循环神经网络
将词汇用向量表示
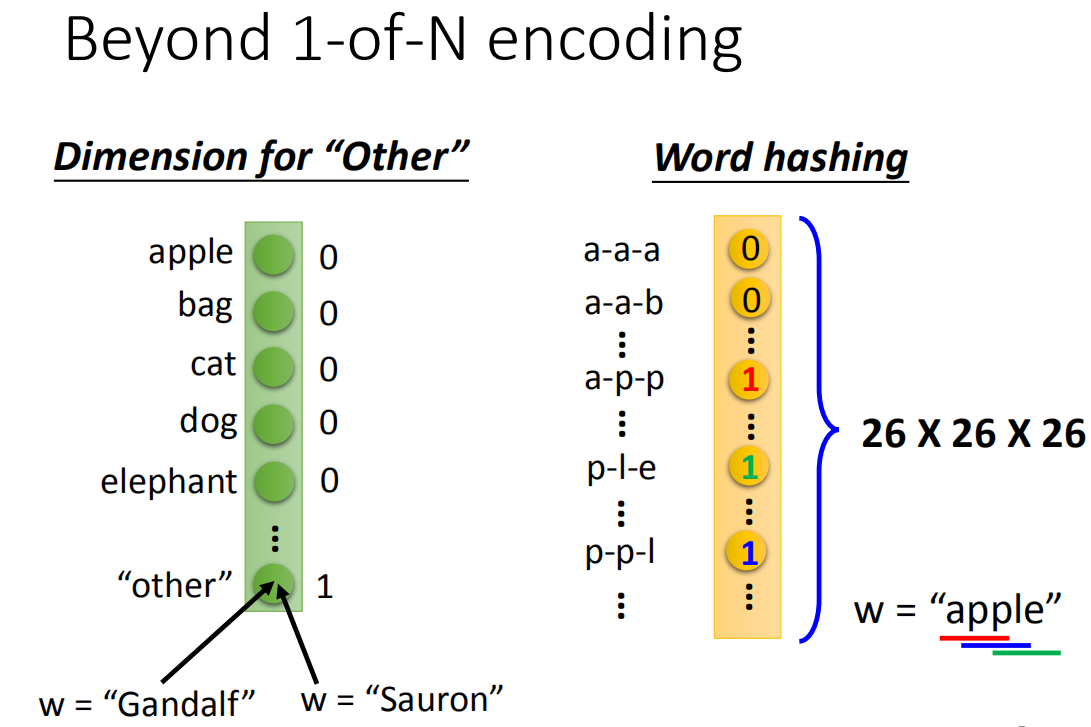
1-N Encoding
如果遇到没有的词汇,1-N Encoding没法表示,再加上一个other类别,将所有没出现的词汇归到other类别里
Recurrent Neural network(RNN) 循环神经网络
每一hidden layer的neuron产生的output会存起来,影响下一个nueron的计算。
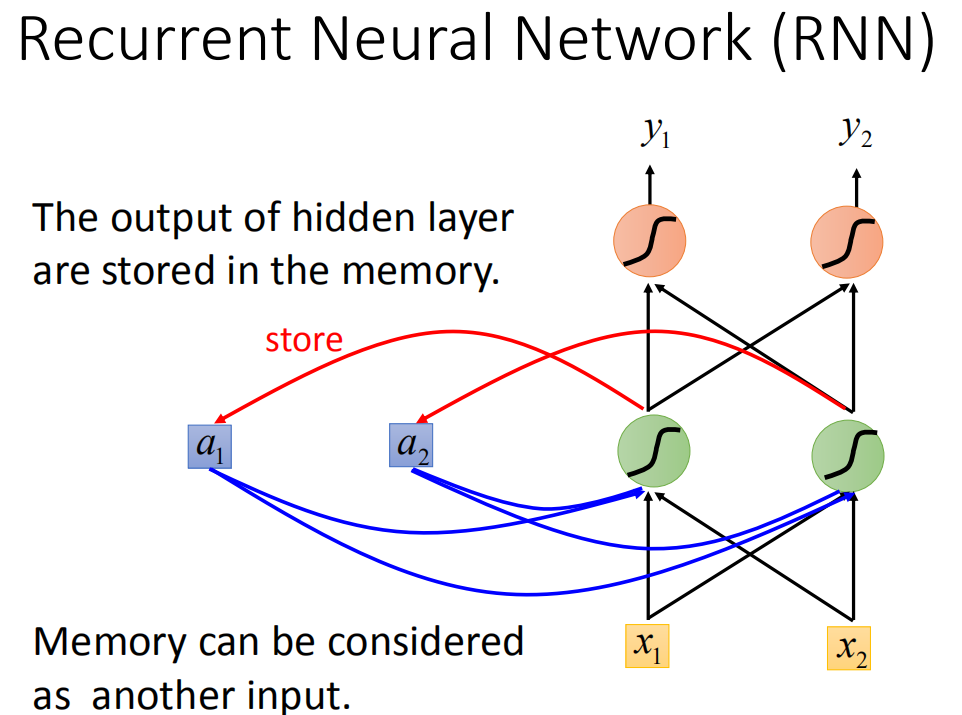
输入相同的值,由于memory里面存的不一样,输出会不同,跟输入的顺序也有关系。
例子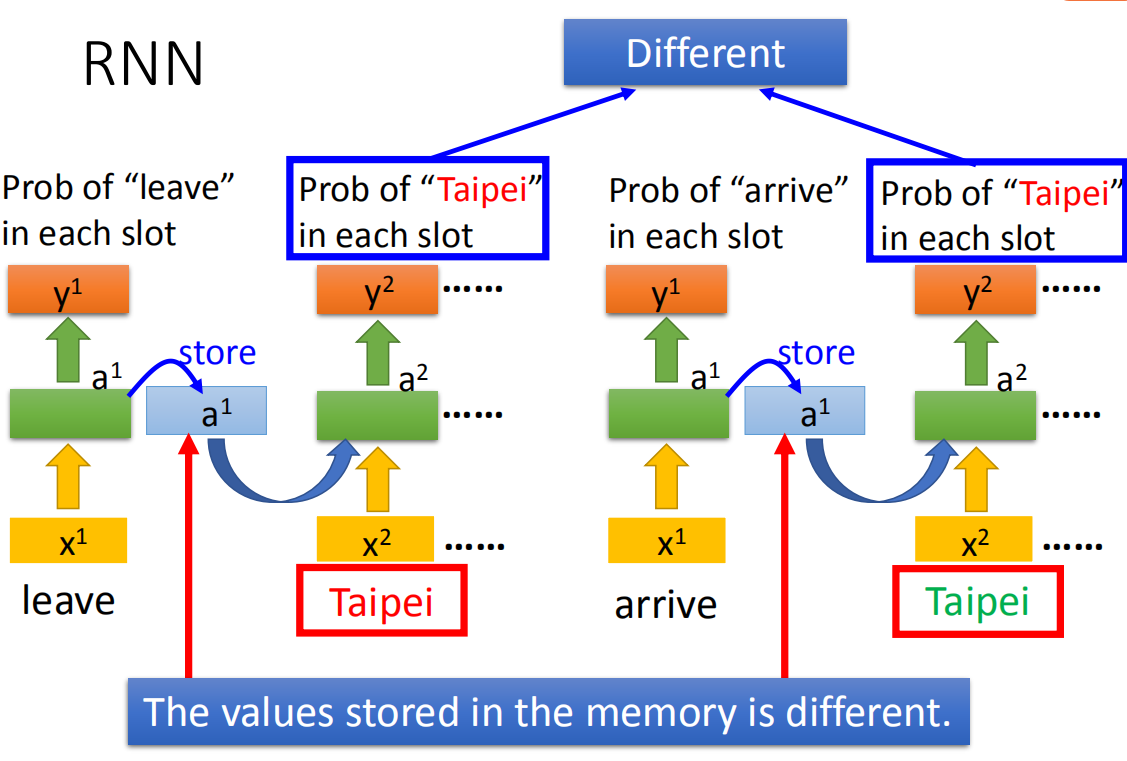
两处输入相同的词Taipei,使用同一个network,但由于在不同时间点使用,存储在memory中的输出不同,得到的output也不同
