1 机器学习四大问题
1.1 机器学习四大问题
上一篇主要介绍机器学习准备工具numpy、pandas、matplotlib的使用。从本篇开始,我将正式进入机器学习算法内容的介绍,像很多的参考资料介绍的那样,我也从线性回归算法说起。不同的是,我根据自己的学习以及参考他人的资料在这里进行详细的理论解释与数学公式推导并分析解释,从我个人的学习经历来看,机器学习的难点有几个方面:
(1)复杂算法的概念抽象不易理解。
(2)数据维度稍微高一点就会导致数学公式极其庞大,这个一方面让人产生畏难的心理,另一方面会使人失去学习的兴趣
(3)计算机编程实战能力不足。编程实现算法是最终的目的,之前在理论方面所有的战斗都是为了更好的熟悉编程的流程。但是有时候花费了几天时间才从头到尾弄明白一个算法,尽管你可能非常熟悉某一门编程语言,最后到真正去编程算法实现时又面对着巨大的困难。
(4)英语论文阅读的能力。这一点并不是所有人都有必要具有的能力,为什么在这里要说呢,因为从传统的机器学习算法到当今的深度学习,很多的问题只有深度学习才能搞定,如果想要高人一等,英文论文的阅读是必不可少的,为什么是英文而不是中文呢,中文的没有,全世界顶级的算法都是发表在国外顶级的会议和顶级期刊上的,以中文的形式提出的顶级算法有吗,当然没有,你也从来没听过,中国人以及华裔提出的英文形式的算法遍地都是。那么,中文的哪些论文是可以拿来用的呢,一个是中文顶级期刊的论文,这里强调的是中文顶级期刊,不是别的期刊和会议。为什么要推荐中文顶级期刊的论文呢,原因主要有三个:一是中文顶级期刊一般都是EI检索,文章的真实性较高、数据比较可靠、文章内容结构完整调理清晰,文章的篇幅也较长,读起来比较舒服,国内的很多期刊会议你也许知道很水很烂,打开中国知网,随便一搜基本都是垃圾,我记得自己当时在学习唐宇迪大神的视频时他就直言不讳了不要打开知网,所以查中文论文资料一定要选择中文顶级期刊上的,比如计算机学报、软件学报、计算机研究与发展、模式识别与人工智能等等,二是中文顶级期刊一般大多数是专题类综述类,看这类文章能让你快速知道某个领域的研究动态,它为你指明了下一步该干什么,但是由于中文顶级期刊的审稿周期略长,所以你现在看到的论文可能是2年前的研究动态,后面就需要你自己再查英文的了。三是中文顶级期刊大都是国内在这个领域进行长期研究的专家的作品,举一反三,你可以站在巨人的肩膀上。中文论文第二个能拿来用的就是国内牛人或者著名研究机构的官方主页上提供的论文。比如南京大学周志华https://cs.nju.edu.cn/zhouzh/、清华大学刘洋 http://nlp.csai.tsinghua.edu.cn/~ly/、微软亚洲研究院周明https://www.microsoft.com/en-us/research/people/mingzhou/、清华大学自然语言处理与社会人文计算实验室http://nlp.csai.tsinghua.edu.cn/site2/index.php/zh/people、南京大学自然语言处理研究组http://nlp.nju.edu.cn/homepage/等等,稍微搜索下各类牛人和知名高校的实验室都会提供很多的资料信息。所以针对第四个难点,如果你想在机器学习包括深度学习领域长期深入发展你需要重点注意。