文章目录
- RNN、LSTM、GRU 的梯度消失及梯度爆炸
- RNN
- RNN 结构
- 前向传播
- 损失函数
- 后向传播(BPTT)
- LSTM
- LSTM 结构
- 前向传播
- 后向传播
- GRU
- GRU 结构
- 前向传播
- 后向传播
- Reference
RNN、LSTM、GRU 的梯度消失及梯度爆炸
RNN
RNN 结构
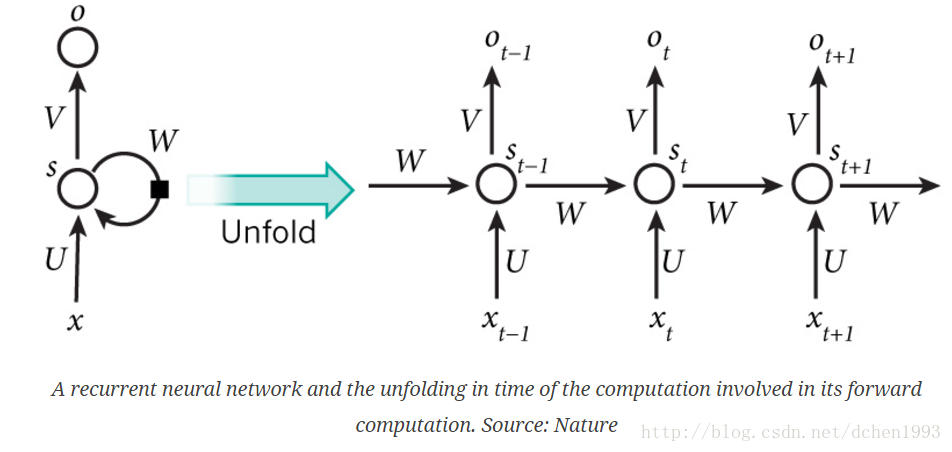
RNN 所有的隐层共享参数
(
U
,
V
,
W
)
(U, V, W)
(U,V,W)。
前向传播
假设
t
t
t 时刻的输入为
x
t
x_t
xt, 隐藏状态为
s
t
s_t
st,输出为
o
t
o_t
ot,那么
s
t
=
f
(
W
s
t
−
1
+
U
x
t
)
s_t = f(Ws_{t-1} + Ux_t)
st=f(Wst−1+Uxt)
o
t
=
g
(
V
s
t
)
o_t = g(Vs_t)
ot=g(Vst)
其中,
f
,
g
f, g
f,g 为激活函数,
f
f
f 常取
t
a
n
h
tanh
tanh,
g
g
g 用于预测,常取
s
o
f
t
m
a
x
softmax
softmax。
损失函数
假设用于序列建模,输入为
(
x
1
,
x
2
,
.
.
.
,
x
T
)
(x_1, x_2, ..., x_T)
(x1,x2,...,xT) ,标签为
(
y
1
,
y
2
,
.
.
.
,
y
T
)
(y_1, y_2, ..., y_T)
(y1,y2,...,yT),模型的输出为
(
o
1
,
o
2
,
.
.
.