其他RNN
可以使用deep网络,每一层的hidden layer计算后将结果保存,下一次这一层的hidden layer计算时叭前一个时间点的值读取出来。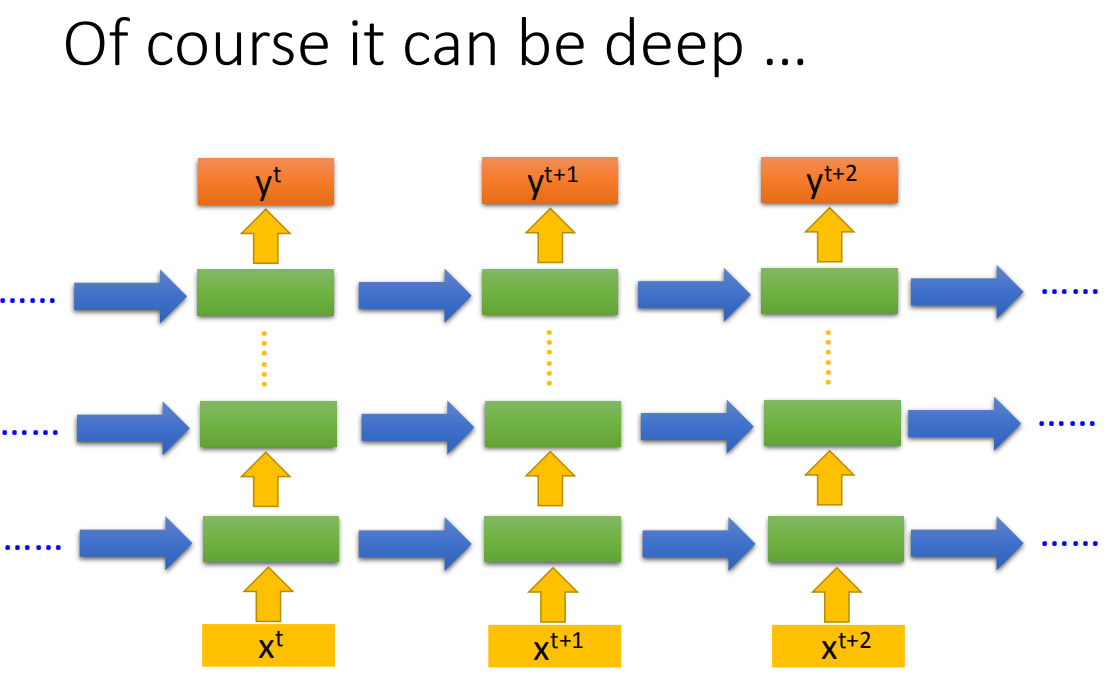
Elman network &Jordan network
之前的时Elman Network,把hidden layer的值存起来,在下一个时间点在读出来,还有一种做Jordan network,Jordan network存的是整个network output的值,它把output值在下一个时间点在读进来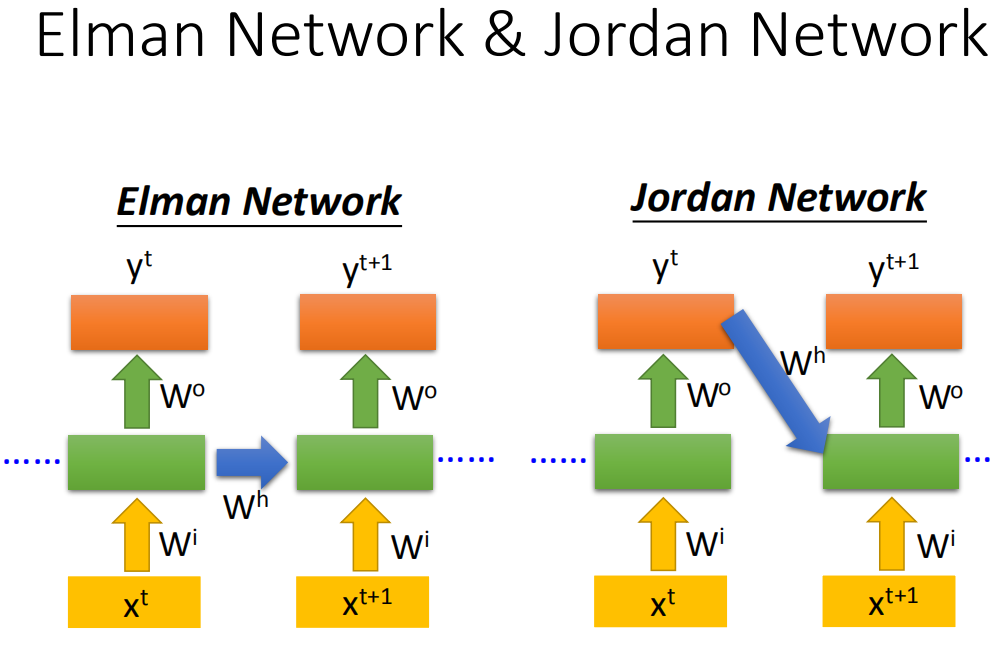
elman network没有target,很难控制它能学什么,但jordan network有target,可以比较清楚放在memory里的是什么样的东西。
