文章目录
- Naive RNN
- 概述
- 结构
- 问题
- LSTM
- 概述
- 外部结构
- 内部结构
- 为什么LSTM缓解了RNN的梯度消失问题
Naive RNN
概述
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题,因此在机器翻译、问答系统等NLP领域有很重要的应用。
结构
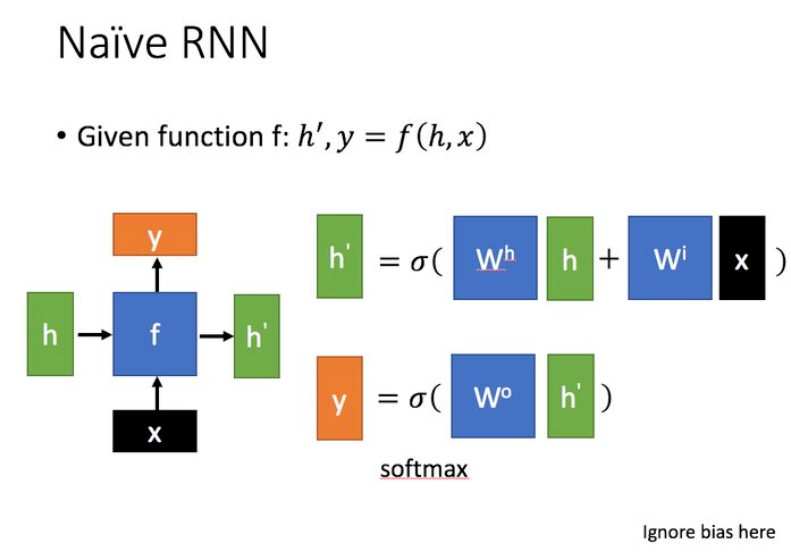
其中,x表示当前状态下数据的输入,h表示接收到的上一个节点的输入,y表示当前状态下的输出,h’表示传递到下一个节点的输出。图中的公式表明了h‘是历史状态(长期记忆)h和当前状态的输入x的线性组合,而y则是对h’进行线性操作。
假设输入为一个序列,则RNN则可以展开成这样的结构:
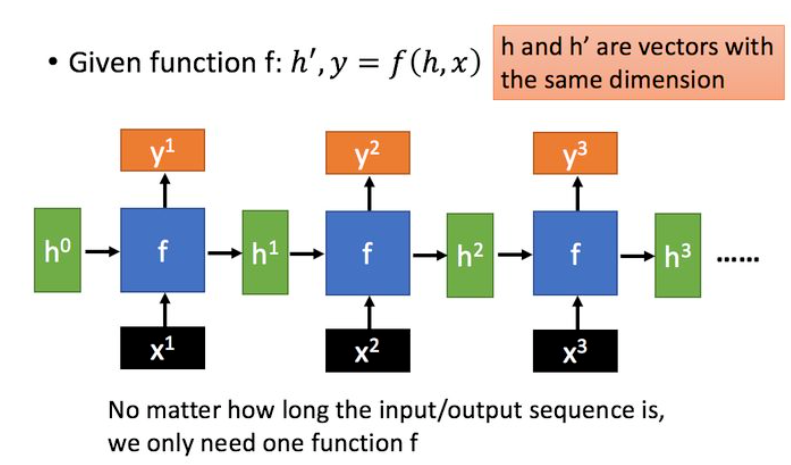
问题
但是实际使用中,RNN具有很严重的梯度消失和梯度爆炸的问题,这是个实践问题,而不是一个理论问题,因为合适的参数一定存在,但是RNN的这组合适的参数不容易找到,这对于RNN来说犹如外卖软件不能点外卖一样致命。
LSTM
概述
LSTM的全称是Long short-term memory,即长短期记忆网络,它有效缓解了RNN中梯度消失的问题(梯度爆炸的问题可以从其他技术中得到缓解),因此在更长的序列上又更优秀的表现。
补充:更加严谨的叫法其实是 LSTM-RNN,即带有长短期记忆网络单元的RNN网络。
外部结构
从输入输出上,LSTM和传统RNN的对比如下所示
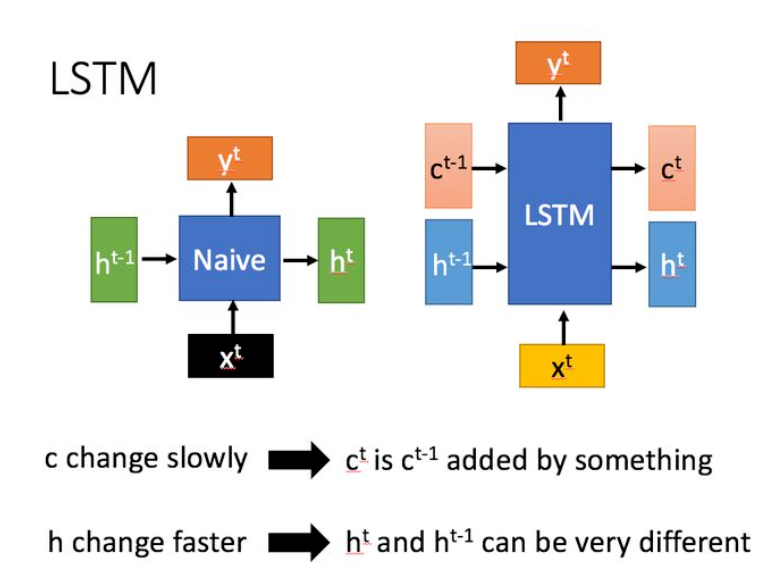
传统RNN只有一个传递状态h,但是LSTM有两个传递状态 c c c和 h h h,前者代表cell state,是在前一个状态输出的c的基础上调整来的,变化缓慢,所以代表长期记忆(long-term memory);而后者表示hidden state,因为作为和输入x拼接的变量,因此与相邻LSTM单元的输入值有关,变化较大,所以代表短期记忆(short-term memory)
可见,LSTM中的c反而和naive RNN的h更加相似,代表着long-term memory。
内部结构
首先,第t个LSTM单元的输入为当前输入 x t x^t xt和上一个状态传递下来的short-term memory h t − 1 h^{t-1} ht−1拼接并训练得到的四个状态:
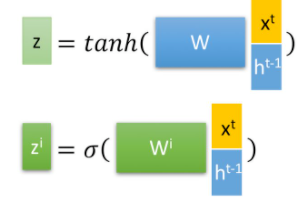
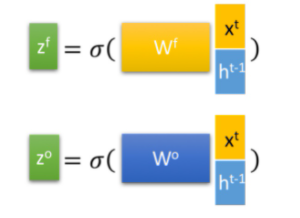
其中,zf,zi,zo是由拼接向量乘以权重矩阵之后,再通过一个 sigmoid激活函数转换成0到1之间的数值,来作为一种门控状态,分别表示遗忘门控、输入门控、输出门控。
而 z 则是将结果通过一个tanh激活函数将转换成-1到1之间的值(这里使用 tanh 是因为这里是将其做为输入数据,而不是门控信号,也有人认为,使用tanh也是传递状态c和h不同的本质原因)
下面则是LSTM的内部结构
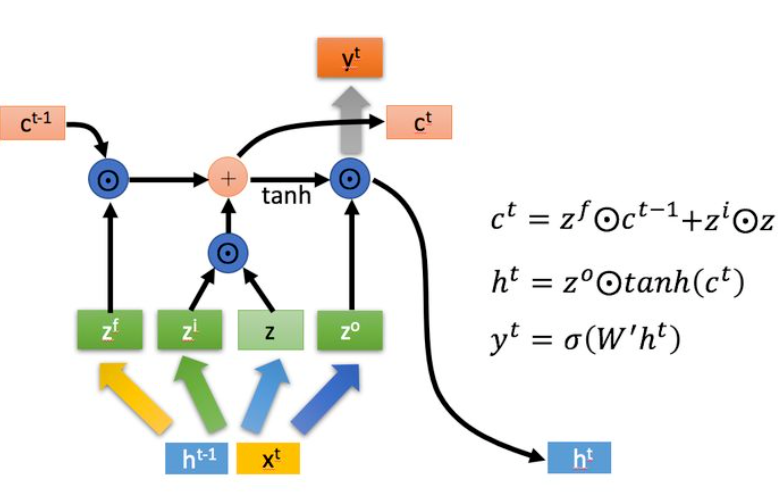
⊙ odot ⊙代表Hadamard Product,即矩阵对应元素相乘,这要求两个矩阵是同型的, ⊕ oplus ⊕代表矩阵相加。
