
=
∑
Y
P
(
Y
)
log
Y
=
∑
Z
Q
(
z
)
log
(
p
(
x
i
,
z
;
θ
)
Q
(
z
)
)
log E(Y)geq E(log Y)=sum_YP(Y)log Y=sum_ZQ(z)log(frac{p(x_i,z;theta)}{Q(z)})
logE(Y)≥E(logY)=Y∑P(Y)logY=Z∑Q(z)log(Q(z)p(xi,z;θ))
那么对于原极大似然估计则有:
l
(
θ
)
=
∑
i
=
1
m
log
∑
Z
p
(
x
i
,
z
;
θ
)
≥
∑
i
=
1
m
∑
Z
Q
(
z
)
log
p
(
x
i
,
z
;
θ
)
Q
(
z
)
l(theta)=sum_{i=1}^mlog sum_Z p(x_i,z;theta)geqsum_{i=1}^msum_ZQ(z)logfrac{p(x_i,z;theta)}{Q(z)}
l(θ)=i=1∑mlogZ∑p(xi,z;θ)≥i=1∑mZ∑Q(z)logQ(z)p(xi,z;θ)
这个时候,我们需要计算的就是下界值,我们通过优化这个下界来使得似然函数最大。那么在训练的过程中,我们使得下界一直取最大,那么最后得到的结果就是我们 需要的。那么问题又来了,如何使得不等式取等号呢,在Jensen不等式中等号的成立条件是随机变量是常数的时候(结合上面中的Jensen不等式的图形,思考一下就应该明白了),那么也就是
Y
=
p
(
x
i
,
z
;
θ
)
Q
(
z
)
=
C
Y=frac{p(x_i,z;theta)}{Q(z)}=C
Y=Q(z)p(xi,z;θ)=C,
Q
(
z
)
Q(z)
Q(z)是z的分布函数,那么我们根据Y对所有的z进行求和有必然为1(概率和为1):
∑
Z
Q
(
z
)
=
∑
Z
p
(
x
i
,
z
;
θ
)
C
=
1
sum_ZQ(z)=sum_Zfrac{p(x_i,z;theta)}{C}=1
Z∑Q(z)=Z∑Cp(xi,z;θ)=1
那么为了使得结果为1,所有的分子的和就等于常数C(与分母相同),那么也就是说,C就是所有的
p
(
x
i
,
z
)
p(x_i,z)
p(xi,z)对z求和。我们可以单独拿出Q(z)来看有:
Q
(
z
)
=
p
(
x
i
,
z
;
θ
)
C
=
p
(
x
i
,
z
;
θ
)
∑
Z
p
(
x
i
,
z
;
θ
)
=
p
(
x
i
,
z
;
θ
)
p
(
x
i
)
=
p
(
z
∣
x
i
;
θ
)
Q(z)=frac{p(x_i,z;theta)}{C}=frac{p(x_i,z;theta)}{sum_Zp(x_i,z;theta)}=frac{p(x_i,z;theta)}{p(x_i)}=p(z|x_i;theta)
Q(z)=Cp(xi,z;θ)=∑Zp(xi,z;θ)p(xi,z;θ)=p(xi)p(xi,z;θ)=p(z∣xi;θ)
那么也就是说,Q(z)代表第i个数据是来自
z
i
z_i
zi的概率,这其实就是Estep要做的事情。那么我们来总结一下EM算法:
- 初始化分布参数 θ theta θ
- E-step:根据参数 θ theta θ计算每个样本属于 z i z_i zi的概率(也就是我们的Q)
- M-step:根据Q,求出含有 θ theta θ的似然函数的下界,并最大优化它,得到新的参数 θ theta θ
- 不断的迭代更新下去
EM算法的应用
如高斯混合模型,HMM等。简要介绍一下高斯混合模型(GMM),数据可以看作是从数个Gaussian Distribution中生成出来的,GMM由K个Gaussian分布组成,每个Gaussian成为一个”Component“;类似于k-means方法,求解方式根EM一样,不断迭代更新下去。
个人订阅号
更多编程,人工智能知识等着你

最后
以上就是冷酷银耳汤最近收集整理的关于【机器学习】EM算法详解的全部内容,更多相关【机器学习】EM算法详解内容请搜索靠谱客的其他文章。








发表评论 取消回复