Bidirectional neural network
双向RNN
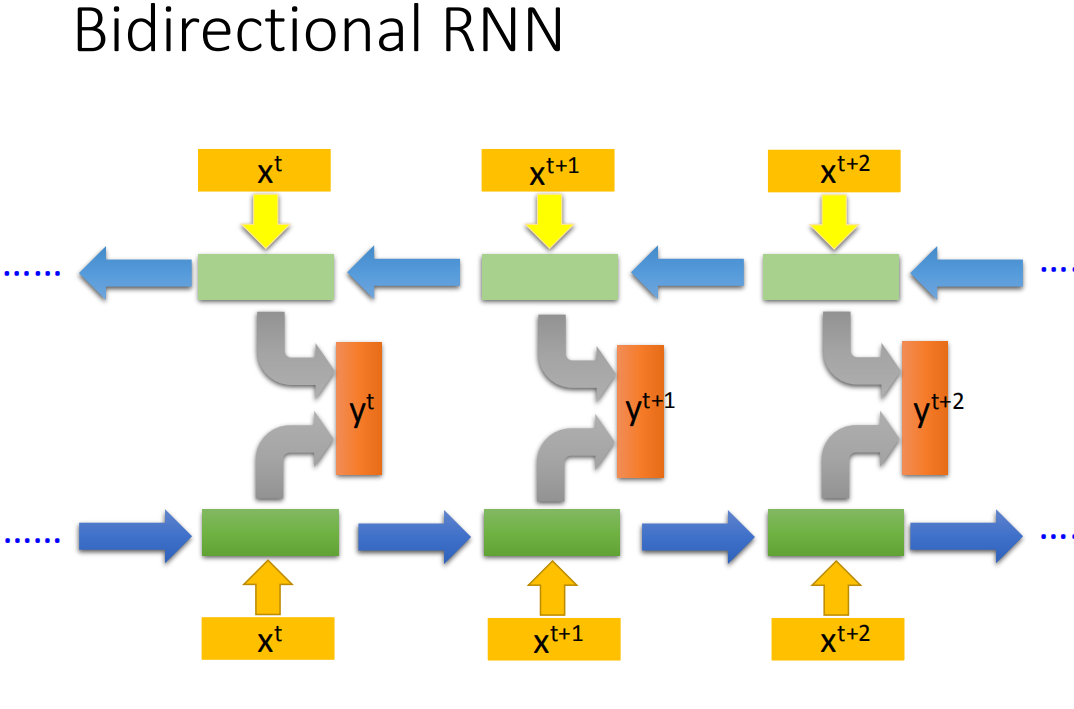
将一个正向RNN,和一个反向RNN,在相同的时间点同时作为一个output layer的输入,得到输出
y
t
y^t
yt ,某个时间点时得到的输出相当于考虑了整句的输入。
LSTM(Long Short-term Memory)
当你想要将output写进去的时候,需要通过一个inout gate,只有它打开时才能写入,至于input gate什么时候打开或者关闭,是神经网络自己学的。输出的地方也有一个output gate,它决定外界其他的meuron可不可以把这个值从memory中读取。还有Forget gate,决定什么时候把memory里存放的东西忘掉,什么时候会继续保存,这些都是由网络自己学到的。
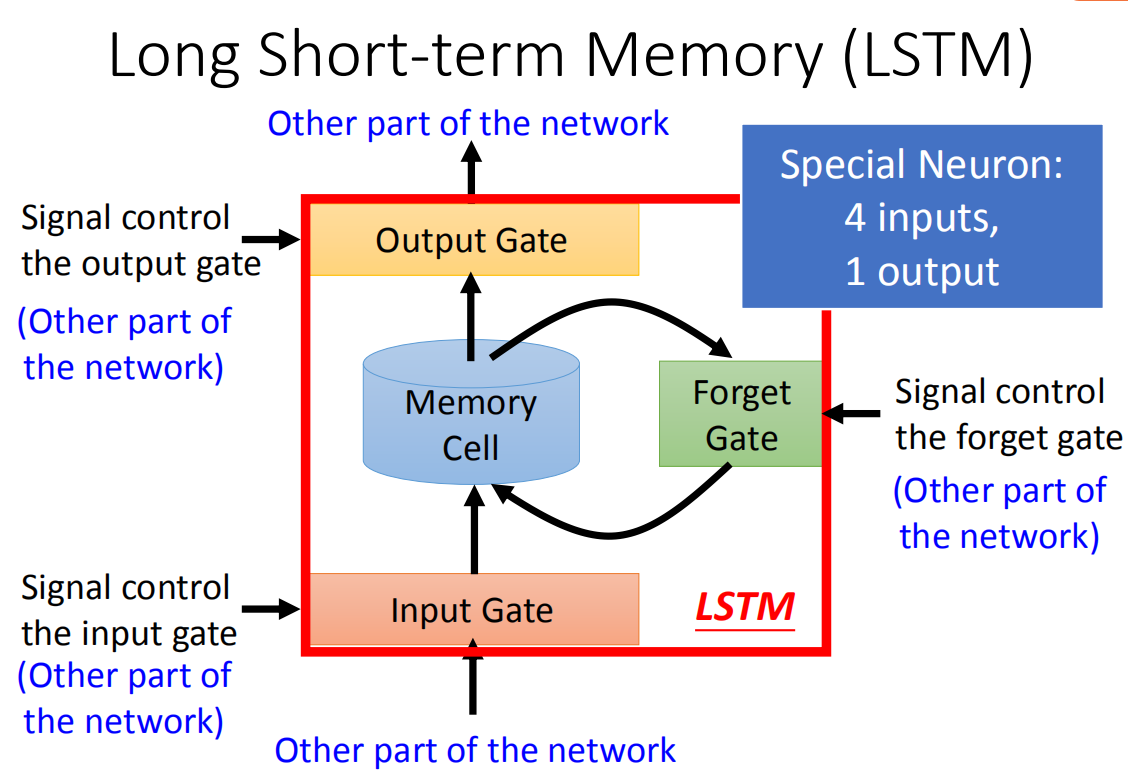