,
o
T
)
(o_1, o_2, ..., o_T)
(o1,o2,...,oT)。那么该样本的损失一般可写为 :
L
=
∑
t
=
1
T
L
t
L = sum_{t=1}^TL_t
L=t=1∑TLt
L
t
=
l
o
s
s
_
f
u
n
c
t
i
o
n
(
y
t
,
o
t
)
L_t = loss_function(y_t, o_t)
Lt=loss_function(yt,ot)
后向传播(BPTT)
RNN 使用梯度下降更新参数
(
W
,
V
,
U
)
(W, V, U)
(W,V,U)。参数
V
V
V 的更新较为简单:
∂
L
∂
V
=
∑
t
=
1
T
∂
L
t
∂
V
=
∑
t
=
1
T
∂
L
t
∂
o
t
∂
o
t
∂
V
frac{partial L}{partial V} = sum_{t=1}^{T} frac{partial L_t}{partial V} = sum_{t=1}^{T} frac{partial L_t}{partial o_t} frac{partial o_t}{partial V}
∂V∂L=t=1∑T∂V∂Lt=t=1∑T∂ot∂Lt∂V∂ot
其中, ∂ L t ∂ o t frac{partial L_t}{partial o_t} ∂ot∂Lt 可以根据损失函数的形式以及 L t , o t , y t L_t, o_t, y_t Lt,ot,yt 的值进行计算, ∂ o t ∂ V frac{partial o_t}{partial V} ∂V∂ot 可以根据激活函数 g g g 的形式以及 o t , s t , V o_t, s_t, V ot,st,V的值进行计算。
对于参数 W , U W, U W,U, s t s_t st 是 W , U W, U W,U 的函数, s t = f ( W s t − 1 + U x t ) s_t = f(Ws_{t-1} + Ux_t) st=f(Wst−1+Uxt)。但是RNN所有隐层共享参数,在这个函数中, s t − 1 s_{t-1} st−1 也是 W , U W, U W,U 的函数。
对于参数
W
W
W (
U
U
U 同理) :
∂
L
∂
W
=
∑
t
=
1
T
∂
L
t
∂
W
=
∑
t
=
1
T
∂
L
t
∂
o
t
∂
o
t
∂
s
t
∂
s
t
∂
W
frac{partial L}{partial W} = sum_{t=1}^{T} frac{partial L_t}{partial W} = sum_{t=1}^{T} frac{partial L_t}{partial o_t} frac{partial o_t}{partial s_t} frac{partial s_t}{partial W}
∂W∂L=t=1∑T∂W∂Lt=t=1∑T∂ot∂Lt∂st∂ot∂W∂st
根据链式法则:
∂
s
t
∂
W
=
[
∂
s
t
∂
W
]
+
+
∂
s
t
∂
s
t
−
1
∂
s
t
−
1
∂
W
frac{partial s_t}{partial W} = [frac{partial s_t}{partial W}]^+ + frac{partial s_t}{partial s_{t-1}} frac{partial s_{t-1}}{partial W}
∂W∂st=[∂W∂st]++∂st−1∂st∂W∂st−1
其中,
[
∂
s
t
∂
W
]
+
[frac{partial s_t}{partial W}]^+
[∂W∂st]+ 表示
s
t
s_t
st 不考虑
s
t
−
1
s_{t-1}
st−1 时直接对
W
W
W 求导。而对于
∂
s
t
−
1
∂
W
frac{partial s_{t-1}}{partial W}
∂W∂st−1,同理:
∂
s
t
−
1
∂
W
=
[
∂
s
t
−
1
∂
W
]
+
+
∂
s
t
−
1
∂
s
t
−
2
∂
s
t
−
2
∂
W
frac{partial s_{t-1}}{partial W} = [frac{partial s_{t-1}}{partial W}]^+ + frac{partial s_{t-1}}{partial s_{t-2}} frac{partial s_{t-2}}{partial W}
∂W∂st−1=[∂W∂st−1]++∂st−2∂st−1∂W∂st−2
∂
s
t
∂
W
=
[
∂
s
t
∂
W
]
+
+
∂
s
t
∂
s
t
−
1
∂
s
t
−
1
∂
W
=
[
∂
s
t
∂
W
]
+
+
∂
s
t
∂
s
t
−
1
(
[
∂
s
t
−
1
∂
W
]
+
+
∂
s
t
−
1
∂
s
t
−
2
∂
s
t
−
2
∂
W
)
frac{partial s_t}{partial W} = [frac{partial s_t}{partial W}]^+ + frac{partial s_t}{partial s_{t-1}} frac{partial s_{t-1}}{partial W} = [frac{partial s_t}{partial W}]^+ + frac{partial s_t}{partial s_{t-1}} ([frac{partial s_{t-1}}{partial W}]^+ + frac{partial s_{t-1}}{partial s_{t-2}} frac{partial s_{t-2}}{partial W})
∂W∂st=[∂W∂st]++∂st−1∂st∂W∂st−1=[∂W∂st]++∂st−1∂st([∂W∂st−1]++∂st−2∂st−1∂W∂st−2)
=
[
∂
s
t
−
1
∂
W
]
+
+
∂
s
t
∂
s
t
−
1
[
∂
s
t
−
1
∂
W
]
+
+
∂
s
t
∂
s
t
−
1
∂
s
t
−
1
∂
s
t
−
2
∂
s
t
−
2
∂
W
=[frac{partial s_{t-1}}{partial W}]^+ + frac{partial s_{t}}{partial s_{t-1}}[frac{partial s_{t-1}}{partial W}]^+ + frac{partial s_{t}}{partial s_{t-1}} frac{partial s_{t-1}}{partial s_{t-2}} frac{partial s_{t-2}}{partial W}
=[∂W∂st−1]++∂st−1∂st[∂W∂st−1]++∂st−1∂st∂st−2∂st−1∂W∂st−2
依次对
s
t
−
2
,
s
t
−
3
,
.