顺便说下,英文论文主要在顶级会议,其次是顶级期刊,顶级会议是核心,顶级会议各个都太出名了以至于你搜一下关键词加官网就出来了,比如机器学习顶级会议机器学习领域:ICML、NIPS、COLT、ECML、UAI、AISTATS,计算机视觉与机器学习混合:CVPR,ICCV,ECCV,机器学习与数据挖掘大杂烩:AAAI,IJCAI,主要是数据挖掘领域:KDD,SDM,ICDM,这里就不再一一列举,当然了国外的牛人与团队也有很多,这里列举下我认为最出名的几位 ,首先是2019年3月27日宣布的,ACM 2018 年图灵奖得主 Yoshua Bengio, Geoffrey Hinton 和 Yann LeCun https://mila.quebec/en/yoshua-bengio/、http://www.cs.toronto.edu/~hinton/、 http://yann.lecun.com/,其他知名人物,Facebook的Tomas Mikolov,其在机器学习和NLP,尤其是NLP领域贡献突出,https://research.fb.com/people/mikolov-tomas/、斯坦佛大学吴恩达,他的机器学习和深度学习视频课程在国内是机器学习入门者的必学资料,绝对的良心教程资料,你值得拥有,https://www.andrewng.org/,斯坦佛大学李菲菲,李菲菲团队创造的ImageNet数据集是ILSVRC的数据集,她还提供深度学习与计算机视觉视频教程https://profiles.stanford.edu/fei-fei-li/ ,澳大利亚阿莱德莱大学沈春华 https://cs.adelaide.edu.au/~chhshen/index.html等等等等。截然不同的是,如果你只是想将算法理论在实际中的某个领域进行应用,那么在需要的时候学习找对应的中文资料基本就可以搞定。
1.2 个人的尝试解决方法
第四个难点其实我已经说的很清楚了,你需要与否以及对应的方法都已提供。下面针对前三个难点,简单说一下个人的解决策略。第一个难点是复杂算法概念抽象,个人的解决方法书读百遍其义自见,精读加思考,然后根据多部精典的参考书和高质量的视频教程(这个要自己筛选,书我用了李航 《李航统计学习方法》 周志华《机器学习》 雷明《机器学习与应用》等 ,视频主要是b站上的。)第二个难点是数学公式庞大,这个需要有一定的数学基础,首先微积分、矩阵分析、概率统计的基础知识要明白,然后是对公式的逐步推导加理解,公式庞大且复杂的原因是数据是多个的且是多维的,所以在进行分析时可以单个数据分析然后慢慢推广到多个,这样才不至于一下拿那么多数据而出现的困扰。第三个问题是计算机编程,这个是核心问题,是你的实践能力问题。编程语言的选择上,多数人应该都是选择的python,我用的也是python。仅仅使用python进行学术研究是完全足够的,但是工作上显得不那么够,根据业务需求你可能还要基本了解和能简单使用一些其他语言,比如java、c++,毕竟编程语言三巨头。回到计算机编程的问题,怎么解决呢,最快的方法是跟随教学视频边看边练习,唯有多练习才能熟练,上机实战时间决定熟练度,没办法,任何一个编程大神都是要大量时间大量练习的。
2 线性回归
2.1 样本数据
