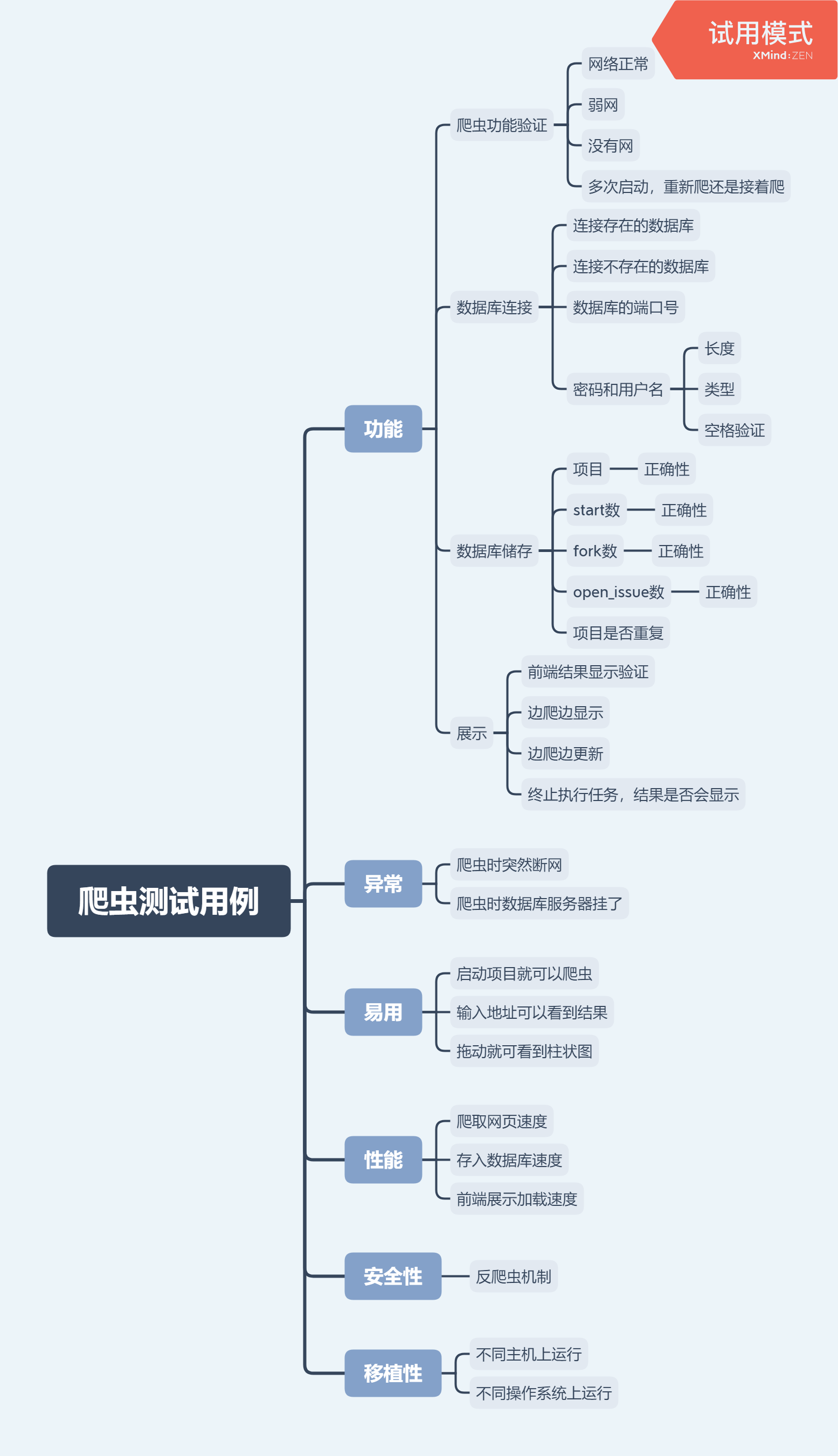
项目背景
爬取github上awssome-java这个项目中所提到的一些上榜项目,分析这项目的活跃程度(start,fork,open_issue)。实现一个类似于”github趋势”的功能。
核心流程
通过程序抓取awesome-java中所有上榜项目内容,解析之后存储到数据库,然后进行数据分析,以柱状图的形式展示在页面中,依此来分析项目活跃程度。
模块划分
1.抓取模块:获取服务器上的网页内容
| 预期 | 实际 | 分析 |
|---|---|---|
| 抓取github上awssome-java这个项目中的上榜项目 | 网页中的URL都被提取出来 | 模块功能正常 |
2.分析模块:分析网页内容,解析出需要的数据
| 预期 | 实际 | 分析 |
|---|---|---|
| 获取到每个项目的start数,fork数,opened_issue数 | 成功获取 | 模块功能正常 |
3.存储模块:存储数据到数据库中
| 预期 | 实际 | 分析 |
|---|---|---|
| 抓取数据,保存到数据库中 | 测试出现异常 | 当前url对应的不是一个github的项目,为了不影响后面的抓取,用try catch把抓取的循环包裹起来。 |
性能优化:
通过打印每个环节的时间,先找到性能瓶颈。
| 获取页面入口 | 获取项目列表 | 解析所有项目时间 | 存取数据库时间 | 整个项目总时间 |
|---|---|---|---|---|
| 3s | 0.4s | 130s | 4s | 138s |
得出性能最差的是循环调用Github API。所以引入多线程的方式来实现批量发送数据
| 1个线程 | 5个线程 | 10个线程 | 15个线程 | 20个线程 | 100个线程 |
|---|---|---|---|---|---|
| 138秒 | 38秒 | 22秒 | 18秒 | 13秒 | 9秒 |
经过测试我们选择20个线程。
4.展示模块:通过一个网页来展示这些抓取到数据的图表信息。
| 预期 | 实际 | 分析 |
|---|---|---|
| 获取到数据,展示图表 | 成功获取 | 模块功能正常 |
总结
经过测试,可以正常获取github上awssome-java这个项目中的上榜项目,并且将项目根据活跃程度(start,fork,open_issue)展示出柱状图。
最后
以上就是踏实黑猫最近收集整理的关于github_crawler测试的全部内容,更多相关github_crawler测试内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复