.
.
,
s
1
s_{t-2}, s_{t-3}, ..., s_{1}
st−2,st−3,...,s1,最终可得到:
∂
s
t
∂
W
=
∑
k
=
1
t
(
∏
j
=
k
+
1
t
∂
s
j
∂
s
j
−
1
)
[
∂
s
k
∂
W
]
+
frac{partial s_t}{partial W} = sum_{k=1}^{t}(prod_{j=k+1}^{t} frac{partial s_j}{partial s_{j-1}})[ frac{partial s_k}{partial W}]^+
∂W∂st=k=1∑t(j=k+1∏t∂sj−1∂sj)[∂W∂sk]+
因此:
∂
L
∂
W
=
∑
t
=
1
T
∂
L
t
∂
W
frac{partial L}{partial W} = sum_{t=1}^{T} frac{partial L_t}{partial W}
∂W∂L=t=1∑T∂W∂Lt
∂
L
t
∂
W
=
∂
L
t
∂
o
t
∂
o
t
∂
s
t
∂
s
t
∂
W
=
∂
L
t
∂
o
t
∂
o
t
∂
s
t
∑
k
=
1
t
(
∏
j
=
k
+
1
t
∂
s
j
∂
s
j
−
1
)
[
∂
s
k
∂
W
]
+
=
∑
k
=
1
t
∂
L
t
∂
o
t
∂
o
t
∂
s
t
(
∏
j
=
k
+
1
t
∂
s
j
∂
s
j
−
1
)
[
∂
s
k
∂
W
]
+
frac{partial L_t}{partial W} = frac{partial L_t}{partial o_t} frac{partial o_t}{partial s_t} frac{partial s_t}{partial W} = frac{partial L_t}{partial o_t} frac{partial o_t}{partial s_t} sum_{k=1}^{t}(prod_{j=k+1}^{t} frac{partial s_j}{partial s_{j-1}})[ frac{partial s_k}{partial W}]^+ = sum_{k=1}^{t} frac{partial L_t}{partial o_t} frac{partial o_t}{partial s_t} (prod_{j=k+1}^{t} frac{partial s_j}{partial s_{j-1}})[ frac{partial s_k}{partial W}]^+
∂W∂Lt=∂ot∂Lt∂st∂ot∂W∂st=∂ot∂Lt∂st∂otk=1∑t(j=k+1∏t∂sj−1∂sj)[∂W∂sk]+=k=1∑t∂ot∂Lt∂st∂ot(j=k+1∏t∂sj−1∂sj)[∂W∂sk]+
当激活函数
f
f
f 为
t
a
n
h
tanh
tanh 时:
∂
tanh
x
∂
x
=
1
−
(
tanh
x
)
2
frac{partial tanh x }{partial x} = 1 - (tanh x)^2
∂x∂tanhx=1−(tanhx)2
∏
j
=
k
+
1
t