所以整个LSTM有四个输入——输入值,控制三个门的值,和一个输出——output
举例
这里可以去看看李宏毅老师的视频,非常细致。
LSTM原理
原来的神经网络会把input乘上不同的weight当成不同neuron的输入,每个neuron都是一个function,而LSTM的memory单元和neuron类似,只不过是input乘上不同的weight当成LSTM的不同的输入,在LSTM中需要四个不同输入才能得到一个输出。所以LSTM需要的参数量是一般neural network的四倍
和RNN的关系
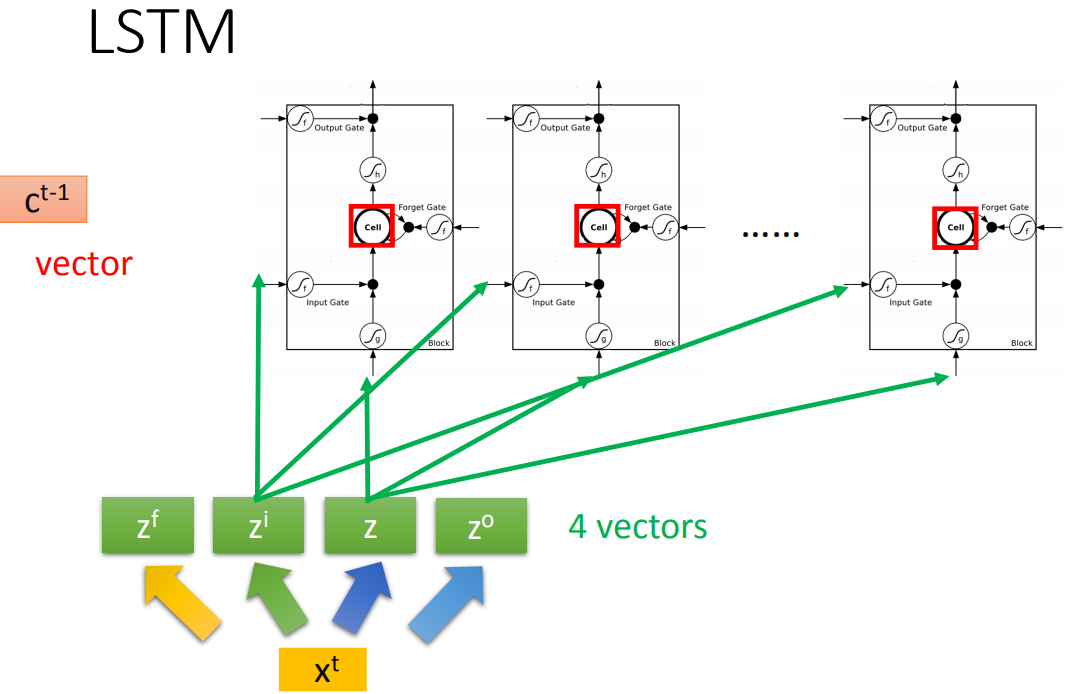
假设有一排LSTM,每个LSTM的memory都存了一个值,连接起来就是一个vector。在时间点t,输入一个 v e c t o r t {vector}^t vectort,这个vector首先乘上一个matrix,线性变换变成z,z的每一维对应每一个LSTM,将z输入到LSTM中。