LSTM主要有三个阶段,分别对应三个门限:
-
忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。具体来讲,就是 z f z^f zf控制 c t − 1 c^{t-1} ct−1的哪些部分需要遗忘。
-
选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 x t x^t xt进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 z z z表示,而选择的门控信号则是由 z i z^i zi(有人认为i代表information,也有人认为i代表input)来进行控制。
将上面两步得到的结果相加,即可得到传输给下一个状态的 c t c^t ct ,也就是上图中的第一个公式。 -
输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 z o z^o zo来进行控制的,并且还对上一阶段得到的 c o c^o co进行了放缩(通过一个tanh激活函数进行变化)。
而 y t y^t yt的输出和 h t h^t ht有关,这一点和naive RNN很相似。
为什么LSTM缓解了RNN的梯度消失问题
为什么RNN很容易出现梯度消失
假设使用SGD train RNN模型的参数,则有:
w
i
+
1
=
w
i
−
r
∂
L
o
s
s
∂
w
∣
w
:
w
i
w^{i+1}=w^i-rfrac{partial Loss}{partial w}|_{w:w^i}
wi+1=wi−r∂w∂Loss∣w:wi
而naive RNN模型的输出参数的表达式为
h
′
=
σ
(
w
h
⋅
h
+
w
i
⋅
x
)
y
=
σ
(
w
o
⋅
h
′
)
h'=sigma(w^hcdot h+w^icdot x) \ y=sigma(w^ocdot h')
h′=σ(wh⋅h+wi⋅x)y=σ(wo⋅h′)
其中,
w
h
,
w
i
,
w
o
w^h,w^i,w^o
wh,wi,wo都是要学习的参数。
接下来我们计算损失函数,这里的损失函数要考虑从0时刻到t时刻的损失函数求和,又称为BPTT(Back Propagation Trough Time):
L
=
∑
t
=
0
T
L
t
L=sum_{t=0}^T{L_t}
L=t=0∑TLt
计算损失函数的梯度:
∂
L
∂
W
=
∑
t
=
0
T
∂
L
t
∂
W
frac{partial L}{partial W}=sum_{t=0}^{T} frac{partial L_{t}}{partial W}
∂W∂L=t=0∑T∂W∂Lt
分别列出损失函数对三个梯度的求导表达式:
∂
L
∂
W
=
∑
t
=
0
T
∂
L
t
∂
W
∂
L
t
∂
W
o
=
∑
t
=
0
T
∂
L
t
∂
y
t
∂
y
t
∂
W
o
∂
L
t
∂
W
i
=
∑
t
=
0
T
∑
k
=
0
t
∂
L
t
∂
y
t
∂
y
t
∂
h
t
(
∏
j
=
k
+
1
t
∂
h
j
∂
h
j
−
1
)
∂
h
k
∂
W
i
∂
L
t
∂
W
h
=
∑
t
=
0
T
∑
k
=
0
t
∂
L
t
∂
y
t
∂
y
t
∂
h
t
(
∏
j
=
k
+
1
t
∂
h
j