下面就开始介绍第一个算法,线性回归。机器学习的问题根据给定的数据有无标签可以分为监督学习和无监督学习,监督学习根据根据标签是离散值和连续值分为分为分类问题和回归问题,分类算法主要有K近邻(KNN)、线性回归(Linear Regression)、决策树(Decision Tree)、朴素贝叶斯(Naive Bayes)、支持向量机(SVM)、集成学习方法(Ensemble Learning)、神经网络(Artificial Neural Network)等等。无监督学习又分为聚类和密度估计,主要算法有k均值(K-Means)、均值漂移(Means-Shift)、基于密度的聚类方法(DBSCAN)、凝聚层次聚类(Hierarchical Clustering)、谱聚类(Spectral Clustering)等等。下面开始线性回归算法介绍。
假设数据集为D:
(1)
其中,
(2)
(3)
数据说明:数据集D包含有N个数据,每个数据都由两部分组成可以称为特征与值(或者自变量与因变量),见公式(1)。每个特征都是一个d维的列向量,见公式(1);每个值都是1个数,见公式(3)。
线性回归就是用数据来拟合一条直线(多维就是面)使得直线上的点与目标值差的平方和最小,即最小二乘法。设权重参数向量为:
(4)
偏置为b,这里为了下面方便将其用来表示,则对每一个样本数据
都能够通过同样的权重参数与偏置的组合得到一个预测值,
(5)
为了写成矩阵形式,给样本数据X在第一列插入全为1的列,公式(2)改写成公式(6),公式(3)不变,公式(5就可以写成公式(7)的矩阵形式。
(6)
(7)
2.2 损失函数
2.2.1 损失函数直接求解
定义损失函数为估计值与实际值差的平方再对所有样本求和,即公式(8)。
(8)
将公式(8)展开,得到公式(9)。这里的与一开始的
相比在第一列加了1,但是数据样本的个数没有增加,仍然为N。
(9)
损失函数最小化,公式(10)。
(10)
求偏导数并置0,,解得公式(11)。
(11)
2.2.2 概率求解与高斯分布
误差值为真实值与预测值之差,公式(12)。
(12)
线性回归假设误差服从均值为0,方差为的高斯分布。所以根据高斯分布公式,得到公式(13)。
(13)
将公式(12)带入公式(13),得到含参数w的方程(14)。
(14)
对所有样本,得到似然函数,公式(15)。
(15)
两边取对数,得到对数似然,公式(16)。
(16)
公式(16)第一项为常数项,求解对数极大似然估计,公式(17)。
(17)
公式(17)等价于求公式(18)的极小值,公式(18)。
(18)
公式(18)就是公式(8)!!!,直接求解即可。
2.3 正则化
2.1 节和2.2节是异曲同工的,求解的参数形式见公式(11)。但是为防止过拟合,通常在损失函数(8)或者公式(18)中加入正则化项,正则化项通常有L1和L2正则,公式(19)和公式(20),分别称作Lasso回归和Ridage回归。
(19)
(20)
利用公式(9)、(19)、(20),得到公式(21)和公式(22)。
(21)
(22)
由于Lasso回归引入绝对值,导致函数不可导,故不能用求导的方法解决,即没有解析解。求解方法有坐标轴下降法(coordinate descent)和最小角回归法( Least Angle Regression, LARS)、近端梯度下降法(Proximal Gradient Descent,PGD)。
对于Ridage回归,直接求偏导数并置0,,解得公式(23))。
(23)
通常的线性回归问题,采用线性回归方法基本就能解决,Lasso回归和Ridage回归的正则化方法也可以进行实验,综合选择效果最好的方法。