然后 x t x^t xt乘上另一个transform得到 z i z^i zi,控制input gate,重复,也就是将 x t x^t xt乘上不同matrix得到四个和LSTM cell个数一样维度的vector,分别控制他们的input,input gate,output gate,forget gate。
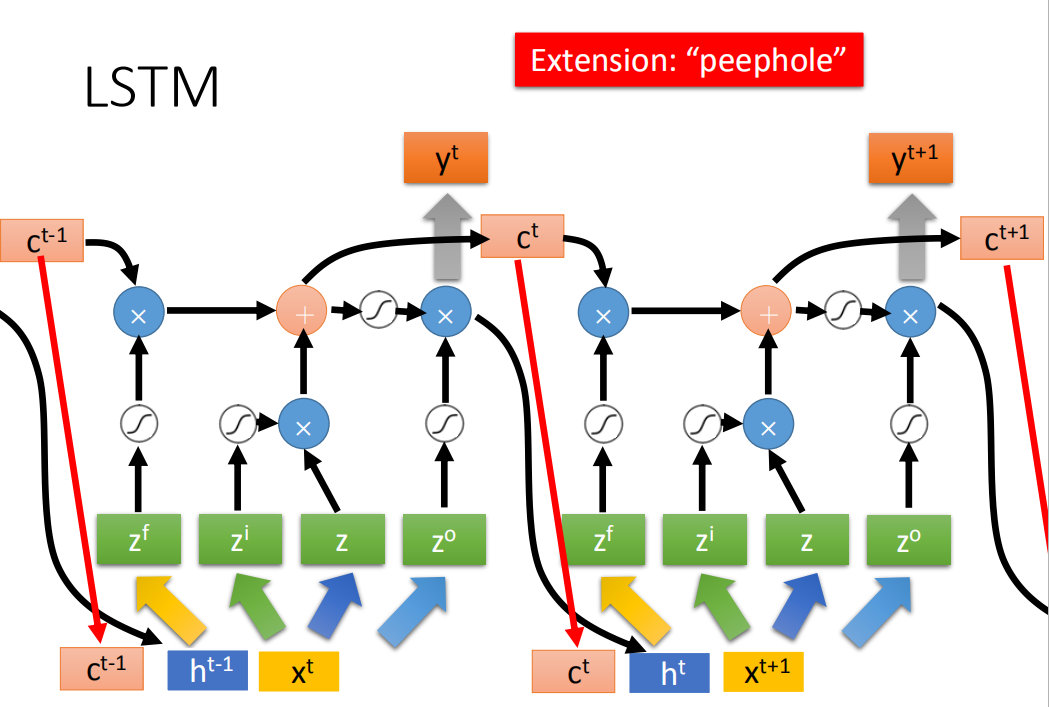
真正的LSTM还会在input时将上一个时间点hidden layer的输出和memory cell里面的值和
x
t
x^t
xt一起考虑。
GRU
简化版LSTM,只有两个gate,虽然少了一个gate,但跟LSTM效果差不多,也少了 1 3 frac{1}{3} 31的参数。
RNN怎么学习?