∂
h
j
−
1
)
∂
h
k
∂
W
h
frac{partial L}{partial W}=sum_{t=0}^{T} frac{partial L_{t}}{partial W}frac{partial L_{t}}{partial W^{o}}=sum_{t=0}^{T} frac{partial L_{t}}{partial y_{t}} frac{partial y_{t}}{partial W^{o}}\ frac{partial L_{t}}{partial W^{i}}=sum_{t=0}^{T} sum_{k=0}^{t} frac{partial L_{t}}{partial y_{t}} frac{partial y_{t}}{partial h_{t}}left(prod_{j=k+1}^{t} frac{partial h_{j}}{partial h_{j-1}}right) frac{partial h_{k}}{partial W^{i}}\ frac{partial L_{t}}{partial W^{h}}=sum_{t=0}^{T} sum_{k=0}^{t} frac{partial L_{t}}{partial y_{t}} frac{partial y_{t}}{partial h_{t}}left(prod_{j=k+1}^{t} frac{partial h_{j}}{partial h_{j-1}}right) frac{partial h_{k}}{partial W^{h}}
∂W∂L=t=0∑T∂W∂Lt∂Wo∂Lt=t=0∑T∂yt∂Lt∂Wo∂yt∂Wi∂Lt=t=0∑Tk=0∑t∂yt∂Lt∂ht∂yt⎝⎛j=k+1∏t∂hj−1∂hj⎠⎞∂Wi∂hk∂Wh∂Lt=t=0∑Tk=0∑t∂yt∂Lt∂ht∂yt⎝⎛j=k+1∏t∂hj−1∂hj⎠⎞∂Wh∂hk
可见,导致RNN容易梯度消失和爆炸的就是这里的连乘项,其本质是
h
t
h_t
ht对
W
i
W^i
Wi求导需要链式求导到最初的
h
k
h^k
hk,为了进一步分析,我们将连乘项中的
h
j
h_j
hj对
h
j
−
1
h_{j-1}
hj−1的导数展开:
∂
h
j
∂
h
j
−
1
=
σ
′
W
h
=
σ
(
1
−
σ
)
W
h
frac{partial h_{j}}{partial h_{j-1}}=sigma^{prime} W^{h}=sigma(1-sigma)W^h
∂hj−1∂hj=σ′Wh=σ(1−σ)Wh
其中,
σ
(
1
−
σ
)
sigma(1-sigma)
σ(1−σ)的取值范围是(0,0.25),即如果
W
h
W^h
Wh小于4,连乘式的每一项都是小于1的,就很容易发生梯度消失!反之,梯度爆炸则不那么容易发生。
LSTM如何避免了梯度消失
LSTM的BPTT展开式非常复杂,但是核心是将RNN中的连乘式替换为了
c
j
c_j
cj对
c
j
−
1
c_{j-1}
cj−1的求导:
∏
j
=
k
+
1
t
∂
h
j
∂
h
j
−
1
→
∏
j
=
k
+
1
t
∂
c
j
∂
c
j
−
1
prod_{j=k+1}^{t} frac{partial h_{j}}{partial h_{j-1}}toprod_{j=k+1}^{t} frac{partial c_{j}}{partial c_{j-1}}