2.4 sklearn 与线性回归实践
2.4.1 sklearn机器学习库
sklearn是一个重要的机器学习库,官网是https://scikit-learn.org/stable/,官方github:https://github.com/scikit-learn/scikit-learn,主要包括6大部分:分类、回归、聚类、降维、模型选择、数据预处理。每个部分都包含了多种具体的算法及其介绍并给出实例,对于机器学习算法的学习是一个很好的参考,同时也是以后对实际问题处理的一个很好的工具。在windows或者Linux系统上直接使用pip install sklearn进行安装即可。下图给出了一个从官网下载的sklearn 算法的介绍图。具体详见官网,这里只是一个推荐,不做也不能多做介绍。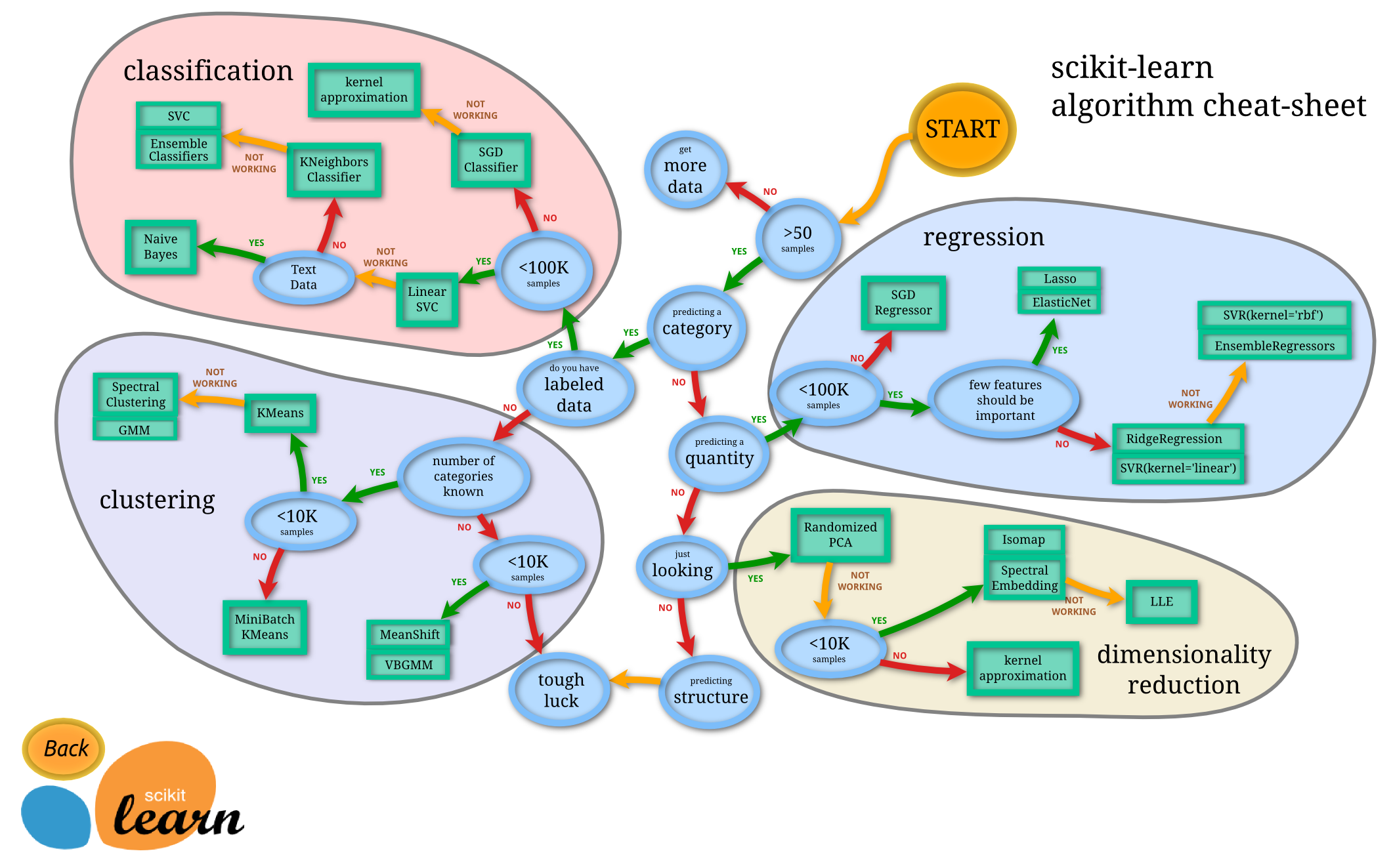
2.4.2 线性回归的python实现
首先说两点,第一是数据,无论采用的是什么算法(当然,除了极具创新的算法除外),数据才是核心,对数据的处理或者称为特征提取是关键,所有特征工程是必须要进行认真研究的;第二是算法实现的框架(或者称为平台),现在很多的深度学习框架如Tensorflow、Pytorch、Caffe、Mxnet、Keras等等,Tensorflow可以是使用最多的框架,在传统机器学习与深度学习领域都能很好使用,Pytorch与TensorFlow齐头并进,在自然语言处理领应用广泛,如果你研究自然语言建议使用,Caffe在目标检测领域是绝对的优先使用者,基于C++的内核使得其运行速度很快,Mxnet是华人李沐、Aston Zhang开发的,Keras是高层神经网络API,后端采用Tensorflow或者theano,高度封装的优缺点都很明显,有点是使用简单,缺点是开发难。不管什么框架,你应该根据自己的研究领域选择,详细内容这里都不做介绍与使用。我个人主要使用Tensorflow,对pytorch和caffe正在学习和使用。
下面我按照上面的原理,进行一个实例的线性回归演示。为了方便,我的数据也是使用sklearn的Boston房价的数据还有一个特征为1维的数据(如有侵权请周知),不同的是我在这里不用梯度下降优化的方法,而是直接使用矩阵求解法,但是同时也给出使用sklearn的实现。先使用Boston房价的数据,在使用一个网上找的一个特征为1维的数据。
下面使用Boston房价的数据。
2.4.2.1 直接求解
step1:导入模块和库,数据集、numpy、matplotlib、显示中文。
from sklearn.datasets import load_boston
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']step2:载入原始数据,字典类型,特征名称、特征数据、目标数据。
sample_data = load_boston()
feature_name = sample_data.feature_names
feature_data = sample_data.data
label_data = sample_data.target
print(feature_name)
print(feature_data)
print(label_data)
step3:根据原理,将特征数据矩阵最前加一列1。