如果要学习的话,需要定义一个代价函数来评估模型好不好,再选择使loss最小的参数。
RNN的损失函数output和reference vector的entropy的和就是要最小化的对象。
定义损失函数之后,用梯度下降来训练,在RNN中使用BPTT,就是考虑时间的反向传播。
训练时,RNN不收敛
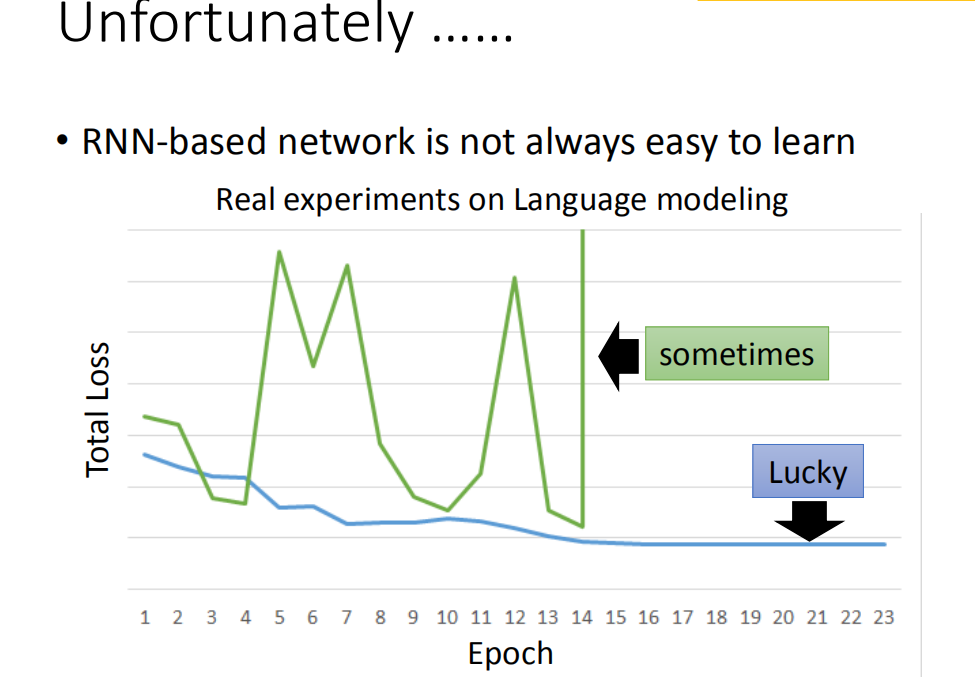
原因:RNN的total loss是非常陡峭的,假设你从橙色的点当做你的初始点,用GD开始调整你的参数(updata你的参数,可能会跳过一个悬崖,这时候你的loss会突然爆长,loss会非常上下剧烈的震荡)。有时候你可能会遇到更惨的状况,就是以正好你一脚踩到这个悬崖上,gradient会很大,但因为之前的gradient会很小,你可能已经把learning rate调的比较大。很大的gradient乘上很大的learning rate结果参数就update很多,整个参数就飞出去了。
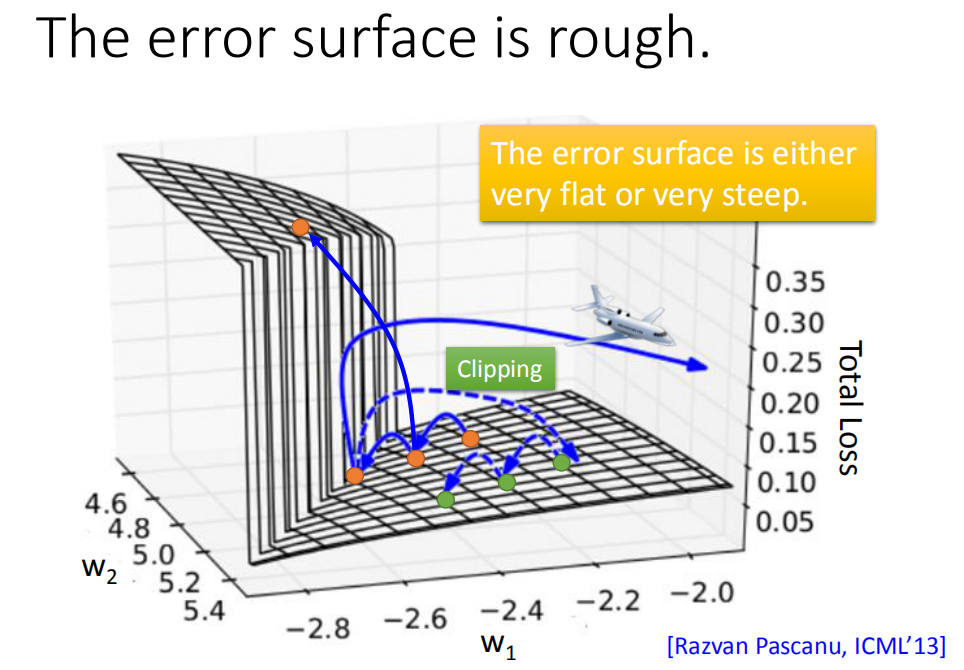
可以用clipping解决,当gradient大于某个阈值时,让它不超过那个阈值。
原因
由于输入的w会被反复输入,一点点的变化对output的影响也是很大的,learning rate的值很难和gradient匹配。
RNN不好训练的原因其实是因为它有high sequence,同样的weight在不同的时间点被反复地使用。
如何解决RNN梯度消失或爆炸?