j=k+1∏t∂hj−1∂hj→j=k+1∏t∂cj−1∂cj
这也从侧面佐证了我们上面所说的,LSTM中的传递状态c和RNN中的传递状态h都代表着long-term memory。
忽略bias,
c
j
c_j
cj和
c
j
−
1
c_{j-1}
cj−1的关系式为
c
j
=
(
z
f
⊙
c
j
−
1
)
⊕
(
z
i
⊙
z
)
=
[
σ
(
W
f
x
j
+
b
f
)
⊙
c
j
−
1
]
⊕
[
σ
(
W
i
x
j
+
b
i
)
⊙
tanh
(
W
x
j
+
b
)
]
begin{aligned} c_{j} &=left(z_{f} odot c_{j-1}right) oplusleft(z_{i} odot zright) \ &=left[sigmaleft(W^{f} x_{j}+b^{f}right) odot c_{j-1}right] oplusleft[sigmaleft(W^{i} x_{j}+b^{i}right) odot tanh left(W x_{j}+bright)right] end{aligned}
cj=(zf⊙cj−1)⊕(zi⊙z)=[σ(Wfxj+bf)⊙cj−1]⊕[σ(Wixj+bi)⊙tanh(Wxj+b)]
则
c
j
c_j
cj对
c
j
−
1
c_{j-1}
cj−1的连乘项等于
σ
(
W
f
x
j
+
b
f
)
sigma(W^fx_j+b^f)
σ(Wfxj+bf),其取值范围是(0,1),这就不是很容易发生梯度消失了。【注意:此时认为
z
f
,
z
i
,
z
o
z^f,z^i,z^o
zf,zi,zo不是
c
j
−
1
c_{j-1}
cj−1的函数,这其实是很片面的,因为这三者都是
h
j
−
1
h_{j-1}
hj−1的函数,自然也是
c
j
−
1
c_{j-1}
cj−1的函数,下面有完整的梯度分析。】
在LSTM的原始论文中并没有 z f z_f zf这样一个控制遗忘的门控,这会造成cell的状态是不可控的,于是加上遗忘门控,而连乘项的截断梯度的估计正好是 f t f_t ft。
补充:上面的梯度计算并不完整,这篇文章很好的解释了这个问题,Why LSTMs Stop Your Gradients From Vanishing: A View from the Backwards Pass (weberna.github.io)
符号假设为
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
C
~
t
C_{t}=f_{t} * C_{t-1}+i_{t} * tilde{C}_{t}
Ct=ft∗Ct−1+it∗C~t
完整的梯度是
∂
h
j
∂
h
j
−
1
=
σ
′
W
h
∂
C
t
∂
C
t
−
1
=
∂
C
t
∂
f
t
∂
f
t
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
+
∂
C
t
∂
i
t
∂
i
t
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
+
∂
C
t
∂
C
t
−
1
∂
C
t
−
1
∼
∂
h
t
−
1
∂
h
t
−
1
∂
C
t
−
1