∂
s
j
∂
s
j
−
1
=
∏
j
=
k
+
1
t
(
1
−
s
j
2
)
W
prod_{j=k+1}^{t} frac{partial s_j}{partial s_{j-1}} = prod_{j=k+1}^{t} (1 - s_j^2) W
j=k+1∏t∂sj−1∂sj=j=k+1∏t(1−sj2)W
( 1 − s j 2 ) ≤ 1 (1 - s_j^2) leq 1 (1−sj2)≤1。当 W W W 比较小时,而连乘项比较多时, ∏ j = k + 1 t ( 1 − s j 2 ) W prod_{j=k+1}^{t} (1 - s_j^2) W ∏j=k+1t(1−sj2)W 就会趋近于0。当 W W W 比较大, ∏ j = k + 1 t ( 1 − s j 2 ) W prod_{j=k+1}^{t} (1 - s_j^2) W ∏j=k+1t(1−sj2)W 就会趋近于无穷。这就是RNN容易发生梯度消失或梯度爆炸的原因。
- 梯度爆炸直接导致浮点数溢出,因此比较容易观测到。
- 梯度消失则是靠前的输入无法起到作用,因此模型只能“短期记忆”,影响模型的拟合能力与收敛速度,比较难以观察。
此处存疑: s j s_j sj 正相关于 W W W,当 W W W 越大, s j s_j sj 越接近于1, ( 1 − s j 2 ) (1 - s_j^2) (1−sj2) 越接近于0,因此 ( 1 − s j 2 ) W (1 - s_j^2)W (1−sj2)W 未必会越大而产生梯度爆炸(欢迎探讨)。相对而言,梯度消失更容易发生。只要 W W W 小于1,且序列足够长,就会发生梯度消失。RNN的梯度消失和深层神经网络的梯度消失不同,深层神经网络的梯度消失一般指层数过深,前面的层因为梯度回传(每一层的梯度不一样)相乘次数多的结果趋近于0,RNN的梯度消失并非指总的梯度趋近于0,而是指参数的更新受近距离的梯度主导(近距离的梯度不会消失),很难学到远距离的关系(远距离的梯度会消失)。
由此可以看出,梯度爆炸或者梯度消失主要是因为BPTT时梯度过大或者梯度过小而导致的,那么可以采取以下方法进行改善:
- 梯度截断(gradient clipping)。设置一个阈值,使梯度不超过这个阈值,当梯度超过时使用阈值代替或对梯度进行放缩。
- 使用非饱和激活函数,如ReLU及其变体。sigmoid 和 tanh 作为激活函数时会将实值放缩到小于1的区域内,从而更容易发生梯度消失。
ReLU不会对原来的梯度进行放缩,因此很难发生梯度消失。某次梯度比较大,参数更新完小于0,那么ReLU梯度就会变成0,不会发生梯度消失,但是该参数会死掉,即永远不会更新, Leaky ReLU 等变体可改善该问题。
LSTM
LSTM 结构
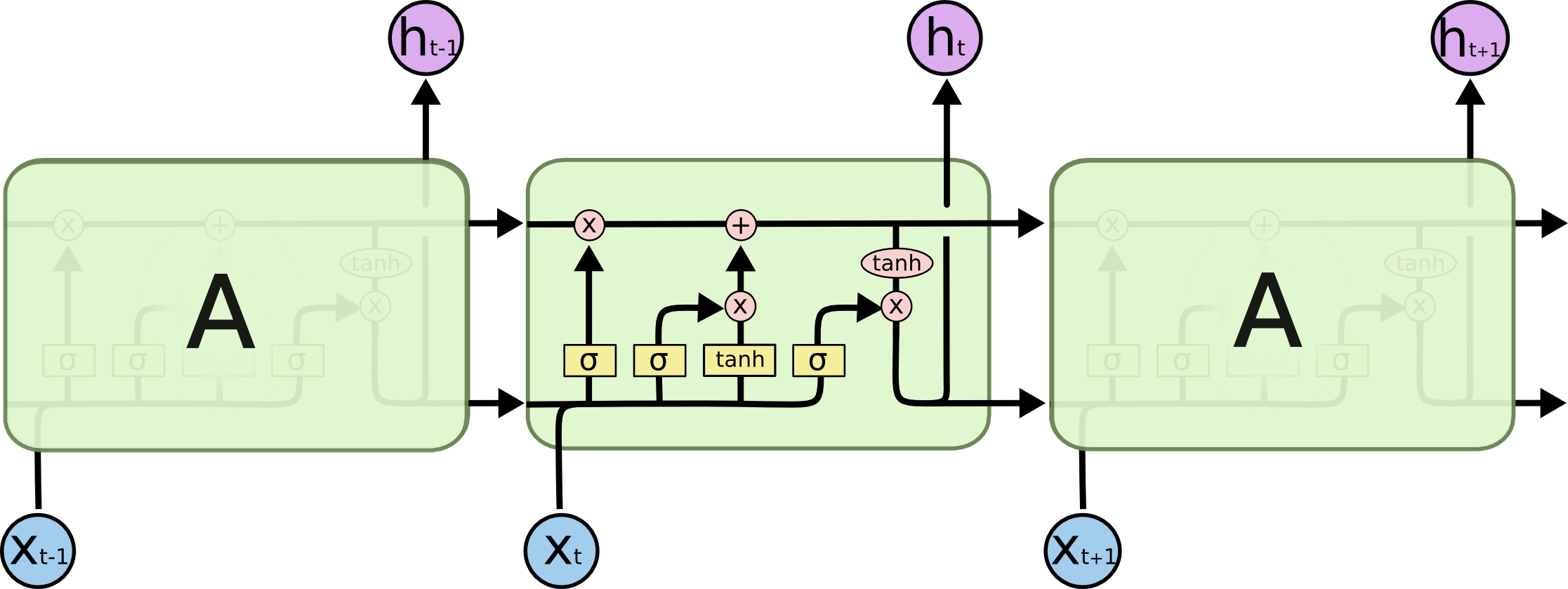
LSTM 主要有三个门结构:输入门、遗忘门、输出门。
前向传播
遗忘门:
f
t
=
s
i
g
m
o
i
d
(
W
f
[
h
t
−
1
,
x
t
]
+
b
f
)
f_t = sigmoid(W_f[h_{t-1}, x_t] + b_f)