使用LSTM,LSTM可以让你的error surface不要那么崎岖。它可以做到的事情是,它会把那些平坦的地方拿掉,解决gradient vanish的问题,但不会解决gradient explode的问题。
为什么我们把RNN换成LSTM?为什么LSTM会handle gradient vanishing的问题呢?
因为在RNN中,每一个时间点memory里面的值都会被覆盖掉,但LSTM里的值,除非forget gate把memory里的值洗掉,否则weight起的影响会一直存在,不会有梯度消失的问题。
GRU
当input gate打开的时候,forget gate会自动的关闭(清除存在memory里面的值),当forget gate没有要清楚里面的值,input gate就会被关起来。也就是说你要把memory里面的值清掉,才能把新的值放进来。
其他应用
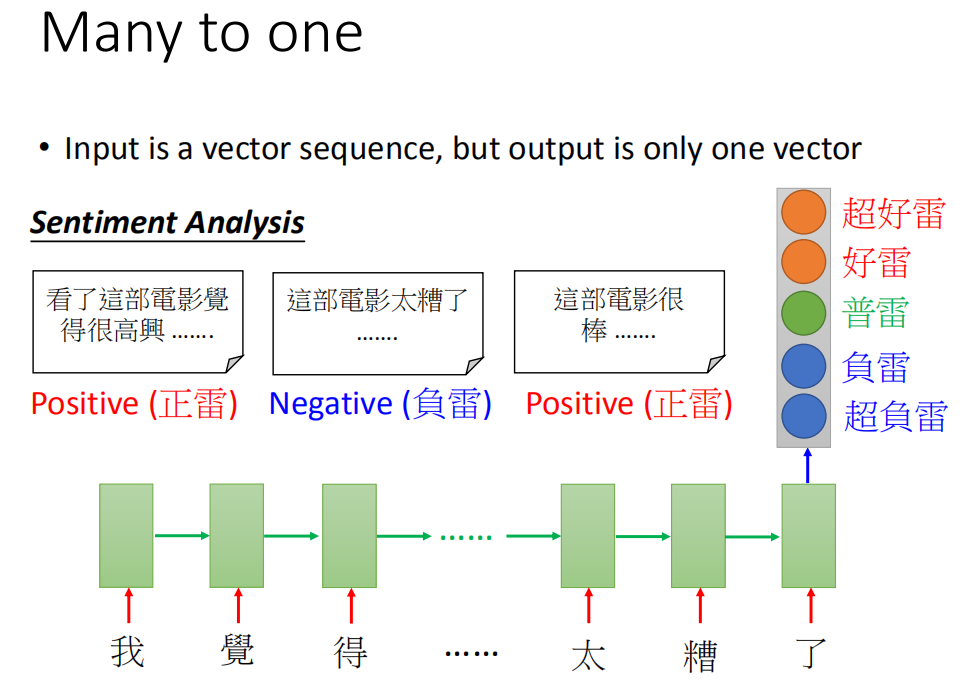
多对一序列
情感识别
输入是一个特征序列,输出一个分类
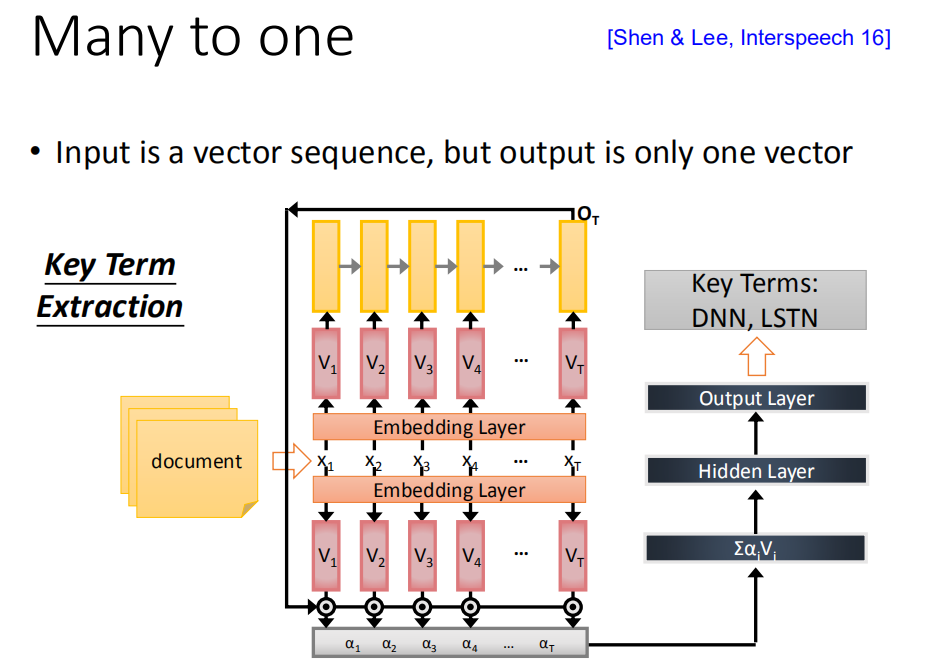
key term extraction
你今天能够收集到一些training data(一些document,这些document都有label,哪些词汇是对应的,那就可以直接train一个RNN),那这个RNN把document当做input,通过Embedding layer,然后用RNN把这个document读过一次,然后把出现在最后一个时间点的output拿过来做attention,你可以把这样的information抽出来再丢到feedforward neural network得到最后的output
多对多序列
input和output都是sequence,但是output sequence比input sequence短
