深度学习-RNN&LSTM学习笔记
文章目录
- RNN中的关键词:
- LSTM关键词
- RNN和LSTM出现的背景和意义
- 标准LSTM门:
- keras中LSTM的参数介绍
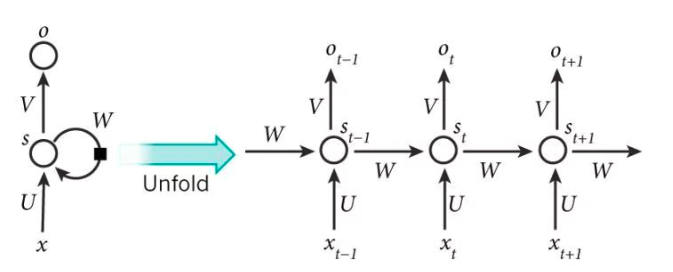
RNN中的关键词:
时序数据:有前后依赖关系的数据序列。例如:对一个包含 3 个单词的语句,那么展开的网络便是一个有 3 层神经网络,每一层代表一个单词。
循环:RNN 之所以称为循环神经网路,是因为一个序列当前的输出与前面的输出有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,也就是说隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
参数共享:虽然RNN在每一步都在做相同的事,那就是更新共享的记忆单元cell,只是输入不同,大大降低了网络需要学习的参数。CNN 和 RNN 的共享参数:我们需要记住的是,深度学习是怎么减少参数的,很大原因就是参数共享,而CNN 是在空间上共享参数,RNN 是在时间上(顺序上)共享参数(cell记忆单元)
长序依赖问题:当前的输入需要依赖很久之前的序列,由于参数在传递的过程中会出现梯度消失或者梯度爆炸的问题,使得普通的RNN很难解决这类问题。
隐藏层:是网络的记忆单元。根据当前输入层的输出与上一步隐藏层的状态进行计算。其中 f 一般是非线性的激活函数,如 tanh 或 ReLU
LSTM关键词
遗忘门:门:是一种让信息有选择的通过的过程,一般将参数经过sigmoid转化为【0,1】之间,0表示忘记,1表示记忆。当信息需要被保留时,才经过激活函数处理,最终输出。否则,直接丢弃
cell记忆单元:RNN的不足是只能根据最近的状态和当前的输入来输出参数;跟原来的RNN相比,lstm最大的亮点是新增了cell记忆单元,它实际上是一层神经元,目的是记忆历史信息。每个时刻t的隐层计算中主要的工作量是更新cell的状态,遗忘历史的记忆,根据历史状态和当前输入更新记忆,并根据历史状态、当前输入和记忆细胞来输出隐藏层的参数。所有时刻共享记忆单元。
RNN和LSTM出现的背景和意义
RNN是循环神经网络的意思,为什么要使用循环呢?对什么进行循环呢?
在翻译中,常常用根据上下文的意思来判断某个词或者某句话的意思。在时序问题中,需要根据历史的数据来推测当前数据的值;但是传统的神经网络中每个数据的输入和输出都是孤立的,RNN就横空出世了。
RNN中循环的含义是 在模型在计算当前的输入信息是,会将历史的输入信息产生的参数考虑进来,这样网络就有了记忆上文的作用了。双向RNN不仅会考了上文的参数,还会考虑下文的参数,这样网络就能够记忆上下文的信息了。其中循环的含义是:上一个输入信息的输出信息会传递给当前的模型,当前的模型输出的信息会传递给下一个输入数据的计算过程,但是整个模型的参数对象和个数是不变的,只不过值在不断更新。即在 RNN 中,每输入一步,每一层各自都共享参数 U,V,W。其反映着 RNN 中的每一步都在做相同的事,只是输入不同,因此大大地降低了网络中需要学习的参数。
但是普通 RNN 训练中,无法解决长时依赖问题(即当前的输出与前面很长的一段序列有关,一般超过十步就无能为力了),因为 Backpropagation Through Time (BPTT) 会带来所谓的梯度消失或梯度爆炸问题(the vanishing/exploding gradient problem)。 就像一个试图记住所有事的人,最终什么也想不起来。怎么解决呢?LSTM就横空出世了。
LSTM:长短期记忆模型。该模型能够处理时间跨度较长的输入信息,原理是LSTM内部有一个遗忘门,遗忘门就像一个开关,当参数包含的信息量不满足规则时,就遗忘该参数。就像智者不会什么事都要记住,而是有选择地记住重要的事,反而会记得更清晰。这样,LSTM就能够记住长序数据了。