modify_data = np.insert(feature_data, 0, 1, axis=1)step4:基本线性回归,按公式(11)直接计算w、预测值、误差、画图。
w = np.matmul(np.matmul(np.linalg.inv(np.matmul(np.transpose(modify_data), modify_data)), np.transpose(modify_data)), label_data)
y_ = np.matmul(modify_data, w)
e = y_ - label_data
plt.figure(1)
plt.plot(e)
plt.xlabel("/数据")
plt.ylabel("/误差")
plt.savefig("res1.png")
plt.show()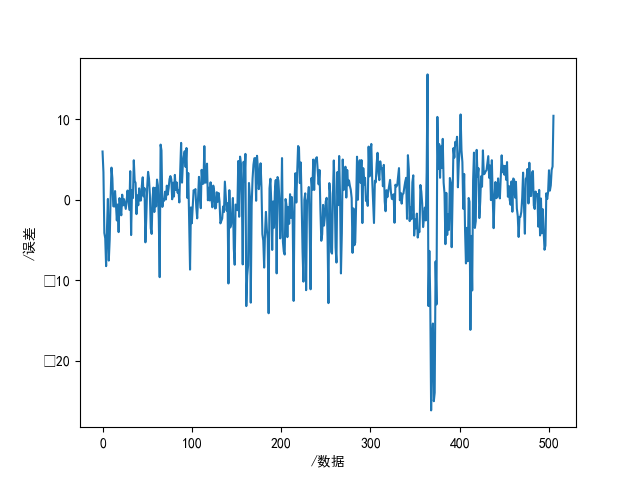
step5:L2正则化,按公式(23),设置3个不同的惩罚系数,直接计算w、预测值、误差、画图。
说明:L1正则化损失函数由于不可导,不可直接计算,通常采用优化的方法来解决。
p_ = [10, 1, 0.01]
plt.figure(2)
for p in p_:
x_T = np.transpose(modify_data)
t1 = np.matmul(x_T, modify_data)
t2 = p * np.eye(14)
x_I = np.linalg.inv(np.add(t1, t2))
t3 = np.matmul(x_I, x_T)
w_l2 = np.matmul(t3, label_data)
print(w_l2)
y_l2 = np.matmul(modify_data, w_l2)
e_l2 = y_l2 - label_data
plt.plot(e_l2)
plt.xlabel("/数据")
plt.ylabel("/误差")
plt.savefig("res2.png")
plt.show()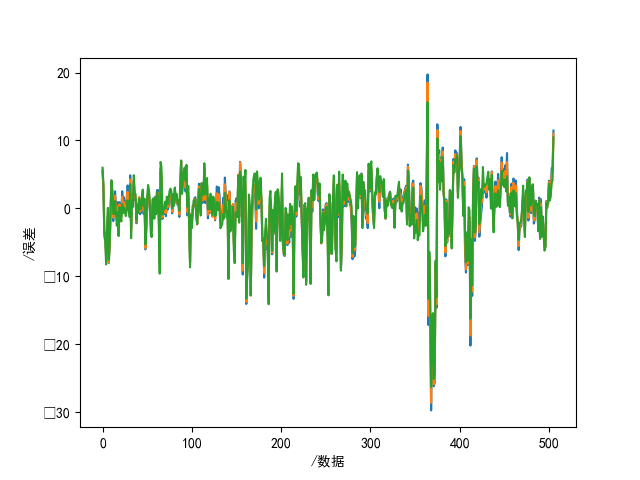
2.4.2.2 sklearn的方法
step1:导入模块和库,线性回归、数据集、训练测试集划分、得分。
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
step2:特征数据、目标数据。
sample = load_boston()
print(sample)
sample_data = sample.data
sample_target = sample.targetstep3:训练集、测试集划分。
x_train, x_test, y_train, y_test = train_test_split(sample_data, sample_target, test_size=0.15, random_state=10)
step4:线性回归模型、训练、权重参数与偏置项。
model = LinearRegression()
model.fit(x_train, y_train)
# 系数与截距
print("权重参数: ", model.coef_)
print("偏置项: ", model.intercept_)
step5:预测值、残差、绘图。
y_ = model.predict(x_test)
print("预测值: ", y_)