语音识别
语音辨识这个任务里面input是acoustic sequence(说一句话,这句话就是一段声音讯号)。我们一般处理声音讯号的方式,在这个声音讯号里面,每隔一小段时间,就把它用vector来表示。这个一小段时间是很短的(比如说,0.01秒)。那output sequence是character sequence。
由于每个input对应的时间间隔很小,好多个vector对应到同一个character。所以你的辨识结果为“好好好棒棒棒棒棒”。通过trimming(不是重复的东西拿掉),就变成“好棒”。
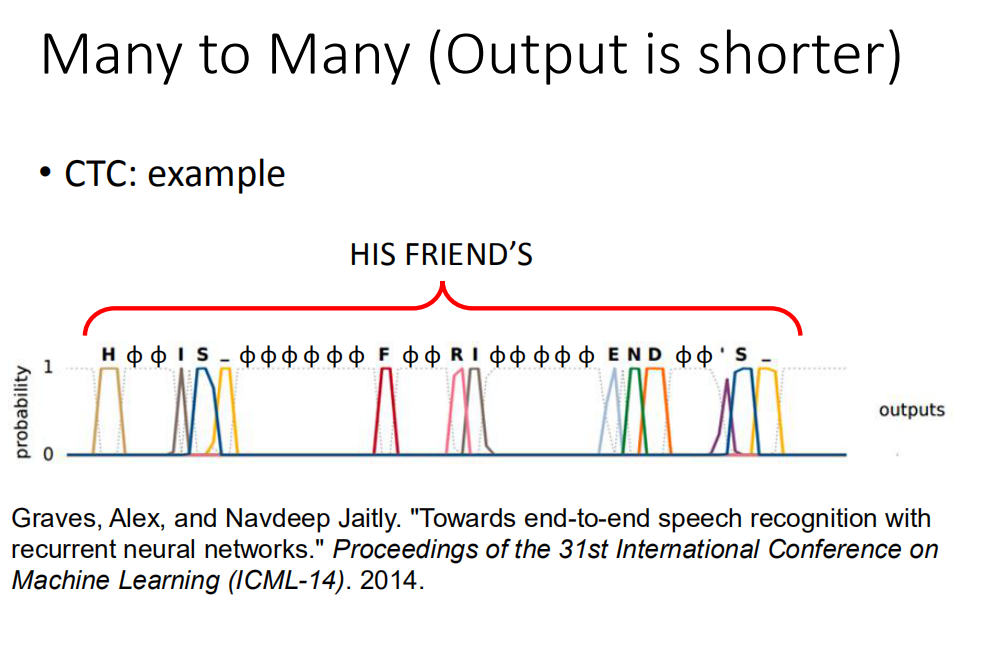
CTC语音识别
在output的时候,不只output所有中文character,还会output符号“null”,最后把“null”拿掉,可以解决叠字的问题。
训练的时候,无法确定具体的某个输出值对应哪个character,所以我们假设出所有可能的情况,都认为是正确的,然后一起训练。
Sequence to sequence learning
输入和输出都是序列。不确定input和output哪个比较长
先输入,用RNN读,在最后一个时间点的时候,memory里面存了所有input sequence的信息。之后会输出一个output,再把之前的output作为输入,读取mmory里面的值,输出下一个output,但是会一直有输出。
如何停止呢?需要在最后输出一个“断”
Beyond Sequence
输入一个句子,得到这个句子的结构树,把书描述成一个sequence就可以实现
Document转成Vector
最后
以上就是虚拟毛巾最近收集整理的关于深度学习(李宏毅)——RNN循环神经网络的全部内容,更多相关深度学习(李宏毅)——RNN循环神经网络内容请搜索靠谱客的其他文章。








发表评论 取消回复