前言
神经网络现在各种网络结构都有了,每一种网络结构都是针对某些领域问题而提出来的,RNN 循环神经网络同样有它自己的背景,通过这些背景你可以更加认识RNN,甚至未来自己也可以设计自己的网络结构。
RNN的提出
在RNN之前,大家提出来的网络结构都很独立,他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如NLP的机器翻译、对话系统、词性标注等,都必须考虑单词与单词的序列问题,他们都是符合一定的语法的,前后单词都有依赖,举个例子:高铁在铁轨上高速驾驶。这几个单词调换顺序是有问题的,甚至换成其他单词在语文的角度上都会语法不通顺,所以我们需要关注每个单词的依赖关系,所以有人提出了一种新的神经网络,也就是RNN,主要解决序列学习和序列翻译问题的方法(seq2seq),接下来我们来看下RNN的模型,了解一下它为什么可以解决这种依赖。
RNN 模型
先来一张图看看结构,这个结构看一眼就懂了:
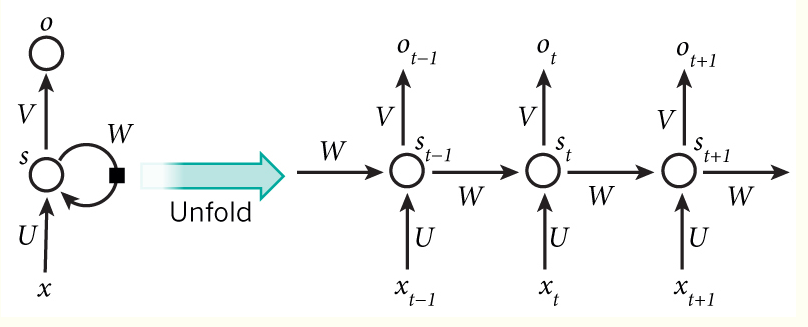
从图中我们可以注意到一下几点问题:
- 输入有先后关系的
对于一个句子来说,每一个单词都是一个输入,不过单纯这样看,其实并没有体现RNN的特点 - 每一个输入经过隐藏层后的输出都作为下一个隐藏层的输入
这一步就相当于把上一个输入给到了当前输入的网络结构中,通过这种方式来解决输入之间的依赖问题, - 每一个输入都有一个输出层
这个输出层也给出了,怎么用就看你,因为具体任务有具体着重的输出层,比如机器翻译只会看最后一个输出层,但词性标注就会看每一个输出层。 - 注意到隐藏层的参数都是一样的
W
W
W
权重矩阵 W W W就是隐藏层上一次的值作为这一次的输入的权重,但每一层的权重是一样的,这也是它称作循环神经网络的原因,因为每一层的结构是一样的,就输入不一样。 -
U
U
U和
V
V
V
U U U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值; V V V是隐藏层到输出层的权重矩阵,这个跟其他神经网络没啥区别。 U U U和 V V V、 W W W的参数都是共享的,也就是都一样的。
上面只是分析了网络结构,现在我们来给出数学形式化描述,哈哈,也就是公式:
O
t
=
g
(
V
•
S
t
)
S
t
=
f
(
U
•
X
t
+
W
•
S
t
−
1
)
O_t=g(V•S_t)\ S_t=f(U•X_t+W•S_{t-1})
Ot=g(V•St)St=f(U•Xt+W•St−1)
公式也比较容易理解
RNN参数共享
深度网络中参数多是事实,减少参数是刚需,当然参数共享也是区别前馈神经网络的原因之一,理论上的支持有人提出参数共享本质上就是说明该模块功能完全相同;在任何一个时间步上,细胞的功能是相同的;另一方面在读取序列时,如果RNN模型在训练期间的每个步骤使用不同的参数,则不会将其推广到看不见的不同长度的序列。
RNN 存在的问题
由于RNN在所有的时间步中共享参数(U,V,W),因此每个输出的梯度不仅取决于当前时间步长的计算,而且还取决于以前的时间步长。 例如,为了计算t=4处的梯度,我们需要反向传播3个步骤并对梯度求和(链式法则),这叫做时间反向传播(BPTT)。由于RNN模型如果需要实现长期记忆的话需要将当前的隐含态的计算与前n次的计算挂钩(具体推导见下文),那样的话计算量会呈指数式增长,导致模型训练的时间大幅增加,因此RNN模型一般不直接用来进行长期记忆计算。
使用BPTT训练的普通RNNs由于消失/爆炸梯度问题而难以学习长期依赖关系(例如,步骤之间相距很远的依赖关系)。
- 梯度消失
时间轴上的 W W W的,时间轴太长了,会导致梯度消失,所以RNN存在无法解决长时依赖的问题。为解决上述问题,提出了LSTM。梯度消失的原因主要是:
∏ t = 0 t ∂ s t ∂ s t − 1 prod_{t=0}^{t}frac{partial s_t}{partial s_{t-1}} t=0∏t∂st−1∂st
∂ s t ∂ s t − 1 frac{partial s_t}{partial s_{t-1}} ∂st−1∂st接近0或者大于1,要消除这种情况就需要把这一坨在求偏导的过程中去掉,至于怎么去掉,一种办法就是随机让 ∂ s t ∂ s t − 1 = = 0 frac{partial s_t}{partial s_{t-1}}==0 ∂st−1∂st==0, ∂ s t ∂ s t − 1 = = 1 frac{partial s_t}{partial s_{t-1}}==1 ∂st−1∂st==1。
为了解决这种问题,有三种方式:
- (1)合适地初始化W,即采用正则化;
- (2)将tanh或sigmoid替换为ReLU;
- (3)使用LSTM或者GRU。
‘梯度消失’其实在DNN和RNN中意义不一样,DNN中梯度消失指的是误差无法传递回浅层,导致浅层的参数无法更新;而RNN中的梯度消失是指较早时间步所贡献的更新值,无法被较后面的时间步获取,导致后面时间步进行误差更新的时候,采用的只是附近时间步的数据。
参考博客
RNN 梯度爆炸的问题
softmax损失函数最简单的求导推导
最后
以上就是要减肥钻石最近收集整理的关于RNN:循环神经网络(Recurrent Neural Network)的全部内容,更多相关RNN:循环神经网络(Recurrent内容请搜索靠谱客的其他文章。








发表评论 取消回复