ft=sigmoid(Wf[ht−1,xt]+bf)
输入门:
i
t
=
s
i
g
m
o
i
d
(
W
i
[
h
t
−
1
,
x
t
]
+
b
i
)
i_t = sigmoid(W_i[h_{t-1}, x_t] + b_i)
it=sigmoid(Wi[ht−1,xt]+bi)
C
^
t
=
t
a
n
h
(
W
c
[
h
t
−
1
,
x
t
]
+
b
c
)
hat C_t = tanh(W_c[h_{t-1}, x_t] + b_c)
C^t=tanh(Wc[ht−1,xt]+bc)
更新记忆:
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
C
^
t
C_t = f_t * C_{t-1} + i_t* hat C_t
Ct=ft∗Ct−1+it∗C^t
输出门:
o
t
=
s
i
g
m
o
i
d
(
W
o
[
h
t
−
1
,
x
t
]
+
b
o
)
o_t = sigmoid(W_o[h_{t-1}, x_t] + b_o)
ot=sigmoid(Wo[ht−1,xt]+bo)
h
t
=
o
t
∗
t
a
n
h
(
C
t
)
h_t = o_t* tanh(C_t)
ht=ot∗tanh(Ct)
其中,
∗
*
∗ 表示矩阵对应元素相乘。
后向传播
LSTM的计算较为复杂,后向传播求导非常麻烦。因此这里只理解LSTM为何能够缓解RNN存在的梯度消失/梯度爆炸。LSTM中实际上有两个记忆单元,
C
t
C_t
Ct 和
h
t
h_t
ht,考虑
C
t
C_t
Ct:
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
C
^
t
C_t = f_t * C_{t-1} + i_t* hat C_t
Ct=ft∗Ct−1+it∗C^t
考虑
C
t
C_t
Ct 中的第
i
i
i 个元素:
C
t
,
i
=
f
t
,
i
C
t
−
1
,
i
+
i
t
,
i
C
^
t
,
i
C_{t,i} = f_{t,i}C_{t-1,i} + i_{t,i}hat C_{t,i}
Ct,i=ft,iCt−1,i+it,iC^t,i
那么:
∂
C
t
,
i
∂
C
t
−
1
,
i
=
f
t
,
i
+
∂
f
t
,
i
∂
C
t
−
1
,
i
+
∂
i
t
,
i
C
^
t
,
i
∂
C
t
−
1
,
i
frac{partial C_{t,i} }{partial C_{t-1,i}} = f_{t,i} + frac{partial f_{t,i}}{partial C_{t-1,i}} + frac{partial i_{t,i}hat C_{t,i} }{partial C_{t-1,i}}
∂Ct−1,i∂Ct,i=ft,i+∂Ct−1,i∂ft,i+∂Ct−1,i∂it,iC^t,i
RNN的梯度下降是单项式连乘,LSTM则是多项式相乘,其次LSTM的梯度向后传播过程有非常多的路径,上述过程只是其中的一种,只用了对应元素相乘和相加,更为稳定,因此LSTM更难发生梯度消失。但是,总路径没有梯度消失不代表所有路径都没有梯度消失,某些路径后向传播时仍然是发生了梯度消失的。