e = y_ - y_test
print("残差: ", e)
plt.figure(1)
plt.plot(e)
plt.savefig("sklearn.png")
plt.show()
下面一维数据。工作时间(经验,年)-薪水(元)。
1.1 39343.00
1.3 46205.00
1.5 37731.00
2.0 43525.00
2.2 39891.00
2.9 56642.00
3.0 60150.00
3.2 54445.00
3.2 64445.00
3.7 57189.00
3.9 63218.00
4.0 55794.00
4.0 56957.00
4.1 57081.00
4.5 61111.00
4.9 67938.00
5.1 66029.00
5.3 83088.00
5.9 81363.00
6.0 93940.00
6.8 91738.00
7.1 98273.00
7.9 101302.00
8.2 113812.00
8.7 109431.00
9.0 105582.00
9.5 116969.00
9.6 112635.00
10.3 122391.00
10.5 121872.00线性回归直接计算。
txt_data = np.genfromtxt('./data/Salary_Data')
# print(txt_data)
x_data = txt_data[:, 0]
y_data = txt_data[:, 1]
t = np.ones_like(x_data)
x_data = np.column_stack((t, x_data))
print(x_data)
w3 = np.matmul(np.matmul(np.linalg.inv(np.matmul(np.transpose(x_data), x_data)), np.transpose(x_data)), y_data)
print(w3)
y3 = np.matmul(x_data, w3)
e3 = y3 - y_data
print(e3)
plt.figure(3)
plt.plot(e3)
plt.xlabel("/数据")
plt.ylabel("/误差")
plt.savefig("res3.png")
plt.show()3 总结
主要介绍机器学习中的一些问题以及解决对策,然后介绍了线性回归以及正则化方法,最后给出实例解释。这里并没有使用在机器学习包括深度学习中的一些手段如梯度下降,也没有使用任何的框架,更没有讨论数据特征的重要性而是使用全部特征,还没有对线性回归做更加深度的分析解释,如线性回归cholesky矩阵分解、total回归、lasso回归(L1)、ridge回归(L2)、弹性网络回归等进行概率角度的原理推导(包括这些的更多实例我会在tensorflow实战这一模块中演示)。再次说明,本文的目的是介绍线性回归的原理及其存在的问题,并介绍两种正则化方法,并给出简单的举例,希望加深自己的理解,也希望能有益于人,如果想对线性回归深究则需要参考更多更详细的资料。
最后
以上就是美丽缘分最近收集整理的关于机器学习(二):机器学习四大难题与线性回归1 机器学习四大问题2 线性回归 3 总结的全部内容,更多相关机器学习(二):机器学习四大难题与线性回归1 内容请搜索靠谱客的其他文章。








发表评论 取消回复