遗忘门的原理是:门:是一种让信息有选择的通过的过程,一般将参数经过sigmoid转化为【0,1】之间,0表示忘记,1表示记忆。当信息需要被保留时,才经过激活函数处理,最终输出。否则,直接丢弃。
标准LSTM门:
参考:https://studentke.github.io/2019/04/21/understand-the-LSTM/
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
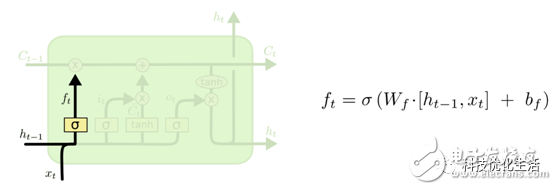
1)决定丢弃信息:
在向cell记忆单元中添加新的信息之前,遗忘门会根据当前的输入和历史隐藏层的信息选择性的以往某些不重要的记忆
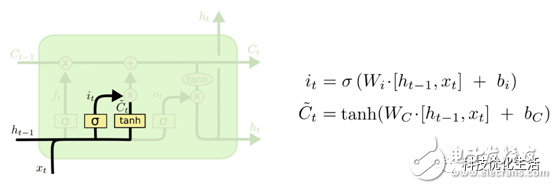
2)确定更新的信息:
根据本次的输入和历史隐藏层信息向cell记忆单元中添加新信息
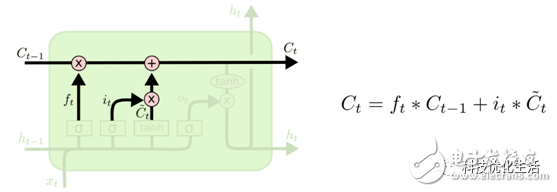
3)更新细胞状态:
遗忘历史的某些旧记忆,再添加当前新的记忆
4)输出信息
计算隐藏层的输出信息,和原RNN保持一致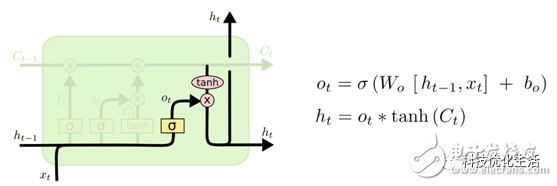
keras中LSTM的参数介绍
-
return_sequences:默认为false。当为false时,返回最后一层最后一个步长的hidden state;当为true时,返回最后一层的所有hidden state。
在LSTM中间层一般将return_sequence =True,在训练的最后return_sequence =False
例如:
#变换
trainx = np.reshape(trainx,(trainx.shape[0],timesteps,1))#变换shape,以满足keras
#lstm training
model = Sequential()
model.add(LSTM(128,input_shape=(timesteps,1),return_sequences= True))
model.add(Dropout(0.5))
model.add(LSTM(128,return_sequences=True))
#model.add(Dropout(0.3))
model.add(LSTM(64,return_sequences=False))
#model.add(Dropout(0.2))
model.add(Dense(predict_steps))
model.compile(loss=“mean_squared_error”,optimizer=“adam”)
model.fit(trainx,trainy, epochs= 50, batch_size=200) -
return_state:默认false.当为true时,返回最后一层的最后一个步长的输出hidden state和输入cell state
cell是指一种伴随整个网络过程中用来记忆,遗忘,选择并最终影响 hidden state 结果的东西,称为 cell state。 cell state 就是实现 long short memory 的关键 -
输入数据的格式:必须是3维矩阵,分别是样本个数,循环次数,样本的特征维度:样本reshape input to be 3D [samples, timesteps, features]
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
最后
以上就是平淡钢笔最近收集整理的关于RNN&LSTM学习笔记的全部内容,更多相关RNN&LSTM学习笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复