早期的LSTM实际上是没有遗忘门的,即相当于 f t , i = 1 f_{t,i} = 1 ft,i=1,因此连乘不会导致梯度消失。在添加遗忘门后,如果遗忘门接近 1(如模型初始化时会把 b f b_f bf 设置成较大的正数,让遗忘门饱和),远距离的梯度不会消失;如果遗忘门接近 0,更有可能是模型学到了某些特征(如文本中的 “not”、“but” 等)选择对前面数据进行遗忘。大多数情况下遗忘门仍然是一个0~1的数,LSTM 仍然是有可能发生梯度消失的,只是概率远远低于RNN。
LSTM 仍然是有可能发生梯度爆炸的,但是因为回传路径复杂多样,并且可能经过多个激活函数,因此频率比较低。实际中梯度爆炸一般结合梯度裁剪 (gradient clipping) 解决。
梯度仅仅是LSTM的有效性的一个方面,LSTM的有效性可以从多视角理解,如建模、信息选择上。如 Written Memories: Understanding, Deriving and Extending the LSTM。
GRU
GRU 结构
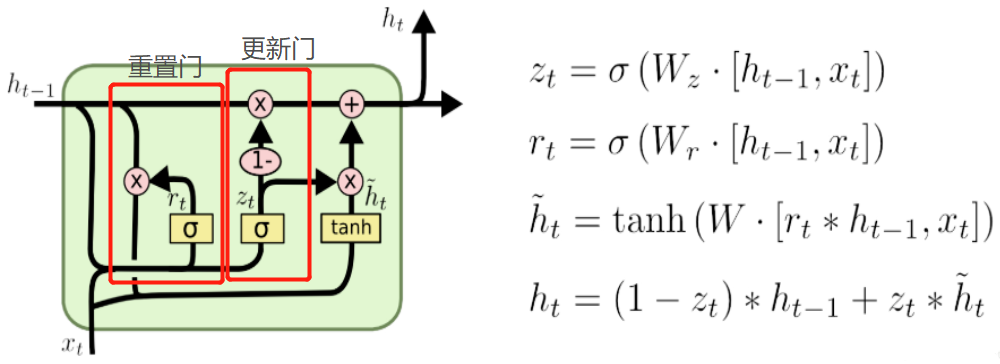
GRU分为重置门和更新门:
前向传播
重置门:
z
t
=
s
i
g
m
o
i
d
(
W
z
[
h
t
−
1
,
x
t
]
)
z_t = sigmoid (W_z[h_{t-1}, x_t])
zt=sigmoid(Wz[ht−1,xt])
更新门:
r
t
=
s
i
g
m
o
i
d
(
W
r
[
h
t
−
1
,
x
t
]
)
r_t = sigmoid (W_r[h_{t-1}, x_t])
rt=sigmoid(Wr[ht−1,xt])
h
^
t
=
t
a
n
h
(
W
[
r
t
∗
h
t
−
1
,
x
t
]
)
hat h_t = tanh (W[r_t * h_{t-1}, x_t])
h^t=tanh(W[rt∗ht−1,xt])
更新记忆状态:
h
t
=
(
1
−
z
t
)
∗
h
t
−
1
+
z
t
∗
h
^
t
h_t = (1-z_t)*h_{t-1} + z_t * hat h_t
ht=(1−zt)∗ht−1+zt∗h^t
后向传播
关于梯度消失和梯度爆炸的分析类似于LSTM。GRU相对于LSTM参数更少,训练更快。理论上GRU记忆能力相对弱于LSTM,但是实际上很难判定优劣,一般通过实验进行选择。
Reference
- https://www.zhihu.com/question/34878706
- Written Memories: Understanding, Deriving and Extending the LSTM
最后
以上就是深情胡萝卜最近收集整理的关于RNN、LSTM、GRU 的梯度消失及梯度爆炸RNN、LSTM、GRU 的梯度消失及梯度爆炸的全部内容,更多相关RNN、LSTM、GRU内容请搜索靠谱客的其他文章。








发表评论 取消回复