frac{partial h_{j}}{partial h_{j-1}}=sigma^{prime} W^{h}frac{partial C_{t}}{partial C_{t-1}}=frac{partial C_{t}}{partial f_{t}} frac{partial f_{t}}{partial h_{t-1}} frac{partial h_{t-1}}{partial C_{t-1}}+frac{partial C_{t}}{partial i_{t}} frac{partial i_{t}}{partial h_{t-1}} frac{partial h_{t-1}}{partial C_{t-1}}+frac{partial C_{t}}{partial C_{t-1}} frac{partial C_{t-1}^{sim}}{partial h_{t-1}} frac{partial h_{t-1}}{partial C_{t-1}}
∂hj−1∂hj=σ′Wh∂Ct−1∂Ct=∂ft∂Ct∂ht−1∂ft∂Ct−1∂ht−1+∂it∂Ct∂ht−1∂it∂Ct−1∂ht−1+∂Ct−1∂Ct∂ht−1∂Ct−1∼∂Ct−1∂ht−1
进一步展开
∂
C
t
∂
C
t
−
1
=
C
t
−
1
σ
′
(
.
)
W
f
∗
o
t
−
1
tanh
(
C
t
−
1
)
+
C
~
t
σ
′
(
.
)
W
i
∗
o
t
−
1
tanh
(
C
t
−
1
)
+
i
t
tanh
′
(
.
)
W
c
∗
o
t
−
1
tanh
(
C
t
−
1
)
frac{partial C_{t}}{partial C_{t-1}}=C_{t-1} sigma^{prime}(.) W_{f} * o_{t-1} tanh left(C_{t-1}right)+tilde{C}_{t} sigma^{prime}(.) W_{i} * o_{t-1} tanh left(C_{t-1}right)+i_{t} tanh ^{prime}(.) W_{c} * o_{t-1} tanh left(C_{t-1}right)
∂Ct−1∂Ct=Ct−1σ′(.)Wf∗ot−1tanh(Ct−1)+C~tσ′(.)Wi∗ot−1tanh(Ct−1)+ittanh′(.)Wc∗ot−1tanh(Ct−1)
之前的结果等于
f
t
f_t
ft,一直都是小于1,现在的结果可以大于1也可以小于1,而且
f
t
,
i
t
,
o
t
,
C
t
ˉ
f_t,i_t,o_t,bar{C_t}
ft,it,ot,Ctˉ都是网络自己学习的,因此可以很好的避免梯度消失的问题。
参考文献
LSTM介绍
【强烈推荐】 https://zhuanlan.zhihu.com/p/32085405
LSTM为什么能够缓解梯度消失
【截断梯度的分析,有些错误,注意甄别】 https://www.zhihu.com/question/44895610/answer/616818627
【完整的梯度分析】 https://zhuanlan.zhihu.com/p/109519044
最后
以上就是小巧咖啡豆最近收集整理的关于RNN+LSTM笔记的全部内容,更多相关RNN+LSTM笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复